
面向多故障模式的多尺度相似性集成寿命预测
2022-06-07 01:31舒俊清许昱晖夏唐斌潘尔顺奚立峰
上海交通大学学报 2022年5期
设备剩余使用寿命(RUL)预测对于提高设备可靠性和预警故障失效具有重要意义.随着传感器和在线采集技术的发展,海量数据驱动的预测方法已成为RUL预测领域的主流方法,可大致分为统计与机器学习方法两类.在工业界,相较于统计方法使用的一些假设限制,机器学习方法应用相对较为广泛.
按照预测步骤的不同,当今主流机器学习方法主要包含RUL直接映射法与基于相似性的方法两类.前者借助机器学习算法直接建立状态监测数据特征与RUL间的映射关系,常用的算法有支持向量机(SVM)、隐马尔科夫模型与人工神经网络等.但是由于设备的寿命长度间可能存在较大差异,在历史数据不足时,这类方法的准确性相对较低.而基于相似性的方法通过构建并匹配退化曲线获得的相似度来预测RUL,可有效避免上述问题.
自从基于相似性的方法被提出以来,大量研究已证明其在RUL预测领域的有效性.文献[12]将基于相似性的回归与证据理论相结合,无需运行至失效的退化数据用于参考,即可实现RUL预测.文献[13]引入核方法双样本检验(KTST)来评估多维传感信号的相似度,并采用威布尔分布来提供RUL置信区间.此外,一些学者直接将多维状态监测数据转化为一维健康指标(HI)曲线,相较于使用多维退化曲线进行相似性匹配,可有效减小相似度测量的计算规模以提高预测速度.目前,线性回归模型、主成分分析、深度神经网络等算法已被学者们用于HI的建立.文献[3]和[15]将双向长短期记忆(LSTM)结构嵌入自编码器中以构建准确性更高的HI,并提出了一种零中心化规则,应对设备初始退化水平间的差异.文献[16]采用受限玻尔兹曼机构建设备HI,并综合利用相似性方法与双向LSTM模型,以提高RUL预测精度.
上述基于相似性的研究已取得较好成果,但仍存在一些可改进之处:一是不同设备退化时会出现多种失效模式,失效模式不同的设备退化过程往往也存在差异,现有研究通常并未考虑失效模式,而是将所有退化轨迹一起进行相似性匹配,计算量大且影响匹配准确度.二是为确保每条退化轨迹都能参与匹配,现有研究通常将匹配时间尺度设置为某个小于所有轨迹长度的常数.在实际中,某些测试设备可提供的退化轨迹可能很短,这种单尺度设置方法将导致其他测试设备退化数据无法被充分利用,从而造成较高的预测误差.此外,各测试设备的退化速度也不一致,难以确定适合所有设备的最优匹配尺度.三是现有基于一维健康指标相似性的研究,通常仅进行RUL的单点预测,而无法表征预测不确定度.在实际工程应用中,以概率形式表达预测结果,描述设备RUL预测的不确定性,对制定合理的维护方案、实现预知维护具有重要意义.
针对上述问题,本文提出多故障模式下多尺度相似性集成(MFM-MSEN)方法.该方法通过故障模式识别,实现分类相似性匹配,并降低匹配复杂度,在此基础上提出多尺度集成策略,提高预测精度与泛化性能,最终拟合出RUL概率分布以提供预测置信区间.将MFM-MSEN方法在数据集中应用,证明了其在多故障模式下应对退化差异的优越性.
1 问题描述
以涡扇发动机为研究对象,分析美国国家航空航天局(NASA)的民用模块化航空推进系统仿真(CMAPSS)数据集,旨在提出一种多尺度相似性方法,以提高涡扇发动机在多故障模式下的RUL预测精度.CMAPSS数据集通过模拟涡扇发动机的退化过程所得,由故障模式与工况种类数不同的4个子集组成,记录了21个由传感器实时采集的状态信号及3个运行工况参数,其中数据集采用的时间单位为运行周期.
考虑到一些状态信号与退化特征无关,其数值仅在几个常数上波动,为了使HI更好地表征退化过程,最终选用了传感器编号为2、3、4、 7、8、9、 11、12、 13、 14、15、 17、 20与21的14个信号.此外,涡扇发动机在运行初期几乎不会衰退,本文引入了分段线性函数来对RUL标签进行修正.根据文献[13],将临界值设置为125,RUL标签中大于125的部分将被修正为125.

迹与所有的训练发动机退化轨迹进行匹配,则会影响匹配的准确度,并且匹配规模的增大会进一步导致匹配计算量与时间消耗的增加.此外,子集FD004包含6种运行工况,这意味着同一个发动机单元在其运行过程中,工况可能会发生变化,而不同工况下其状态信号的波动范围也不一致,从而造成了预测难度的增加.
2 基础理论方法
2.1 自编码神经网络

