
结合随机掩膜与特征融合的孪生网络目标跟踪
2022-06-02 07:08马永杰谢艺蓉徐小冬
西北师范大学学报(自然科学版) 2022年3期
马永杰,陈 宏,谢艺蓉,徐小冬,张 茹
(西北师范大学 物理与电子工程学院,甘肃 兰州 730070)
目标跟踪作为计算机视觉的一个基础分支,在视频监控、智能交通、无人驾驶等方面具有广泛应用[1-3].影响目标跟踪算法性能的关键因素包括外界因素(如光照变化、遮挡、相似背景干扰等)、内部因素(如姿态变化、外观变形、尺度变化、平面旋转、快速运动等[4])和跟踪速度.实现一个兼具高性能与实时性的视觉跟踪系统仍然具有挑战性.
当前,目标跟踪算法主要包括相关滤波类算法和孪生网络类算法.基于相关滤波的目标跟踪算法通过循环矩阵在傅里叶域中快速求解来实现快速跟踪,如CSK[5]、KCF[6]、DSST[7]等.随着深度学习的快速发展,为了利用端到端优势,研究人员将Siamese框架应用到了目标跟踪领域.Bertinetto等[8]开创性地提出了全卷积孪生神经网络(Fully-convolutional siamese network, SiamFC)的单目标跟踪算法,将目标跟踪任务转化为相似度匹配问题.通过训练一个改进的AlexNet[9]网络作为通用的匹配函数,实现模板与搜索区域互相关,从而得到目标区域.SINT[10]使用Siamese网络学习一个匹配函数,将后续每一帧得到的多个候选框与第一帧目标框进行匹配度计算,得分高的候选框即为预测目标.CFNet[11]在SiamFC的基础上添加了相关滤波层,实现了在线优化网络特征.SiamTri[12]引入3分支损失,提高了跟踪器的训练性能.
尽管全卷积孪生网络目标跟踪算法在精度和性能上都取得了较大的突破,但是仍然遗留了一些问题.一是特征提取能力不强,SiamFC采用较浅的AlexNet作为骨干网络,当遇到变形、尺度变化等复杂场景时,容易出现跟踪任务失败现象;二是特征类型单一,SiamFC仅采用高层的语义信息进行卷积互相关而忽略低层的位置信息,导致跟踪器定位能力不足,当跟踪过程出现目标遮挡、相似干扰时,难免出现模型漂移.针对SiamFC的上述两个问题,文中提出了一种结合随机掩膜与特征融合的孪生网络目标跟踪算法.将SiamFC骨干网络AlexNet网络替换成深度更深的VGGNet[13]网络,以提高模型的特征提取能力;在输入端对模板分支和搜索分支添加带有噪声的随机掩膜,并在跟踪器模板分支加入了注意力机制去调节模型,以提高模型的抗干扰能力;将网络的Conv4-1和Conv5-1层进行特征融合,使模型兼具网络低层的位置信息和网络高层的语义信息,以提高模型对相似语义的判别能力.
1 文中算法
文中算法的基础框架如图1所示.

图1 算法的基础框架
1.1 全卷积孪生神经网络
SiamFC是一种典型的端到端网络训练模型,不经过复杂的中间建模过程,从输入端到输出端得到一个预测的结果,它具有模板分支和搜索分支两个输入分支.模板分支的模板图像Z和搜索分支的搜索图像X分别被裁剪为127×127×3和255×255×3大小的输入对,经过共享权值的卷积神经网络φ输出图像大小分别为6×6×256和22×22×256,最后经过互相关的卷积操作得到一个17×17×1的响应图.响应图中响应最高的一个点就是下一帧预测目标的中心位置.
整个网络的跟踪过程可以定义为
f(Z,X)=φ(Z)*φ(X)+b,
(1)
其中,φ为改进的卷积神经网络AlexNet;*表示卷积的交叉相关运算;b∈R为偏置项;f(Z,X)为17×17×1的置信响应图.
整个网络采用二分类的逻辑损失函数
l(y,v)=lg(1+exp(-yv)),
(2)
其中,v为模板与搜索区域候选框的相似度得分;y∈{+1,-1}为正、负样本的标签值.
1.2 基于VGGNet的孪生网络结构
尽管全卷积孪生神经网络SiamFC在跟踪性能上比KCF等相关滤波强,但是仍然存在一些不足.SiamFC使用AlexNet作为骨干网络,仅有5层,特征提取能力不强,当目标出现变形、尺度变化时 很容易丢失目标; 此外, SiamFC使用的AlexNet引入了padding操作,会破坏网络的绝对平移不变性,导致目标跟踪性能下降.
因此,文中采用深度更深的预训练VGG16代替AlexNet作为骨干网络,该网络有着更强的特征提取能力,有助于提高模型的性能.采用特征图裁剪,在每一层引入padding的卷积层后,进行裁剪(crop)操作,具体的网络结构如表1所示.

