
融合知识图谱的文本聚类方法研究
2022-06-09 07:46何先波
南京理工大学学报 2022年2期
龚 芝,马 凌,刘 敏,何先波
(1.湖南信息学院 计算机科学与工程学院,湖南 长沙 410151;2.西南石油大学 信息学院,四川 成都 637001;3.西华师范大学 计算机学院,四川 南充 637002)
由于文本数量、文本结构及多语言符号诸多因素影响,文本数据挖掘难度不断提升,而文本聚类作为文本挖掘的核心方法之一,在文本挖掘质量提升方面优势明显[1],特别是对非标签数据挖掘分析贡献较大。通过聚类,可以有效挖掘海量异构多维数据之间的关系,完成离散非标签的数据分类,将数据进行有效归类整理,提高数据的可用性,为各行业的数据模型分析提供技术支持。在多类别多语言融合的复合文本聚类过程中文本的特征提取及消歧对文本聚类的准确度有较大影响[2],因此对聚类样本的特征预处理显得尤为重要。当前的聚类性能提升研究,一方面是从平台部署角度出发,通过超强运算的云平台及并行技术提高大规模聚类效率,另一方面是寻求适用度更强的算法来提高聚类的准确度和稳定性,本文研究主要集中在后者。
当前,关于文本聚类挖掘方面的研究较多。张旭等[3]从新闻文本入手,详细分析了样本的不同特征选择对聚类性能影响明显,合适的特征训练有助于提高聚类准确度。殷硕等[4]重点分析了语义特征提取方法,并证明了文本特征语义对聚类效果影响明显。这两者都阐述了文本特征有效提取对聚类性能影响较大。知识图谱采用概念、实体和关系的三元模型,可以有效地分析文本的核心概念及关键内容,得到文本的所有知识元节点。相比于文本分词后立即聚类,通过知识图谱建模后对知识元节点聚类,可以获得更高的聚类准确度。因此,本文借助知识图谱技术,将待聚类的文本特征进行有效提取、整合和评价,获得更精准有效的文本特征,然后通过近邻传播(Affinity propagation,AP)聚类算法实现文本聚类,并采用差分进化(Differential evolution,DE)的偏向参数优化策略对AP算法进行聚类增强,提高其在文本挖掘聚类中的准确度。
1 知识图谱
知识图谱技术结构主要是通过知识集合分类,对知识单元抽取[5],然后整合及评估获得知识图谱,其主要结构如图1所示。

图1 知识图谱技术结构
如图2所示,知识图谱采用概念(Concept)、实体(Entity)、关系(Relation)和属性(Attribute)[6]来表示知识,知识图谱的构成要素为知识元。
知识域d内的知识元集合KE d可表述为[6]:K E d={ke1,ke2,…,ke i,…,ke n},其中第i个元素kei可表述为ke i={ci,ei,r i,a i},其中ci、ei、r i和a i分别表示概念知识、实体知识、关系知识和属性知识。知识域d内的概念、实体和关系集合C d、E d和R d
[7],分别表述为:C d={c1,c2,…,c k,…,cnc}、E d={e1,e2,…,ek,…,e ne}和R d={r1,r2,…,r k,…,r nr},概率c i根据其包含的属性可以表述为:Aci={a1,a2,…,a j,…a na},其中nc、ne、nr和na分别代表概念、实体、关系和属性总数。

图2 知识图谱结构
对复杂文本首先进行知识集合分类,接着进行知识单元解析,最后提取知识单元包含的知识元及图谱,通过逐层分析,获得知识图谱。
2 文本聚类算法
2.1 AP聚类
AP聚类的数学描述如下:设2个待聚类的样本i与j,其两者之间相似程度S(i,j)可用以下公式表示[8]