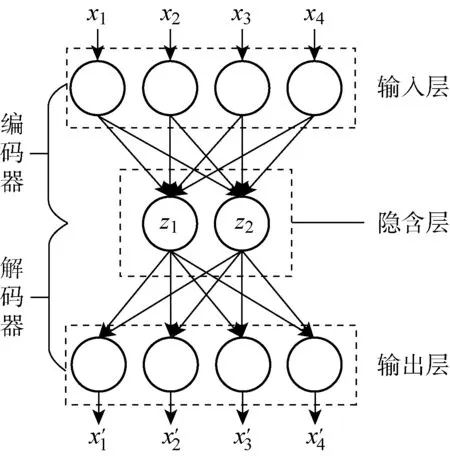
编码器对输入网络的高维数据进行编码,压缩为低维特征向量,即隐含层输出,而解码器则将其解码为′,期望还原成输入数据.AE的训练目标即最小化重构误差,则有
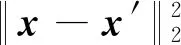
(1)
在此种无监督训练方式下,只使用正常状态数据训练AE,重构误差的大小则可有效反映设备异常程度.此外,通过采用合适的非线性激励函数,编码器可将高维输入数据非线性映射至低维特征数据,且该低维数据可通过解码器进行还原,据此有效克服线性降维方法造成的信息损失问题.因此,本研究将自编码网络用于健康指标建立以及故障特征提取之中.
2.2 支持向量机
支持向量机是一种有监督的二分类模型,其核心思想是找到一个合适的超平面能在最大限度上将不同类别样本分开.单个SVM模型只能处理二分类问题,但通过设计多个SVM模型,并采用投票法综合多个模型的结果可实现多分类功能.本文采用“一对一”SVM多分类方法,其思想是在任意两类样本之间设计一个SVM模型, 对于包含′类样本的训练集,则需设计′(′-1)2个SVM模型假定训练集样本总数为,即={(,), (,), …, (,)},其中维向量∈,类标签∈{1, 2, …,′},=1, 2, …,,那么第类与第类样本间SVM模型的优化问题可表示为
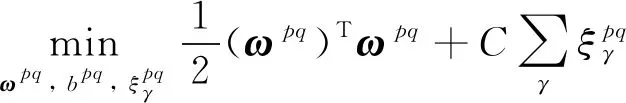
(2)
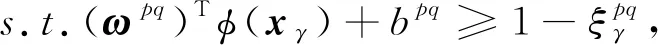
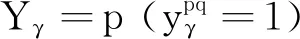

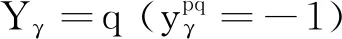

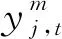
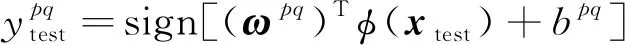
(3)
1933年春,持志中学,即私立持志学院①今上海外国语大学的前身。1924年 12月,何世桢与其弟何世枚,在上海体育会西路兴办“私立持志大学”。校名源自何园主人何芷舠的别字“汝持”。附属中学,成立了持钟剧社。持钟剧社成立时恰逢左翼戏剧运动的浪潮。1933年,《持志半月刊》刊载的一篇题为《持钟剧社成立之前》的文章,很好地体现了持钟剧社的创社宗旨:
2.3 核密度估计
核密度估计(KDE)是一种用于估计未知概率密度函数的非参数方法,其在研究数据分布特征时,不做任何先验假定,目前在理论和应用领域都受到了高度重视.假定,, …,为独立同分布的个样本点,其在KDE下的概率密度函数(PDF)为

(4)
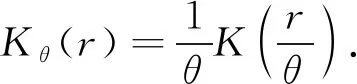
3 MFM-MSEN预测方法

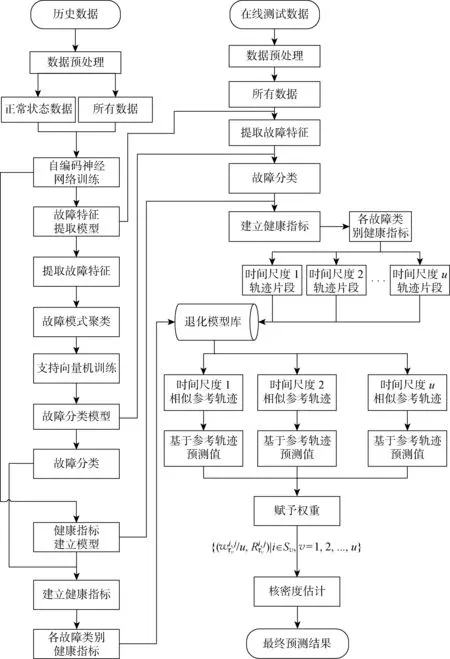
3.1 基于AE重构误差的健康指标建立
作为相似性方法的基础,HI的构建能简化退化模型,进而提升相似性匹配的效率.考虑到在实际工业环境中,往往存在一些未监控因素会造成设备间的差异.若直接使用多维监测数据的压缩表示作为HI,则鲁棒性较差.因此,本文基于AE重构误差来建立健康指标.
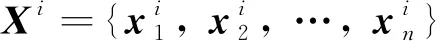
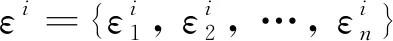
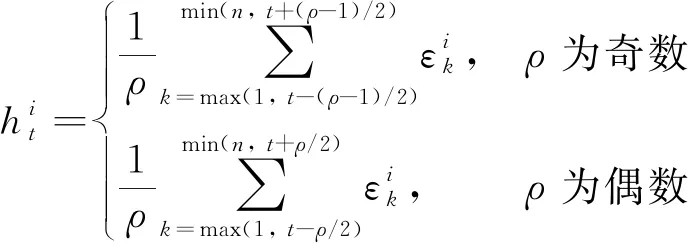
(5)
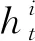
3.2 基于AE-SVM的故障模式识别
为提升多故障模式下相似性匹配的速度与准确度,将AE-SVM与时序加权预测相结合,对设备故障模式进行识别与分类.为提取更多故障模式信息,减小非线性信息损失,以AE编码器输出的低维特征向量,即原始状态监测数据的压缩表示为故障特征.考虑到设备运行初期的故障特征往往并不明显,使用-means对故障模式进行聚类时,只选用其即将失效时的特征.假设存在类设备故障,聚类后第类故障的特征矩阵为

