
基于深度学习的贵州辣椒蚜虫发生气象条件 预测模型初报
2022-05-31 06:40:12刘凯歌吴康云牟玉梅
辣椒杂志 2022年1期
刘凯歌 吴康云 邢 丹 宋 敏 牟玉梅 李 明,3*
(1. 贵州春芯科技有限公司, 贵阳 550081; 2. 贵州省农业科学院辣椒研究所, 贵阳 550025; 3. 北京市农林科学院信息技术研究中心/国家农业信息化工程技术研究中心/农产品质量安全追溯技术及应用国家工程研究中心/中国气象局-农业农村部都市农业气象服务中心/农业农村部农产品冷链物流技术重点实验室(北京), 北京 100097; 4. 石河子大学农学院/特色果蔬栽培生理与种质资源利用兵团重点实验室, 新疆石河子 832003)
辣椒作为世界上栽培面积最大的调味作物,深受人们喜爱,其维生素C含量居蔬菜首位,且具有较高的药用价值。贵州是我国辣椒主产地,随种植面积的不断扩大和连续种植,病虫害发生与危害逐年加剧,特别是在高温多雨季节更易导致病虫害爆发流行,造成辣椒产量大幅下降甚至绝收,成为制约辣椒产业发展和农民增收的瓶颈。
蚜虫是辣椒生产中高发害虫之一,聚集在辣椒叶片、花梗及果实上吸食汁液获取营养,造成辣椒大幅减产并降低果实品质。蚜虫还是多种病毒的传播媒介,极易引发病毒病。因此,通过对蚜虫发生情况进行预测,进而为农户提供防治信息及用药指导、降低蚜虫为害损失至关重要。由于蚜虫种群分布范围广、繁殖力强,导致溯源难度大、虫量调查复杂。结合蚜虫生活习性,通过分析其与环境条件的相关性,作为预测蚜虫是否发生的参考依据。陈敏等采用数理统计法对蚜虫发生情况进行了回归分析预测,但这种方法比较复杂,需要对多年数据进行拟合,使用不当则会降低病害预测的可信度和准确性。随着大数据、机器学习和遥感等技术的不断发展与成熟,应用在蚜虫预测上的方法和预警水平得到了极大改善,高风昕、王秀美等、唐翠翠等、李文峰等、Holloway等、Worner等分别结合气象数据,利用机器学习、深度学习技术,基于蚜虫物候期相关数据构建了预测模型,但尚未见应用于辣椒蚜虫预测的研究报道,且这些方法对长时间序列数据的提取能力较差。由于缺乏记忆能力,这些模型在基于学习过程对数据进行预测时的鲁棒性受到了限制,可能导致准确率降低等。
