
基于机器学习的儿科急诊患者候诊时间预测及关联分析研究*
2022-06-06 09:54郭琳琳魏永祥郭琳瑛
医学信息学杂志 2022年4期
郭琳琳 魏永祥 郭琳瑛 李 姣 郑 思
(首都儿科研究所附属儿童医院 北京 100020) (中国医学科学院/北京协和医学院医学信息研究所 北京 100020)
崔 英 陈 宇
(首都儿科研究所附属儿童医院 北京 100020)
1 引言
儿科急诊患儿候诊时间长是医患关系的主要矛盾点之一。患儿就医往往由2~3名成人陪同,拥挤的环境和焦躁的候诊情绪不仅降低患者就医体验,也增加急诊科医护人员的职业紧张[1]。医院所采取的优化就医流程相关措施,如增加预检分诊护士和看诊医生排班等,根据管理者经验判断实施,无法科学、精准地预测患者候诊时间,动态调配医疗资源。患者候诊、就诊时间是衡量急诊科效率、评估当前拥挤状态的最常用指标[2]。评估患者候诊时间有利于医院管理人员合理分配医疗资源,使急诊患儿及时得到救治,避免拥挤聚集情况出现。因此患者候诊时间预测是缓解急诊科拥挤状况的重要方法和手段。当前针对儿科急诊患者候诊时间预测的相关研究较少。本研究以首都儿科研究所附属儿童医院2021年1-6月共95 875条数据为基础,提出一套基于机器学习的患者候诊时间预测模型的标准构建流程,包括原始数据提取、异常值检测、候诊时间相关变量设计及提取、描述性统计分析、机器学习模型构建、模型评价及特征重要性分析。
2 研究现状
2.1 基于量表评分的方法
目前评估医院拥挤程度的主流方法。该方法通过预定义一组与医院医疗资源和患者情况相关的变量集合,使用加权求和的方法计算拥挤程度分级。国家急诊科过度拥挤研究(National Emergency Department Overcrowding Study,NEDOCS)评分系统被广泛应用于评估急诊科拥挤程度,该评分系统包含23个指标并通过计算给出拥挤程度评估结果,最初研究在两个医院中取得0.49的决定系数[3]。严重过度拥挤-过度拥挤-未过度拥挤(Severely overcrowded-Overcrowded-Not overcrowded Estimation Tool,SONET)是用于评估急诊科过度拥挤程度的工具,SONET考虑当前急诊科中不同危重分级、状态的患者人数并加权计算得出拥挤度评分,结果显示该评分优于广泛使用的NEDOCS评分[4]。然而该方法预测性能受限,仅能给出当前医院的拥挤程度,无法计算具体等待时间预测结果。
2.2 基于离散事件模拟的方法
