
基于改进Multi-ResUnet算法的黏结集料图像分割方法
2022-06-06 14:21:26郝雪丽李玉峰裴莉莉
同济大学学报(自然科学版) 2022年5期
郝雪丽,李玉峰,裴莉莉,李 伟,石 丽,曹 磊
(1. 长安大学信息工程学院,陕西西安 710064;2. 安徽科力信息产业有限责任公司智能交通安徽省重点实验室,安徽合肥 230088)
集料在沥青路面中起关键性的骨架与填充作用,对于集料生产企业,传送带上集料粒径检测的准确与否对于集料的生产效率及生产质量的评价起着决定性作用[1]。然而,传送带上集料常常处于黏结状态。在集料图像分割时将黏结在一起的多颗集料识别为一颗,对后期集料自动分析中的级配与粒形判断造成较大影响。因此,实现黏结集料图像的自动分割对于道路路面施工与集料生产具有重要的实际应用价值[2-3]。对于单颗集料,在经过三维重构技术及噪声处理等预处理后,使用区域生长算法对集料三维图像进行分割[4]。裴莉莉等[5]提出基于反向神经网络的集料粒径快速检测方法,但该方法仅适用于非黏结状态下的集料粒径检测。传送带上集料普遍存在黏结现象,因此对黏结集料图像进行准确分割是开展后续分析的前提。
国内外学者对黏结集料图像分析进行了广泛研究,但黏结集料图像的分割效果还有待进一步提高[6]。Amankwah 等[7]将均值漂移与分水岭算法的融合算法作为图像分割模型对黏结集料图像进行分割。Malladi等[8]提出了一种基于形态学的超像素分割(SUM)算法,可对分水岭变换方法进行置换,以有效地分割复杂的块状岩石图像。Sulaiman 等[9]采用图像处理技术研究河床砂石集料粒径分布,获得了小质量样本的粒径统计信息。Xu 等[10]使用大津算法进行沥青灰度图像的分割处理,并采用最小二乘法对数据进行离散化,实现了对不同低温条件下沥青与集料之间的内聚力和黏合强度的定量分析。Wang 等[11]基于图像预处理方法分离矿石图像中的前景图像和背景图像,并采用自适应结构要素优化的分水岭算法实现了矿石图像分割。Li等[12]用标注的黏结矿石图像数据集训练整体嵌套边缘检测(HED)模型,通过HED模型提取具有较强鲁棒性的矿石图像边缘特征,再使用查表算法提取细化边缘,最终通过标记连通子块得到分割结果。满新耀等[13]使用工业电子计算机断层扫描仪(CT)对沥青试件和路面面层试件进行扫描,从黏结点数量、面积和角度3 个方面提取形态特征参数,用以表征沥青试件及面层试件内部集料的黏结特征。Rajan等[14]使用2种集料破碎机生产的4.75、9.50、12.50 mm 三档集料,通过集料图像测量系统(AIMS)测量集料尺寸,对2 种集料破碎机制进行综合评价。Ma 等[15]提出了一种基于卷积神经网络和数字图像处理技术的带状矿石图像分割算法,通过过程控制系统(PCS)采集矿石图像数据,从粗糙图像(CIS)与精细图像(FIS)两方面对矿石图像进行分割。
分水岭算法、自适应阈值分割算法、基于集料边缘的分割算法等虽然能够实现对黏结集料图像的基本分割,但是不能满足复杂环境下的精细分割需求。同时,这些算法还存在参数复杂度较高或需指定分割阈值等问题。因此,提出了Multi-ResUnet 模型,实现对黏结集料较为准确的分割。
1 Unet模型
1.1 Unet模型网络结构
Unet 模型是一种基于全卷积神经网络(FCN)的改进的网络模型[16],所需的训练集少且分割精度较高,较少的数据集就能实现对集料图像较为精确的分割。Unet 模型的U 型结构包括收缩路径与扩展路径两部分。收缩路径用来提取黏结集料图像中的语义信息,由编码器组成;扩展路径用来精确定位,由解码器组成。Unet 模型网络结构如图1所示。

