
面向规范性文件的基于BERT的文本纠错模型
2022-06-07 06:14汪苏琪王明文曾雪强
山西大学学报(自然科学版) 2022年2期
汪苏琪,王明文,曾雪强
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
0 引言
行政规范性文件是各级机关、团体、组织制发的各类文件中最主要的一类,因其内容具有约束和规范人们行为的性质,故名称为规范性文件。它具有数量大、权威性强等特点,这类文件的文本往往是需要反复审核之后才能发表的,劣质的行政规范性文件会侵犯公民、法人和其他组织的合法权益,更会极大地损害当地政府公信力。因此,辅助有关工作人员对行政规范性文件进行文本纠错就具有了现实意义。
在中文文本纠错任务领域,易蓉湘等[1]提出了中文基于规则的查错方法,对错误的中文文本进行归纳,得到错误规则的模板,积累了这些规则之后,再将可能的错误句子与模板进行对比,检索出错误词。该查错方法的准确率较高,但是由于错误规则模板不可能面面俱到,其他不符合错误规则模板的错误无法检错,因此召回率很低。张仰森等[2]选择以规则和统计相结合的方式对政治新闻的文本进行纠错,首先得到一个以政治语言为特征的错误规则模板,再结合规则与统计的方法实现文本纠错。卓利艳[3]的中文文本自动校对系统使用的方法是条件随机场和N-gram[4]模型,将文本进行错误类型分类,最后再以规则、统计的方式进行纠错。
近年来,已有的文本纠错研究工作大部分以 seq2seq[5](Sequence to Sequence,序列到序列的模型)模型框架为基础,进行文本纠错。他们把文本纠错任务当作机器翻译任务来处理,它的主要思路是把文本纠错问题看成同一类语言的翻译问题,即把错误文本翻译为正确文本,主要实现方法是基于注意力机制的Encoder-Decoder模型。 Fu等[6]采用的基于注意力机制的 Transformer和 Zhou等[7]采用的基于 BiLSTM[8](Bidirectional Long Short-Term Memory,双向长短期记忆网络)和Attention[9]机制的神经翻译模型都在2018年NLP&CC比赛的中文语法纠错比赛中取得了很好的成绩。薛鑫[10]采用了统计机器翻译和神经网络机器翻译相结合 的 方 法 ,以 RNN[11](Recurrent Neural Network,循环神经网络)和N-gram语言模型选取候选词。黄改娟等[12]模拟人类阅读过程提出了一种基于动态文本窗口的纠错方法,叶俊民等[13]将检错和纠错两个阶段作为一个整体,提出了一种基于层次化修正框架的文本纠错模型,提高了模型的解码速度。
随着文本纠错任务的应用越来越广泛,研究者对于各类不同的应用场景提出了有针对性的文本纠错方法。陈翔等[14]在文本数字化工作中以频率统计树构建查错模型,提出了规则与统计结合的自动纠错方法。韩彦昭等[15]针对微博文本中谐音词比重较大的特点使用条件随机场模型进行了文本的词性标注,用贝叶斯方法计算谐音词的原生词候选进行微博文本的纠错。
虽然已有的文本纠错工作取得了一定的效果,但目前还缺少专门针对行政规范性文件的文本纠错任务的算法,不利于有关工作人员更加高效地开展工作。因此,针对有关工作人员在对行政规范性文件的写作过程中的检查错误、纠正错误、文本校对等环节,本文根据上述研究中存在的问题,提出了一个面向规范性文件的基于 BERT[16](Bidirectional Encoder Representations from Transformers,一种经典的自然语言处理领域的预训练方法)的文本纠错模型。该方法能够用计算机自动分析文本中的语义信息,并且针对文本中常见的冗余、缺失、错序、错字等错误[17]进行纠正,帮助工作人员及时发现错误并改正,减轻司法人员的负担,提高他们的效率。
1 模型