其中:为×矩阵,为第类故障的故障特征样本数量,为故障特征的维度,即AE隐含层神经元的数量.对应的类标签可表示为×1矩阵=[…]
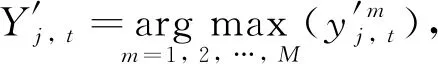
老板娘呢?老板娘站在榆树下,转着金环、银环、玉环的手腕剔指甲,看“老黄”带着他的傩戏班大包小包回村去,村里柴门闻吠,风雪夜归人,狗吠儿啼之后,闹完梁二狗的洞房,再灌一肚子的黄粱酒,睡!人声渐寂,一盏一盏灯火熄灭,他们布下的这一出黄粱梦,终于弄到了钱过年,也没有伤到人,自己自荐做老板娘,十余日的辛劳,还是值得的。明年鸟窝大师他们还会继续设局吧,这样的浮华世界,桃源故事,就像酒席上面开胃的山珍野菜,在这个盛世华年里,当然可以卖出好价钱。

(6)
=1, 2, …,

群众文化不仅体现了国家的特色,还在一定程度上代表着民族的特色。我国是一个多民族国家,各民族对群众文化都有自身的见解,各民族的文化建设方式也各有不同。但是,文化建设的本质是一成不变的,都是在娱乐活动中,满足人民群众的精神需求,并提高人民群众的文化素养,进而促进国家的快速发展。通常情况下,文化建设在文化艺术活动的基础上,应用各种各样的文化内容、管理模式,提升文化建设水平。
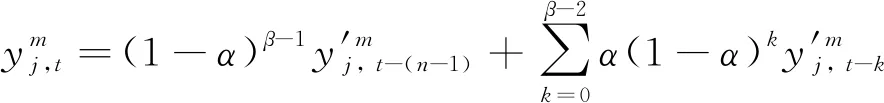
(7)
=1, 2, …,
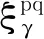
而对于IV类润滑剂而言,由于其主要成分为合成油聚α烯烃,其对橡胶材料各类性能参数的影响略有不同。当被浸泡在IV润滑油中时,丁腈橡胶吸入润滑油的量小于溶解在润滑油中的橡胶添加剂的量,内部的网状结构被压缩,橡胶试样内部分子链的自由度变小,导致其体积减小、硬度增大、拉断伸长率减小;而体积增大使得内部的网状结构被压缩,增大了网状链结构中的相互作用力,使得其抗拉伸能力有所增强,所以其断裂拉伸强度增大。
3.3 多时间尺度相似性匹配
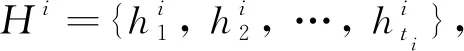

(8)
=1, 2, …,-+1
由此可见,时间尺度是影响相似性匹配准确性的关键因素.由于各测试轨迹长度间差异较大,若采用单个时间尺度,将无法充分利用所有测试样本的数据信息.此外,退化速率不同的测试样本适合的匹配尺度也不同.例如对于正在加速衰退的测试样本,由于其HI值变化十分迅速,采用较短的轨迹片段即可准确匹配.
(2)学生明确测试的自变量(测试桥的结构),控制无关变量(桥的长度、跨度),掌握科学的实验方法,对实验过程作好记录。
针对上述问题,本研究提出了多尺度集成(MSEN)策略,将退化轨迹截取为多个不同长度的轨迹片段.假定匹配时间尺度集合为{,, …,},其中为尺度数量,且有0<<<…<,则尺度需满足以下条件:
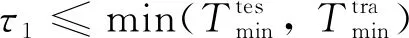
(9)
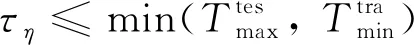
(10)
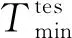
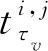
混合式教学的一大优势就是对学生的考核是过程性的全方位的。本课程对学生的考核包括线上线下两部分,线上主要包括在线作业、在线测试和在线学习行为;线下主要包括学生的出勤、学生课堂表现和小组汇报成绩。其中,学生的在线学习行为主要包括在线时长、课程论坛、学习材料学习、学习笔记等等。线上的成绩可以通过系统设定,自动生成。线下成绩可以导入平台,通过平台实现对学生高效的综合管理与评价,进而激励学生持续认真的学习。
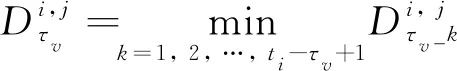
(11)
=1, 2, …,
在每个时间尺度下,选择与测试样本相似度较高的参考样本用于预测RUL概率分布.