表1 基于VGGNet的孪生网络结构
1.3 基于随机掩膜的抗干扰识别
随机掩膜(Random soft mask,RSM)的核心思想就是通过给训练图片添加随机权重值的噪声掩膜来模拟复杂环境,从而提高跟踪器对复杂环境的抗干扰能力.
1.3.1 随机掩膜定义 在目标跟踪过程中,目标与背景之间的区分度越高,卷积网络越容易识别目标.文中首先采用一种添加噪声掩膜的方法,来提高目标与背景区分度.如图2所示,噪声掩膜是通过特征融合来生成相应权重的软掩膜,当训练图片叠加软掩膜后,实现了特征增强,能令卷积网络更关注目标区域.

图2 训练图片叠加掩膜噪声的效果
但是,在跟踪过程中,当场景发生变化时,目标与背景之间的区分度也是变化的.如果掩膜噪声权重设定为固定值,并不能很好地适应复杂多变的跟踪环境.于是文中提出一种随机掩膜的方法,将掩膜噪声权重设定为随机值来模拟剧烈变化的场景.不同噪音权重w下噪声掩膜呈现出的目标与背景区分度也不同,将训练图片与噪音权重w={0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1}的噪声掩膜进行叠加,效果如图3所示.

图3 训练图片叠加不同权重的掩膜噪声效果图
文中将噪声掩膜权重w取[0.5,1]的固定值进行OTB2015[14]消融实验.从表2实验可知,最终文中噪音权重w的取值确定为[0.7,1],并采用轮盘赌策略,每次从{0.7,0.8,0.9,1}中随机选择一个数值作为训练图片的噪声掩膜权重.
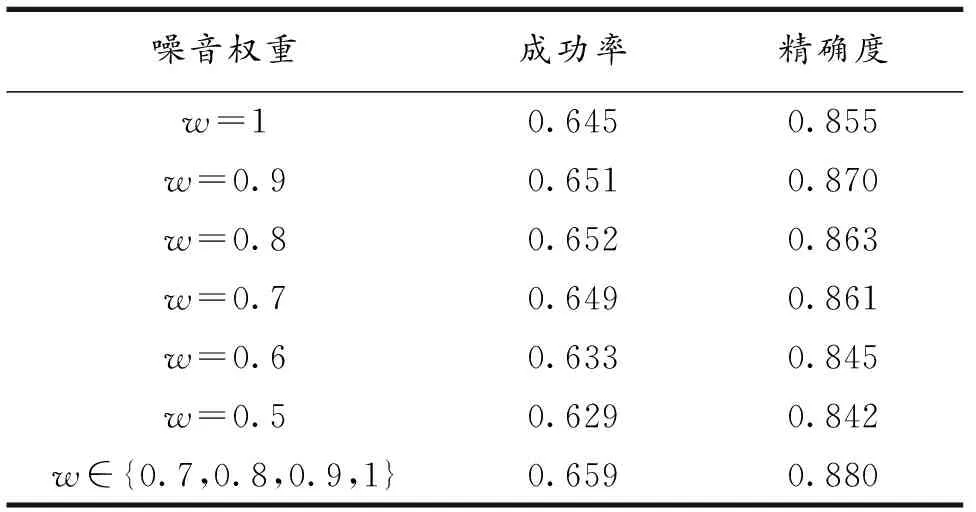
表2 噪声掩膜有效性测试结果
1.3.2 随机掩膜生成不同于孪生网络只有模板分支Z和搜索分支X两个输入分支,文中增加了噪声模板分支Znoise和噪声搜索分支Xnoise两个分支,如图1中左侧实线框所示.随机掩膜主要包括随机噪声权重掩膜的生成和随机噪声权重掩膜的叠加两部分,如图2所示.
1)随机噪声权重掩膜的生成.可用下式表示
其中,w为噪声权重;Zn,Xn为噪声模板分支和噪声搜索分支的输入图片;Zn1,Xn1为噪声模板分支和噪声搜索分支输出的噪声掩膜.
