
基于DBLP数据集的作者研究兴趣挖掘
2022-05-30 10:48:04邵明阳单菁
电脑知识与技术 2022年27期
关键词:数据存储
邵明阳 单菁


摘要:为从DBLP数据集中挖掘出作者研究兴趣,提出了基于DBLP数据集中有效信息的作者研究兴趣挖掘模型,主要是利用了数据集中作者姓名和论文题目进行研究兴趣的挖掘。因为DBLP数据集的元数据以XML格式存储,因此采用SAX解析器对其进行解析。解析出有用信息后,提出了一种基于索引的数据存储方式。由于作者研究兴趣词汇主要来自数据集中论文的题目,因此将题目划分短语后,根据短语的重要度,确定专家的研究兴趣词汇。经实验表明,该系统的运行速度较快,能较好地提取出作者的研究兴趣信息。
关键词: 研究兴趣挖掘; DBLP数据集; 数据存储; 格式解析; 短语划分
中圖分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)27-0009-03
开放科学(资源服务)标识码(OSID):
1 引言
随着计算机领域的快速发展,不论是高校或者还是研究所发表的论文的数量也是逐年上升。研究人员通过在期刊和会议上发表他们的研究成果,然后被更广泛的受众所消费,从而导致合作和引用,进而使创新和突破性的想法得以迅速传播[1]。而各类国际期刊或者会议发表的论文会被收录进DBLP,这使得DBLP这个英文文献数据网站的数据集也越发庞大,目前DBLP已收集了超过500万种出版物的信息。DBLP最初功能为数据库系统,为计算机领域提供文献的检索功能,它所收录的期刊和会议论文质量较高,而且更新非常迅速,这使得它很好地反映了国际研究的前沿方向。它的数据并未采用数据库存储,而是采用了可扩展标记语言(Extensible Markup Language,XML)格式存储元数据,元数据包括了标题、作者、摘要、出版单位、日期等信息,因为DBLP数据集提供的信息有限,因而进行作者研究兴趣挖掘的有效信息只有作者姓名和论文题目。
2 相关研究
对于兴趣的挖掘目前国内已有不少学者在进行相关算法的研究和改进。刘小捷等人[2]提出了一种基于维基百科类别图的推特用户兴趣挖掘系统,该方法使用个性化PageRank算法[3],通过在维基百科类别图上随机游走的方式扩展用户兴趣度。池雪花等人[4]通过基于学术论文研究学者的兴趣标签,计算学者和兴趣标签的相似度,作为兴趣标签的匹配度。传统的用户兴趣研究主要基于统计和聚类等方法[5],例如黄镇圣对高校图书馆用户进行研究[6]。石豪等人考虑到了用户之间的相似性[7]。易明等人从用户、资源、标签的聚类进行用户兴趣挖掘[8]。随着社交网络的兴起,有不少研究人员通过社交数据进行兴趣的提取,Weng等人采用LDA算法挖掘主题分布,进而获取用户的兴趣特征[9]。Hung等人通过用户自定义标签、用户收藏等设置以及社交关系,构建用户的兴趣模型[10]。以上研究是通过大量的文本和各种不同的数据集进行兴趣挖掘,而本文目的是基于DBLP数据集,试图快速挖掘出每位研究者的研究兴趣。基于DBLP提供的信息,我们试图通过每位作者的论文题目找出其感兴趣的研究方向,本文主要解决了如下两个问题:
(1) 通过Python语言标准库中simple API for XML(SAX)解析XML格式文件,由于只有作者姓名和论文题目为本文有用信息,所以可以选择过滤掉其他信息。提取信息后,考虑到空间复杂度和时间复杂度,自建索引提高检索速度。
(2) 得到论文题目后,我们选择采用速度较快的Rapid Automatic Keyword Extraction(Rake)算法[11]对论文题目的关键词进行提取,然后根据关键词的重要度确定大于指定阈值的词汇作为作者的研究兴趣。
3 作者研究兴趣挖掘模型