3.4 基于MSEN策略的RUL分布预测
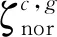
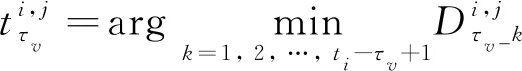
(12)
=1, 2, …,
基于参考样本,测试样本的RUL预测值可表示为

(13)
=1, 2, …,

(14)

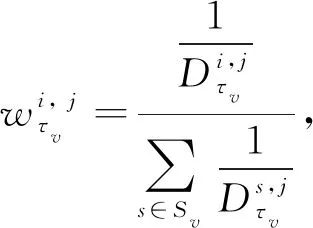
∈,=1, 2, …,
(15)
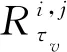
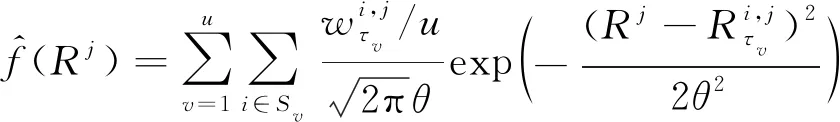
(16)
式中:为测试样本的RUL.
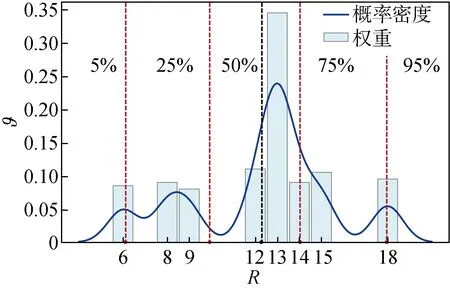
基于KDE的RUL概率分布拟合如图4所示,其中:ϑ为核密度值;为剩余寿命预测值.依据预测值和对应的权重,基于KDE的RUL概率分布预测可提供不同水平的置信区间.此外,通过计算所拟合分布的均值,可得到最终的RUL点估计值为

(17)
通过集成多个尺度的预测值,具有不确定性的RUL最终预测结果可以为预知维护提供更准确和可靠的支持.
4 案例研究
4.1 数据预处理
由于不同工况下传感信号的波动范围不同,所以对于包含6种工况的FD004,在归一化处理前需根据工况参数,对传感信号进行-means聚类.对子集中属于同种工况的信号数据,本文采用最小-最大值规范化方法来消除量纲的影响,公式如下:
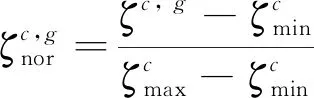
(18)
由于难以选择使预测误差最小的最优时间尺度,本文提出了MSEN策略集成多尺度RUL预测结果,从而提高预测的准确性与泛化性能.由图3可知,测试样本的预测结果根据与其相似的多尺度参考轨迹片段得到.假设在时间尺度下,参考样本中与测试样本最相似的轨迹片段的起始时刻可以表示为

选择包含两种故障模式的子集FD003与FD004用于分析,具体信息如表1所示.由表1可知,训练集与测试集可提供的运行周期数间存在较大差异.训练集记录了训练发动机单元从开始运行至失效的全寿命周期状态监测数据,测试集则只包含测试发动机单元运行至失效前某个时刻的状态监测数据,需要对该时刻设备的 RUL进行预测.此外,CMAPSS数据集提供了各测试发动机的RUL实际值,以验证预测方法的性能.在子集FD003与FD004中,发动机单元既可能因为高压压气机出现故障而失效,也可能由于涡扇故障而失效,本文中以“故障1”和“故障2”来区分两类故障.故障模式不同的发动机单元,退化数据的变化趋势也会存在差异.因此,在进行相似性匹配时,若将测试发动机退化轨
4.2 预测实现
(1) 健康指标建立.
使用聚类后的故障特征训练故障分类模型,模型采用高斯核函数,惩罚系数设为1.最终,综合考虑10个时刻的故障特征,加权系数设为0.4,识别测试单元的故障模式.

