
考虑多性能指标相关性的退化设备剩余寿命预测
2022-06-07 09:04郑建飞牟含笑胡昌华赵瑞星张博玮
哈尔滨工程大学学报 2022年5期
郑建飞, 牟含笑, 胡昌华, 赵瑞星, 张博玮
(1.火箭军工程大学 导弹工程学院,陕西 西安 710025; 2.火箭军装备部驻西安地区第三军事代表室,陕西 西安 710100)
随着工业设备自动化、集成化、精密化水平的不断提升,设备运行过程中监测获得的数据规模不断增大,数据结构也日益复杂[1]。多元退化设备往往由多个部件组成,其不同的性能指标表征的设备退化过程间往往具有相关关系[2]。预测与健康管理(prognostics and health management, PHM)技术通过分析设备的性能监测数据,预测其剩余寿命(remaining useful life, RUL),并据此开展科学合理的维修替换活动,从而有效降低设备的失效风险和维修成本[3-4]。
在工程实际中,监测获得的原始数据往往存在大量不相关或冗余信息,如果直接用来预测RUL可能会影响预测精度。在监测信息的表征方面,信息熵可以描述各性能指标包含信息量的多少,互信息能够衡量各性能指标与设备RUL之间的相关程度,已经广泛应用与RUL预测的特征筛选阶段。
近年来,针对多元退化设备的多元退化建模以及数据融合领域研究逐年增多。多元退化建模相关研究大多假设多个性能退化过程服从同一分布,对于2个性能指标以上的退化设备,往往需要采用多维分布对退化过程进行建模,模型推导和参数更新难度较大[5-6]。多维监测数据融合研究大多只是对多个性能指标进行了简单的线性组合,提取的特征不能充分反映多性能指标间的复杂耦合关系,进而难以准确描述设备的退化演进规律[7-9]。
Copula函数是一种研究相依性测度的方法,能够较好地描述二元随机变量的非线性相关关系,并且已经广泛应用于气象[10-11]、水文[12-13]、电力[14-15]等领域的研究。在多元退化设备的可靠性分析以及RUL预测等领域,也有不少学者基于Copula理论开展了相关研究。张建勋等[16]对不同的退化变量建立了不同的退化过程,并通过Copula函数对RUL边缘分布进行拟合,得到了陀螺仪RUL的联合分布函数。Xu等[17]基于Vine Copula提出了一种多元退化建模方法,相较于忽略退化变量耦合关系的退化模型,可靠性评估的准确性有了明显提升。然而此类方法都是先对单一性能指标建立退化模型进行RUL预测或可靠性评估,再利用Copula函数对预测评估结果进行融合,不能充分利用原始多维监测数据中隐藏的设备健康状态变化信息。