作者研究兴趣挖掘过程中一个很重要的步骤就是论文题目的关键词提取,本文通过使用Rake算法进行关键词的提取,目前主要的关键词提取算法除Rake外还包括基于TF-IDF词频统计的关键词抽取[12],基于词图模型的关键词抽取(TextRank)[13]等算法。TF-IDF算法有一个较大的缺点:需要一个较为全面的语料库来支持一篇文档的关键词提取,这样的做法时间开销或者空间开销较大,不适合简单快速的关键词提取。而TextRank利用投票机制来为文本中的词语进行加权,从而利用权重排序得到关键字,关键字提取的过程中仅利用了文档自身的信息,而不需要对多篇文档学习训练,因此比较简洁,但是由于算法过程中需要构建词图和迭代计算,对于大量数据来说,运行速度太慢,不易收敛,Rake算法则很好地解决了以上问题。
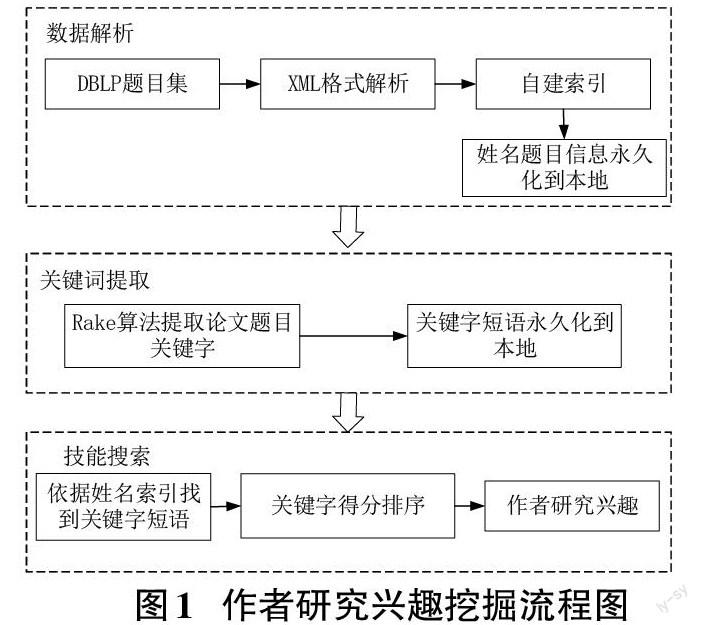
整个研究兴趣挖掘过程大约分为三个部分,首先是对DBLP数据集的XML格式的解析,过滤掉一些无用信息,只保留作者姓名和论文题目等关键性信息,其次是对解析出的论文题目进行关键词提取,最后是将作者与关键词的关联,通过作者姓名搜索按照得分大于指定阈值的关键词作为其研究兴趣。
3.1 基于DBLP数据集提取信息
3.1.1 数据集解析
由于DBLP的元数据由XML格式进行存储,所以并不能直接分析。在Python中提供的解析XML的API接口主要有两种:Simple API XML(SAX)和Document Object Model(DOM)。两种接口的解析思路不同,各自的特点如下:
(1) SAX解析器。它是事件驱动型的,首先会对整个文档顺序扫描,当扫描到开始和结束标签等信息时,会触发事件处理函数,对事件做相应处理,直至文档结束。SAX解析时边扫描,边解析,流式读取文件,速度较快,但是操作较复杂。
(2) DOM解析器。DOM解析时,会把文件一次性的读入内存,并构建一棵树状结构,通过对树的遍历解析出文件的内容。这样的缺点是当文件过大时,占用大量的内存空间,当只对文档中某些内容感兴趣时,执行效率较低。
因为DBLP数据集较大,本文采用了SAX解析的方式,避免了大量占用内存,运行效率较高。
3.1.2 数据集解析
选定SAX解析后,下一步是提取出作者和题目,为了节省空间和以后查找信息的快速方便,并未将提取出的作者和题目信息放入数据库,而是以文本形式进行存储,为了查找得快速,将每条题目中加入了索引。经过多次随机测试,创建索引需要耗费几分钟时间,但索引建立好后查找的速度较快,在几秒钟之内。具体算法流程如下:
(1) 用SAX开始顺序读取文件,从第一个元数据开始从0编号,此编号作为当前论文题目的索引,同时将作者姓名作为关键字存入Python的字典數据结构中,将索引号作为其值,并且将论文题目存入列表当中,这样顺序解析下去。
(2) 将得到的字典和列表中的信息,分别作为文本永久化到电脑当中,得到作者的文本文件和论文题目的文本文件,这两个文件也是后续操作的基础。
(3) 将文件加载到内存,分别读入到字典和列表中,然后通过在字典中查找作者姓名得到此作者所有的题目索引,进而在列表中找到论文题目,并输出。
通过以上步骤便从DBLP中提取到了相关信息,并且进行了存储,这些将作为以后步骤的基础。
3.2 通过Rake算法提取关键词
3.2.1 Rake算法介绍
相较于中文来说,Rake算法非常适合对英文文本中的多单词短语关键字进行提取,在英文文本中的短语关键字大多数是不会含有停用词和标点符号的,Rake算法正是根据这一点来进行短语的划分。Rake关键词提取算法中的几个概念定义如下:
定义1 (停用词):停用词大多数情况下指两类,一类是语言中的一些功能词,比如英文中的“the、on、which”等词,具有语法作用,而不具备实际意义。另一类是词汇词,比如“need”等,这样的词并不会对词组的划分起到作用。停用词在语言处理中需要被过滤掉。
定义2 (词频):词频指单词在文本中出现的次数,记为wordFrequency。
定义3 (词共现度):词共现度指一个单词在整篇文档中非重复共现词的数量,记为wordDegree。
Rake算法的大致流程如下:首先将输入的文本按照标点符号划分为句子集合,然后对于每一个句子依照停用词划分为短语集合,将这些短语加入最终提取的关键词的候选词中。这些短语又是由单词组成,这样通过词频和词共现度之间的关系计算出每个单词的得分,在一个词组中将每一个单词的分数相加,便可以得到整个词组的分数。单词分数计算公式如下:
[wordScore=wordDegreewordFrequency] (1)
即单词的分数就是词的共现度除以词频,此公式是Rake算法的核心。接下来就是将一个短语中单词的分数相加得到短语的分数,然后依照分数将短语排序,排序越靠前的短语就越重要。
3.2.2 使用Rake算法提取题目关键词
由于使用Rake算法进行关键词提取过程中需要使用停用词,所以在代码的具体实现过程中,我们采用了Python库中的nltk模板语料库的停用词来对短语进行划分。Rake算法对文本提取的过程中,需要将文本划分为句子然后再进行处理,而笔者的输入是一个一个的论文题目,所以笔者将论文题目视作句子,作为输入,这样就不需要再对文本进行划分为句子的步骤,具体的算法流程如下:
(1) 首先将保存论文题目的文件读入内存,然后用Rake算法将每一个论文题目以单句的形式进行处理,得到关键词及其在整个文档中总的分数,并以字典的形式储存。
(2) 依照顺序读入论文题目,将每一个论文题目依据停用词分出短语,然后利用上述的字典得到短语总的分数,然后将这一条论文题目的所有短语及其分数写入到文件,依次读取下去。这样就可以保证索引顺序不会打乱,为以后的操作提供方便。
通过以上这些步骤便从论文题目中提取出了关键词,并以文件的形式存储下来。
3.3 依照作者搜索技能
作者研究兴趣挖掘流程如图1所示。
由前面所做的工作我们得到了保存作者姓名的文档,保存论文题目的文档和保存题目关键词的文档。有了这些信息我们可以通过搜索作者姓名找出作者擅长的研究领域,具体算法流程如下:
(1) 首先将姓名文档和关键词文档读入内存,姓名文档读为字典,其键为姓名,其值为索引列表,关键词文档读为列表。
(2) 将要查询的姓名通过字典找出对应的索引列表,将这些索引通过关键词列表找到对应的值,即每一个题目的关键词,将这些关键词保存在一起然后使用集合(set)去重,最后将这些关键词输出。
(3) 根据关键词的得分,得出作者最擅长的某些领域,其中在计算关键词的得分时,考虑到作者的署名位序对研究兴趣的挖掘有很大影响,署名越靠前的作者对文献的研究兴趣贡献度越大,署名靠后的因逐级给予更少的得分,因此将署名位序加入关键词得分计算公式中。
4 实验
4.1 实验环境
操作系统:Window 10 专业版64位。
处理器:英特尔酷睿i7-9750H。
内存:16G(DDR4 2666MHz)。
硬盘:1T机械硬盘。
4.2 实验过程和结果
实验数据集采用DBLP数据集,对数据解析处理后,使用Rake算法将题目中的关键词提取出来,并记录和存储。最后按照作者的名字将所有关键词按照得分排序,将得分靠前的一些关键词作为作者感兴趣的研究方向。表1展示了部分运行结果及作者主页中对自己研究兴趣的描述。
为了测试系统的速度,记录了各部分的运行时间,结果如表2所示:
以上三个操作最耗费时间,剩下的操作在内存中完成,不会占用过多的时间,考虑到DBLP数据集大约有500万条数据,实验表明本系统运行速度相对较快,可以满足日常的任务需求。
5 结论
本文专注于基于DBLP的作者研究兴趣挖掘,提出了一种通过挖掘题目中的关键词获得作者研究兴趣的方法。该方法首先需要对DBLP的数据进行解析,获得解析后的作者姓名信息和论文题目信息,并为了检索的快速在论文题目的信息上建立了索引,接下来就是将获得的论文题目信息进行关键词的抽取,以此作为研究兴趣,并生成关键词的文档进行保存,基于以上工作,接下来就可以通过作者姓名,将关键词信息联系起来,进行搜索。最后通过实验表明,本系统运行速度较为快速,可以较好地提取出作者的研究兴趣。
参考文献:
[1] Wu Y,Venkatramanan S,Chiu D M.A population model for academia:case study of the computer science community using DBLP bibliography 1960-2016[J].IEEE Transactions on Emerging Topics in Computing,2021,9(1):258-268.
[2] 劉小捷,吕晓强,王晓玲,等.基于维基百科类别图的推特用户兴趣挖掘[J].计算机科学,2019,46(9):79-84.