2)随机噪声权重掩膜的叠加.模板分支Z和噪声模板分支Znoise进行融合,搜索分支X与噪声搜索分支Xnoise进行融合,如下式所示
其中,⊕为叠加操作;Zin,Xin为模板分支和搜索分支的输入图片;Z*,X*为噪声掩膜叠加后的模板分支和搜索分支图片.
1.4 注意力机制模块
文中利用3分支注意力(Triplet attention)模块[15]和卷积块注意力模块(Convolutional block attention module, CBAM)[16]的优点形成了一种新的注意力机制,可以认为是CBAM注意力机制在3个维度上的交互.文中的3分支注意力机制模块如图4所示,输入的特征图经过Channel-attention操作实现通道注意力叠加,再经过3分支实现通道C和空间(H×W)跨纬度交互.3分支中,经过Channel-attention操作的特征图进入左边分支,整体上形成了通道-空间注意力计算分支,即CBAM注意力机制.其余两个分支实现维度交互,最后将3个分支的输出进行平均聚合.
图4中的Channel-attention操作如(7)式所示:
γ(χ)=S(MLP(map(χ))+MLP(avp(χ))),
(7)
其中,χ为输入特征;map,avp为自适应最大池化和自适应平均池化操作;MLP表示挤压(降维)-激励(升维)的卷积操作;S为Sigmoid激活函数.
图4的Z-Pool操作如(8)式所示:
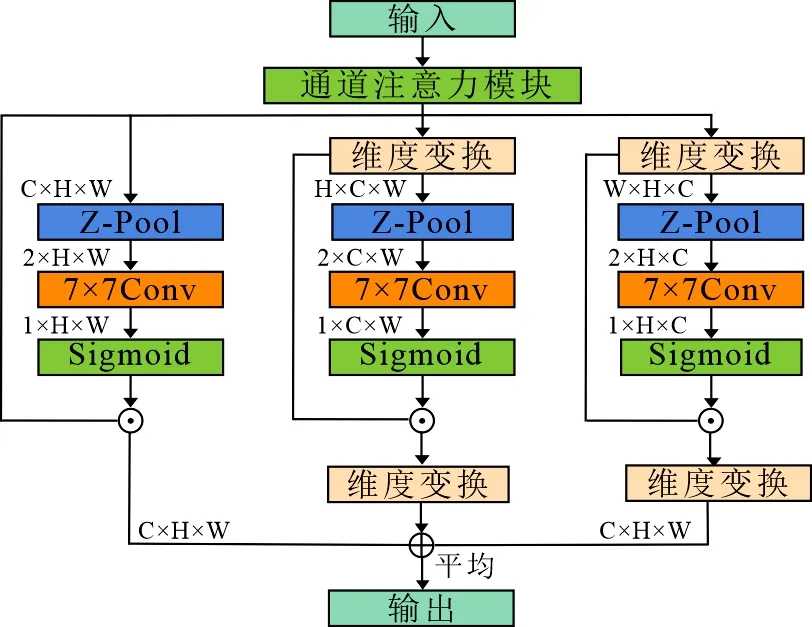
图4 三分支注意力机制示意图
Ψ(γ)=MaxPool(γ)⊙AvgPool(γ),
(8)
其中,Ψ(γ)为Z-Pool操作的输出特征图;⊙表示拼接操作; MaxPool,AvgPool为最大池化操作和平均池化操作.Z-Pool负责将高维度的Tensor缩减为二维,将最大汇集特征和平均汇集特征连接起来,能够保留实际张量的丰富表示.
通过类热力图对不同网络进行可视化,结果如图5所示,第一行是未加入注意力机制模块的可视化结果,第二行是加入注意力机制模块的可视化结果.从实验结果可以看出添加注意力机制模块的网络注意力范围更广,覆盖目标面积更大,提取的目标特征更多,识别能力更强.

