
基于实体共现与引用的潜在共病关系发现*
2022-06-06 09:54关陟昊单治易林紫洛杨雪梅唐小利
医学信息学杂志 2022年4期
关陟昊 单治易 林紫洛 杨雪梅 唐小利
(中国医学科学院/北京协和医学院医学信息研究所 北京 100020)
1 引言
我国是世界上老年人口最多的国家,老年与共病密切相关,60岁以上居民中有75.8%被1种以上慢性病困扰[1]。共病与日益增加的不良健康结果相关,如死亡率高、残疾、生活质量差、住院以及医疗资源和支出增加[2]。疾病防治重在预防,我国大力推进的健康中国战略核心在于“治未病”这一预防理念。如果能够发现疾病共患的关联规律、预测潜在的共病关系,对临床诊疗方案有效制定和国家医疗资源合理配置具有参考意义。
2 研究现状
2.1 概述
共病这一概念最早由美国Feinstein A R提出,英文表达形式为“comorbidity”,是指患有所研究的某种索引疾病的患者同时还伴发其他疾病[3]。本研究中所指共病为多种疾病同时发生在同一机体内的现象,包括并发症、合并症和继发症等。目前国内外关于共病的医学研究主要分为两个方向,分别是共病模式研究和共病预测研究。医学领域的“疾病关联”多指疾病与病因的关联,包括:宿主病因,即基因、蛋白、通路等组学角度的病因[4-5];环境病因,即社会、物理、化学等流行病学角度病因[6]。因此相比于“疾病关联”,“共病”一词更适合描述疾病之间的关联关系。
2.2 共病模式研究
共病模式研究目的是了解调查人群的共病患病现状,挖掘常见高发共病组合或共现关系较强的疾病诊断集群[7]。共病模式研究较为成熟,但多基于共现和统计分析思想,提取、描述能力较强,预测能力较弱,研究重点在于挖掘常见疾病之间关联关系、发现高频疾病组合,以达到疾病预警、共病防治的目的。
2.3 共病预测研究
2.3.1 研究策略 随着自然语言处理和网络分析技术发展,共病预测正在成为共病研究中重要研究方向。目前国内外已有大量关于共病预测的相关研究成果,研究策略主要包括以下3个方面。一是从生物信息学角度:基于高通量基因组学、蛋白组学数据,利用生物信息学方法,从基因表达角度计量疾病间关联关系,进而预测可能共现的疾病[8]。二是从临床医学角度:基于电子病历数据,提取疾病共现关系,根据疾病在真实世界中的共现频次和关联网络特点预测未出现的并发疾病[9]。三是从情报学角度:基于临床病例构建共病网络,适用于挖掘发病率较高的常见病共病关系[10-11],但对于发病率非常低的罕见病,可能不会在所研究的临床病例样本中出现,也可能被多次误诊[12]。解决上述问题的方法之一是使用严谨准确的科学文献数据,生物医学文献包含科研人员对疾病的明确表述。
2.3.2 基于知识网络的相关研究 大量的文献集聚使研究内容彼此之间的关系呈现为一种高度复杂性的网络,研究人员可以通过知识网络对相关隐性知识进行挖掘[13]。Xu R、Li L和Wang Q[14]将两个疾病概念在同一个句子中的共现视为具有共患风险的疾病对,通过提取疾病概念对建立疾病风险网络,该数据集随后被一些学者[15-16]用于共病网络研究,这说明基于语义模型提取共病关系是可行的。