根据式(1)求解任意两个样本点的相似度值,组成样本相似矩阵,其中对角线元素称为偏向参数P,P值对聚类类别数影响较大,在实际应用时对聚类性能影响敏感度高。
设r(i,j)和a(i,j)分别表示样本i与j的吸引度函数和隶属度函数,点i和j的相似程度与r(i,j)+a(i,j)的值呈正比,求解任意2个样本点的吸引度和隶属度,将其组成矩阵R=[r(i,j)]N×N和A=[a(i,j)]N×N。
关于r(i,j)和a(i,j)的求解方法为[9]

r(j,j)为节点j的自吸引度,j′表示除了j的其他样本点,i′表示除了i和j的其他样本点。
当i=j时,式(3)变为[10]

对式(2)两边都加上a(i,j),则有

设E=[e(i,j)]N×N=[r(i,j)+a(i,j)]N×N,E=R+A称为决策阵,设Γ=[τ(i,j)]N×N=[s(i,j)+a(i,j)]N×N,Γ=S+A为潜力阵,则式(5)变为
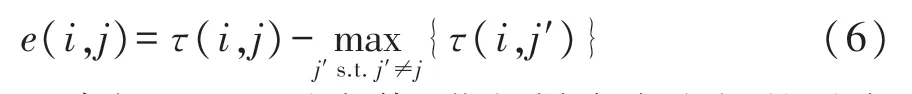
求解e(i,j)最大值,获得样本点之间的最大相似程度,样本点与某簇中心相似程度越高,则表示这个节点属于这个簇,逐一求解各节点至各簇中心点的e(i,j)最大值,便能获得所有点的聚类类别。
2.2 DE算法
设种群规模为N,属性维度为D,差分缩放因子为F,交叉速率CR,每个个体的取值为[Umin,Umax],则第i个个体 的j维属性可表示为[11]

式中:i=1,2,…,N;j=1,2,…,D;rand为(0,1)随机数。
设第G代的个体(i=1,2,…,N)的变异操作得到的G+1代个体为[12]

式中:i≠r1≠r2≠r3,r1、r2和r3为第G代中除了编号为i的个体之外的随机3个个体;F常见取值[0,2]。
个体交叉方法为[13]
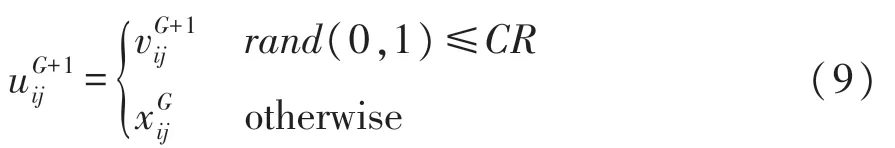

式中:f表示适应度函数。当达到最大代数Gmax时,DE算法停止。
2.3 DE-AP聚类流程
首先,对文本进行知识图谱分析,生成包含知识图谱四元组的样本集合,然后进行DE-AP聚类。根据样本集合构建相似度矩阵,初始化偏向参数,接着通过DE算法进行偏向参数优化,以簇内各节点的相似度之和作为适应度函数,求解DE的适应度最优个体即为最优偏向参数,最后通过最优偏向参数求解AP聚类结果。具体流程如图3所示。

图3 基于知识图谱的DE-AP聚类流程
3 实例仿真
为了验证DE-AP算法的数据聚类挖掘性能,进行实例仿真。仿真数据来源为某大型新闻门户平台,首先验证知识图谱对大规模多样化样本的聚类影响,对聚类结果进行可视化展示;然后分别采用AP算法和DE-AP算法进行聚类性能仿真,对比2种算法的准确率和均方根误差(Root mean squared error,RMSE)性能;最后将常用聚类算法和本文算法进行聚类性能对比仿真。
在进行聚类训练时,4种样本集的训练和测试个数比为3∶1。DE算法的主要参数取值C R=0.1,F=0.1。
3.1 知识图谱对DE-AP的聚类性能影响
为了验证知识图谱对DE-AP的聚类影响,分别采用DE-AP和知识图谱DE-AP算法对表1中的数据集进行性能仿真,并对聚类结果进行可视化,考虑到篇幅原因,在此仅选择体育和历史样本集的可视化结果进行展示,如图4-7所示。