图5 使用Grad_ CAM网络可视化结果
1.5 特征融合
文中以更深的VGG16网络为骨干网络,通过特征融合策略提高目标的定位能力.表3给出了消融实验结果,可以看出采用卷积层Crop4-1生成的和Conv5-1生成的响应图进行特征融合跟踪性能最佳.
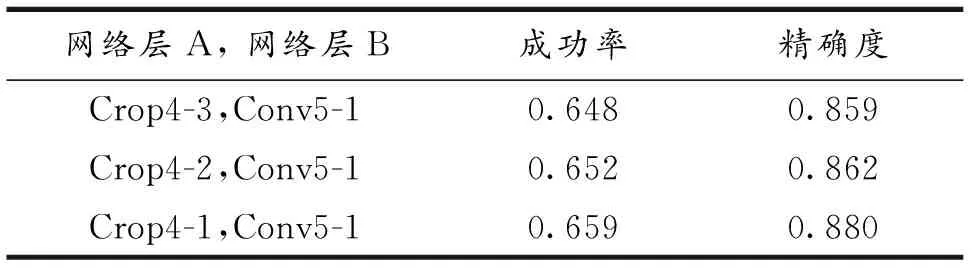
表3 不同特征层融合测试结果
卷积层Crop4-1和Conv5-1这两层有着更多的语义信息和空间信息,特征融合后的响应图质量更高.融合过程如图1所示,模板分支和搜索分支的Crop4-1层特征图尺寸分别为9×9×512和25×25×512;Conv5-1特征图的尺寸分别为5×5×256和21×21×256.为保持尺寸一致,采用互相关卷积操作得到特征图尺寸和通道数相同的响应图,将Crop4-1层和Conv5-1层生成的响应图拼接后通过卷积核为1的卷积操作实现特征融合.
2 实验结果与分析
2.1 实验平台与模型训练
文中算法的软件环境采用Ubuntu18.04搭载Pycharm,使用Pytorch1.1.0编程框架验证算法性能.所有的实验均在Intel Core i9-9900KF 3.6 GHz和GeForce RTX-2070S显卡上执行.
使用GOT-10k[17]数据集来进行模型训练,随机地从相同视频提取模板图像(127×127×3)和搜索图像(255×255×3)组成训练对作为网络的输入.采用随机梯度下降算法(Stochastic gradient descent, SGD)初始化目标函数,利用二分类交叉损失对整个网络进行训练,训练50个周期,学习率从10-2衰减到10-5.使用3个固定尺度{0.9745,1,1.0375}来估计目标尺度,尺度的变化通过线性插值的方式来更新,如(9)式所示.
S=(1-rscale)x0+rscalex1,
(9)
其中,更新因子rscale设为0.59;x0为中间尺度;x1为惩罚后的尺度.从而实现线性插值的方式更新尺度信息.
为验证文中跟踪算法的有效性,在5个具有挑战性的视频基准库OTB2015[14],VOT2016[18],VOT2018[19],UAV123[20]和TempleColor128[21]上进行实验,5种数据集的特点和指标如表4所示.

表4 不同数据集的特点和指标
2.2 基于OTB2015实验
OTB2015数据集共有100个视频序列,包含光照变化(IV)、尺度变化(SV)、遮挡(OCC)、变形(DEF)、运动模糊(MB)、快速移动(FM)、平面内旋转(IPR)、平面外旋转(OPR)、离开视野(OV)、相似背景(BC)、低分辨率(LR)共11个属性.
除了基准算法SiamFC[8],文中还与一些先进的跟踪算法进行了比较,包括SiamRPN[2],UDT+[22],CIResNet22-FC[3],SRDCF[23],SINT[10],Staple[1],SiamTri[12],CFNet[11]等.
2.2.1 定量分析 1)评价标准.为了定量的评估文中算法的性能,使用成功率(Success plots)和精确度(Precision plots)两个指标作为评价标准,并绘制成功率图和精确度图来显示评价结果.覆盖率(OS)是指跟踪结果的预测框和真实目标框的面积的交集比它们面积的并集,如(10)式所示.
其中,a为跟踪算法得到的定位框bounding box;b为目标的真实标签ground-truth.
成功率代表覆盖率大于某个阈值的帧数和视频帧数总数的比率,取值为[0,1],一般阈值设定为0.5.
精确度代表视频中跟踪成功的帧数占总帧数的比率.若跟踪算法得到的目标位置中心点与真实标签的中心点的欧氏距离小于给定的阈值,则表示跟踪成功.
2)混合干扰下的算法总体性能分析.图6分别给出了在11种混合干扰共同影响下的10种算法的成功率和准确率.由图6可知,文中算法的总体成功率和总体准确率均最高.算法的成功率达到了0.659,相比基准SiamFC算法,提升了7.7%.算法的精确度达到了0.880,相比SiamFC算法,提升了10.9%.

