
司法场景下案例推荐系统的召回方法研究
2022-06-07 06:14肖悦马为之张敏杨俊刘奕群马少平
山西大学学报(自然科学版) 2022年2期
肖悦,马为之,张敏*,杨俊,刘奕群,马少平
(1.清华大学 计算机科学与技术系,北京信息科学与技术国家研究中心,北京 100084;2.清华大学 智能产业研究院,北京 100084)
0 引言
随着信息技术的飞速发展,在互联网上存在大量的信息资源,这使得用户筛选信息资源时需要花费大量的时间和精力,造成严重的信息过载问题。为了解决这一问题,推荐系统利用交互历史或者用户和物品信息对用户兴趣进行建模,并从海量候选信息中匹配用户需要的内容,有效地解决信息过载问题,并成为互联网中一项重要的服务。
随着司法公开的不断推进,可公开获得的司法信息的不断增多。根据中国裁判文书统计,可公开获得的案例文书达到1.2亿篇,并以每天超过5万篇的速度增加。同时用户也有对司法信息强烈的需求,不但法律从业者需要司法信息的辅助,普通民众也有日益增长的需求。司法领域信息公开成为一个重要的全新场景[1-8],对当前的司法也造成了一定的影响[9-12],司法信息推荐能够用来满足用户获取信息的需求并解决信息过载问题,因此司法案例推荐有重要的研究价值。
在推荐系统中,召回与精排是关键的两个步骤,现有的大部分工作关注于精排,但是对召回方法的尝试与研究有限。在实际系统中,往往存在海量的待推荐对象,如何从这些对象中找到用于精排的候选对象也同样重要,召回决定着精排模型的能力上限。司法推荐场景下的召回与现有场景下的召回存在一系列的不同之处,主要体现在以下三个方面:
(1)场景特殊知识会影响召回准确率。对于案例的案由等场景特有的知识,传统召回方法并不能很好地利用这些司法要素,其召回率会受到一定的影响。
(2)用户的使用习惯与信息流或商品推荐有着不同。法律工作者往往会聚焦在某一类案件上,普通用户关注点相对分散。
(3)被推荐对象间关联性更难以被挖掘,尤其体现在案例上。商品间存在配套使用等固有联系,信息流间存在流动关系,但案例间相对独立,其关联性不显著。
本文基于实际司法场景构建了数据集,设计了基于司法要素的召回方法,并与基于内容的方法以及经典召回方法做了比较。为了综合不同召回方法,从多个角度利用案例特征以及用户历史信息,本文提出了多路召回方法并对多路召回策略进行了讨论与探究。
本文的主要贡献如下:
(1)系统地回顾并实现了基于协同过滤、基于案例文书内容的召回方法,并提出基于司法要素的召回方法,以对司法场景下的领域知识加以利用。
(2)设计了多路召回方法的融合框架,能够有效综合各路结果,实现融合,并提出了参与融合单路的选择策略。
(3)基于真实司法推荐场景数据集对各召回方法进行了评价,取得了较好的实验结果,对实际系统有一定的指导意义。
本文内容按照如下结构组织:第1节介绍了当前智能司法推荐的研究与其他场景的召回;第2节介绍了召回方法的设计与实现;第3节介绍了多路召回的框架;第4节展示了基于实际场景的实验结果以及相关分析;第5节对全文做出总结。
1 相关工作
1.1 智能司法推荐的研究