表1 仿真文本集
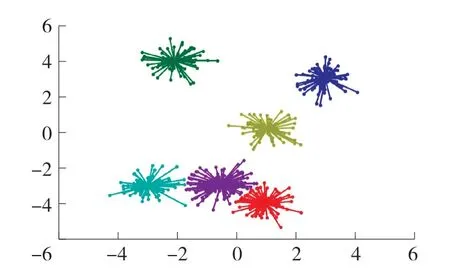
图4 DE-AP聚类可视化(体育样本集)

图5 知识图谱+DE-AP聚类可视化(体育样本集)
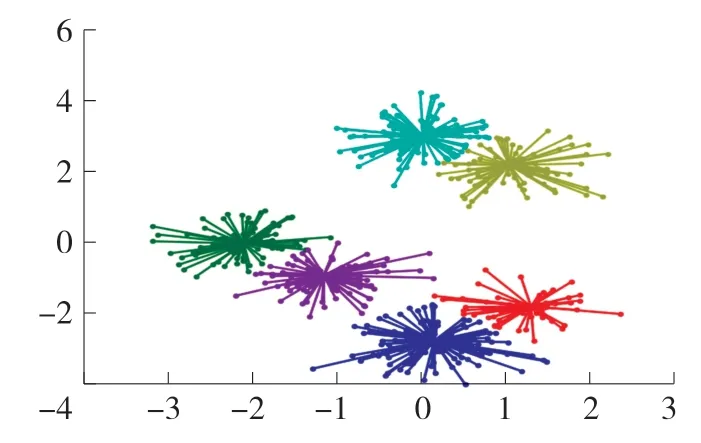
图6 DE-AP聚类可视化(历史样本集)
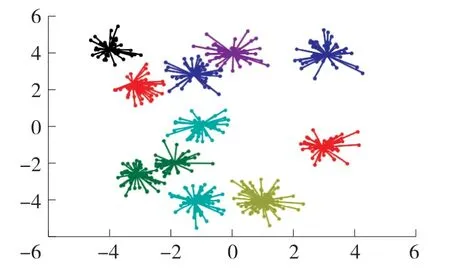
图7 知识图谱+DE-AP聚类可视化(历史样本集)
从上述4图可知,经过了知识图谱处理之后,对于体育和历史样本集,聚类类别数更趋近于实际值,而未经过知识图谱分析之前,体育和历史的聚类类别数分别为6和6,远小于实际类别10和11,聚类误差较大,这表明聚类文本通过知识图谱的分析之后,DE-AP算法的聚类准确度得到明显提升。
3.2 DE的优化性能
为了验证DE算法在AP文本数据聚类挖掘中的性能,分别采用基于知识图谱的AP算法和DE-AP算法对表1中的文本进行聚类,聚类准确率结果如图8所示。

