
利用麻雀搜索算法优化深度置信网络的入侵检测研究
2022-05-27 10:11:02王家宝缪祥华
化工自动化及仪表 2022年2期
王家宝 缪祥华,b
(昆明理工大学a.信息工程与自动化学院;b.云南省计算机技术应用重点实验室)
随着网络规模的不断扩大和网络技术的不断更迭, 给网络安全带来了更多的问题和挑战,国内外的网络安全事件频发,网络安全问题得到了更多的重视。 近年来,入侵检测技术作为保护网络的有效安全技术被广泛研究,许多研究者引入了神经网络、支持向量机等来予以解决,并且取得了较好的效果。 但是在面对海量复杂数据时,传统机器学习方法在特征学习时易受时间复杂度和空间复杂度制约,导致入侵检测识别攻击数据的准确率低、误报率高[1]。而深度学习在面对海量数据分析时有突出的表现,可用于复杂网络环境下的入侵检测问题。
深度置信网络(Deep Belief Network,DBN)是深度学习中的一个经典模型,是一个由多层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)和一个反向传播神经网络(Backpro Pagation Neural Network,BPNN)构成的深度学习分类器,通过非线性的神经网络结构拟合复杂函数,来提高分类和预测的准确率[2]。 DBN的网络结构指的是网络层层数和每层的神经元数。 DBN的网络结构设置对DBN的性能有着重要的影响。 DBN作为深度学习的经典模型,常被应用在入侵检测领域。 但DBN的网络结构一般由科研人员凭经验设定,如果DBN的网络结构未达到最优,则无法完全发挥DBN的性能。 因此,笔者提出采用麻雀搜索算法(Sparrow Search Algorithm,SSA)对DBN的网络结构进行优化,以提高DBN模型的性能。
1 DBN
DBN由数个RBM堆叠构成,通常会在顶层加入一个BPNN来实现有监督的分类,DBN中下一层的隐藏层就是上一层的可见层[3]。 图1所示的DBN即由两个RBM和顶层一个BPNN构成。
DBN模型的训练分两个阶段[4]:第1阶段是预训练阶段,自下而上分别对每一个RBM进行无监督训练, 得到每一层之间的权重w和每一层的偏置b;第2阶段是微调阶段,自上而下对整个DBN中的参数进行微调,以提高模型性能。 顶层BPNN接收下一层RBM输出的特征向量作为输入,可以进行无监督训练,也可以在输入层中加入标签实现有监督训练。
DBN在特征提取方面的性能较好,通过顶层BPNN的有监督训练可以学习已知攻击类型的网络流量特征,对于未知的攻击类型也可以通过它在特征提取方面的优势提高检测率,适用于需要处理大量网络数据的入侵检测。
2 RBM
RBM是一种随机神经网络,由一层可见层和一层隐藏层构成,一般可见层为输入层,隐藏层为输出层。 RBM同一网络层的神经元无连接,相邻网络层间的神经元全连接。 RBM的网络结构如图2所示。
用向量v表示可见层的状态,向量h表示隐藏层的状态,可见层有m个神经元,隐藏层有n′个神经元,vi表示可见层第i个神经元,hj表示隐藏层第j个神经元,RBM的参数θ={wij,ai,bj},wij为两层神经元之间的权重值,ai表示可见层第i个神经元的偏置值,bj表示隐藏层第j个神经元的偏置值。 则RBM的能量函数E[5]定义为:

当参数确定时,基于能量函数E可得(v,h)的联合概率分布:
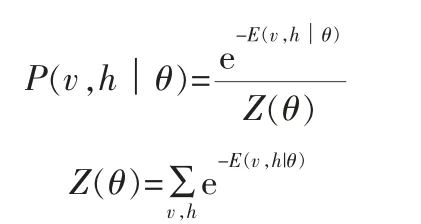
其中,Z(θ)为所有可能情况下的能量和,称为配分因子。
因此,可以得到两层的激活概率分别为:


其中,σ(x)为sigmoid激活函数。
为了尽快得到最大概率,采用对比散度算法训练RBM。 该算法通常仅需要1次迭代就可以得到最大概率。 对比散度算法利用训练数据初始化可见层,通过条件分布概率得到隐藏层,再通过条件分布概率得到最终的可见层,最终得到的可见层就是输入数据的重建。
3 SSA
SSA是于2020年由薛建凯和沈波根据麻雀的觅食行为和反捕食行为提出的一种新型群智能优化算法。 SSA[6]将麻雀分为发现者和加入者,麻雀中发现者和加入者的身份可以互相转换,但是总体比例不变。 发现者负责在全局中搜寻食物资源丰富的区域,加入者会监视发现者,靠近发现者的区域进行觅食或者抢夺发现者的食物。 当麻雀种群发现危险时,处在边缘区域的麻雀会迅速向安全区域靠拢,处在中心区域的麻雀则会随机移动。 SSA的步骤如下:
a. 初始化麻雀种群,定义其相关参数,计算所有麻雀个体的适应度并进行排序,找出全局适应度值最优的麻雀,记录其适应度值及其全局最优位置;
b. 迭代更新发现者、加入者和意识到危险的麻雀的位置,若当前全局最优适应度值比上一代最优值高就进行更新操作, 否则不进行更新操作,继续迭代;
c. 适应度函数收敛或达到满足条件,获得全局最优值和最优适应度值。
SSA与其他传统优化算法相比, 具有收敛速度快、 精度高和不易陷入局部最优值的优势,更容易获得优化问题中的全局最优解。 因此,笔者采用SSA对DBN进行优化。
4 SSA优化的DBN模型
4.1 模型总体框架
DBN在特征提取方面具有较好的性能,适用于入侵检测技术。 DBN的网络结构是否为最优决定了DBN的性能是否为最佳。 但是研究者凭借经验设定的DBN网络结构无法完全发挥DBN的性能。 因此,笔者用SSA优化DBN得到新的入侵检测模型SSA-DBN。 使用SSA优化DBN的核心思想就是得到位置最优的麻雀, 也就是适应度最高的麻雀个体, 在迭代结束时根据此麻雀的参数设置DBN的最优网络结构,得到最优的入侵检测模型。基于SSA-DBN的入侵检测模型框架如图3所示。
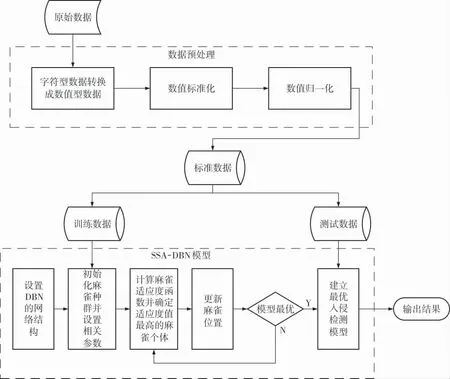
图3 SSA-DBN入侵检测模型框架
SSA-DBN入侵检测模型分为数据预处理模块和SSA-DBN模块。 数据预处理模块的功能是处理原始数据,使处理后的数据可以输入SSA-DBN模块。 SSA-DBN模块的功能是对输入数据进行分类,识别攻击类型的数据。
4.2 数据预处理模块
数据预处理共分为3个步骤:
a. 字符型数据转换为数值型数据。由于入侵检测数据集中的某些特征是字符型数据,而DBN只能处理数值型数据,因此将该数据集中的字符型数据转换成数值型数据。