当前推荐算法与推荐系统由于服务对象、应用场景的不同,有着不同的应用方向。有学者从普通民众的角度出发,提出了律师推荐系统[1]为老百姓提供法律服务;一些学者从法律文书的撰写出发,提出了法条推荐系统[2];同时,为了解决“同案不同判”的相关问题,出现了类似案件的推荐系统[3]。
智能司法推荐场景相对宽泛,推荐对象随着需求的不同而不同。本文主要涉及案件判决文书,即案例的推荐。本文需要根据用户的案例特点点击历史,推荐其可能关注的其他案例。一般而言,除文本内容外,案例文书主要包含案由、案情、关键词、法律、法条五种司法要素。其中,案由是对案件性质的描述,如:民事案件中的合同纠纷、刑事案件中的罪名;案情是对案件具体经过的描述,多为短语与短句;关键词是一些用于概括案件经过的词语;法律为案例引用的法律名称,如:《中华人民共和国合同法》;法条为引用的具体条目,如:《中华人民共和国民事诉讼法》第一百七十条。
现有的工作从不同的应用需求出发,在司法场景下做出了不同尝试,但大多都聚焦于精排,对召回的关注度不足,而召回在实际场景中决定着精排的上限,有着同样的重要地位。
1.2 其他场景下的召回方法
当前其他场景下的召回方法较多,相对传统的方法有基于内容、基于协同过滤、基于BM25等方法。随后,因式分解机(FM)[13]的提出为召回算法带来了方便,通过FM的应用,特征组合变得更加高效,利用FM可更加便捷地对用户与项目进行表征。基于神经网络与深度网络的方法是当前最主流的方法,其主要思想仍然在于借助网络化的方法,对用户以及项目进行细粒度的表征,通过其特征进行召回或推荐,此方法在业界得到了广泛的应用。FM与神经网络的出现也促进了传统方法的发展,使得基于内容方法的特征提取变得非人工化并更加细致,也带动基于模型协同过滤方法[14]的发展。以下列举了几个基于神经网络的模型。
(1)“双塔”召回。微软基于文档与查询词之间的相似度,提出了DSSM模型[15],从语义的角度进行召回、推荐,后逐渐发展为“双塔”模型。之后也有学者将该模型进行了一定改进,将其应用在较大数据集上[16]。
(2)序列召回。RNN被应用于会话推荐来捕获用户的序列行为信息。近年来,基于多兴趣召回的 MIMD[17]与基于长期兴趣的 SDM[18]模型被提出,并部署在了相关的实体平台上使用。
(3)图召回。通过构建用户与案例的有向图,对用户与案例的关系做进一步挖掘,对其特征进一步提取并以此为依据进行推荐与召回。特别随着知识图谱的发展,基于知识图谱的推荐系统得到了较大的发展[19-20]。
以上召回方法广泛应用于商品或信息流等场景,商品与信息流场景下拥有大量用户与物品的交互数据,为召回算法的有效性提供了保障。而在司法场景下,可利用的数据尤其是用户的交互数据较少,增大了召回的难度,故本文从多个角度出发,对有限的数据进行多方面挖掘及综合利用,从而提升召回效果。
2 召回方法设计与实现
2.1 基于司法要素的召回
案例文书具有特定的表达形式与规范,文书内包含了多种法律要素,对案例进行了详细描述。例如,民事合同纠纷是案件案由,拖欠工资是案件的案情之一。案例与法律要素之间有着特殊的联系,在此我们使用连接率C来刻画这种联系,其定义如式(1)所示,其中NumYS表示拥有司法要素YS(可取值为案由(AY)、案情(AQ)、关键词(GJC)、法律(FL)、法条(FT))的案例数,Num表示案例总数。

