
判别增强的生成对抗模型在文本至图像生成中的研究与应用*
2022-05-27 02:05谭红臣黄世华肖贺文于冰冰刘秀平
计算机工程与科学 2022年5期
谭红臣,黄世华,肖贺文,于冰冰,刘秀平
(1.北京工业大学人工智能与自动化学院,北京 100124;2.香港理工大学计算机科学系,香港 999077;3.大连理工大学数学科学学院,辽宁 大连 116024)
1 引言
文本至图像生成任务是一项基本的跨模态图像生成任务,被广泛应用于工业数据库构建、图像编辑、故事可视化和跨模态检索等智能多媒体任务中。随着深度生成模型的发展,一些表现良好的生成模型,例如变分自编码[1]、像素循环模型[2]和生成对抗网络GAN(Generative Adversarial Network)[3]模型等,可以有效地实现文本至图像生成任务。由于GAN在图像生成任务中的出色表现,当前大部分高性能文本至图像生成算法都是基于GAN构建和实现的。2016 年,Reed等[4]首次提出并采用 GAN实现文本至图像生成任务,生成64×64大小的图像;之后,研究人员提出的StackGAN[5]和StackGAN++[6]则是采用多阶段或级联式生成模式将生成图像的分辨率提高至 256×256,并将KL(Kullback-Leibler)散度约束引入模型中以缓解生成图像的模式崩塌现象。Zhang等[7]提出的HDGAN也采用级联式生成模式,并引入局部块判别模型将生成图像分辨率进一步提高至512×512。

Figure 1 Structure of DE-GAN图1 DE-GAN的网络框图
级联式生成模型有效地提升了生成图像质量,但忽视了词汇对生成图像局部语义的引导与增强作用。基于级联式生成模式,注意力生成对抗模型AttnGAN(Attentional Generative Adversarial Network)[8]首次在GAN的生成模型中引入词注意力机制,提出了级联式注意力生成模型,有效辅助了生成模型对图像局部细节语义的生成与刻画。镜面生成对抗网络模型MirrorGAN (Mirrror Generative Adversarial Network)[9]则同时将全局句子注意力和局部词注意力引入生成模型中来增强生成图像全局和局部的语义表达。基于级联式生成模型,在语义增强的生成对抗网络SE-GAN(Semantics-Enhanced Generative Adversarial Network)[10]中,作者提出在SE-GAN中使用注意力竞争机制来帮助词注意力模块过滤非关键词的注意力信息,保留或增强关键词注意力信息,以提高图像关键语义细节的生成质量。接着,在知识迁移的生成对抗网络KT-GAN (Knowledge-Transfer Generative Adversarial Network)[11]中,作者提出了文本-图像交替注意力更新机制,动态且交替地更新词汇特征和图像特征,以增强图像细节的生成。基于级联式生成模式,动态记忆的生成对抗网络DMGAN (Dynamic Memory Generative Adversarial Network)[12]中引入了动态记忆词注意力机制,以降低高阶级联生成图像对初始阶段生成图像质量的依赖,并动态调整词汇对图像局部生成的贡献度。
尽管基于注意力机制引导的生成模型可以有效提升生成图像细节质量,但忽视了判别模型对局部细节语义的感知和捕捉能力。在生成对抗网络训练过程中,判别模型首先通过一系列卷积操作提取图像全局特征。基于图像全局特征,逻辑分类器判别当前图像采样是生成图像分布还是真实图像分布。相比图像模态,文本描述通常覆盖图像的部分语义。缺少文本语义引导,判别模型中的卷积操作很容易忽略图像中与词汇相关的关键语义。由此导致:(1)判别模型对文本关键语义感知能力差。(2)文本和判别模型提取的图像全局特征在语义上出现不一致。这样一来,生成模型容易生成劣质的图像细节“迷惑”判别模型。(3)生成图像与文本描述的语义不一致性。因此,本文的主要策略是在文本至图像生成算法的判别模型中引入文本词汇引导注意力机制,提高判别模型对文本引导的图像局部语义感知能力。
基于以上分析,本文提出了新的文本至图像生成模型—判别语义增强的生成对抗网络DE-GAN(Discrimination-Enhanced Generative Adversarial Network)模型。在判别模型中引入了词汇-图像判别注意力模块,增强判别模型对文本引导图像局部语义的感知,驱动生成模型生成高质量的图像。本文在 CUB-Bird数据集[13]上进行模型训练与测试的实验结果表明,本文提出的DE-GAN在IS(Inception Score)[14]指标上达到了4.70,相比基准模型提升了4.2%,达到了较高的性能表现。
2 文本至图像生成的DE-GAN模型
在文本至图像的生成中,大部分高性能算法都采用级联式注意力生成模型以生成高质量图像,本文也基于级联式注意力生成模型构建DE-GAN。
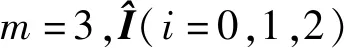
2.1 模块功能和信息流
(1)文本特征编码模型:为了提高文本编码模型对句子结构的鲁棒性,以及句子/词汇的视觉辨识能力,本文采用文献[8]预训练的双向长短时记忆Bi-LSTM(Bi-directional Long Short-Term Memory)网络[14]作为DE-GAN的文本编码模型来提取文本描述特征。模型输入为文本描述,输出为词汇特征矩阵W∈RD×T和句子特征向量s∈RD,其中T表示一个句子中词汇的数量,D表示特征维数。
(2)条件扩张模块Fca:句子特征向量s通过条件扩张模块Fca转化为句子特征向量s*。该模块首次在StackGAN[5]中出现,可以缓解生成图像模式崩塌的问题。
(3)初始化特征过渡模块FTM0:该模块由一系列卷积和上采样层组成。输入为句子特征向量s*和噪声向量z~N(0,1),输出为图像特征H0。