双向长短期记忆(bidirectional long short-term memory, BiLSTM)网络具有强大的时序信息处理能力,逐渐成为设备RUL预测中的热门方法[18-19]。BiLSTM网络由前向LSTM和后向LSTM网络组成,能有效挖掘时序数据的前后依赖关系。然而在设备RUL预测问题中,不同时刻的时序信息重要度可能不同,对最终预测结果的影响程度也不同。BiLSTM网络在进行时间序列预测时,通常只使用最后一个时间步的隐藏状态,随着输入序列长度的增加,可能造成对有效信息的忽视和丢失。注意力(Attention)机制模拟人类视觉,将注意力集中在重要的信息部分并忽略一些无关信息,因此能更好地聚焦于对模型输出更为重要的信息[20-21]。将注意力机制引入BiLSTM网络,能深入挖掘输入数据的时序关联信息,并在不同时刻根据对RUL的重要程度为所有隐藏状态分配不同权重,进一步增强网络捕获远程依赖信息的能力,从而提升预测模型的效率和预测结果的准确性[22]。
综上分析,本文研究了一种考虑多性能指标相关性的多元退化设备剩余寿命预测方法。首先,基于信息熵和互信息进行特征选择,筛选出信息量丰富且能有效表征设备RUL变化的性能指标;然后,基于数据融合的思想,通过Copula函数构造考虑多性能指标相关性的健康指标;最后,将构造的健康指标输入到构建的Attention-BiLSTM网络,从前向和后向2个方向捕获健康指标中隐含的设备退化特征,并通过Attention机制自动调节不同时刻隐藏状态的权重,优化预测网络。相较于现有基于深度学习的多元退化设备RUL预测研究往往忽略多性能指标耦合关系的问题,所提方法考虑了多个性能指标之间的相关性,能更准确地描述多元退化设备的退化规律。
1 特征选择
首先基于信息理论,从监测数据所含信息量以及与设备RUL变化相关程度的角度进行特征选择。
1.1 信息熵
信息熵采用数值形式衡量随机变量取值的不确定性,信息熵越大,描述该变量所需的信息越多,具体形式为[15,23]:
(1)
式中:X为随机变量;p(x)表示变量X取值为x的概率,可以通过核密度估计方法得到:
(2)
式中:n为样本个数;h为窗口宽度;K(·)表示核函数,本文选择高斯核函数,计算公式为:
(3)
(4)
式中:d为变量X的维数,对于一维随机变量取d=1。
1.2 互信息
互信息是2个变量相互依赖关系的一种度量,可以看成是一个随机变量中包含的关于另一个随机变量的信息量[24]。变量之间的互信息越大,表示其相关性越强,计算公式为:
(5)