如表1所示,案由是连接率最高的司法要素,案情和关键词次之,而法律和法条的连接率较低。我们考虑使用连接率较高的司法要素进行召回。

表1 司法要素连接率Table 1 Connection rates of judicial element
2.1.1 方法思路与具体实现
经过对司法要素的统计,我们发现案例往往拥有不止一种司法要素,对于某一种司法要素,一个案例同样可能拥有多个,例如一个案例可能引用了多部法律。同时,司法要素的频率也比较重要。一个用户可能浏览了同一案由案件多次,利用用户历史行为对用户进行表征时,频率特征能够反映用户更细致的偏好。BM25算法有利于通过离散特征进行相似度计算并能较为有效地考虑频率信息,因此使用其来计算用户点击历史案例列表与其他案例的相似度得分,随后挑选出相似度较高的案例作为召回结果,某个用户ui与某案例itemj在某一司法要素的相似度计算方式如式(2)所示,其中IDF为逆文本频率指数,Y表示某种司法要素的集合,Yui表示用户ui点击历史中该种司法要素的集合,Yitemj表示案例j中含有的司法要素集合,f(y,Y)表示某个要素y在Y中出现的次数,avgdl为某种要素总数与案例总数的比值,k1,b为常数。

2.1.2 优化与改进
通过观察式(2)可以看出,在对某一种要素做召回时,若两个案例的要素完全相同,那么这两个案例与同一个用户的相似度一致。例如,用户对案由为抢劫罪的案件具有偏好,在召回结果中所有案由为抢劫罪的案例得分均相同,而此案由案例总数可能超过了召回列表长度,只能为用户推荐一部分案例,此时需要进一步考虑相同司法要素案例与用户的相似程度,对基于司法要素的召回进行改进,共有以下四种改进方式:
改进一:在要素相同的基础上,优先推荐点击量较高的案例;
改进二:在要素相同的基础上,优先推荐点击较新的案例;
改进三:在要素相同的基础上,优先推荐点击较新、点击量较高的案例且二者并重;
改进四:按照历史案例要素分布情况召回案例,使召回案例列表与历史案例列表要素分布保持一致。
2.2 基于内容的召回
案例文书的主体仍然是文字,文本特征也是案例文书的特征之一。案例文书的文字中具有丰富的深度语义信息,因此考虑借助BERT对文本中的深度信息进行提取。

2.3 基于协同过滤的召回
在实际场景中,相似的用户所关注的案例也可能更相似,相应的,用户在关注某一案例时也可能会关注与之相似的案例。因此,我们使用了基于用户协同过滤(UserCF)的召回,基于案例协同过滤(ItemCF)的召回,分别通过相似用户、相似案例进行召回。
UserCF与ItemCF两种方法都属于协同过滤方法,其中,UserCF的步骤如下:
(1)根据用户的点击历史建立大小为|U|×|U|的稀疏矩阵 W,W[i][j]表示用户 ui,uj点击过的相同案例个数;
(2)对两个用户 ui,uj,利用 W[i][j]与 ui,uj点击过的不重复案例的总数之比作为用户相似度,求出用户的k个邻居;
(3)根据相近用户点击过的物品itemj,计算用户ui对物品itemj的得分,公式如式(3)所示,其中Sj为对itemj评过分的用户集合;

(4)选取得分top n的案例作为最终的召回结果。
ItemCF与UserCF类似,唯一不同之处在于建立的为案例间的稀疏矩阵,利用案例的邻居进行推荐。
2.4 基于热度的召回
在实际场景中,越热门的案件就越有可能得到用户的关注,因此我们利用热度这一信息进行召回。步骤如下:
(1)统计每个案例被点击的次数,以次数表示热度;
(2)为每个用户推荐热度为top n的案例。
3 多路召回方法框架
在实际场景中,需要一定数量的召回案例,单路召回方法能力有限,只用一种方法有较大局限性。单路的召回方法各有优劣,且考虑的角度不尽相同,因此可以考虑利用多种方法的结果做多路召回。但如何对多路结果进行融合,仍有待实验验证。
单路召回将对每个用户生成一个召回列表,列表包含了召回的案例以及案例的得分,且以得分降序排列。案例的得分用于刻画用户与案例间的相似度,得分越高相似度越高。不同召回方法得分的定义不同,基于司法要素的召回得分如式(2)所示;基于内容的召回中,通过BERT方法可以得到用户与案例之间的欧式距离d,得分为e-d;基于协同过滤方法得分如式(3)所示;基于热度的召回以案例的被点击次数为得分。我们以Bagging为基本思路,设计了以下几种融合策略,以下三种策略展示了对某一个用户各路召回结果的利用。
策略一:每路中从前到后依次取案例,直到取得N个不重复的案例或K路均取完;
策略二:先将每路的评分归一化,某个用户ui对案例itemj的得分如式(4)所示,其中,K表示路数,s[k]表示第k路中ui对itemj归一化后的得分;

策略三:仅考虑单路召回中案例所在的位置,计算表达式与式(4)一致,此时s[k]的值为案例所在位置索引值的倒数。
4 实验结果及分析
4.1 数据集
数据来源于元典智库(现名为元典深思)线上平台,收集了2020年10月—2021年4月的相关案例与用户点击行为,数据已除去爬虫用户,所得数据均由非爬虫用户产生。共收集到权威案例7 167个,用户4 464个,平均交互次数为34.86次,稀疏度为0.995。采用留一法构造数据集,我们将用户的点击均视为正例,并取用户最后一次的交互作为测试集,用户其他历史交互作为训练集。
4.2 评价方法
每种召回方法都会对每一个用户得到一个召回列表,列表按照与用户历史案例的相似程度降序排列,若召回列表前N个案例中含有测试集中对应用户的正例,则认为该用户在N的限制下命中,记作HN[u]=1,反之则记作HN[u]=0。考虑所有用户(用户组成的集合为U),有式(5)定义。在召回阶段,N的取值相对较大,主要是实现第一步的筛选,作为精排模型的输入。本文在单路召回中,本文取N=200,多路召回中则取N=1 000。