但是从文本挖掘角度来说,共现关系并不能完整体现概念间基于文献建立的关联,因为概念除了在同一篇文章中共同存在,还会通过文献间引用建立关联,被称为实体计量学。Song M、Kang K和An J Y[17]对比基于共现和基于引用构建的实体关联网络,提出基于引用关系构造的网络能够发现更为多样但链接关系较弱的关联,而利用基于共现关系构造的网络可以得到更高准确率。由此可知在实体关联网络的构造过程中,基于引用提取的关系偏重于“全”,基于共现提取的关系偏重于“准”,将二者融合起来可能会达到“全”和“准”的平衡。国内外已有基于单一关系(共现或是引用)进行潜在关系发现的研究成果,并没有将二者结合的先例。
2.3.3 链路预测 其作为分析复杂网络的有效手段,是指如何通过已知网络节点以及网络结构等信息,预测网络中尚未产生连边的两个节点之间产生连接的可能性,在共病预测领域已有广泛应用,但都局限于从共现层面提取共病关系,忽略了实体间通过引用行为建立的关联。
2.3.4 创新研究路径 为解决以上问题,本研究探讨将共现与引用关系相结合的潜在共病关系发现方法。以糖尿病领域为例,通过时间切片方法说明所提方法的优越性,并对该领域的共病组合进行预测,提出未来可能的共病组合,结合相关文献分析疾病间有可能发生关联的途径。
3 方法论
3.1 概述
本研究选用文献数据作为研究对象,基于语义模型和实体计量学提取共病关系构建共病网络,利用链路预测算法计算网络结构特征指标,选取预测效果最好的指标进行共病关系的预测。本研究设计4个步骤:数据收集、共病关系提取、共病网络构建以及共病关系预测,见图1。
3.2 数据收集
PubMed数据库是美国国立医学图书馆(National Library of Medicine,NLM)开发的免费文献检索系统,提供生物医学文摘信息及相关数据链接。本研究旨在发现可以为临床诊疗与疾病预防提供参考的共病组合,因此选取数据库中时效性较强的文献类型。Colil数据库是日本学者基于PubMed Central Open Access Subset(PMC-OAS)全文本构建的生物医学领域引用语句数据库[18],本研究选取Colil数据库获取文献对应的施引语句。
3.3 共病关系提取
3.3.1 主谓宾(Subject-Predicates-Object,SPO)结构提取 使用SemRep工具提取文献摘要中的共病对,SemRep是NLM基于统一医学语言系统(Unified Medical Language System,UMLS)开发的从生物医学文本中抽取语义三元组的工具,这个三元组被称为语义谓词。语义谓词由主语、宾语和它们之间的关系组成,形成SPO三元组。利用SemRep工具从下载的MEDLINE摘要数据中抽取语义三元组,通过限制实体类型为“dsyn”(疾病或综合征);限制语义类型为“COMPLICATES”(并发)、“ASSOCIATED_WITH”(与…相关联)、“CAUSES”(引起)、“AFFECTS”(影响)、“PREDISPOSES”(诱发)、“MANIFESTATION_OF”(现象表达)、“PRECEDES”(先于…发生)、“COEXISTS_WITH”(与…同时发生)可以筛选出具有共病关系的疾病对[14]。