将患者就诊问题转换为排队问题,使用仿真软件模拟排队行为,从而进行等待时间预测。Hung G R、Whitehouse S R和O'neill C等[5]使用离散时间建模软件构建患者流动模型用于模拟儿科急诊科的人员配置场景,结果表明该模型响应人员配置变化并对等待时间预测结果做出相应改变;Connelly L G和 Bair A E[6]使用Extend DES建模软件模拟急诊科活动模型,通过输入医疗人员配备水平、设施特征、患者数据、账单记录等信息预测患者平均等待时间,结果表明58%患者的绝对误差小于3小时。然而,该方法较为复杂,需要较多历史数据验证仿真模型,同时需要设置较多参数以近似真实情况。
2.3 基于机器学习的方法
根据患者就诊时间相关变量,采用线性回归、决策树等机器学习算法对其进行建模并预测具体的候诊时间。该方法的核心是构建合适且相关的患者变量。Kuo Y H、Chan N B和Leung J M Y等[7]使用两组变量集合和4种机器学习模型构建急诊科候诊时间预测模型,其中最优模型在测试集上的决定系数为0.429;Sun Y、Teow K L和 Heng B H等[8]使用分位数回归算法构建急诊科患者候诊时间预测模型,在中位候诊时间为17分钟的数据集中模型预测绝对误差小于20分钟;Pak A、Gannon B和 Staib A[9]使用4种回归算法和随机森林模型用于急诊科候诊时间预测,结果表明机器学习算法优于简单的滚动平均方法。何跃、邓唯茹和刘司寰[10]使用3种决策树组合BP神经网络构建急诊等待时间预测模型,但是该方法缺少变量与等待时间相关性的进一步探究。刘翠、王巍和代伟等[11]使用人工神经网络构建超声科患者排队时间预测模型,发现患者排队时间的变化规律。通过医院工作流程的精细化管理和医疗资源的合理分配来缩短患者就诊时间,可以提高患者满意度[12-13]。结合本院数据和有关研究的样本[9]发现,来源于不同地区的不同人群的急诊患者候诊时间数据会存在一定差异,因此需要选取合适的机器学习模型来进行研究。
3 资料与方法
3.1 数据来源
本院2021年1-6月共95 875条急诊患者就诊数据,包括患者性别、年龄、医生工资号、就诊分区、取号时间、首诊时间、首诊名称、首次医嘱时间、末次医嘱时间、是否有辅助检查(检验、检查等)及是否开药。
3.2 数据预处理
对原始数据进行数据清洗、加工处理,以得到适合候诊时间预测建模的数据。本研究主要采用以下3条数据清洗规则:去除缺失急诊分区信息的样本数据;去除候诊时间小于0(首诊时间到取号时间小于0分钟)或者年龄大于18周岁的错误样本数据;去除总就诊时间异常(末次医嘱时间到取号时间大于2天)和候诊时间异常(首诊时间到取号时间大于480分钟)的样本数据。经过数据清洗后,最终得到90 573条样本数据用于后续分析,见图1。
3.3 描述性分析和特征提取