图8 AP和DE-AP的聚类准确率
由图8对比得出,在5个数据集的聚类挖掘中,基于知识图谱的DE-AP聚类性能明显由于AP算法性能,DE-AP算法的5个数据集的聚类准确率均高于0.9,而AP算法在历史类数据集上聚类准确率仅为0.7,其他4类保持在0.8左右,这表明DE算法对偏向参数的优化,有效地提高了AP算法的文本聚类准确率;从聚类时间方面来看,引入了DE的偏向参数优化,增加了耗时,但相比于整个聚类时间来看,DE优化的时间较少,AP和DE-AP算法达到稳定的时间相差较小。
下面将继续对AP和DE-AP的算法稳定性进行仿真,分别验证2种算法的聚类准确率RMSE性能,具体统计结果如表2所示。
从表2可知,在5类数据集中,DE-AP算法的RMSE值比AP算法更小,表明DE-AP算法的聚类准确率更稳定,经过了DE的偏向参数优化,DE-AP算法的文本聚类更稳定,这主要是因为经过偏向参数优化,降低了AP算法聚类的震荡程度,不再因为偏向参数的变化而造成聚类性能大幅震荡。
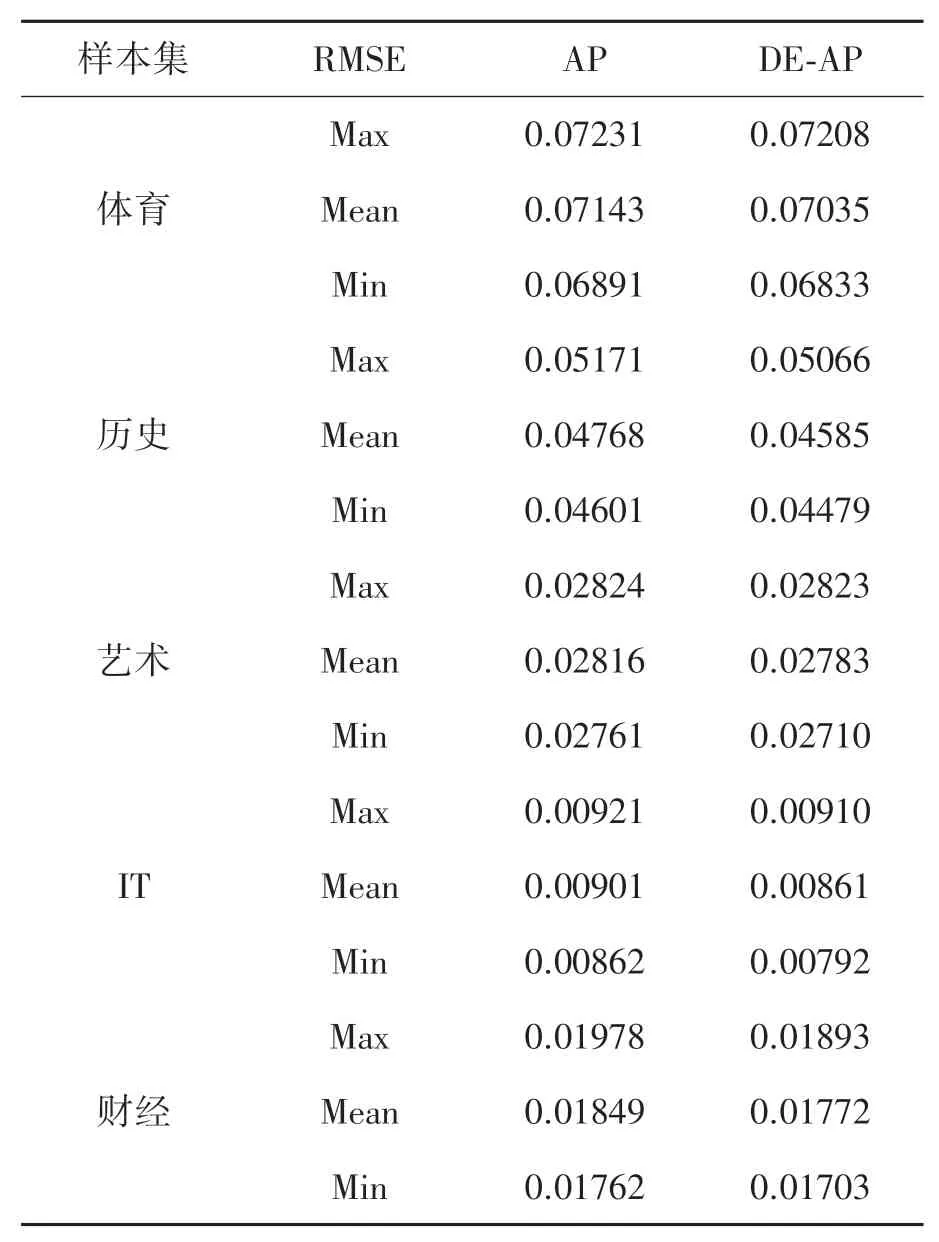
表2 AP和DE-AP的聚类准确率RMSE
3.3 不同算法的聚类性能
分别采用常用文本聚类算法K-means[14]、K-modes[15]、卷积神经网络(Convolutional neural network,CNN)[16]和基于知识图谱的DE-AP对表1中的数据进行仿真,统计其平均聚类准确率和RMSE。
从表3可以看出,在4种样本集的聚类准确率方面,DE-AP算法最优,聚类准确率均在0.9以上,CNN算法次之,而K-means和K-modes算法较差,均在0.8以下。而从数据集横向对比,其中4种算法在IT集的文本聚类准确率最高,而历史样本集聚类准确率最差,这可能与样本集所包含的属性个数有关系,当属性越多,数据聚类的难度随之攀升,准确率也相应下降,历史样本集的属性数明显高于IT样本集。