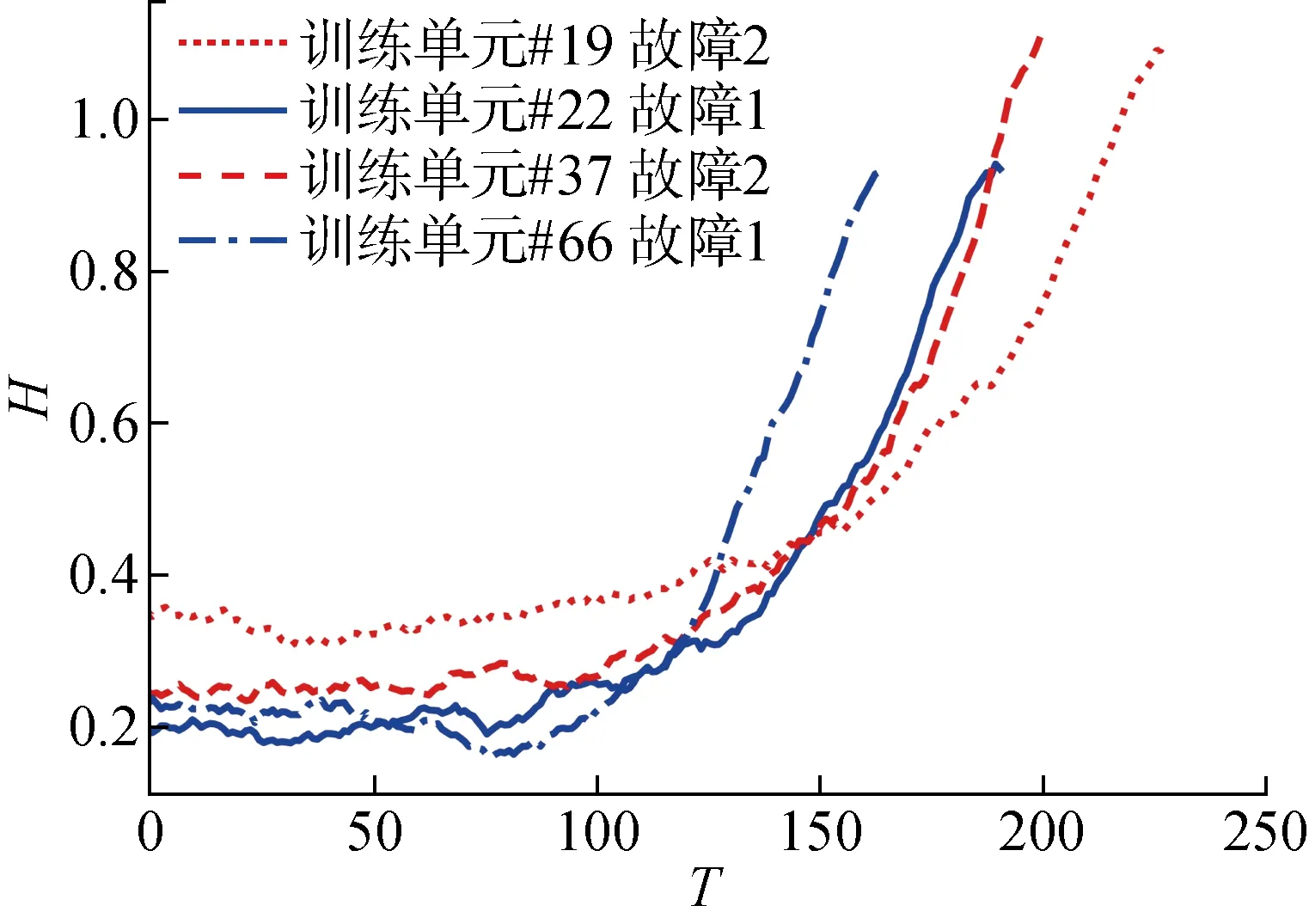
子集FD003部分训练单元的HI曲线如图5所示.在运行初期,轨迹的斜率接近于0,在即将失效时,HI值迅速上升.这表明退化轨迹可较好地表征发动机的退化过程.此外,可发现图5中处于两种不同故障模式的训练单元最大健康指标值间存在一定差异,侧面证明了多故障模式识别以及分类相似性匹配的必要性.
根据全国水资源综合规划成果,受水区多年平均水资源总量为434.76亿m3,占全国水资源总量的1.53%,其中地表水资源量为232.41亿m3,地下水资源量为284.54亿m3。
(2) 多故障模式识别.
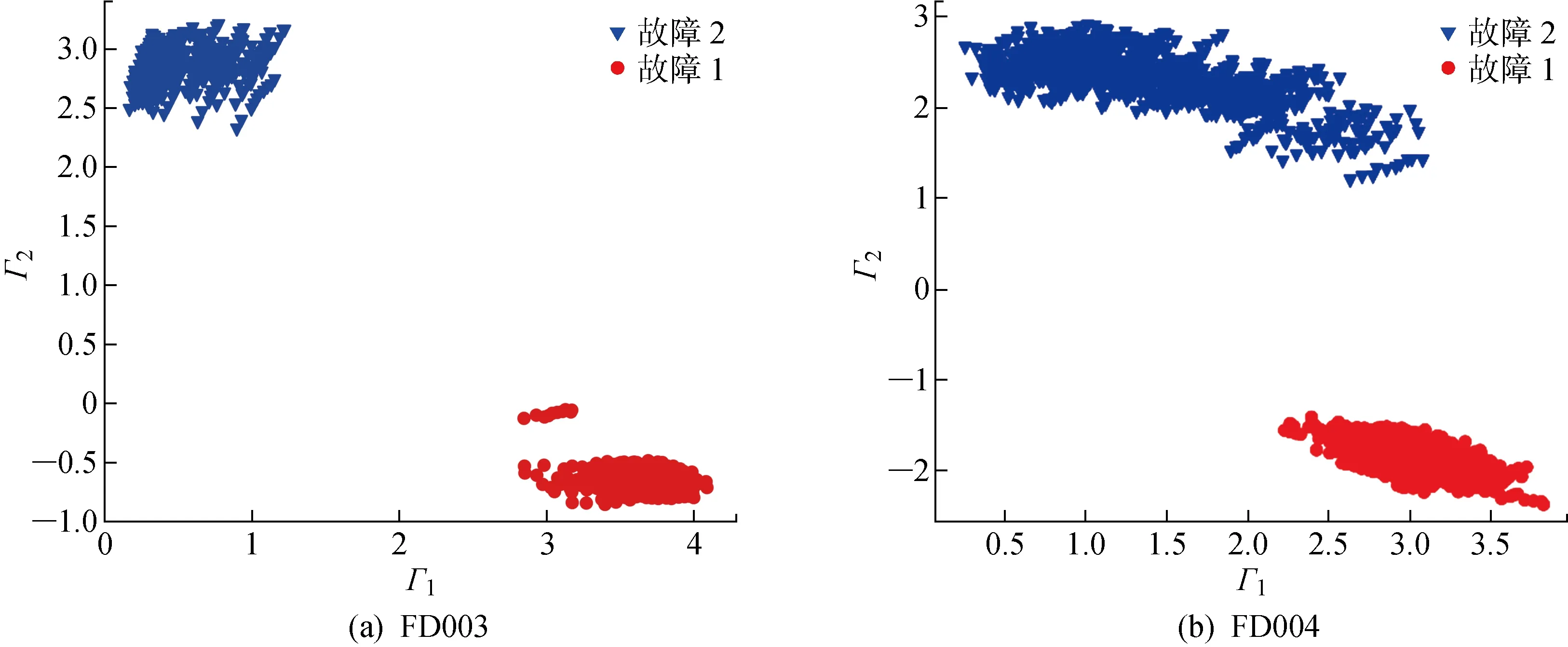
在多故障模式识别中,首先需确定提取故障特征的维数.通过AE对训练数据的重构误差大小来判断特征向量是否包含足够的故障信息,同时考虑重构误差值与故障特征聚类复杂度,设定特征维数为2.因此,AE编码器与解码器之间的隐含层2神经元数目设置为2,网络其他参数与HI建立模型相同,使用训练单元全寿命周期的数据对网络进行训练.为确保发动机已出现明显故障,仅选择每个训练单元最后10个运行周期的特征用于聚类分析,训练集的聚类效果如图6所示, 其中:和分别为提取的故障特征1与故障特征2.由图6可知,在FD003与FD004中两类故障均有显著差异,表明故障特征提取与聚类方法具有较好的泛化性.