图1 Unet模型网络结构Fig.1 Structure of Unet network
图1中,左侧为收缩路径,激活函数为修正线性单元(Relu),在收缩路径的每个编码器中编码后图像特征通道的数量均增加1 倍。右侧为扩展路径,在扩展路径的每个解码器中首先通过2×2的反卷积将特征通道的数量减半,之后通过跳层连接将反卷积的输出与对应层级采样的特征矩阵结合,最后再将结合后的特征图进行卷积计算。在网络结构的结尾采用全连接层(FC)将每个特征向量映射到输出层。
Unet模型通过数据增强应对可用训练数据集较少的情况,而数据增强主要通过随机弹性变形对训练样本进行增广,因此Unet模型不需要在图像标签集中应用随机弹性变形。对于集料形态的多样性以及相互遮挡情况下集料的复杂性,随机弹性变形可以有效模拟集料形态的真实变化,因此可将Unet模型应用于黏结集料图像分割。此外,Unet 模型网络结构使用加权loss 函数,可以给黏结集料背景部分的loss 函数赋以更大的权重,将复杂的黏结集料图像与背景准确分割,实现对图像中集料部分和背景部分的精确区分。
1.2 Unet模型分割黏结集料图像存在的问题
Unet 模型中,同一级别编码器和解码器通过跳层连接进行特征的融合,如在第1 次池化操作之前第1个跳层连接将编码器与最后一个反卷积操作之后的解码器桥接在一起,使网络能够将池化操作期间丢失的空间特征信息从收缩路径传播到扩展路径。然而,这种结构也有弊端。编码器提取的特征是在网络的较低层进行计算的,而解码器提取的特征是在网络的较深层中进行计算的,简单地合并2组特征可能会产生语义鸿沟,因此对来自底层网络结构的特征进行更多的处理来解决语义鸿沟问题。
Szegedy 等[17]在Inception 架构中引入Inception块,Inception 块利用并行变化的卷积核来提取不同比例图像中的特征信息,不同尺度下获得的特征信息可一起传递到更深层的网络中。
2 基于Multi-ResUnet 模型的黏结集料图像分割模型
集料形状通常是不规则的且尺寸大小也不尽相同。形状大致可分为角形、立方形、细长形、片形、细长片形和不规则形6 类[18-19],如图2 所示。在尺寸上粗集料有4.75、9.50、13.20、16.00 mm 四档,如图3所示。适用于黏结集料图像分割任务的网络应该能够应对不同情况下的集料对象,具有一定的鲁棒性和泛化能力。

图2 不同形状集料二值化图Fig.2 Binarization images of aggregates in different shapes

图3 不同尺寸集料二值化图Fig.3 Binarization images of aggregates in different sizes
2.1 基于Inception网络优化的Unet模型
Unet 模型的网络结构中,每个收缩路径的池化层和扩展路径的转置卷积层后都有2 个3×3 的卷积层,实际上类似于一个5×5 的卷积运算。基于Inception 网络思想,可以使用多分辨率分析功能增强来优化Unet 模型的网络结构。具体做法是将3×3、5×5 与7×7 卷积运算并行进行,从而使网络能够从不同比例的图像中学习到特征。Inception网络的计算原理如图4所示。

图4 Inception块计算原理示意图Fig.4 Schematic diagram of Inception block calculation principle
Multi-ResUnet模型使用一系列更轻量的3×3卷积块对更复杂的5×5和7×7卷积块进行分解重构,如图5所示。第2个和第3个3×3卷积块的输出等效于5×5和7×7的卷积运算,因此从3个卷积块中获取输出并将其串联在一起就可实现对Inception块的分解重构,从而使网络具备从不同尺度提取空间特征的能力。

图5 Inception块重构Fig.5 Inception block refactoring
在网络中加入一个残差连接可使网络能够学习到多个空间维度的特征,最终构建的网络结构如图6所示,将这种结构称为MultiRes块。

图6 MultiRes块Fig.6 MultiRes block
2.2 基于残差连接的Unet优化模型
通常,在深度学习中网络拓扑越深,可从图像中提取出的特征就越具代表性,但一味地增加网络深度也会导致梯度消失与梯度爆炸。使用残差学习替代原始数据学习可以有效地防止这个问题。一般情况下的残差结构如图7所示。
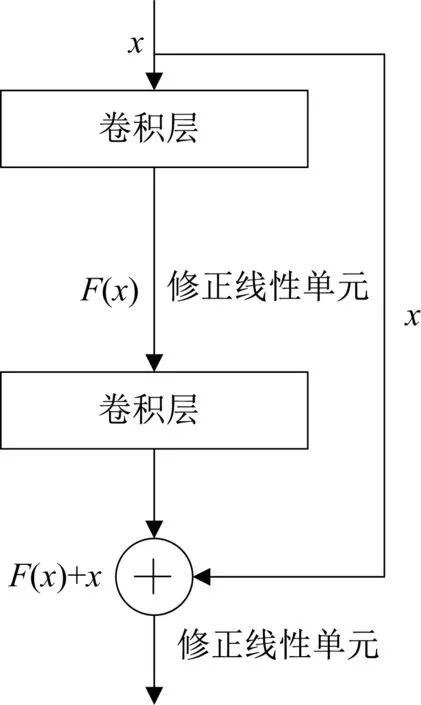
图7 残差结构示意图Fig.7 Schematic diagram of residual structure
图7中,x是残差结构的输入,F(x)是残差结构要学习到的残差,残差结构的输出结果为h(x),而h(x)=F(x)+x,在残差结构中把学习目标F(x)从h(x)转换为h(x)−x。
对于Unet模型中的语义鸿沟问题,可以在跳层连接中加入一些卷积层(即残差连接)以提高跳层连接前编码器提取特征的复杂度,在特征上附加的非线性变换能够在一定程度上平衡语义鸿沟。因此,残差连接可以使网络更加容易地学习到图像特征。残差连接结构如图8所示。
在图8中,卷积层的3×3过滤器与1×1过滤器组成了残差连接,将这种结构称为Res路径。