本文提出了基于BERT的规范性文件纠错模型,将中文文本的纠错过程拆成两个阶段,分别为检错阶段和纠错阶段。
1.1 检错阶段
检错阶段使用的是基于BERT-BiLSTMCRF(Conditional Random Field,条件随机场)的序列标注模型以及命名实体识别方法过滤实体部分,在该阶段,模型可以标注出句子中文本错误的位置。纠错阶段分四种错误类型分别建模,其中冗余类错误的纠正是通过删除冗余部分来完成的;错序类错误的纠正是通过颠倒错序位置顺序来完成的;缺失类错误是通过BERT掩码语言模型预测缺失部分来完成的;错字类错误是通过BERT掩码语言模型和混淆词匹配相结合的方法来完成的,借此四个模型完成纠错功能。
1.1.1 基于BERT-BiLSTM-CRF的序列标注模型
基于BERT-BiLSTM-CRF的序列标注模型分为BERT层、BiLSTM层和CRF层共三层,一个待检测的文本序列通过该模型之后,可以判断该文本序列是否有误及有误时的错误类型。
(1)BERT层
对于一个待检测的中文文本序列,将其表示为 W={w1,w2,w3,…,wn}。那么这个输入序列对应到BERT模型中,就会分别生成token embedding、segment embedding和 position embedding三个词嵌入(分别为字符向量、句子向量和位置向量),将这三个词嵌入组合起来就成了BERT 的 输 入 序 列 X={x1,x2,x3,…,xn},这 个输入序列包含每个token的字符信息、句子信息以及它们的位置信息。与其他的语言模型相比较,BERT预训练语言模型可以对词前后两侧的信息进行充分的利用,以此得到更佳的词分布表征式。
(2)BiLSTM层
中文文本纠错的结果在一定程度上受到上下文信息的影响,因此希望模型在序列中加入上下文信息。对于BERT的输入序列X={x1,x2,x3,…,xn},将它分别加入两个 LSTM 模型中。第一个LSTM是正向流动的,每一个token的隐藏状态与上一个token的隐藏状态和本token的值有关,也就是得到的隐层序列H={h1,h2,h3,…,hn}中,hi的值由 hi-1的值和 xi的值计算得到,隐层序列H包含了前向token的信息。第二个LSTM与第一个LSTM形式相同,只是从前向变成了后向输入,因此隐层序列H′={h′1,h′2,h′3,…,h′n}中 ,h′i的 值 由 h′i+1的值和xi的 值计算得到,隐层序列H′包含了后向token的信息。将前向隐层序列H和后向隐层序列H′直接拼接在一起,就得到了同时包含前向信息和后向信息的 一 个 序 列 Y={y1,y2,y3,…,yn},其 中 yi=[hi,h′i]。BiLSTM 层最终的输出由包含过去的信息和包含将来的信息两部分共同组成。
(3)CRF层
CRF专注于解决序列标注难题,混合了隐马尔可夫模型和最大熵马尔可夫模型的优势,以此来应对序列标注问题中的标注误差难题。这个模型的学习和预测是以样本特征生成的,它可以根据设置的特征模板进行特征选取,再把特征权重优化,以此得到最优结果。
CRF层的输入是经过BERT层和BiLSTM层训练后得到的序列 Y={y1,y2,y3,…,yn},对于这个输入序列,条件随机场遵从训练模型形成与之相匹配的标签序列L,且每个标签L都从一个指定的标签集中选取。
在本文的中文文本纠错任务中,相邻文字之间的标记信息是至关重要的,因此在模型中加入了CRF层来捕捉这种关系。参考常见的序列标注过程,将CRF层放置在神经网络架构的最后一层,把BiLSTM层的输出作为序列输入进行处理,对每个字符进行分别标注,图1中,“O”为正确字符的标注,“W”为错误字符的标注。基于BERT-BiLSTM-CRF的序列标注模型的流程图如图1所示。
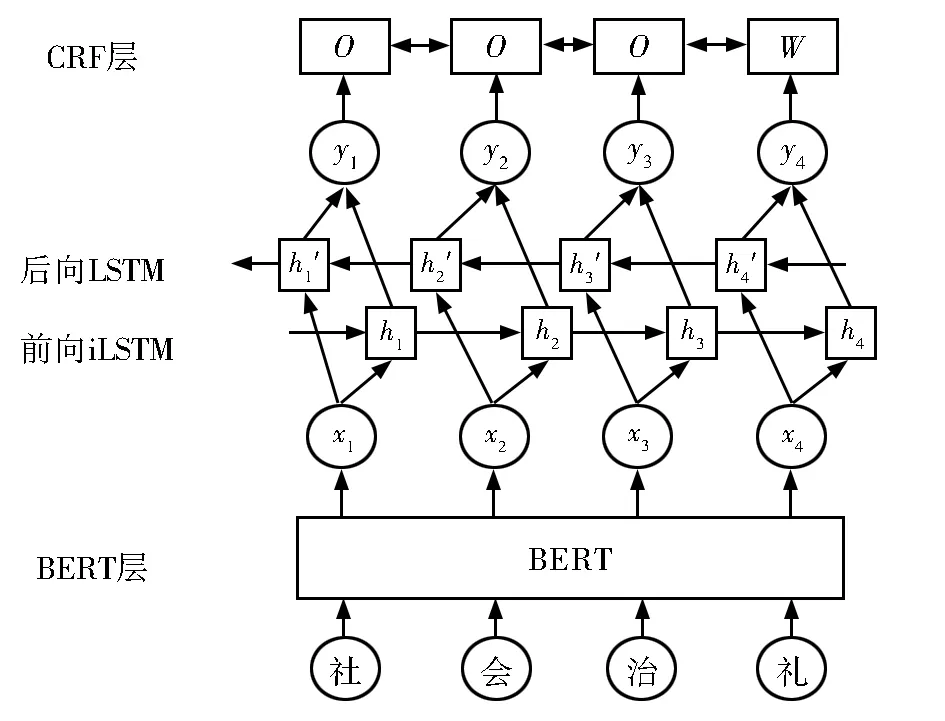
图1 BERT-BiLSTM-CRF流程图Fig.1 Flow chart of BERT-BiLSTM-CRF model