图6 OTB2015精确度和成功率图
3)11种干扰单独影响下算法的性能分析.由图7a~7k可知,文中算法在背景相似、目标变形、快速运动、平面内旋转、光照变化、低分辨率、运动模糊、目标遮挡、平面外旋转、出视野、尺度变化条件下取得了较好的成绩,精确度分别达到了0.851,0.861,0.872,0.897,0.889,0.897,0.893,0.819,0.881,0.843,0.876.在各种干扰单独影响下,文中算法的跟踪精度均高于其他算法,与基准算法SiamFC相比,精确度分别提高了16.1%,17.1%,12.9%,15.5%,15.3%,5.0%,18.8%,9.7%,12.5%,17.4%,14.1%,其中提升最多的3种属性为目标变形、运动模糊和出视野.
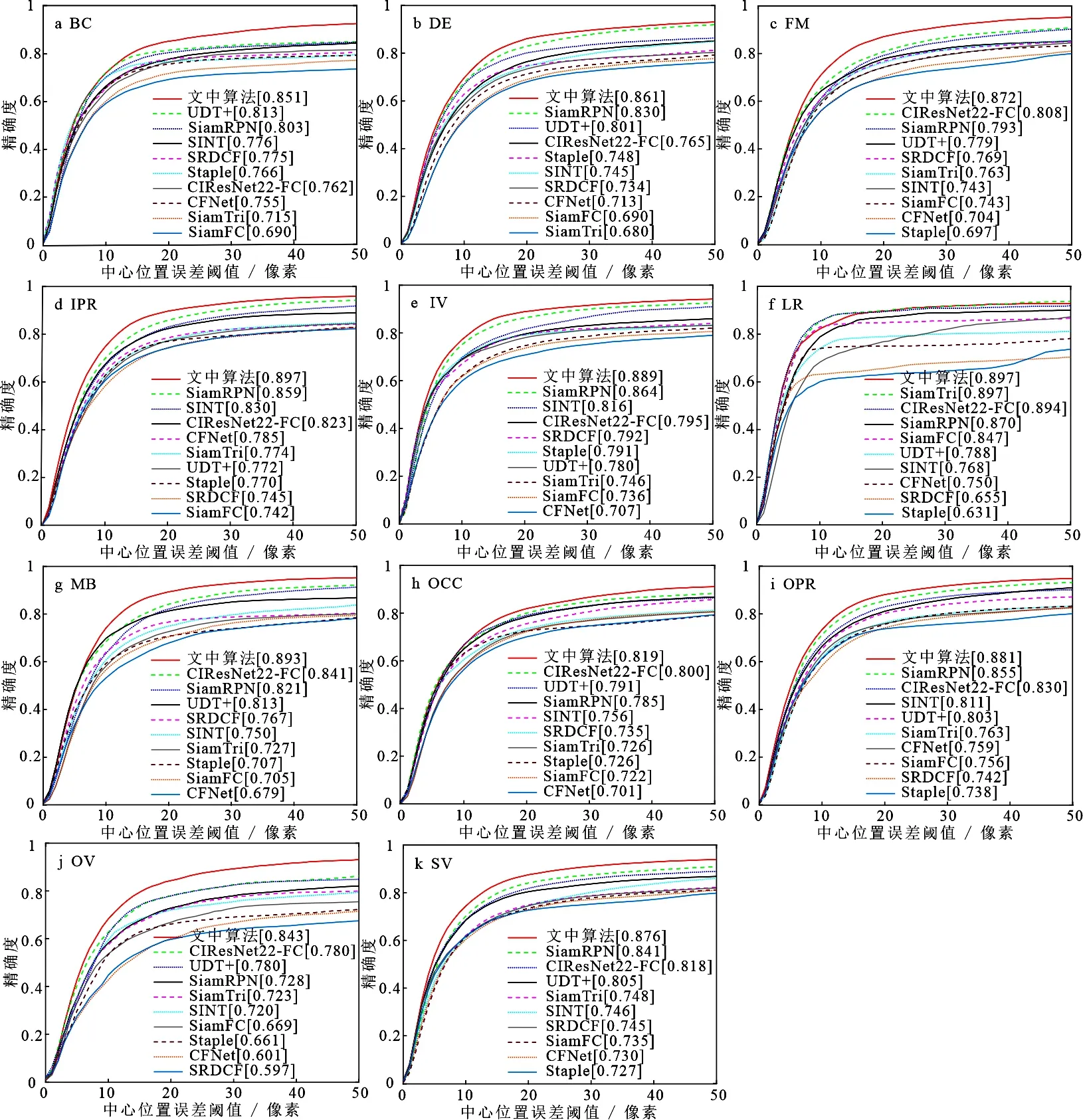
图7 不同属性视频下的跟踪精度对比
总体来说,在11种干扰下,与其他算法相比,文中算法成功率和精确度均较高.由于算法提出的随机掩膜、注意力机制和特征融合等策略用于提升SiamFC的抗干扰能力和特征提取能力,所以遮挡、背景相似、运动模糊、变形、尺度变化这几种相关属性更需要着重关注.在这些干扰下,算法的精确度均最高,说明算法处理这几种干扰的能力优于其他几种算法.
2.2.2 定性分析 选取了几个具有代表性的视频序列,如表5所示进行更详细分析,结果如图8所示,给出了CFNet,UDT+,SiamTri,SiamFC和文中算法的跟踪结果.