长短期记忆(Long Short-Term Memory, LSTM) 神经网络是由Hochreiter等提出的循环神经网络(Recurrent Neural Network, RNN)的变体,常用于解决存在长期依赖问题的时间序列数据预测。其通过改变内部结构,优化RNN在迭代过程中的梯度消失和梯度爆炸问题,已广泛应用于轨迹预 测、空气污染预测、电力负荷预测、交通流量预测、股票预测等领域,并取得了良好的效果。本文通过气象站采集的辣椒生长期间的气象数据,结合人工调查蚜虫发生情况,采用深度学习技术,构建基于LSTM的蚜虫发生预测模型,为辣椒种植根据气象变化和预测结果及时采取防治措施提供参考。
1 材料与方法
1.1 试验时间与地点
试验于2021年6—9月在贵州省辣椒研究所遵义官庄基地 (27.44°N,107.12°E)开展,选择本地有代表性的中上等肥力水平、地势平坦、向阳、前作一致、肥力均匀、排灌方便的地块作为试验地。
1.2 试验材料
栽培辣椒品种为“黔椒8号”,由贵州省辣椒研究所提供。田间按1.3 m连沟开厢,厢面宽80 cm,畦高20 cm,行距60 cm,株距40 cm,过道50 cm,厢植两行,单株定植,间设2厢保护行,小区面积546 m。
1.3 试验设计
田间部署一套气象站,监测辣椒生长环境数据。选取5个小区、100株辣椒进行蚜虫发生情况的系统调查,挂牌定点(定株)每日调查虫害发生时间、生育期、发生严重程度等。6月23日辣椒初花期时初次监测到蚜虫发生,7月3日达到4 881头/百株的危害高峰期。
1.4 试验方法
1.4.1 模型变量选取 温度、湿度、风速、降雨量等气象因子是影响蚜虫消长动态变化的决定因素。本文选取气象站每30 min采集的温度、相对湿度、风速、太阳辐射强度、降雨量作为模型输入变量,以人工调查的蚜虫是否发生作为模型输出变量,其模型变量设置与描述见表1。

表1 模型变量设置与描述Table 1 Model variables setup and description
1.4.2 数据预处理
利用PyCharm 2019.3 & Python 3.7.11对原始气象数据进行均值计算、变量定义与数据格式处理,用线性插值法进行数据缺失值处理,公式如下:

式中X、Y、X、Y、是已知样本数据;为X、X之间的数据;为与对应的需插值的缺失数据。采用最大最小法进行归一化处理,将有量纲数据统一转化为[0,1]之间的无量纲数据,归一化公式如下:

式中X为所有样本数据(i = 1,2,.... n);X为所有样本数据中的最小值;X为所有样本数据中的最大值;X为归一化后得出的结果。归一化后得到模型数据集,划分数据集的70%作为模型训练集,用于模型学习数据特征,剩余30%作为模型测试集,用于验证、评价模型学习的有效性。