1.1.2 实体过滤器
在行政规范性文件中,包含大量的实体,这些实体内容包括人名、地名、机构名、日期等,这些实体往往没有什么规律且包含了丰富的语义信息,是文本中至关重要的语义单位。BERT-BiLSTMCRF模型在进行错误检查时,很容易把这些实体识别为错误的情况。因此,本文希望用命名实体识别[18]方法把文本中的实体找出来并进行特殊处理,降低系统误判人名、地名等信息为错误的可能性。
本文用BERT-BiLSTM-CRF模型为句子标注出文本的错误标签,用训练好的命名实体识别模型为该句子标注出文本的实体标签。判别错误标签是否是实体标签的一部分,如果是的话,和实体集匹配对比,匹配到相同的实体,则取消这个错误标签,没有匹配到相同的实体则保持标签不变。如果不是实体的一部分,则直接进入下一阶段。实体过滤器流程图如图2所示。

图2 实体过滤器流程图Fig.2 Flow chart of entity filter
1.2 纠错阶段
序列标注模型预测出句子每个字所对应的标签以后,我们可以根据这些标签进行纠错处理。针对冗余、缺失、错序、错字等4种不同的标签,本文提出了4种不同的解决方案。
(1)对于冗余类错误,我们在检错阶段标记出错误位置,并删除了冗余部分。
(2)对于错序类错误,我们在检错阶段标记出错误位置,将标记为错序的部分顺序颠倒回来。
(3)对于缺失类错误,我们在缺失部分加上一个“[mask]”掩码标签,即原序列改为“听证程[mask]按照”。我们将这个包含掩码标签的句子输入到BERT的掩码语言模型中,用这个掩码模型预测“[mask]”的内容。取若干个预测到的词为结果替换“[mask]”,补充到句子中,这样得到若干个候选句子,从这几个词中选择最有可能的词作为结果输出。
(4)对于错字类错误,我们把错字部分替换成了“[mask]”掩码标签,即“被征求[mask]见的部门”。首先,使用BERT掩码语言模型预测“[mask]”的内容,取若干个预测到的词为结果替换“[mask]”,补充到句子中,这样得到若干个候选句子。其次,如果句子标注为“W”的词X出现在混淆集[19]中,则进行混淆词替换纠错处理,将混淆集中的混淆词进行逐一替换,然后再通过模型对替换后的句子进行标注,计算替换后的词被标注为“W”的概率,取其中混淆集中最小概率值的混淆词记为Xj,如果P(X)-P(Xj)>β(β为阈值),Xj为正确的预测词,同样选取若干个预测词组成预测句子。最后,综合两个方法选取出的预测句子,选取出可能性最大的预测句子作为结果输出。纠错阶段的流程图如图3所示。

图3 纠错阶段流程图Fig.3 Flow chart of error correction stage
2 实验
2.1 实验数据及标注
本文的数据集来源于某市提供的审核文件集,文件集主要涉及某市各类《实施方案》《通告》《报告书》《实施意见》等各类行政规范性文件,每一份文件包含若干个细则,一共有106个审核文件。经过提取、统一格式、分句、筛除无用数据等方式预处理之后,以句号为分隔符将长段落分割,最终获得了9 176个句子,这些句子总共包含419 535个字符,最长的长度为502,句子的平均长度为47。
为了生成冗余、缺失、错序、错字等4类错误句子,我们分这4种情况把9 176个句子分别改造为符合其中一种错误的句子。冗余错误类数据的构造方式是在句子序列中随机选取一个汉字字符并重写一次这个字符接在后面,标记字符的位置并将错误类型标为“R”;缺失错误类数据的构造方式是在句子序列中随机选取一个汉字字符并删去这个字符,标记字符的前项和后项并将错误类型标注为“M”;错序错误类数据的构造方式是在句子序列中随机选取两个相邻的字符调换顺序,标记这两个字符并将错误类型标为“N”;错字错误类数据的构造方式是在句子序列中随机选取一个汉字字符,选中的字符有50%的可能替换为该词混淆集中的同音、相似字形的字符,另50%的可能是随机替换成其他字符,标记这个字符并将错误类型标为“S”。以此得到的数据集,其数据格式如图4所示。