在保证发动机正常运行的情况下尽量增加训练数据样本,本文选择各训练单元总寿命周期中前20%的状态监测数据用于训练HI建立模型.模型参数如表2所示.输入层与输出层神经元数量均设置为所选信号的数量.为增强模型的非线性映射能力,采用3个全连接层为隐含层.其中,隐含层1与隐含层3均采用 ReLU激励函数,有助于实现网络的稀疏连接.考虑到归一化的信号数据范围是 [0, 1],输出层采用tanh激励函数对数据进行规范化处理.模型训练时批尺寸设为128,最大训练周期数设为30,采用自适应矩估计算法作为优化器.设定平滑因子为20,对AE模型的重构误差进行平滑化处理,以生成最终的HI.
(3) 多尺度匹配.
鉴于研究内容具有极强的专业性及发表文章语言的局限性,为使更多的国内读者及时了解竹藤研究前沿进展,本刊将及时跟踪GABR成果,对原文内容进行精简、提炼,以中文形式呈现给读者。本期介绍全球首次报道的棕榈藤基因组的情况。
数据集运行周期数分布如图7所示,其中:为概率密度.由图7与表1可知,训练集与测试集退化轨迹长度间均存在较大差异,这也意味着涡扇发动机的退化速度各不相同.因此,本文针对FD003与FD004分别设计了一个时间尺度集合.为充分利用退化数据信息,将最小尺度设置为测试发动机的最小运行周期数.此外,考虑到过长的轨迹片段将包含过多无用信息干扰匹配,最大尺度应小于100.为避免尺度过多导致匹配时间过长,最终选择间隔为20的4个时间尺度构成集合.将测试单元按轨迹长度分成四个组别,使用不同数量的时间尺度进行匹配,具体信息如表3所示.