对预处理后的样本数据进行描述性统计分析,以发现不同临床亚群患者相关特征,辅助指导构建等待时间预测建模相关变量设计。此外通过绘制就诊人数、患者平均候诊时间等随时间变化的趋势图,帮助医院管理人员了解就诊人数和急诊科拥挤程度在不同时间段的变化模式并以此实施相应决策。对于特征提取方面,根据先前研究[7,9],本研究设计并提取19个变量用于候诊时间预测模型构建,见表1。

表1 变量描述
3.4 基于机器学习的候诊时间预测模型构建
使用线性回归(Linear Regression,LR),回归模型(Least Absolute Shrinkage and Selection Operator,LASSO),K最近邻(K-Nearest Neighbor,KNN),随机森林(Random Forest,RF),极端梯度森林[14](eXtreme Gradient Boosting,XGBoost)及LightGBM[15]共6种机器学习算法构建候诊时间预测模型。LR是一种利用最小二乘法将多个自变量逼近拟合因变量的回归分析算法,可以简易地表示为y=β0+β1x1+β2x2+β3x3+…+βkxk+ε。LASSO是一种在LR的基础上进行改进的方法,其在最小二乘法中引入L1惩罚项以压缩数据空间维度,从而实现参数估计和变量选择。KNN是一种在样本空间上寻找K个最近邻样本作为待预测样本的估计,并计算近邻样本标签均值作为预测值的算法。RF是一种包含多个决策树的集成机器学习算法。其使用Bootstrap方法从训练集中有放回地抽样,并对其中每个样本随机选择一定数量特征构建多个决策树,最后在预测阶段将所有决策树预测结果的平均值作为最终预测结果。XGBoost是一种基于梯度提升决策树的增强算法。其在训练时使用贪婪策略,在每次迭代时都学习一个决策树用于预测上一个决策树预测值与真实值的残差;同时,其将二阶泰勒公式展开引入损失函数以提高精确度,并利用正则项简化模型。LightGBM是一种基于梯度提升决策树的增强算法。其采用单边梯度采样、互斥特征捆绑、受限决策树生长策略等方法降低模型复杂度,加速模型训练速度的同时使模型精确度保持稳定。
3.5 实验参数设置
首先对6种机器学习模型进行超参数网格搜索,以确定每种机器学习模型的最优超参数,见表2。采用10折交叉验证用于评估模型表现,设置10个随机种子以重复实验,给出模型表现的平均值。对于模型表现结果,采用决定系数R2,平均绝对误差(Mean Absolute Error,MAE),平均绝对百分误差(Mean Absolute Percentage Error,MAPE),均方根误差(Root Mean Square Error,RMSE)作为评价指标,计算方法为:

表2 机器学习模型超参数
(1)
(2)
(3)
(4)
4 结果
4.1 儿科急诊拥挤程度描述性统计