式中:p(x,y)为随机变量X和Y的联合分布;p(x)和p(y)分别为2个随机变量的边缘分布。
2 基于Copula方法的健康指标提取
2.1 Copula函数简介
Copula函数是一类将变量的联合分布与各自边缘分布连接在一起的函数。记F是边缘分布为F1,F2,…,Fn的随机变量X=[x1,x2,…,xn]的联合概率分布函数。Sklar定理指出,存在一个Copula概率分布函数C(·),对任意X∈Rn有:
F(x1,x2,…,xn)=C(F1(x1),F2(x2),…,Fn(xn))
(6)
常用的Copula函数包括Gumbel-Copula,Clayton-Copula和Frank-Copula,具体信息如表1所示。其中,Gumbel-Copula可以用来描述上尾相关性较强的数据,Clayton-Copula可以用来描述下尾相关性较强的数据,Frank-Copula可以用来描述具有尾部对称且尾部相关性较强的数据。
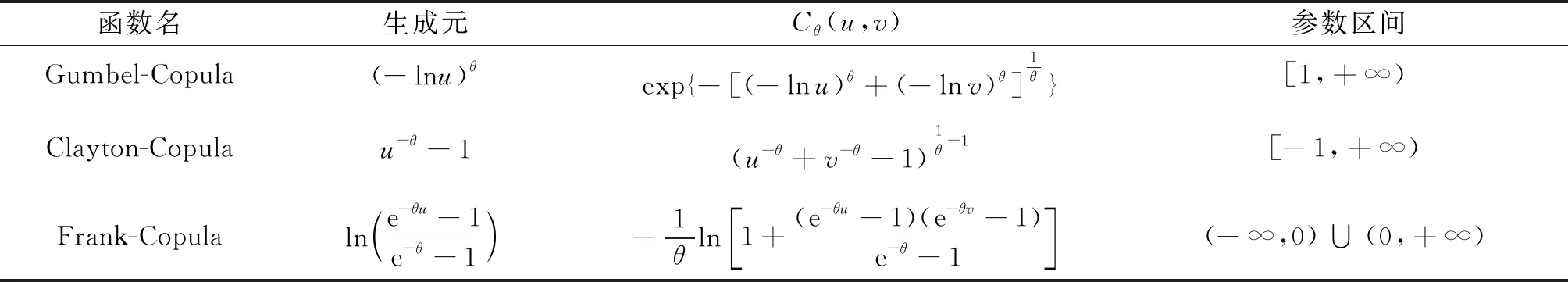
表1 常用Copula函数
Copula函数中的相关参数可采用极大似然估计获取。令L(θ)=lnc(θ),其中c(·)表示Copula概率密度函数,则Copula函数的相关参数θ的估计值为:

arg max[lnc(F1(x1),F2(x2),…,Fn(xn);θ)]
(7)
2.2 Copula函数模型选择
本文选取平方欧式距离d2、均方误差MSE、AIC信息准则3个评价指标对表1中的3种Copula函数模型进行选择,3种指标数值越小,所选Copula函数对原始数据的拟合效果越好。以二元相关变量为例,对于随机变量X和Y,根据核密度估计方法得到其边缘分布u=F(x)和v=F(y),根据样条插值法得到经验边缘分布H(x)和G(y)。
1)平方欧式距离d2。
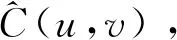
(8)
(9)
式中:n表示样本数量;I[·]为示性函数,当H(x)≤u时,I=1,否则I=0。
2)均方误差MSE。
均方误差通过计算Copula理论分布与经验分布之间的差异程度评估Copula函数的拟合情况,其计算公式为:
(10)
3)AIC信息准则。
AIC信息准则,也称为赤池信息准则,可以衡量模型的复杂度以及该模型对数据拟合的优良程度,计算公式为:
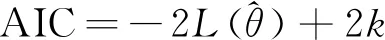
(11)
2.3 Copula条件抽样