4.3 SSA-DBN模块
SSA-DBN模块的功能是对输入的数据进行识别分类,可分为两个步骤:
a. 使用训练数据集对SSA-DBN模块进行训练和参数调优,得到最优入侵检测模型;
b. 将测试数据集输入到训练好的SSA-DBN模块中得到分类结果。
该模块基本步骤伪代码如图4所示,其中,I为最大迭代次数,PD为麻雀中发现者的数量,SD为发现危险的麻雀的数量,A为警戒值,s为麻雀种群的数量,F(X)为适应度函数,X表示DBN的网络结构。
该算法首先随机初始化麻雀种群的数量并定义相关参数,计算并找出当前适应度函数的最优值。 然后更新麻雀的位置,再次计算当前适应度函数的最优值,若为最优,则X为DBN最优的网络结构参数,否则继续更新麻雀位置直到获得最优值或达到最大迭代次数。 最后根据最优参数构建最优入侵检测模型进行识别分类操作。
5 实验
5.1 实验数据
本次实验采用UNSW-NB15入侵检测数据集,该数据集中共包含10种类型的数据, 其中1种为普通类型的数据,9种为攻击类型的数据,每条数据共有49种特征。 9种攻击类型的数据分别为模糊攻击(Fuzzers)、分析攻击(Analysis)、后门攻击(Backdoors)、拒绝服务攻击(DoS)、漏洞攻击(Exploits)、 泛型攻击(Generic)、 侦察攻击(Reconnaissance)、恶意代码攻击(Shellcode)和蠕虫攻击(Worms)。该数据集中共包含2 540 044条数据,在该数据集中已经进行了训练数据集和测试数据集的划分,训练集中共有175 341条数据,测试集中共有82 332条数据。
5.2 实验环境与评价标准
实验使用Python V3.6作为编程语言,并使用Tensorflow框架进行实验。
使用4个评价指标对本次实验进行评估,分别是P(精度)、AC(准确率)、R(召回率)和F1(F1-measure)。
在实验中,根据预测和实际是否一致可以分为真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。 真阳性为预测和实际都为真;真阴性为预测和实际都为假;假阳性为预测为真,实际为假;假阴性为预测为假,实际为真。
精度为正确预测为真的占全部预测为真的比重,其公式为:
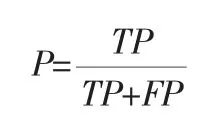
准确率为所有正确预测的占全部预测的比重,其公式为:

召回率为正确预测为真的占全部实际为真的比重,其公式为:

F1-measure的公式为:

5.3 实验结果与分析
为使结果更加客观, 进行多次重复实验,结果显示,多次实验的差值较小,实验数据较稳定。
对多次实验结果求平均值进行分析,结果如图5所示, 可以看出,SSA-DBN模型的准确率为92.05%, 召回率为90.62%, 精度为94.23%,F1-measure 值 为92.38% ;DBN 模 型 的 准 确 率 为90.86%, 召回率为88.65%, 精度为93.31%,F1-measure值为90.91%。SSA-DBN模型对比未优化的DBN模型的4个评价指标均有所提高, 说明SSADBN模型有效提升了入侵检测的效率。
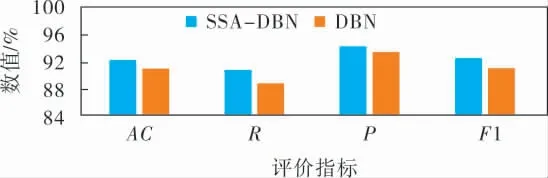
图5 模型性能评估结果
SSA-DBN、RepTree、LR-RFE和HMC 4种模型的准确率对比如图6所示,可以看出,文献[7]提出的RepTree模型准确率为88.95%,文献[8]提出的LR-RFE模型准确率为88.27%,文献[9]提出的HMC模型准确率为80.78%,而SSA-DBN模型的准确率达到了92.05%。 说明SSA-DBN模型比其他3种模型在UNSW-NB15数据集上的准确率具有明显优势。
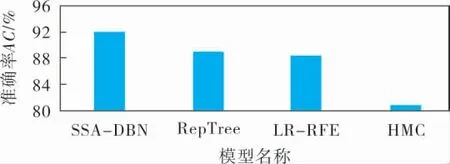
图6 4种模型的对比结果
6 结束语
DBN的网络结构对其性能起到重要的作用,笔者提出用SSA优化DBN,通过找到麻雀的最优适应度值确定DBN的网络结构,使SSA-DBN模型达到最优,提高了模型的检测性能。 通过实验分析,SSA-DBN模型相比传统DBN模型在各项评价指标上都有更优异的表现, 与RepTree、LR-RFE和HMC3种模型相比也具有一定的优势。 如何解决数据集中各种类型数据的平衡问题, 继续提高模型的检测性能, 是笔者需要进一步研究的方向。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
作文小学中年级(2019年10期)2019-11-04 00:39:52
新世纪智能(高一语文)(2018年11期)2018-12-29 11:32:06
趣味(语文)(2018年2期)2018-05-26 09:17:55
中国塑料(2016年11期)2016-04-16 05:26:02
山东青年(2016年1期)2016-02-28 14:25:22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