4.3 单路召回结果
为了方便方法表示,我们使用简写表示某种方法,对应关系如表2所示,其中,YS为变量,表示司法要素的类型,可取AY等。由于单路召回方法可召回案例数有限,各个单路召回均只统计前200个结果的命中率。

表2 方法简称对照表Table 2 Comparison between methods and their abbreviations
4.3.1 单路召回结果
各单路召回结果如表3所示。其中,基于司法要素的召回使用了用户近20次的案例点击历史。其中,Essemble综合考虑了案由、案情与关键词三个司法要素,三者并重。

表3 单路召回结果Table 3 Results of single-channel recall
通过结果,可以看出:
(1)基于案由这一司法要素的召回取得了最好的效果,说明了司法要素这一场景特殊知识的重要性,也说明了该种召回方法在此场景下是有效的。
(2)在司法要素中,并非所有的要素都是有效的。例如,法条的连接率虽然远低于要素的连接率,但其召回率却相对较高,这是因为在连接率较低时,含有该项特征的案例可能恰好是同一类案例,从而使得召回率提高,但这种较高的召回率是没有意义的,由于含有该项特征的案例较少,难以反映整体情况。因此,应当综合考虑连接率与召回率,此外,案由、案情、关键词三种要素综合后的结果不如案由召回,由此认为以案由为特征的召回是有效的。之后的多路召回中使用案由召回,基于司法要素的改进对象也为案由召回。
(3)基于文本召回的效果并不理想,可能的原因是案例的文本较为复杂,案例的文本内容大部分依赖于事件本身,即文本内容会大量叙述相关事实,而案例与案例间的事实差异较大,文案之间差异明显,不利于相似程度的判断。
(4)协同过滤方法取得了较好效果,说明利用相似用户与相似案例进行推荐在此场景中仍是有效的。ItemCF召回与UserCF召回的结果较为接近,是因为两者是对同一历史信息以相似方式的利用,因此其最终结果相对来说也会较为接近,此问题将在4.3.3做进一步讨论。
(5)基于热度召回的方法召回率相对较低。在司法场景下,用户关注的更可能是某一个案例相关的其他案例,而不是热度较高的案例,热度并不能反映案例之间的相关程度,也没有对用户做个性化的推荐,故其效果相对较差。
4.3.2 改进后的司法要素召回
同案由案例在上述召回方法中具有相同的分数,为了使同案由案例有一定区分度,按照2.1.2中的各方法改进(分别利用了热度、时间、热度与时间、用户历史的案由分布)后的结果如表4所示。

表4 改进后的案由召回Table 4 Improved recall methods based on cause of case
结果显示,改进一、二、三与之前的结果在测试长度较长时差距并不大,原因在于案例的总数目相对较少,当召回测试案例数目较多时,差距就会缩小,因此应当考虑表格的前两项数据。可以看出,当推荐以热度优先时相应的结果更好,当以时间优先时,结果相对降低。在司法场景下,被点击的越多的案例被再次点击的概率会更高,但越新的案例并不一定会得到更多点击。改进四效果相对较差,原因在于案例的总数目并不多,改进四的做法会导致被推荐的案例数减少,但当案例总数较多时,改进四或许能取得更好的结果。例如,当案例总数足够多时,其他改进很可能推荐的都为同一种案由的案例,而改进四则能兼顾案例案由的多样性。
在本场景下,利用热度对案由召回的改进最为理想,因此之后实验中使用的案由召回,皆为基于改进一的案由召回。
4.3.3 重合度分析
上述五种方法从不同的角度进行了推荐,单单从召回率并不能看出几种方法间的关系,也不能反映几种方法的重要程度。为了进一步分析几种方法的关系并衡量几种方法的重要程度,我们进行了正确重合度分析,结果如表5所示,表项的具体计算方式如下:

表5 不同方法的正确结果重合度Table 5 Coincidence of correct results of different methods
(1)以li、cj分别表示表格第i行、第j列所示的方法,以t[i][j]表示表格数值,初值为 0;
(2)若在li、cj两种方法下,对用户u,都有H200[u]=1,则t[i][j]=1;
(3)考虑所有li、cj组合,通过式(6)得到最终表项的取值,分母的H200[u]是基于方法li得到的。