图4 行政规范性纠错文本数据集数据样例Fig.4 Data sample of administrative normative error correction text
最后得到一个基于行政规范性文件的文本纠错数据集,它包含36 704条数据,选取其中的80%作为训练集,另外20%作为测试集。在测试集中还加入了相同数量的正确句子,作为测试时的正例。
完成数据集的构建之后,根据任务需要对数据集的每条数据进行序列的标注,标注规则如表1所示。

表1 数据标注规则Table 1 Rules for data labeling
2.2 实验结果与分析
Pycorrector是一个在Github上开源的中文文本纠错工具,它常用于音似、形似错字(或变体字)的纠正,可用于中文拼音,笔画输入法的错误纠正,它的开发语言是python3。Pycorrector实现了一些通用的纠错方法,该工具适合用于作为中文文本纠错的基线模型。在本次实验中构建的数据集下,将本文基于BERT的规范性文件纠错模型与Github上经典的开源中文文本纠错项目Pycorrector作为比较,把检错和纠错两个阶段分别进行对比。
检错阶段如表2所示。本文构建的基于BERT的规范性文件纠错模型在精确率、召回率和F1值上均有较大的提升。相比于Pycorrector的检错模型,精确率上提升了3.37%,召回率上提升了4.17%,F1值提升了4.04%。说明本文构建的纠错模型在行政规范性文件构建的数据集上拥有比Pycorrector的检错模型更好的结果。

表2 检错模型对比表Table 2 Comparison of error detection models
纠错阶段如表3所示。本文构建的基于BERT的规范性文件纠错模型在纠错阶段的精确率、召回率与F1值也有很大的提升,相比于Pycorrector的纠错模型,精确率提升了4.71%,召回率上也提升了9.92%,F1值提升了9.48%。

表3 纠错模型对比表Table 3 Comparison of error correction models
通过实验结果我们容易得知,本文提出的新模型相较于经典的Pycorrector在模型的效果上更胜一筹,实证表明,在检错阶段,使用了BERT-BiLSTM-CRF的序列标注模型和命名实体识别方法进行实体标注的新检错模型,相较于以统计语言模型为主的Pycorrector检错模型的效果有了更大的提升。而在纠错阶段,与使用了BERT掩码语言模型和混淆集匹配方法相组合的新纠错模型相比较,Pycorrector的纠错模型也有所不如。
3 结论
本文提出了一个基于BERT的规范性文件纠错模型,这个模型在我们构建的基于行政规范性文件的文本纠错任务的数据集上取得了较好的效果,实验结果表明它能很大程度上辅助司法工作人员对行政规范性文件审核,提高工作效率。此外,对于下一步工作,本文提出了一些改进的思路:我国的行政规范性文件中经常会出现缩略词来精炼地表达意思,这类缩略词很容易被系统误判,可以考虑针对这种特殊现象给出一个特定的解决方法;本文模型因为对错误类型的细化而取得了更好的效果,可以针对其中的效果不够好的错字类型进行进一步细分以提升错字类的准确度。
猜你喜欢
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
中国广播(2019年12期)2019-02-02
海峡姐妹(2018年3期)2018-05-09
人大建设(2018年1期)2018-04-18
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
农机使用与维修(2014年10期)2014-10-23