图8 残差连接Fig.8 Residual connection
2.3 基于Inception网络和残差连接的多形态Unet模型网络结构
采用Inception网络和残差连接对Unet模型进行优化,得到Multi-ResUnet模型,即将卷积层的2个卷积计算替换为基于Inception网络的MultiRes块,而Unet模型中的4个跳层连接被替换为基于残差结构的Res路径,Multi-ResUnet模型的网络结构如图9所示。

图9 Multi-ResUnet模型的网络结构Fig.9 Network structure of Multi-ResUnet model
图9中的网络结构同时保留了Inception网络与残差连接的优点,既可学习到不同尺寸的特征,又可避免梯度消失或爆炸,加快了网络学习的速度。在Unet模型中,编码器和解码器特征图间的语义鸿沟随着网络朝内部的快捷路径移动而减小。因此,在Multi-ResUnet模型的网络结构中也逐渐减少沿Res路径的卷积块数量,即沿着4个Res路径分别使用4、3、2、1个卷积块。另外,考虑到编码器-解码器中的特征图数量,分别在4个Res路径的块中使用32、64、128、256个滤波器。
表1 描述了Multi-ResUnet 模型网络结构的细节。除输出层外,该网络中所有卷积层均通过Relu激活函数激活,并进行批量标准化。类似于Unet模型,输出层由Sigmoid激活函数激活。

表1 Multi-ResUnet模型网络结构细节Tab.1 Details of Multi-ResUnet network structure
3 基于Multi-ResUnet 模型的黏结集料图像分割试验
3.1 试验平台
使用三维数据采集设备Gocator 3110 采集4.75、9.50、13.20、16.00 mm四档共2 550个黏结集料的三维点云图像,采集设备如图10所示。采集到黏结集料的三维点云数据后对其背景高度值进行去除以突出图像主体,并将集料图像的深度转换为灰度以得到二维黏结集料图像,图像的原始尺寸为576×832像素,图像数量为60张。在数据集中以5∶1的比例选择50张黏结集料图像作为训练集,10张作为测试集,并通过手工绘制集料颗粒的边缘轮廓制作标签集。图11为图像数据样本及其标签。

图10 黏结集料图像采集设备Fig.10 Image acquisition equipment for cohesive aggregates

图11 黏结集料图像样本及其标签示例Fig.11 Sample image and label example of cohesive aggregates
试验在Windows 10系统下进行,网络模型的架构通过基于TensorFlow 后台的Keras 环境实现,训练 环 境 的CPU 为Intel core i7-8700,GPU 为NVIDIA 2080Ti,RAM 为32 GB。网络超参数的设置为:根据图片尺寸选择的输入维度为(256,256),选择下降速度最快、效果最好的自适应矩估计(Adam)优化器,综合考虑模型的分割精度和显卡性能,选择每次训练的样本数(batch-size)为10,选取修正线性单元Relu作为激活函数(见图12),损失函数采用二元交叉熵损失。损失函数表达式如下所示:

图12 Relu激活函数Fig.12 Activation function Relu

式中:n为样本数量;yi为样本i的标签;P(y)为n个样本都为正的预测概率。
3.2 模型评价指标
从精确率(precision)、召回率(recall)和准确率(accuracy)3 个性能指标表达黏结集料图像分割精度,从而对模型性能进行客观评价[20]。将图像分割模型的输出二值图作为输出图,人工绘制的集料轮廓图作为标准图。3个评价指标的计算式如下所示:

式中:P表示精确率;R表示召回率;A表示准确率;T表示预测像素与真实像素均为1的像素点数;N表示预测像素为1但真实像素为0的像素点数;F表示预测像素为0但真实像素为1的像素点数;M表示预测像素与真实像素均为0的像素点数。
3.3 Multi-ResUnet模型训练
Multi-ResUnet 模型训练和测试过程中的损失函数曲线和准确率曲线如图13、14所示。

图13 损失函数曲线Fig.13 Loss function curve
从Multi-ResUnet模型的损失曲线可以看出,在训练后期模型达到了较为稳定的状态。由图14 可知,经过训练模型准确率也达到了一个较高的水平且趋于平稳,同时Multi-ResUnet模型在测试集上的准确率略高于训练集,表明模型并没有发生过拟合现象并具有较好的泛化性。