在此种表示方式下,可以通过观察行来判断方法li正确结果在其他方法正确结果中的占比,通过列来观察其他方法正确结果在方法cj正确结果的占比,行所示数据越大,说明其正确结果包含在其他方法正确结果中的比例越大,其有效性相对越低,列所示数据越大,说明其包含越多其他方法的正确结果,其有效性相对越高。
通过结果可以看出,两个协同过滤方法正确结果的重合度较高,但与其他方法的包含与被包含比例适中;案由召回包含了较多其他方法的正确结果且其被包含的比例相对较低;BERT与Popular两种方法包含与被包含的比例相对适中。结果说明案由召回在此场景下是有效的,BERT、协同过滤、Popular都具有一定的价值,而UserCF与ItemCF两种方法之间重合度较高,二者之间应当可以只保留一种方法。
4.4 多路召回结果
4.4.1 不同多路融合策略的召回结果
不同策略的多路召回结果如表6所示。策略一选取了每路中靠前的案例,策略二将案例得分进行了多路平权处理,以得分为依据进行召回,策略三使用了索引值倒数作为得分。
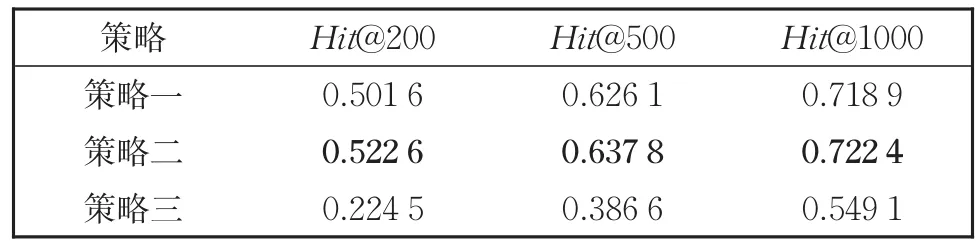
表6 不同多路融合策略的结果Table 6 Results of different multi-channel strategies
三种策略中,效果较好的为策略一、二,策略一选择了每路靠前的案例,形成最终的召回序列,能一定程度上综合各路的结果,具有一定的有效性。策略二则以量化的方式融合了各路的结果,有利于综合各路优势,故取得较好效果。
4.4.2 消融实验
通过重合度分析,我们发现五路中案由召回相对重要,认为ItemCF与UserCF可以仅保留一种方法即可,而BERT、Popular方法具有一定的价值,在此通过消融实验做出验证。方法一到五分别表示无案由召回、无BERT召回、无UserCF召回、无ItemCF召回、无Popular召回,四路与五路召回结果总数保持一致,此时每路被选择的案例数量增加。结果如表7所示。
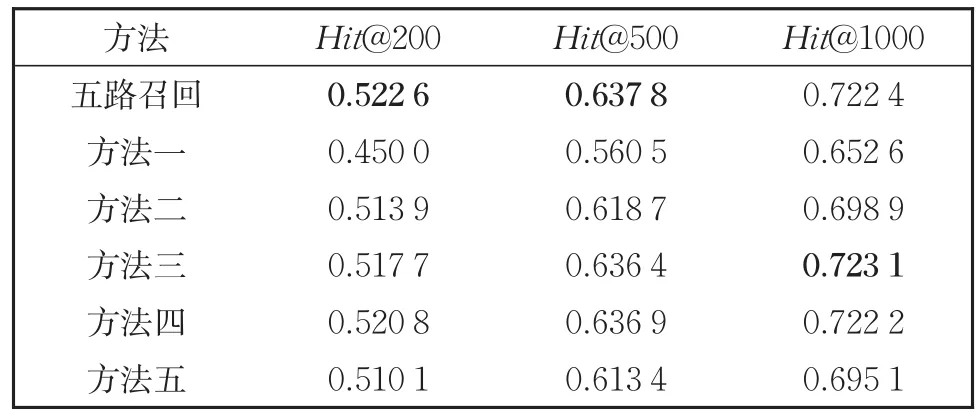
表7 消融实验结果Table 7 Results of ablation experiments
从结果可以看出,当缺少的方法为ItemCF与UserCF其中之一时,召回率下降并不明显,而缺少的为其他方法时,召回率有所下降,尤其是缺少案由召回时,达到了最低值。可以认为案由召回在五路中贡献较大,而两种协同过滤方法最终的贡献程度较为接近。其中,在舍弃UserCF召回时,Hit@1000有所提高,这是因为在舍弃UserCF之后其他方法能提供的案例变多,使结果改善,但通过前两列的值,仍可认为五路召回是最为有效的。
4.5 其他分析
策略四采用的为各路平权相加的融合方式,但是否存在更好的网络结构或网络权重还有待进一步探究,故引入神经网络方法,解决如下两个问题:(1)探究适宜的网络结构;(2)提供网络权重的一种训练方法。整个训练与测试的设计如下。