Copula函数能够较好的描述2个变量之间的非线性相关关系,同时反映随机变量本身的统计特性。本文采用条件抽样方法对Copula联合分布进行随机模拟,得到能够反映变量本身统计特性以及变量间相关关系的健康指标。
对表1中3种Copula二维联合分布分别求取条件分布,这里以给定v条件下求u发生的条件概率为例。
1)Gumbel-Copula。
(12)
2)Clayton-Copula。
(13)
3)Frank-Copula。
(14)
通过式(12)~(14)得到条件概率后,代入边缘分布求解逆函数x=F-1(u)和y=F-1(v),将Copula联合分布映射到样本值空间,得到能够反映多元变量间相关关系的健康指标。
2.4 算法实现过程
1)为建立Copula模型,首先需要确定各个性能指标的边缘分布,本文选择核密度估计方法拟合各性能指标的边缘分布。
2)通过Copula函数对不同性能指标的边缘分布进行联合,利用备选Copula函数建立二元Copula模型,并给出参数估计与拟合优度检验结果。
3)根据2.2节的评价指标对备选Copula函数模型进行拟合优度检验,3种指标数值越小,所选Copula函数对原始数据的拟合效果越好。
4)基于2.3节的条件抽样方法对Copula联合分布进行随机模拟,将Copula联合分布映射到样本值空间。
3 基于Attention-BiLSTM网络的RUL预测
3.1 BiLSTM网络基础理论
BiLSTM网络能够通过前向和后向2种方式捕获时序数据中的依赖关系,前向LSTM获取输入序列的过去信息,后向LSTM获取输入序列的未来信息,具体结构如图1所示[25]。

图1 BiLSTM结构示意
在每个时间步t,分别计算前向LSTM层的输出ht和后向LSTM层的输出ht,然后将ht和ht连接起来,得到BiLSTM网络输出yt。BiLSTM的更新方程为:
ht=LSTM(xt,ht-1)
(15)
ht=LSTM(xt,ht+1)
(16)
yt=whyht+whyht+by
(17)
式中:why表示前向LSTM层到输出层的连接权重;why表示后向LSTM层到输出层的连接权重;by表示输出层的偏置。
BiLSTM层每个时间步的输出由前向和后向隐藏状态计算得到,在时间序列预测问题中,最后的预测输出通常仅由最后一个时间步对应的隐藏状态得到。尽管此时的隐藏状态与前后时刻的隐藏状态相连,能够反映输入数据间的时序依赖关系,但随着输入序列的增长,网络学习过程中可能丢失一部分有用信息,影响预测效果。
3.2 Attention-BiLSTM网络模型