首先对90 573条样本数据的关键信息进行描述性统计。可知绿区占总就诊人数最多,而红区、黄区患者较少。由于就诊分区为红区的患者病情最危重,在实际情况中均为立即就诊,因此不需要对其进行候诊时间预测,但由于其在一定程度上与黄区、绿区患者共同使用医疗资源,因此仍加入红区患者参与计算。此外夜班(20时~次日8时)中的平均就诊人数略多于白班(8时~20时),而夜班医生数略少于白班医生数。门诊小夜班结束后,病情较轻患者只能在急诊科就医,也会对急诊医疗资源产生一定程度消耗,见表3。
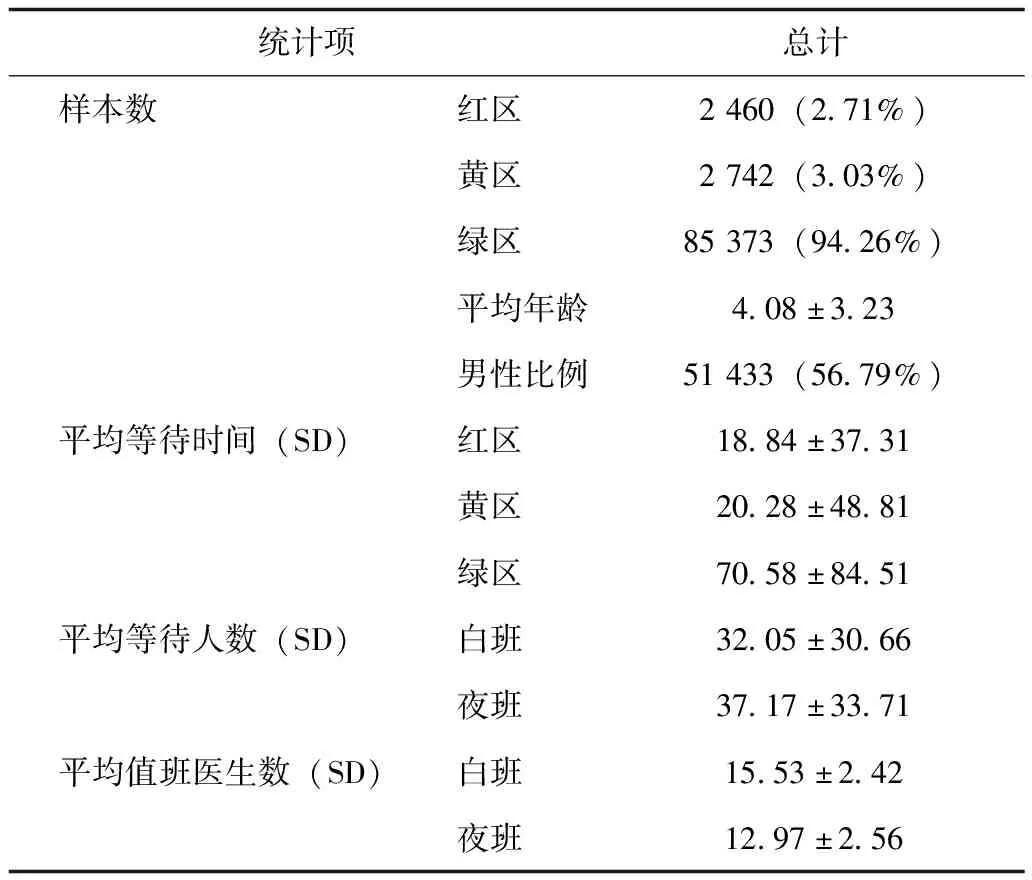
表3 患者就诊数据描述性统计
4.2 儿科急诊候诊时间趋势分析
根据2021年1-6月就诊数据进行时间趋势分析可知,急诊科拥挤程度(患者候诊时间)与就诊人数高度相关,在2021年1-3月,由于防疫政策、节假日、季节等因素影响,急诊科总体就诊人数较少,同时患者平均等待时间短(低于25分钟);之后随着防疫政策调整、人员流动较年初更加自由、学校开学、逐步入夏等原因,急诊科就诊人数上升,同时患者平均候诊时间也大幅上升,最高近3小时。由此可知不同时间段急诊科拥挤程度变化较大。为了最有效缓解该现象,需要根据患者候诊时间灵活实施加速就诊措施。因此患者候诊时间预测模型是为执行各种措施提供时间预估的重要手段。
4.3 就诊候诊时间预测模型表现
4.3.1 模型构建 使用LR、LASSO、KNN、RF、XGBoost、LightGBM构建基于机器学习的急诊患者候诊时间预测模型。所有模型的整体预测能力均较好,其中LightGBM取得最优的R2、MAE及RMSE,相对于作为基线水平的LR模型,LightGBM在3个指标上的提升分别为8.28%、9.54%和4.28%,模型表现优越,可以对不同状态下的患者提供较为准确的候诊时间预测,见表4。
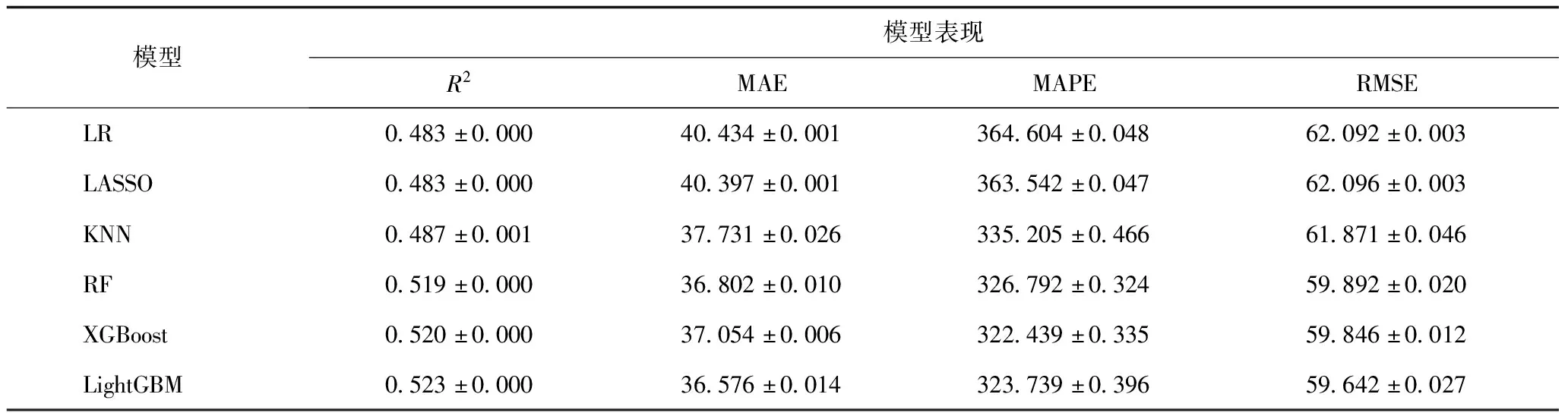
表4 机器学习模型表现结果(分钟)
4.3.2 6种机器学习模型在不同时间段的等待时间拟合能力分析 绘制24小时段绿区、黄区患者的平均候诊时间趋势图,观察结果可知急诊科患者平均候诊时间存在两个高峰,分别为8~12时、20~23时,该结果符合本院实际诊疗情况。此外6个机器学习模型均能较好拟合并预测该变化趋势,平均候诊时间的MAE分别为13.071、13.082、13.180、13.319、14.448、13.376。证明使用机器学习算法构建患者候诊时间预测模型的稳健性和准确性较好;同时LightGBM表现出最优的拟合效果,见图2。