网络的输入与输出:输入为一个长度为5的向量,分别表示五路中的得分,输出为长度为1的向量,表示五路召回的综合得分。
训练:每次从用户的点击历史中返回一个正例与从用户没有点击的案例中采样得到的九个负例,对案例进行分数预测,损失函数使用成对的损失函数。
测试:测试时针对用户与其所有未点击过的案例,通过网络计算每一个案例的得分,将案例以得分进行降序排序,得到最终的召回列表。
网络结构如下。
网络一:单层线性网络,不含bias;
网络二:双层线性网络,线性层不含bias,使用GeLU为激活函数;
网络三:双层线性网络,线性层不含bias,无激活函数。
以2.3中策略三所示方法作为对比,结果基于十折交叉验证得到,结果如表8所示。
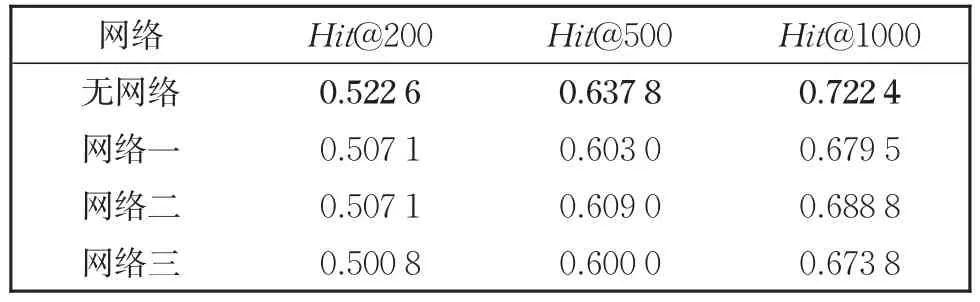
表8 不同网络结构的召回结果Table 8 Results of different network structures
针对问题(1),通过结果可以看出,单层线性网络与双层网络的效果相差不大,原因在于本问题较为简单,无须复杂网络即可达到较好效果,反而平权相加的方式拥有最好的效果。
针对问题(2),由于数据集中正例数目过少,因此对于神经网络训练的指导意义并不强,每次训练收敛时所得的权重相差过大,难以得到一个相对稳定的权重,神经网络方法对权重的确定指导意义较小。
5 结论
智能司法信息处理是司法领域从信息化走向智能化的关键路径,司法场景下的推荐系统有利于满足用户的司法信息需求和缓解信息过载等问题,是一个重要的新兴研究领域。针对案例推荐的召回方法研究,本文系统地回顾并实现了基于协同过滤、基于案例文书内容的召回方法,并提出基于司法要素的召回方法。相比于其他方法,基于司法要素的召回对司法场景下的特殊知识进行了挖掘与利用,利用案由进行召回的方法取得了较好的效果,验证了基于司法要素召回的有效性。在多种融合策略中,将各路对某个案例的评分进行平权相加可取得较好结果,且实现方法简单,算法复杂度低。在选取单路的召回策略时,可以进行重合度分析,若存在某两路结果重合度较大,则可考虑舍弃其中的一个方法从而获得更高的效率。最后,本文尝试了使用神经网络进行多路召回结果融合,但其效果不如多路加权相加方式的效果,反而出现了严重的过拟合问题。由于数据集正例数较少,神经网络收敛时权重差异较大,能为权重确定带来的指导较少。
猜你喜欢
社会科学战线(2022年8期)2022-10-25
上海人大月刊(2022年4期)2022-04-14
家庭影院技术(2021年3期)2021-05-21
家庭影院技术(2021年1期)2021-03-19
家庭影院技术(2021年1期)2021-03-19
人大建设(2018年1期)2018-04-18
人大建设(2018年1期)2018-04-18
中学生数理化·高二版(2016年4期)2016-05-14
债券(2015年9期)2015-09-29
债券(2015年7期)2015-08-08