反映设备退化信息的长时间序列在输入BiLSTM网络时会通过滑动时间窗分为若干时间步对应的短序列,而不同时间步的短序列隐含的设备退化特征往往不同[26]。本文在BiLSTM层后引入注意力机制,对BiLSTM预测模型进行改进,具体的网络结构如图2所示。
图2中,xi为输入的短时间序列,BiLSTM层对输入数据进行双向时序特征提取,并将每个时间步输出的隐藏状态[h1,h2,h3,…,hn]输入Attention层。通过Attention层进行自动学习,给不同隐藏状态赋予不同的权重[a1,a2,a3,…,an],使网络模型能够关注到更重要的信息,优化预测网络。对每个时间步的隐藏状态加权求和后得到综合特征,进而输入到全连接层,得到最终的预测结果y。
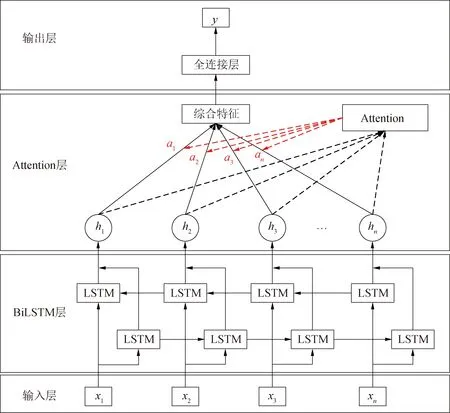
图2 Attention-BiLSTM网络模型
Attention层的计算过程为:
ei=tanh(Wshi+bs)
(18)
(19)
(20)
式中:hi为BiLSTM层在每个时间步输出的隐藏状态;Ws和bs分别为隐藏状态的权值和偏置;ai为注意力权重;s为对所有隐藏状态加权求和后得到的综合特征。
综上,在BiLSTM层后引入Attention,可以充分利用每个时间步的隐藏状态提取有用信息,提升网络模型的预测效果。
本文所提模型的结构框架如图3所示,可分为数据预处理、健康指标提取和剩余寿命预测3个部分。具体步骤为:
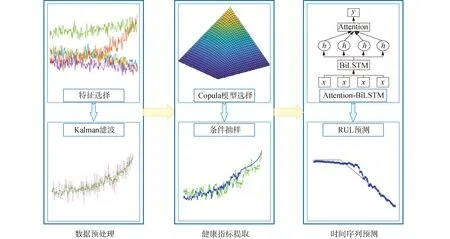
图3 模型结构
1)基于信息熵和互信息进行特征选择,筛选出信息量丰富且能有效表征设备RUL变化的性能指标;
2)对筛选出来的性能指标进行Kalman滤波,减少原始数据中的随机噪声;
3)根据性能指标间Kendall秩相关系数的大小确定分组,利用不同的Copula函数模型描述性能指标间的相关关系,并通过平方欧式距离、均方误差和AIC信息准则3个评价指标选出最优的Copula模型;
4)通过条件抽样对Copula联合分布进行随机模拟,得到新的能够刻画原始数据统计特性以及相关关系的采样值作为健康指标;
5)将训练集得到的健康指标输入Attention-BiLSTM网络进行训练和学习,不断调整网络模型的结构和参数以降低模型损失,得到训练好的网络;
6)将测试集得到的健康指标输入训练好的网络,得到RUL预测结果,并通过均方根误差(root mean square error, RMSE)与其他方法的预测结果进行对比分析。
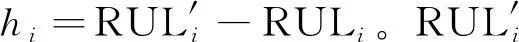
4 实例验证