(4) RUL分布预测.
第一个办法就是在饮食上做出改变。每一样食物在体内的消化速度是不一样的,有些食物很快被消化,短时间内就能为身体提供能量。像富含蛋白质和纤维的食物就有助于加快新陈代谢。
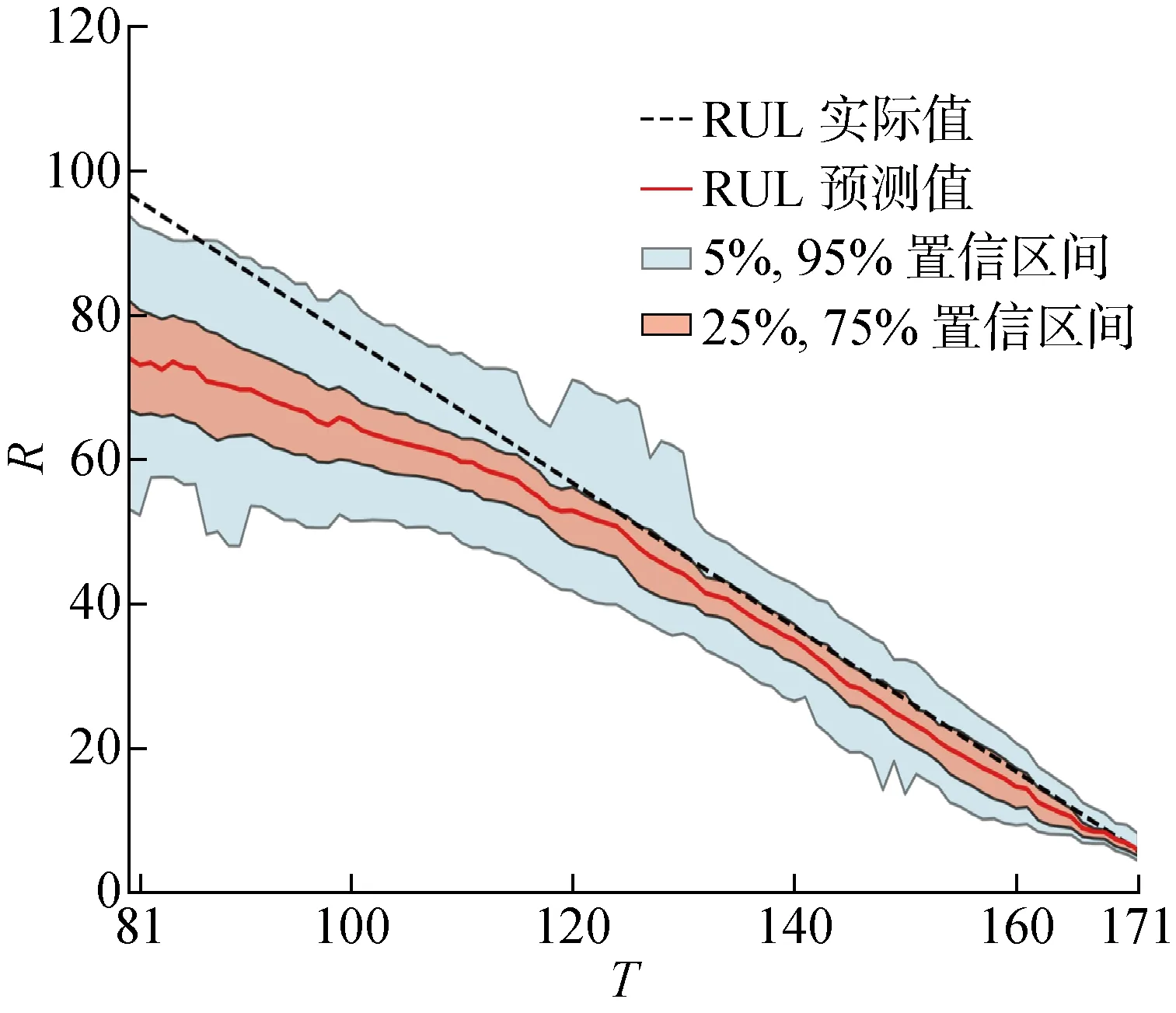
完成多尺度匹配后,设定松弛因子为1.5来选择用于RUL预测的相似参考轨迹.最终,采用带宽为0.7的高斯核密度估计器,集成多尺度预测结果,拟合RUL的概率分布,如图8所示.由图8可知,随着运行周期的增加,RUL预测值越来越接近于真实值,且置信区间在逐渐缩小,证明了MFM-MSEN方法的有效性.
预设N=20,M=3,L=6,图2和图3分别为随机选取单个SU的信道和功率策略概率演化过程.从图中可以看出经过200次迭代后,用户信道选择概率向量由初始值{1/3,1/3,1/3}最终收敛到{0,0,1},并维持恒定不变.同时用户在6个功率等级上的选择概率也同样的表现,结论与定理1和定理2相符.
3、棚温控制:下种后棚温白天保持在30~35℃之间,夜间保持在15℃以上,注意下种后棚内温度不能超过38℃以上,因为达到40℃高温时,种子不利于发芽。根据实践经验,幼苗出土后,如果温度超过26℃时,下胚轴会急速伸长,而形成高脚苗,所以幼苗拱土后,白天棚内温度降到25~22℃之间,特别要注意的是此时晚间棚内温度不能超过10℃以上,不能低于5℃,控制夜间苗不生长,棚内高温、高湿会导致幼苗徒长。第一片真叶见长后白天要适当加大棚内温度,温度白天保持在28~33℃之间,夜间5~10℃之间。真叶见长后喷一次“金元宝”液肥,可增加植株叶绿素含量及生根量,使幼苗生长旺盛健壮,提高幼苗抗寒能力。
5 结果分析与讨论
为消除自编码神经网络随机性的影响,本文取10次重复实验的结果,用于MFM-MSEN方法的效果验证.
5.1 预测结果
为更全面地评价预测性能,采用两个度量标准:均方根误差(RMSE)以及Score函数.Score函数针对RUL预测中高估RUL会带来更严重的损失这一特性,给予高估RUL更高的惩罚,Score函数及RMSE的计算公式如下:
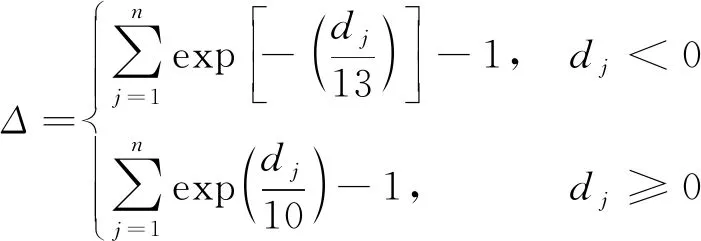
(19)