4.3.3 不同分区患者平均等待时间预测分析 由于不同分区患者代表不同病情危重程度的临床人群,因此候诊时间预测模型需要区分不同分区患者以促进个性化诊疗实施。通过绘制不同分区患者平均候诊时间预测结果的时间趋势可知,虽然6种机器学习模型均能准确预测绿区患者的平均候诊时间变化,但LR、LASSO、KNN模型对于黄区患者几乎无预测能力,而3种决策树集成模型(RF、XGBoost、LightGBM)在黄区患者中仍有较为准确的预测能力。该结果表明在患者候诊时间预测中,复杂度较高的集成模型能够学习到罕见临床亚群信息,从而提供泛化性更好的预测,见图3。
4.4 特征重要性分析
使用6种机器学习模型中表现最优的LightGBM模型输出其特征重要性分数。观察结果可知,本研究设计的多个变量(wait.green、t.avg4h.green、arrivals.green等)在LightGBM模型中重要程度较高,而原始数据中的部分变量(doctor、triage、holiday等)对结果影响较小。以上结果反映了本研究设计的变量集合对患者等待时间预测模型构建的重要性;同时该结果也证明诊疗活动的历史信息能够用于预测当前及未来医院拥挤程度,从而辅助医院管理者决策,见图4。
5 结语
提高患者就诊效率和满意度是在儿科急诊诊疗活动中执行医疗资源管理、分配的重要目标。其中针对儿科急诊患者候诊时间进行预测是科学安排医疗资源以缓解急诊科拥挤程度的前提。本研究基于大规模患者就诊数据共构建6种不同机器学习模型用于儿科急诊就诊患者的候诊时间预测,最佳模型的决定系数(R-squared,R2)为0.523,预测模型表现良好,能够较为精准地预测急诊科患者候诊时间,同时精确拟合不同时间段下患者平均候诊时间,具备较高稳健性和泛化性。综上,该模型有助于医院管理者提前采取应对措施以合理分配医疗资源,缓解急诊科拥挤程度,改善医疗环境,提高患者满意度。本研究拟于下一步将该模型应用至本院急诊科并探讨其在其他诊疗科室的应用潜力,从而在真实场景下帮助医院管理者更高效、合理地实施资源动态调配。研究存在一定局限性。研究仅限于2021年6个月的样本数据,无法反映年度季节性趋势,如月份,对于候诊时间的影响。在未来的研究中将采用更加完整的年度样本数据以及考虑增加疾病诊断和治疗等临床因素,开展急诊候诊时间更深入的比较分析,使结果更加全面。
猜你喜欢
中国毕业后医学教育(2022年4期)2022-11-29
医院管理论坛(2022年8期)2022-10-14
中国药学药品知识仓库(2022年7期)2022-05-10
中国药学药品知识仓库(2021年18期)2021-02-28
商业评论(2020年3期)2020-06-15
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
视野(2015年14期)2015-07-28
读者(2015年12期)2015-06-19
决策与信息·下旬刊(2013年1期)2013-03-11