[3] Page Lawrence, Sergey Brin, Rajeev Motwani, et al. The PageRank citation ranking: bringing order to the Web[J]. Computer Science,1998,1(29):1-17.
[4] 池雪花,刘丽帆,章成志.基于学术论文的学者研究兴趣标签发现研究[J].情报工程,2019,5(2):28-39.
[5] 石光莲,杨敏.基于FCA的Folksonomy用户兴趣研究述评[J].现代情报,2017,37(5):172-177.
[6] 黄镇圣.基于Web浏览的高校图书馆用户个性化研究[J].科技信息,2009(12):183.
[7] 石豪,李红娟,赖雯,等.基于folksonomy标签的用户分类研究[J].图书情报工作,2011,55(2):117-120.
[8] 易明,邓卫华.基于标签的个性化信息推荐研究综述[J].情报理论与实践,2011,34(3):126-128.
[9] Weng J S,Lim E P,Jiang J,et al.TwitterRank:finding topic-sensitive influential twitterers[C]//Proceedings of the third ACM international conference on Web search and data mining.New York,New York,USA.New York:ACM,2010:261-270.
[10] Hung C. Huang Y C, Hsu J Y, et al. Tag-based user profiling for social media recommendation[C] //Proceedings of the 2008 Workshop on Intelligent Techniques for Web Personalization and Recommender Systems at AAAI. Hawaii, USA, 2008:49-55.
[11] Stuart Rose, Dave Engel, Nicholas Charles, et al. Automatic keyword extraction from individual documents[J]. Text Mining: Applications and Theory, 2010,3(4):1-20.
[12] Aizawa A . An information-theoretic perspective of tf-idf measures[J]. Information Processing & Management, 2003, 39(1):45-65.
[13] Mihalcea R, Tarau P. Textrank: Bringing order into text[C] //Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
【通联编辑:王力】
猜你喜欢
文理导航(2017年2期)2017-02-16 13:18:46
办公室业务(2016年11期)2017-01-09 18:02:44
中国科技博览(2016年24期)2016-12-28 23:25:48
电子技术与软件工程(2016年20期)2016-12-21 11:11:51
电脑知识与技术(2016年28期)2016-12-21 10:13:14
电脑知识与技术(2016年27期)2016-12-15 20:33:05
电脑知识与技术(2016年12期)2016-06-14 19:10:43
电脑知识与技术(2016年12期)2016-06-14 01:13:57
科教导刊·电子版(2016年11期)2016-06-03 19:01:33
电脑知识与技术(2016年8期)2016-05-19 13:33:11