3.3.2 引用语句实体提取 MetaMap是NLM开发的医学实体抽取工具,可以将生物医学文本与UMLS叙词表中的概念匹配起来。使用MetaMap工具识别施引语句中的医学实体,通过限制实体类型为疾病或综合征(disease or syndrome)可以筛选出施引语句中所包含的疾病实体。例如PMID为33450530的文献的施引语句中包含的疾病实体为“Diabetes Mellitus”,假设该篇文献摘要中包含的疾病实体为“Ketoacidosis”和“Asthma”,那么基于引用关系建立的共病对为“Diabetes Mellitus-Ketoacidosis”和“Diabetes Mellitus-Asthma”。
3.4 共病网络构建
对抽取出的共病关系进行数据清洗,首先排除Disease、Syndrome、Disorder等无意义的泛指概念[19]。同一种疾病可能有不同表达方式,例如妊娠性糖尿病可能被表达为gestational diabetes或diabetes during pregnant。因此要对提取出的疾病概念做消歧处理。具体而言是将实体列表导入德温特数据分析平台(Derwent Data Analyzer,DDA)通过人工建立叙词表的方式完成清洗工作。对基于共现的共病关系和基于引用的共病关系做取并集处理,得到完整共病网络。
3.5 共病关系预测


表1 链路预测指标及计算公式
3.5.2 模型评价指标 AUC是常用的准确性评估指标,表示预测的正例排S在负例前面的概率[21],选取AUC作为模型评价的指标。
3.5.3 预测方法有效性验证 由于共病网络形成是具有时序性的,因此预测方法的有效性可通过时间切片方法进行验证,即将第1年至第n-1年数据作为训练集,第n年的数据作为测试集。为比较基于共现关系的方法、基于引用关系的方法和本研究所提出的方法在预测新共病关系方面的性能差异,分别对这3种方法对应的共病网络进行链路预测并用AUC评估模型的预测性能。
4 糖尿病领域实证
4.1 数据收集
从两个维度收集数据,一是获取2016-2020年PubMed数据库中糖尿病相关文献,二是通过Colil数据库获取这些文献的引用语句。在PubMed中检索糖尿病相关文献,时间限定为2016-2020年,共收集到213 199篇文献和对应的1 024 427条引用语句。
4.2 共病网络对比分析
基于引用关系提取的唯一疾病实体数量大约是基于共现关系提取的唯一疾病实体数量的5倍,二者交集占前者的4%、占后者的23%。在共病对数量方面,两种方法提取出的重复疾病对数量为40对,占基于共现方法提取数量的3%,占基于引用方法提取数量的2‰,可以看出仅基于共现或基于引文不能获取完整的共病网络,这说明将二者结合是有意义的,见表2、图2。
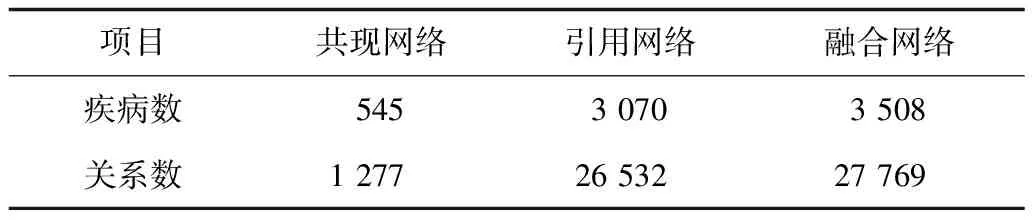
表2 基于共现、基于引用和融合后网络的疾病和关系数量
4.3 指标分析
各项指标均大于0.5,说明在糖尿病的共病网络中边不是随机产生的,可以利用链路预测算法对未来共病网络进行预测。整合后的网络在各项预测指标上总体优于仅基于共现和仅基于引用构建的网络,说明整合后的网络能够很好地描述糖尿病领域的共病现象,将二者结合是有意义的。其中基于随机游走的Cos指标预测效果最好,见表3。因此利用基于随机游走的Cos指标对全部数据进行预测,列出了相似度最高的前10条边,即最有可能产生连边的疾病对,见表4。