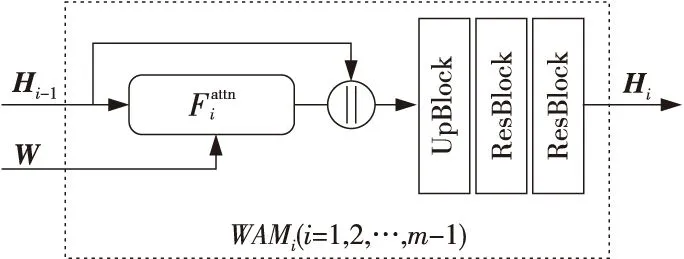
Figure 2 Structure of the word-level attention module图2 词注意力模块的网络结构
DE-GAN生成阶段的信息流形式化表示如式(1)所示:
H0=FTM(z,Fca(s)),
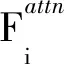
i=1,2,…,m-1,
(1)
(6)判别模型Di:该模块输入为图像(真实图像或者生成图像)、词汇特征矩阵W和句子特征向量s*,输出图像真伪性。
2.2 语义增强的判别模型
基于词注意力辅助的生成模型可以很好地刻画图像细节语义,但判别模型仅通过一系列的卷积模块提取图像的全局特征,缺少对文本引导的关键语义细节的感知能力。这样一来,生成模型很容易生成较差的细节迷惑判别模型。为了提高判别模型对文本引导的关键视觉语义的感知能力,本文在判别模型中引入了词汇-图像判别注意力模块,提出了语义增强判别模型。图3展示的是语义增强判别模型的网络框图,即图1中的判别模型Di的网络结构,其中,H表示图像特征,F1,F2,…,Fn表示卷积模块,n为卷积模块的数量,f*表示图像全局特征向量。

Figure 3 Structure of the semantics-enhanced discriminator图3 语义增强判别模型网络框架
在语义增强判别模型中,词汇-图像判别注意力模块对与词汇语义相关的图像子区域进行特征增强,以提高判别模型对关键语义的捕捉能力。接下来,本节描述词汇-图像判别注意力模块和语义增强判别模型的构建步骤。
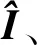
为了增强关键词汇对图像局部语义的刻画,步骤2和步骤3采用DMGAN[12]中的门控机制对词汇特征权重进行调整。

(2)
其中,A和B为1×D的神经感知层,σ(·)为sigmoid激活函数。
步骤3结合词汇特征、图像子区域特征和门控权重,对词汇特征权重进行调整,如式(3)所示:
(3)
其中,Mw和Mr为1×1的卷积操作。

(4)
步骤5对相似性权重矩阵S的元素进行规范化,如式(5)所示:
(5)
步骤6对权重矩阵θ∈RT×N按T的维度取最大值,得到θ*∈RN,称θ*为词汇对图像子区域的相关性权重掩膜。
步骤7利用掩膜矩阵θ*对图像特征H∈RN×D进行特征增强:
H*=θ⊙H,H*∈RN×D
(6)
其中,⊙为哈达玛积。
步骤8将语义增强后的图像特征H*与图像特征H进行特征相加后输入后续卷积模块F2,…,Fn中,提取图像全局特征向量f*。
步骤9判别模型中的逻辑判别器根据图像特征向量f*和句子特征向量s*判别图像真伪性和语义匹配性。
2.3 DE-GAN损失函数
如图1所示,在DE-GAN第i(i=0,1,2)个阶段,生成模型Gi的损失函数LGi和判别模型Di的损失函数LDi分别定义如式(7)和式(8)所示:
(7)
式(7)中,无条件损失函数用来训练生成模型生成逼真图像,以至于判别模型无法判别图像真伪性;基于文本特征的有条件损失函数用来约束生成图像语义尽可能匹配文本语义。
(8)
3 实验与结果分析
本文提出的DE-GAN模型是在技嘉GTX 3090Ti类型的显卡上进行训练的,代码采用Python编写,采用的深度学习框架是PyTorch。
本文实验从定性和定量的角度评价DE-GAN模型性能。定性评价:根据可视化模型在CUB-Bird数据集上的生成图像,主观评价DE-GAN与一些前沿模型生成图像的视觉效果。定量评价:计算模型在CUB-Bird数据集上的IS评价指标,进行客观的分析与评价。
与大部分级联式生成模型[4-9,16-21]的设置相同,DE-GAN一共设置3个模块,即m=3。文本特征编码模型 (Text Encoder)在DE-GAN模型训练阶段的参数是固定的。在模型的测试阶段,其输入只有文本描述。