1.4.3 模型构建与评价 使用PyCharm 2019.3 & Python 3.7.11,基于Keras深度学习框架(以TensorFlow为后端)进行模型构建,并采用混淆矩阵 (confusion matrix)、受试者工作特征曲线(Receiver Operating Characteristic, ROC)、AUC值(Area Under the ROC Curve)和准确率(Accuracy),精准率(Precision),召回率(Recall),F分值(F-score)对模型性能和分类预测指标进行评价。
混淆矩阵是通过n行×n列的矩阵将预测值与真实值对比数量进行可视化的一个评价指标,用于展示模型预测情况,列联表分析结果如表2所示。

表2 分类结果和汇总列联表Table 2 Contingency table of categorical results and summary
ROC曲线是以假阳性率(FPR)为横坐标、真阳性率(TPR)为纵坐标得到的用于展示模型分类效果的曲线图,AUC值是ROC曲线下的面积,其值越接近1,表示模型的分类性能越好。其计算公式如下:

准确率表示预测正确的样本数占样本总数的比例,精准率表示正确预测发病的样本数占预测发病样本数的比例,召回率表示正确预测发病的样本数占实际发病样本数的比例,F-score是综合精准率和召回率的评价指标。其计算公式如下:
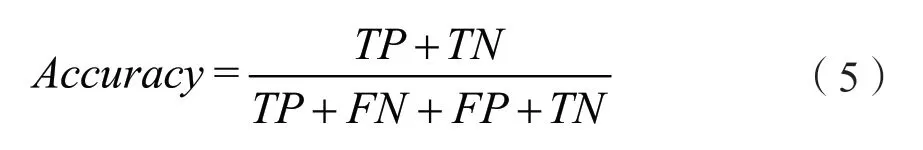

上述公式中,真阳性是指实际为阳性且预测为阳性的样本,假阳性是指实际为阴性但预测为阳性的样本,真阴性是指实际为阴性且预测为阴性的样本,假阴性是指实际为阳性但预测为阴性的 样本。
2 结果与分析
2.1 模型训练结果
模型训练准确度和训练过程损失函数(Loss function)变化趋势如图1所示,结果分别为0.981 6 和0.008 0,表明模型对数据学习效果较好。其中Loss函数选 用 均方根对数 误 差(MSLE, Mean Squared Logarithmic Error)来评价模型预测值和真实值之间的差异程度,损失函数越低,表明模型的性能越好。
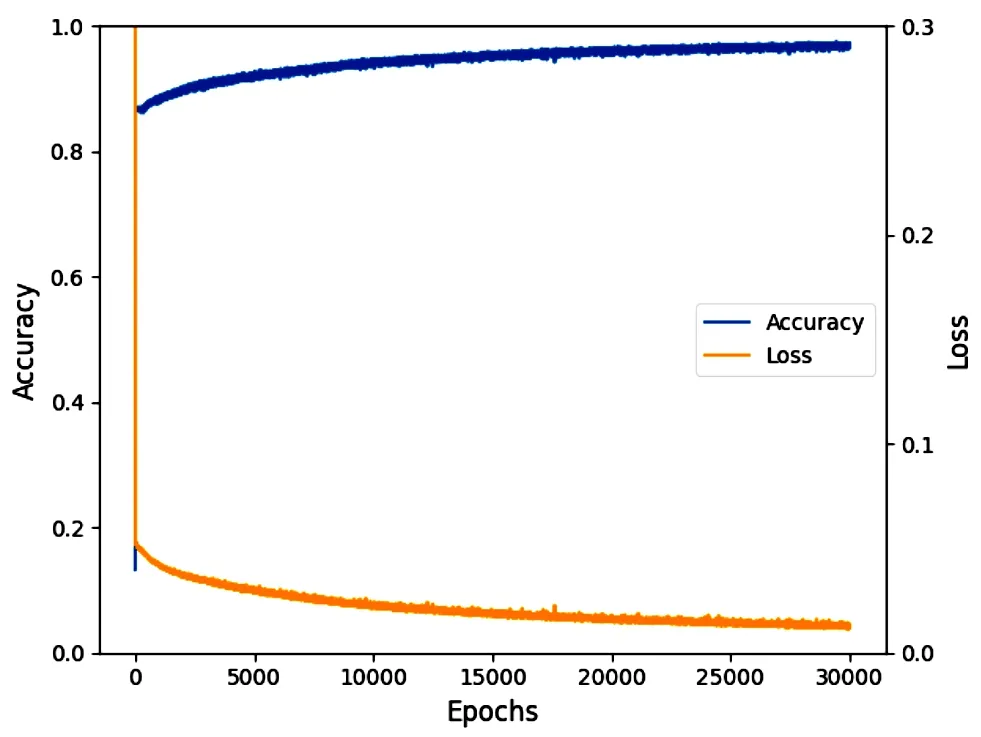
图1 模型训练过程训练集准确度和Loss值变化趋势Figure 1 Model training process training set accuracy and Loss function change trend
2.2 模型预测结果