本文采用CMAPSS发动机数据集对所提方法进行实例验证,CMAPSS数据集记录了发动机编号、运行周期数、3个工作环境参数以及21个传感器测量值,传感器具体描述如表2所示[8,27]。本文选取其中的FD003数据集进行实验,包含100台训练发动机和100台测试发动机数据,在运行过程中存在2种不同的故障模式,数据间衍生关系比较复杂。因此,有必要考虑不同特征参量之间的耦合关系并提取退化特征,从而更准确地描述航空发动机的复杂退化规律。

表2 CMAPSS数据集传感器信息[28]
4.1 特征选择
首先,对于航空发动机运行过程中有明显变化的14个性能指标,基于信息熵和互信息理论进行特征选择,结果如图4所示。
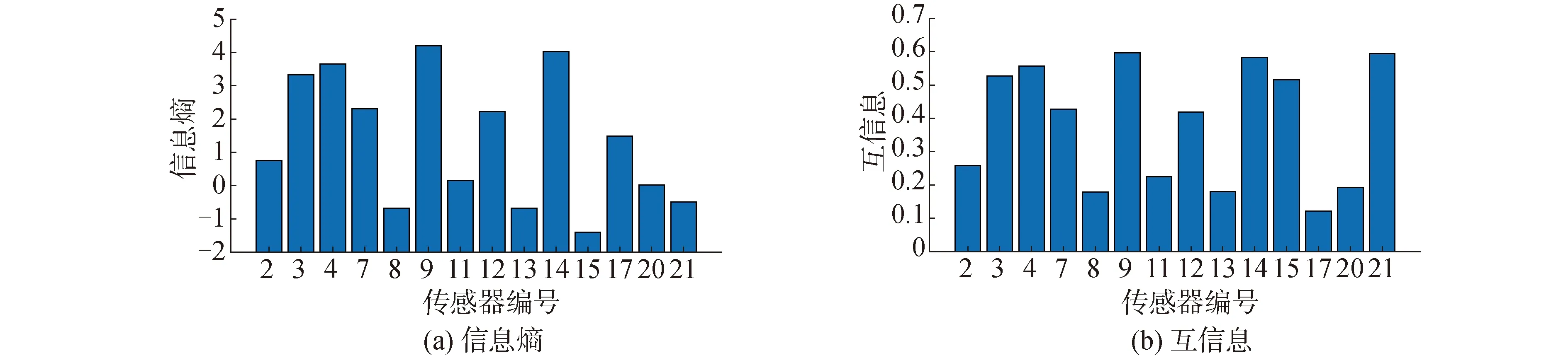
图4 信息熵和互信息结果
尽管第9和第14号传感器的监测数据对应的信息熵与互信息都较大,但其原始信号无明显的趋势性,不能很好地表征设备的退化过程。因此,在信息论的基础上考虑各个性能指标的原始趋势特点,选择第3、4、7、12号传感器数据进行后续的健康指标提取和剩余寿命预测。
4.2 健康指标提取
在设备实际运行过程中,由于受到外部扰动影响,性能监测数据往往包含大量随机噪声,因此采用卡尔曼滤波对原始数据进行降噪处理。
本文基于Copula理论来提取反映多元退化设备状态信息的健康指标。首先,通过kendall秩相关系数分析各个性能指标间的相关关系,结果如表3所示。3号和4号传感器数据的相关性较高,7号和12号传感器数据的相关性较高。因此,按照相关性大小确定分组,分别构建二元Copula模型C1和C2,描述性能指标间的相关关系。

表3 不同性能指标间的kendall秩相关系数
为建立Copula模型,首先需要确定各个性能指标的边缘分布,本文选用核密度估计方法进行边缘分布的拟合,以训练集中1号发动机的第3号和第4号传感器数据为例,按照从小到大顺序对2个传感器数据的核密度边缘分布和经验分布函数进行排序,如图5所示,核密度估计方法与经验分布的边缘拟合效果较好。

图5 边缘分布
对3号传感器边缘分布u=F(x)和4号传感器边缘分布v=F(y)利用备选Copula函数建立二元Copula模型C1,参数估计与拟合优度检验结果如表4所示。
由表4可见,以欧氏距离d2、MSE、AIC信息准则最小为评价标准,Gumbel-Copula函数为第1组Copula模型C1的最优模型,图6给出Gumbel-Copula概率密度图和分布函数图。由图6可知,3号传感器和4号传感器数据的上尾相关性较强,Gumbel-Copula函数能较好地描述其相关特征。