图14 准确率曲线Fig.14 Accuracy curve
batch-size 对模型的训练结果有重要影响,主要体现在每轮的训练时长和每次迭代的平滑度上,每轮迭代次数由全量样本和batch-size 决定。batchsize设置过小会导致迭代梯度不平滑,模型训练的损失值发生振荡,不利于模型的收敛。小的batch-size可以更好地获得个体差异性,因此具有更高的精度。batch-size 过大则容易陷入局部最优,不能准确地收敛于最小值,而且容易忽视数据中的个体差异性,使模型的训练精度下降。模型的学习率决定了寻找最优参数的快慢,较大的学习率使得网络训练的速度更快,但可能无法找到最优解,达不到最优效果。较小的学习率则会导致网络训练速度变慢,还可能使网络陷入局部最优解,找不到全局最优解。在模型训练中常常会出现过拟合和欠拟合的情况,训练轮数过小会导致模型训练欠拟合,得不到最优解,训练轮数过大则容易产生过拟合问题,在训练集上得到的模型无法在测试集上达到相近的测试效果,使模型的泛化能力变差。从图13、14 可以看到,训练轮数超过100后曲线基本不再变化。在进行多次参数调整后,获得了最优分割精度,设置batch-size为10,学习率为0.0167,训练轮数为100。
3.4 试验结果分析
为进一步验证Multi-ResUnet模型的性能,选取Unet 模型和基于形态学的分水岭算法在10 张测试集上进行对比试验,并通过精确率、召回率、准确率指标来评估分割效果,各模型的分割结果如图15所示。

图15 各模型分割结果Fig.15 Segmentation results of different models
从工程指标上分析,对测试集中的10张黏结集料图像进行了处理,共265颗集料,Multi-ResUnet模型可以将其中253 颗集料的边缘分割出来,准确率达到95.47%。基于形态学的分水岭算法可以将黏结集料与背景进行有效分割,但在分割时需对算法的开闭结构要素大小进行不断调整以找到最优值,而且易将黏结的多个集料分割为一个颗粒。从图15c可以看到,分水岭算法将黏结集料分割成了4块集料,效率较低。Unet 模型对黏结集料进行了较好的分割,但仍然存在集料边缘不连续与过分割的问题,如图15b 所示。为了更好地量化分割结果,3 种算法在10 张测试图片上的分割性能如表2 及图16所示。

表2 3种算法的性能指标Tab.2 Performance metrics of three algorithms

图16 各模型在测试集上的性能表现Fig.16 Performance of models on test set
由表2 及图16 可知,分水岭算法在3 种性能指标上均表现较差,而Multi-ResUnet 模型在3 种性能指标上均表现优异。Multi-ResUnet 模型相较于分水岭算法和Unet 模型,在精确率上分别提升了30.46%和2.11%,在召回率上分别提升了4.68%和1.85%,在准确率上分别提升了25.95% 和2.47%。在错误评价方面,虚警率=1−精确率,Multi-ResUnet模型虚警率均值为0.066 4,分水岭算法虚警率均值为0.371 0,Unet 模型虚警率均值为0.087 5。Multi-ResUnet 模型虚警率相比分水岭算法下降了30.46%,相比Unet 模型下降了2.11%。因此,Multi-ResUnet模型可显著优化分割结果。
4 结语
提出了基于Inception 块与残差连接优化的Multi-ResUnet 模型。采用Multi-ResUnet 模型对黏结集料图像进行分割,并与Unet模型和分水岭算法的分割结果进行对比。结果表明,Multi-ResUnet模型可以更加准确地将黏结集料的边缘进行分割,并且可以有效抑制集料边缘不连续与过分割。同时,Multi-ResUnet 模型在3 个性能指标上的表现也最优,分割精确率可以达到0.933 6,证明了该模型的优越性。
作者贡献声明:
郝雪丽:提出研究方案,设计论文框架,审阅论文,提供技术及经费支持。
李玉峰:调研及文献整理,参与数据预处理及程序编写,起草并修订论文。
裴莉莉:调研及文献整理,参与算法开发及方法验证,修订论文。
李 伟:指导研究方案,审阅论文,提供技术及经费支持。
石 丽:实施现场试验,构建数据集,参与数据分析和处理,验证算法。
曹 磊:实施现场试验,参与算法设计实现,模型训练,论文写作及修订。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
黑龙江交通科技(2020年8期)2020-09-08 02:37:48
自动化学报(2019年6期)2019-07-23 01:18:32
上海公路(2017年4期)2017-03-01 07:04:27
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
河南科技(2015年8期)2015-03-11 16:23:52