Figure 4 Image visualization of the proposed DE-GAN model and contrastive models on CUB-Bird dataset图4 DE-GAN和对比模型在CUB-Bird数据集上可视化生成图像质量比较
3.1 数据集及评价指标
CUB-Bird数据集包括11 788幅鸟类的图像,这些图像隶属于200种鸟类,并且每幅图像对应 10条文本描述。本文选择150种鸟类的数据作为训练集,其余50种鸟类数据作为测试集。与大部分文本至图像生成算法一样,本文也采用IS[14]来评价生成图像质量。IS指标越高,图像质量越高,表示模型生成的图像具有更好的多样性和分类准确性。评价过程中采用StackGAN[5]预训练的Inception-V3[22]模型提取图像特征。
3.2 与前沿模型的比较与分析
在定量评价方面,为了评价生成图像的多样性和目标分类的均衡性,表1展示了本文提出的DE-GAN和一系列前沿模型在CUB-Bird数据集上的IS指标评分。如表 1 所示,本文的DE-GAN的IS指标评分达到了4.70,高于大部分前沿模型的表现。
在定性评价方面,本文通过可视化方式将DE-GAN的生成图像与一些前沿模型的生成图像进行比较。如图4所示,相比较AttnGAN模型和SE-GAN模型所生成的鸟类图像,本文的DE-GAN生成的图像质量更好,尤其在鸟类翅膀的生成上,DE-GAN可以生成复杂且逼真的纹理细节。尽管AttnGAN和SE-GAN可以较好地刻画文本描述的语义,但是目标的几何轮廓生成效果较差,而DE-GAN可以生成较好的几何结构。除此之外,本文提出的DE-GAN的生成图像在语义上更能反映文本描述,尤其是局部的语义刻画,包括颜色、属性和几何纹理。

Table 1 IS of the proposed DE-GAN model and contrastive models on CUB-Bird dataset表1 DE-GAN 和对比模型在CUB-Bird数据集上的 IS指标结果
3.3 消融实验
为了验证DE-GAN的有效性,本节进行消融实验结果的展示与分析。
考虑到GPU显存大小,本文提出的DE-GAN一共有3个生成阶段 (m=3),相应地有3个判别模型,本节讨论将词汇-图像判别注意力模块引入第3个判别模型—DE-GAN (D3)、引入第2、3个判别模型—DE-GAN (D3,D2)和引入所有判别模型—DE-GAN (D3,D2,D1)的性能变化,实验结果如表2所示。

Table 2 IS of the ablation experiment表2 消融实验的IS指标结果
表2结果显示,3种模型的性能皆优于基准模型。但是,DE-GAN (D3,D2)和DE-GAN (D3,D2,D1)的性能差于DE-GAN (D3)的。如图5所示,在级联式生成任务中,低阶段生成模型通常更着眼于整体结构和目标轮廓生成,生成图像分辨率过小,这样一来,卷积后的图像特征尺寸容易过小,注意力机制很难将词汇语义准确地对应到相应的局部视觉特征上,容易出现局部语义对应的偏倚性,阻碍判别模型判别。

Figure 5 Image visualization at different stages of the proposed DE-GAN model图5 DE-GAN不同阶段生成图像可视化
3.4 模型局限性与讨论
本文提出的DE-GAN仍然存在着图像生成失败的案例。如图6所示,图中鸟的细节纹理生成质量较高,但是鸟的几何外形生成质量差。这是因为注意力缺少几何属性约束,使得注意力将细节语义倾向于平铺整幅图像。

Figure 6 Failure cases图6 失败案例
未来的工作包括:(1)约束注意力的几何信息,进一步提高注意力信息几何属性的准确性,提升注意力机制在文本至图像生成任务中的表现;(2)将本文提出的词汇-图像判别注意力模块进一步推广到其他图像生成模型中。
4 结束语
本文提出了新的文本至图像生成模型—判别语义增强的生成对抗网络DE-GAN模型,并在判别模型中引入了词汇-图像判别注意力模块,提高了判别模型对文本引导的图像局部关键信息的感知和捕捉能力,驱动生成模型生成高质量图像。实验结果显示,DE-GAN在CUB-Bird数据集上达到了较高的图像生成质量。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
北京航空航天大学学报(2022年8期)2022-08-31
核安全(2022年3期)2022-06-29
保定学院学报(2022年2期)2022-04-07
开放教育研究(2020年2期)2020-03-31
数学大世界(2019年7期)2019-05-28
—— “T”级联
同位素(2019年1期)2019-03-14
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
汽车与新动力(2014年4期)2014-02-27