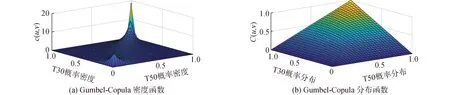
图6 Gumbel-Copula联合密度和联合分布
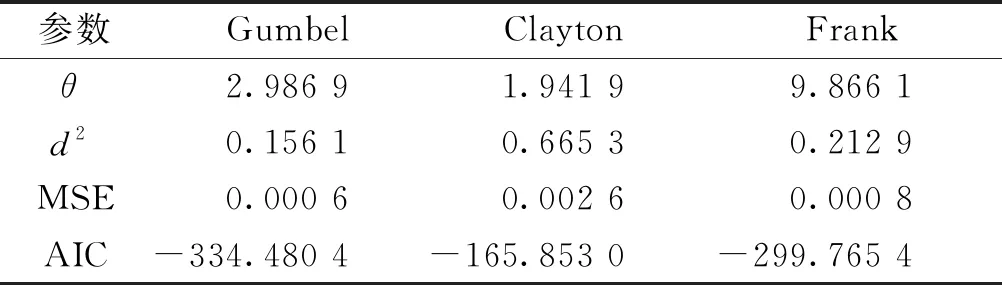
表4 C1参数估计和拟合优度评价
与C1类似,由7号传感器的边缘分布和12号传感器的边缘分布构建C2联合分布,参数和拟合优度评价结果如表5所示,选择Clayton-Copula函数构建第2组Copula模型,图7给出Clayton-Copula概率密度图和分布函数图,可以看出7号和12号传感器数据的下尾相关性较强,Clayton-Copula函数能较好地拟合其相关关系。
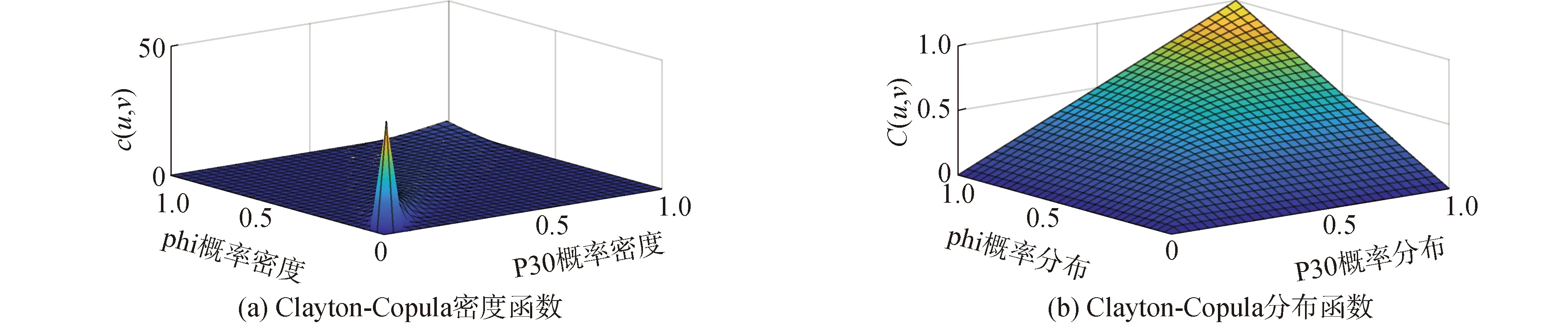
图7 Clayton-Copula联合密度和联合分布
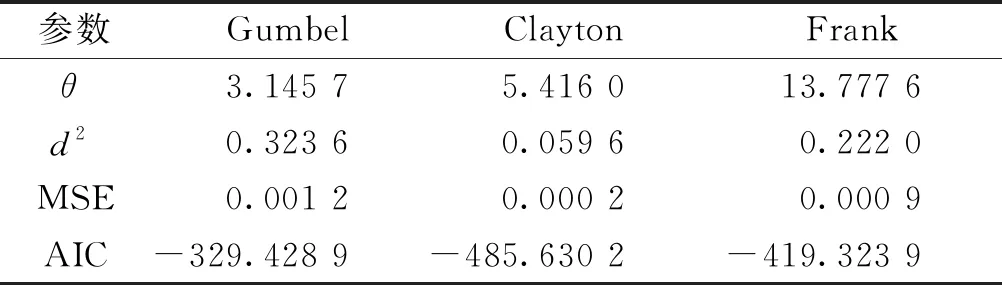
表5 C2参数估计和拟合优度评价
对经过特征选择和预处理过后的性能监测数据进行Copula拟合,并通过条件抽样得到健康指标。由于模型采用多次二维Copula函数,所以其条件抽样是一个多次求逆函数的过程,重复二元Copula条件抽样过程,直到产生所选4个性能指标的模拟值。以测试集1号发动机的3、4号传感器为例,通过Copula条件抽样得到的健康指标如图8所示。
图8中的实线为基于Copula函数条件抽样,随机模拟500次取平均后得到的健康指标,既包含原始数据的统计特性,又能反映2个性能指标间的相关关系,因此能更全面地反映多元退化设备的退化信息。

图8 Copula条件抽样结果
4.3 剩余寿命预测
与文献[18]类似,本文将RUL标签设为分段线性,最大值设为130,滑动时间窗设置为30。为优化网络模型,本文在BiLSTM层后引入Attention层,设置学习率随损失值变化自动调整,衰减因子为0.1,具体网络结构参数如表6中所示。
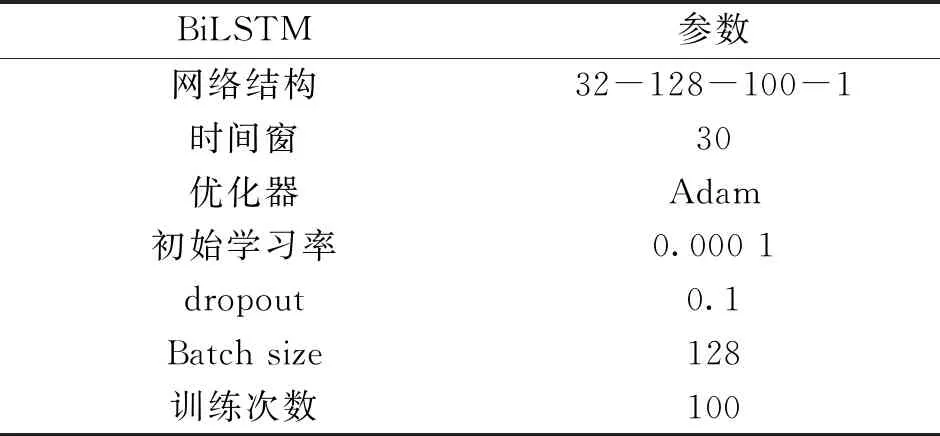
表6 Attention-BiLSTM网络参数
将本文所提Copula+Attention-BiLSTM模型与Attention-BiLSTM、BiLSTM、LSTM 4种方法在FD003数据集上的单步预测结果进行了对比,测试集模型损失通过RMSE来表示,图9给出了4种方法在100次迭代过程中的损失值变化,表7给出了最终趋于稳定时4种方法预测结果的RMSE。