表5 各视频的场景属性
Bolt1.该视频中跟踪的是一名运动员.运动目标特点为非凸性,运动过程中不断进行平面内旋转和平面外旋转,周围有遮挡.从图8a中可以看出,在第22帧,CFNet、SiamTri和SiamFC算法已经丢失目标;在第63帧,UDT+算法也发生漂移,而文中算法能够全程准确地跟踪到目标,因为文中的训练算法能够有效地排除干扰,对目标进行定位.
Matrix.该视频为是一段雨夜中的打斗场面,跟踪目标为打斗者之一.目标身处光照变化的环境,而且目标与背景的颜色极为相似,随着镜头的拉伸目标不断发生尺度变化, 当目标快速运动时,大部分算法的辨识度不够.如图8b所示,视频刚开始的第41帧中,其余算法均丢失目标,在第50帧中,CFNet找回跟踪目标,在第70帧中,其余3种算法仍处于丢失目标状态.文中算法能够持续跟踪目标,是因为算法有着较强的特征提取和识别能力,有效克服相似干扰.

图8 OTB2015数据集的定性结果展示
MotorRolling.该视频的跟踪目标是摩托车和人.目标在测试视频中处于低分辨的环境,当目标在快速运动时,会发生运动模糊,周围的灯光环境随之发生变化,并且目标在跟踪过程中发生了尺度变化.如图8c所示,在视频刚开始的第11帧,其余几种跟踪算法已经发生漂移.而在第46帧中,空中的相似干扰令其余几种算法完全丢失目标.在第112帧,文中算法仍然可以完美跟踪到目标.文中算法在整个视频中都能够准确跟踪到目标,说明算法应对背景相似和低分辨率等复杂环境的有效性.
Skiing.该视频是跟踪的一个高速运动的滑雪运动员.其主要跟踪难点在于目标自身的快速运动、周围的光照条件不断发生变化、大尺度平面内旋转.如图8d所示,在视频刚开始的第25帧,只有文中算法和CFNet能跟踪目标,从第43帧开始,CFNet丢失目标.文中算法能持续准确跟踪目标,说明算法能够很好应对光照变化、变形、尺度变化等挑战.
根据不同跟踪算法在OTB2015数据集的定性结果展示,文中算法在背景相似、运动模糊、变形、低分辨率、遮挡、尺度变化等场景属性有着良好的性能.
2.3 基于VOT2016和VOT2018数据集实验
2.3.1 基于VOT2016实验分析 VOT2016数据集包含60个精细标注的短序列.评估时,只要检测到追踪失败,被测追踪器就会重新初始化.主要评估指标有平均重叠期望(Expected average overlap, EAO)、准确度(Accuracy,A)、鲁棒性(Robustness,R).其中,OEA和A的分数越高,R的分数越低,证明跟踪器性能越强、稳定性更好.这里选取了SRDCF[23],SiamFC[8],deepMKCF[24],UDT[22],HCF[25],KCF[6]等6种算法与文中算法进行比较,OEA排名如图9a所示.文中算法相对于基准算法SiamFC,OEA和A的分数分别提高了4.1%和3.9%,鲁棒性提高了7.9%,如表6所示.