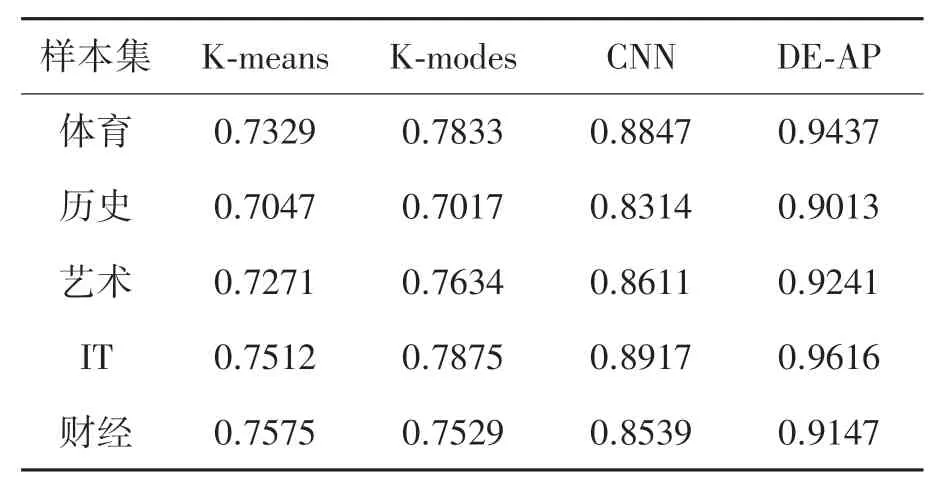
表3 4种算法的聚类准确率
从表4可以看出,在4类数据集的聚类准确率RMSE性能方面,DE-AP的RMSE值最小,CNN次之,K-modes最差,这说明DE-AP的聚类准确率的稳定性最高,而且对比Max、Min和Mean,DE-AP算法3者的值更聚合,表明这个算法在这4类样本集的文本聚类中稳定性高,相比于其他3种算法,聚类稳定性优势明显。

表4 4种算法的聚类准确率RMSE
4 结束语
将基于知识图谱的DE-AP聚类算法应用于文本聚类,能够获得较高的聚类准确率。通过合理设置DE算法的差分缩放因子和交叉速率,求解AP算法的偏向参数;通过DE算法求解的最优偏向参数进行AP文本聚类。与常用聚类算法对比,基于知识图谱的DE-AP聚类算法能够获得更高的聚类准确率。后续研究将在聚类的效率方面进行展开,考虑引用Hadoop云平台,将知识图谱分析和DE-AP聚类分布式进行,以提高聚类效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
心理学报(2022年7期)2022-07-09
心理学报(2022年1期)2022-01-21
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
当代陕西(2020年23期)2021-01-07
健康体检与管理(2021年10期)2021-01-03
当代陕西(2019年12期)2019-07-12