表3 链路预测各指标的AUC值
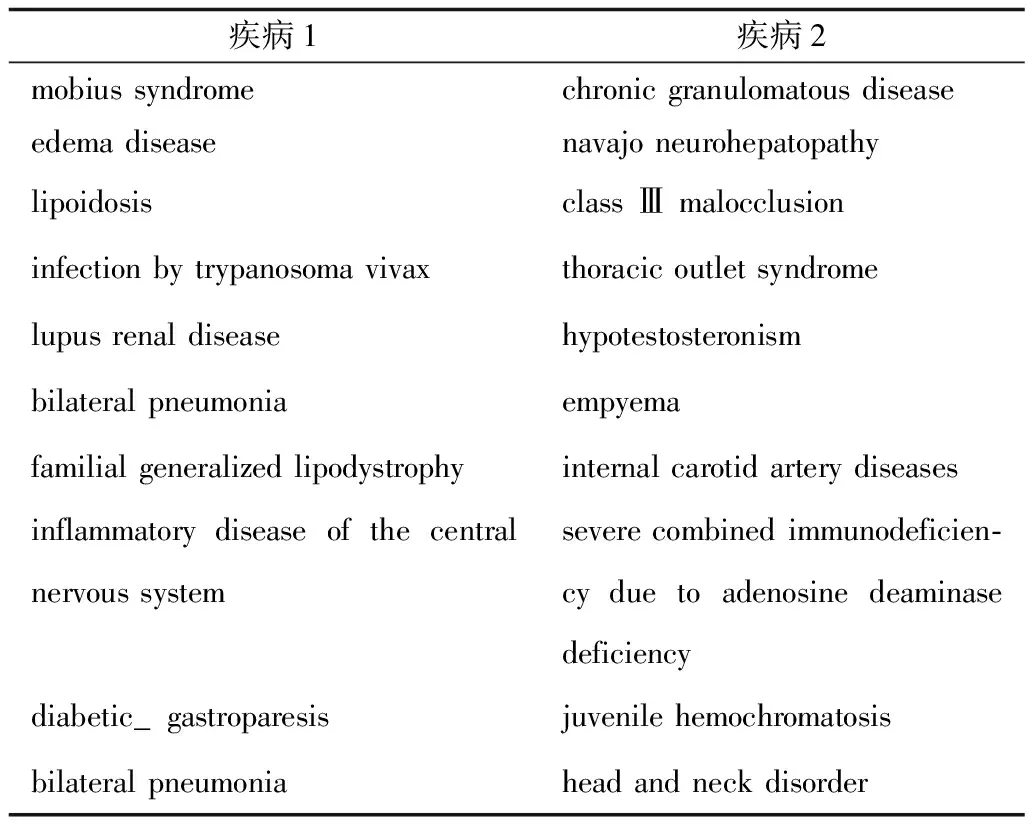
表4 相似度最高的前10个疾病对
4.4 预测出的共病关系的科学性验证
通过查找表中所列疾病的相关文献进行分析,发现疾病对之间的发病机制存在关联。针对部分疾病组合进行解读和说明。mobius syndrome-chronic granulomatous disease:Mobius综合征是一种罕见的出生缺陷[22],其致病基因之一与B细胞的存活有关[23]。慢性肉芽肿是一类基因突变引起的免疫缺陷病[24]。这两种疾病均在患者幼年起病,影响免疫系统正常功能。edema disease-navajo neurohepatopathy:纳瓦霍神经肝病多发于严重金属污染地区[25],而体内累积过多重金属会对神经、血液、消化等系统造成损害,水肿可能这些基础疾病的结果。这两种疾病的发病可能都与患者居住环境有关。lipoidosis-class Ⅲ malocclusion:类脂蛋白沉积症是指透明蛋白样物质沉积在皮肤、黏膜及内脏而引起的疾病,牙齿发育异常是常见的并发症[26]。三类牙错合是颌骨大小与牙齿大小不成比例的临床表征之一。二者均在幼年发病并进行性发展,到患者成年时期自然静止,且都与口腔黏膜异常有关。lupus renal disease-hypotestosteronism:狼疮性肾病患者体内的促炎细胞因子升高会影响脂类代谢,这是低胆固醇血症的病因之一[27]。狼疮性肾病和低胆固醇血症均与细菌、病毒感染以及免疫系统的异常炎性反应有关。综上疾病间可能通过症状、生活环境、发病时期等途径产生关联。疾病之间的关联并非偶然,患者当前所患疾病可能是另一种疾病的危险因素,发现共病的共同机制对疾病的早期干预和防控措施制定具有一定意义。
5 结语
本研究利用实体提取技术和复杂网络分析方法,从生物医学文献中提取疾病实体并根据语义和引用关系构建共病对,融合实体共现与引用关系,构建共病网络,运用链路预测方法对潜在疾病组合进行预测,为疾病的病因、病理、治疗等方面研究提供新的参考方向。研究不足之处在于:受链路预测算法限制,只能预测网络中已有节点间的新链接,不能预测网络中尚未出现的节点间的链接;受科研条件和专业知识的限制,仅能通过已发表的文献解释潜在疾病组合间产生关联的可能途径,未能通过一定实验手段进行验证。
猜你喜欢
医学与社会(2022年10期)2022-11-10
火力与指挥控制(2022年8期)2022-09-16
网络安全与数据管理(2022年6期)2022-07-13
健康护理(2022年5期)2022-05-26
昆明医科大学学报(2021年12期)2021-12-30
移动通信(2021年5期)2021-10-25
中华老年多器官疾病杂志(2021年1期)2021-01-25
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
科技创新导报(2016年27期)2017-03-14