模型对训练集进行学习后,通过测试集验证模型精度并进行二分类预测(蚜虫发生或蚜虫不发生)得出评价指标如图2所示。图2(a)为测试集数据条数(1 446条)的分布情况,其中,真阴性(92条)、假阳性(107条)、假阴性(82条)、真阳性 (1 165条)。
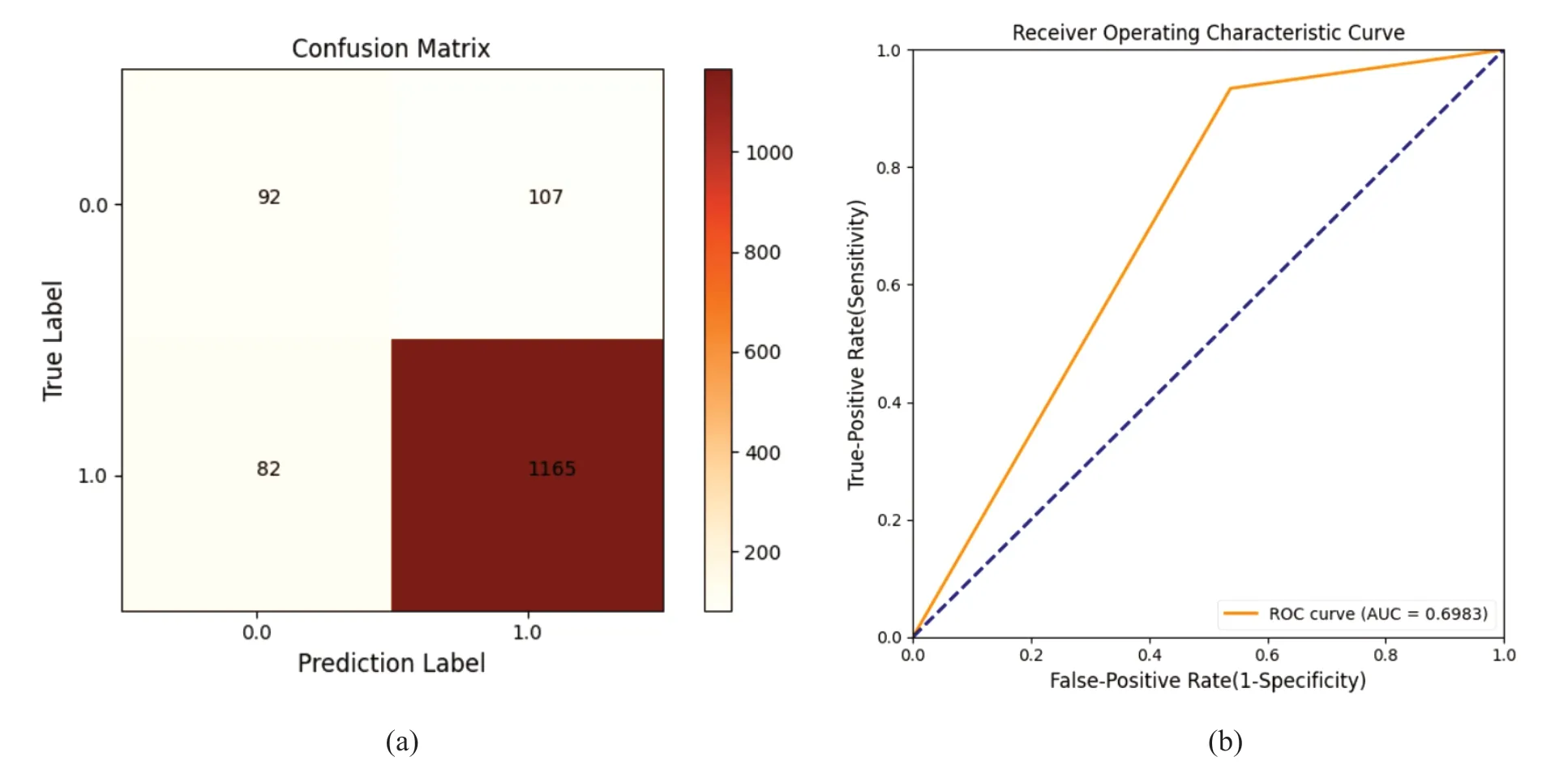
图2 预测模型分类评价指标 (a): 混淆矩阵,(b): ROC曲线图Figure 2 Prediction model classification evaluation index. (a): confusion matrix; (b): ROC curve
由图2(a)可知,预测准确率为87%,预测发生精准率为92%,预测发生召回率为93%,预测发生F-score为92%,表明模型对蚜虫发生预测结果较好。由图2(b)可知,AUC值为0.6983,这是因为自6月23日蚜虫发生以来,在辣椒整个生长季(6—9月)期间,蚜虫未发生的数据所占比例较小,模型对此部分数据特征的学习效果不够充分,导致分类错误(即结果为假阴性和假阳性),影响了模型总体精度。结合模型评价指标,总体上来说,模型性能较好,可通过探索、改进进一步提高蚜虫发生分类预测水平。
3 结论与讨论
本文基于深度学习技术,结合辣椒生长期间气象数据构建了贵州辣椒蚜虫发生预测模型。其中,预测准确率为87%,预测发生精准率为92%,预测发生召回率为93%,预测发生F-score为92%,模型预测蚜虫发生指标评价结果较好,能根据气象条件对生产上蚜虫是否发生作出预测。未来,将利用蚜虫识别计数技术对各分布方位的虫量进行统计,进而为蚜虫发生严重等级分级工作提供技术支持,同时从蚜虫是否发生的二分类预测拓展到发生严重程度的多分类预测,并将模型整合至监测预警系统平台供用户使用,以期对蚜虫发生情况作出评判、决策,进而为农户及时采取防治措施提供决策支持。
本文是首次将LSTM结合气象数据应用于辣椒蚜虫发生预测上,还存在一些不足,如由于蚜虫发生规律及种群动态变化较复杂且存在较大不确定性,易导致误差等,因此本研究暂没有考虑这些因素,只针对气象数据对蚜虫发生情况的影响进行了分析建模。另外,由于此模型对数据要求较高,其原理是从和蚜虫发生相关的大量气象数据中学习、捕捉关联性信息,再通过新输入数据来判定是否符合发生特征,进而得到蚜虫是否发生的预测结果。正如上述所说,自辣椒定植以来未发生蚜虫的数据相对不够多,造成预测蚜虫发生与预测蚜虫不发生的综合分类预测结果不够理想,这也是今后需要对模型进行优化、改进的方面之一。