图9 VOT2016和VOT2018期望平均重叠率排名

表6 在VOT2016数据集上测试结果
2.3.2 基于VOT2018实验分析
VOT2018数据集由60个视频(相对于VOT2016数据集使用更难的序列组成)组成,主要的评估指标也是期望平均重叠率,精度和鲁棒性.这里选取了MEEM[26],SiamFC[8],Staple[1],TRACA[27],KCF[6],SRDCF[23]等6种算法与文中算法进行比较,OEA排名如图9b所示.如表7所示,文中算法相对于基准算法SIamFC,OEA和A的分数分别提高了7.4%和3.0%,鲁棒性提高了12.6%.

表7 在VOT2018数据集上测试结果
2.4 基于UAV123和TC128数据集实验
2.4.1 基于UAV123数据集实验分析 UAV123数据集囊括123组视频序列,主要由无人机拍摄而成,特点是背景干净,视角变化较多.其评估指标与OTB2015数据集的评估指标一致.文中选取了SiamFC[8],SRDCF[23],MEEM[26],DSST[7],KCF[6],CSK[5]等6种算法与本文算法进行比较.如图10所示,文中算法的结果都是最优的,其中成功率达到了0.529,比SiamFC高2.9%,精确度达到了0.753,比SiamFC高2.5%.
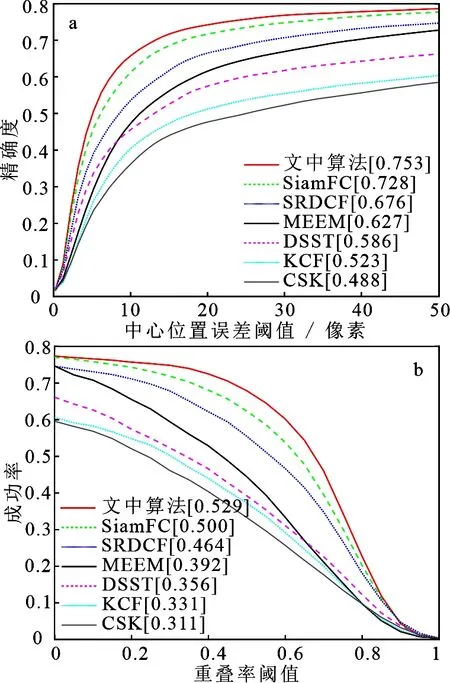
图10 UAV123成功率和精确度图
2.4.2 基于TempleColor128数据集实验分析 TempleColor128数据集包含128个彩色视频序列,更加贴近于现实场景的跟踪环境,其评估指标与OTB数据集一致.为了验证模型的泛化能力,文中选取了UDT+[22],SiamFC[8],SRDCF[23],KCF[6],DSST[7],CSK[5]等6种算法,实验结果如图11所示.文中算法仍然保持着优越的跟踪性能,其中成功率达到了0.542,比SiamFC高4.4%,精确度达到了0.755,比SiamFC高5.7%.

图11 TempleColor128成功率和精确度图
2.5 消融实验
为了验证注意力模块(Attention)和随机掩膜(RSM)模块对跟踪器性能提升的贡献,在OTB2015数据集上做了如下消融实验,结果如表8所示.单独添加Attention模块,成功率和精确度有所提升,当Attention模块和RSM模块同时添加时,成功率和精确度提升最大,分别达到了0.639和0.880,证明了这两个模块的有效性.

表8 消融测试结果
3 结束语
文中提出了一种结合随机掩膜与特征融合的孪生网络目标跟踪算法.使用VGGNet骨干网络替换AlexNet网络,使模型兼具低层的位置信息和高层的语义信息,实现低层与高层特征层融合,具有更强的特征提取能力和目标定位能力;添加随机掩膜,模拟复杂环境,使跟踪器模型对各种复杂环境有着更好判别能力;引入包含通道分支C和空间分支H、空间分支W的3分支注意力机制,通过跨维度交互,实现通道与空间的注意力互相关联,使模型更加关注目标特征.这些改进有效地消除了SiamFC特征提取能力不强、不能适应背景相似、变形、运动模糊等复杂场景、容易出现跟踪任务失败等现象,并且在其余属性上取得了良好的结果.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
黑龙江大学自然科学学报(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2021年4期)2021-08-30
人工晶体学报(2021年3期)2021-04-17
电子制作(2019年13期)2020-01-14
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2018年5期)2018-04-09