由图9可见,前2种方法的初始loss值均较高,引入Attention机制后,模型收敛速度明显加快,初始loss值相较于前2种方法明显下降。随着迭代次数的增加,模型损失均呈现波动下降,最终趋于平稳。由局部放大图可见,本文所提方法的损失收敛较快,且loss值相较于其他3种方法最小,最终稳定在14.866左右。表7给出了4种方法预测结果的RMSE对比结果,可以看出本文所提Copula与Attention-BiLSTM相融合的方法预测误差更小。接下来,从单个发动机的一次全测试循环角度进行分析,具体如图10所示。
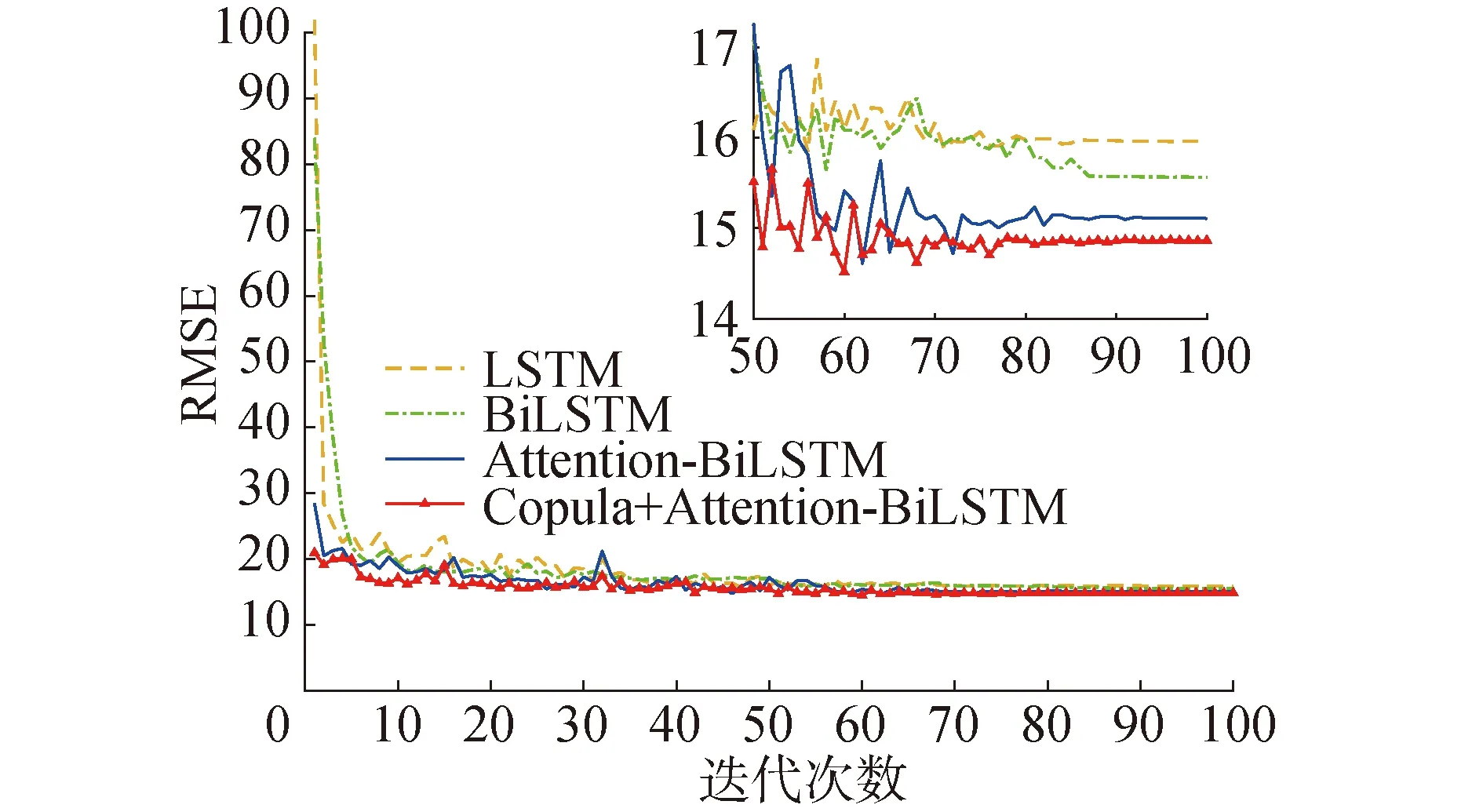
图9 不同方法loss对比

表7 不同方法RUL预测结果对比
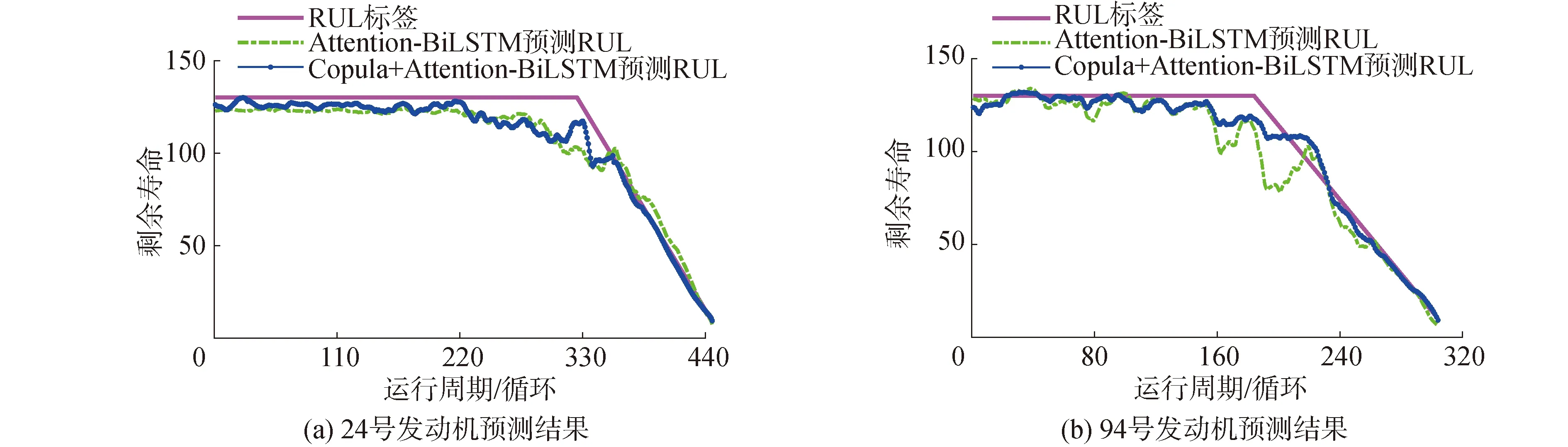
图10 第24台和第94台发动机RUL单步预测结果
图10给出了分别以测试集中第24台和第94台发动机为对象,将本文所提方法与Attention-BiLSTM方法在一次全测试循环进行RUL预测的对比结果。由图10可见,发动机RUL预测结果与监测数据有关,尽管前期预测值与标签存在一定误差,但随着监测数据的累积,预测值越来越接近RUL标签,同时,本文方法的预测结果在大部分测试循环更接近RUL标签,这也从单台发动机寿命周期的角度验证了本文方法预测RUL的准确性。
5 结论
1)本文提出了基于Copula与Attention-BiLSTM网络的剩余寿命预测方法,充分考虑了监测获得的性能退化数据间的相关关系,能更好地描述设备的退化规律,提高RUL预测准确度。
2)通过在CMAPSS数据集进行实验并与其他方法对比,可以看出本文所提方法收敛速度更快,预测的RMSE相较于其他几种方法更小,验证了本文所提方法的有效性。
本文通过Kendall秩相关系数对多个性能指标两两分组,并引入Copula函数分析二元变量间的相关关系。下一步可研究能够直接描述多元变量相关性的方法,以提高RUL预测的时效性。
猜你喜欢
纺织科学研究(2021年1期)2021-12-03
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
电子制作(2019年22期)2020-01-14
时代英语·高一(2019年1期)2019-03-13
电子制作(2018年9期)2018-08-04
考试周刊(2017年7期)2017-02-06
安徽理工大学学报·自然科学版(2016年1期)2016-12-14
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