(20)

将车身摆放到合适的位置,展示其升级后的悬挂减震系统,是展示路虎卫士品质的好方式,滑板公园的坡道也非常适合展示这种定制改装的效果。
2.1.2 两种检测方法阳性与复发时间比较 骨髓形态学检测复发的5份AML标本中有1份在提前于形态学3个月发现MRD阳性,另外4份同时发现MRD阳性。骨髓形态学检测复发的4份ALL标本中有1份在提前于形态学1个月发现MRD阳性,另外3份同时发现MRD阳性。
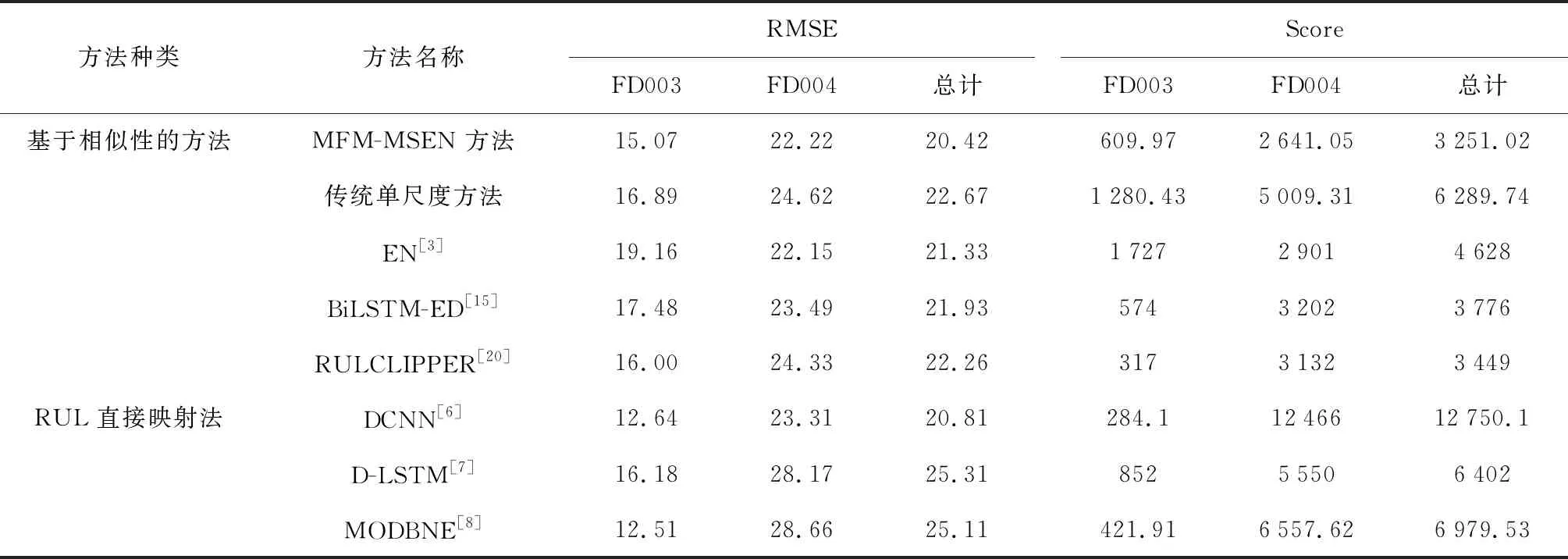
按照RUL标签从小到大的顺序,FD003测试单元的预测结果如图9所示,其中:为测试发动机按RUL标签从小到大顺序的编号.由图9可知,总体预测效果较好,RMSE值达到15.07.将MFM-MSEN方法与现有先进研究方法对比,结果如表4所示.由表4可知,MFM-MSEN方法的总计RMSE和Score值达到了所有预测方法中的最低.对于预测难度较高的子集FD004,可发现所提方法的RMSE值接近于所有预测方法中最优值,且Score值达到了所有方法中的最优,证明了MFM-MSEN方法在复杂工况数据集上的优越性.其次,MFM-MSEN方法在FD003上也取得了不错效果,RMSE值优于其他相似性方法,表明该方法具有较好的泛化能力.
此外,将传统单尺度方法与所提方法进行比较,传统方法中采用测试单元最小运行周期数作为匹配时间尺度.由表4可发现,MFM-MSEN方法显著提升了预测精度,进一步证明了故障模式识别与MSEN策略的有效性.

5.2 故障识别效应分析
为探究故障识别对预测效果的影响,将MFM-MSEN方法与未经故障分类的MSEN方法进行比较,结果如表5所示.其中,提升比率:

(21)
式中:与分别为对应方法的评价指标值.由表5可知,在两个子集上,MFM-MSEN的RMSE与Score值均显著低于MSEN方法,尤其对于FD003,Score值降低高达51.1%.这是由于故障模式相同的发动机单元退化过程通常更为相似,按照故障模式进行分类匹配有助于提高匹配准确性.此外,分类匹配可有效缩小匹配规模与计算量,并且发动机数量越多,匹配规模缩小量越大.因此,MFM-MSEN方法显著缩短了匹配时间,特别是对于发动机数量较多的FD004,时间缩短接近6 min.

5.3 多尺度集成策略效应分析
设定测试单元最小运行周期数作为单一匹配尺度,面向多故障模式的单尺度(MFM)方法与MFM-MSEN方法的对比结果如图10所示.在两个子集上,MFM-MSEN方法的RMSE值均低于MFM方法.这证明了MSEN策略的优越性,可有效解决单尺度方法造成的退化数据利用率低的问题.

为进一步探究集成策略的必要性,将测试单元按轨迹长度分成4个组别,各组别在不同匹配尺度下的预测结果如图11所示.可发现各组别最优尺度并不一定是最大或最小尺度,这意味着无法根据轨迹长度直接判断出最优尺度.而通过集成策略将多个尺度的预测结果结合,可有效避免最优尺度选择困难的问题.并且在所有测试组别上,多尺度预测的RMSE值均低于或接近最优单尺度.综上,MSEN策略有效提高了预测泛化性能与精度.

6 结语
考虑到设备故障模式多样性、退化速度差异性以及可提供数据长度的不一致性,本文提出了MFM-MSEN寿命预测方法.在该方法中,通过故障特征提取与故障聚类等实现故障分类模型的训练,并设计时序加权预测策略来识别测试设备故障模式,以进行分类匹配,提高预测精度的同时降低了匹配的计算复杂度.此外,该方法提出MSEN策略实现了多尺度相似性匹配,并采用KDE法集成多尺度结果拟合概率分布,有效提高了数据利用率与预测泛化性能,且能提供RUL置信区间.在CMAPSS数据集上验证方法的效果,相较于现有其他先进方法,MFM-MSEN方法总体上取得了最高的精度,效应分析也进一步证明了故障识别与MSEN策略的优越性.未来将采用更多复杂数据集验证预测方法的泛化性,并设计相关实验以量化其鲁棒性.此外,可优化多尺度预测结果集成时权重的设置机制,以进一步提升预测性能.