
面向联邦学习的本地差分隐私设计
2022-05-27 06:55:12张昊
智能计算机与应用 2022年5期
张 昊
(东华大学 计算机科学与技术学院,上海 201620)
0 引 言
联邦学习(F-L)作为一种分布式部署的深度学习的框架,不仅让多方共同完成一个训练目标模型,而且摒弃传统的深度学习中数据集都需要统一部署在服务端的特性。每个分布式的客户端(分布式的节点)仅需各自在本地储存自己私有的数据集,并且无需上传私有数据集给服务器。因此理论上联邦学习相比传统的集中式训练的方法更有效地保证客户端的隐私。但是现在仍有可能泄露客户端私有隐私。攻击者可以通过观察客户端的上传的信息,并且通过某些手段,例如成员推理攻击推断出客户端的隐私信息,从而泄露了客户端的隐私。因此违背了联邦学习满足隐私保护的特性。
在联邦学习的环境下,常用的隐私保护手段有同态加密和本地差分隐私。其中,同态加密由于是密码学的方法,优点是不降低数据的准确性,可以有效地还原隐私数据,缺点是同态加密的加解密和通信代价很高。本地差分隐私本质是扰动数据,因此优点是适合计算性能较差的设备,例如移动设备,缺点是会牺牲一定的效用性,因为添加的噪声是随机的,而且估计值会有一定的方差。
基于此研究时立足于联邦学习情况下,本地差分隐私更加适用于保护客户端的隐私。但是少有人研究本地差分隐私与模型精度之间的影响。因此本文考虑随机响应以及优化一元编码机制下,探讨的个数、、客户端数量、扰动机制和数据分配方式对模型精度的影响。本文还设计了自适应隐私预算策略,可以根据相邻轮模型相似度来提升模型的收敛速度。
1 隐私保护联邦学习实现
在权重聚合的框架中,客户端在每轮训练结束后上传的是模型权重,并且聚合的过程是Federated Averaging算法。在此基础上,本文设计权重聚合的隐私保护系统实现,具体如算法1所示。
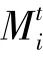
:联邦学习中参与客户端总数,每个客户端记作p(1≤≤)
:每轮参与训练客户端数的比例
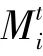
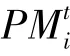
DB:p的训练数据集
:本地训练最小批量尺寸
:训练迭代总轮数
E:本地总迭代轮数
:学习率
1:Parameter Server Executes:
2:←服务器初始化全局模型
3://客户端分配数据集
4:()
5:for epochin()do
6:for client∈Sdo
7://更新模型
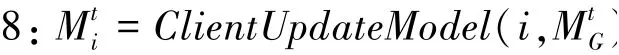
9: //上传前扰动模型权重
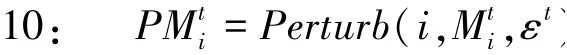
11:end for
12://聚合估计扰动模型
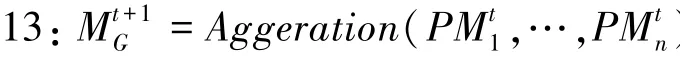
14:end for
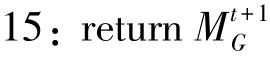
16://权重聚合下训练模型
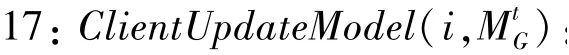
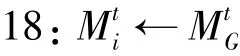
19:←DB随机分成大小为的批量
20:for local epochin range E( )do
21: for batch∈do
22: //小批量梯度下降
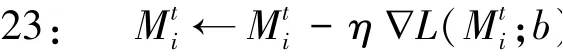
24: end for
25:end for
1.1 随机响应机制实现与分析
此章节主要描述常用2种本地差分隐私机制随机响应,优化的一元编码在联邦学习的裁剪、编码、估计的具体实现,并且优化本地差分隐私在服务器端聚合速度。
1.2 扰动机制实现步骤
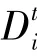
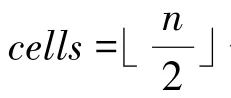
(2)编码:客户端中第个数据记作p,映射后所有状态数为,这里的数学公式可写为:
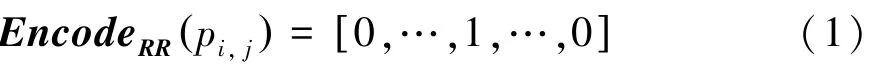
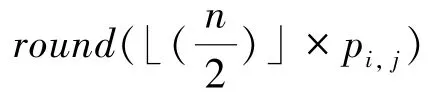
(3)扰动:对于随机响应机制,经过RR编码后的数据需要扰动后才能上传给中心服务器:
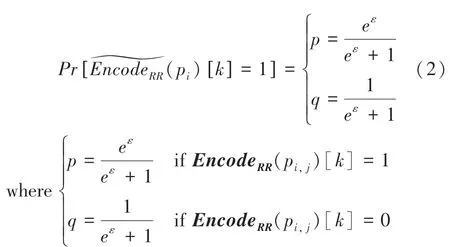
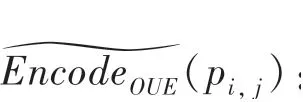
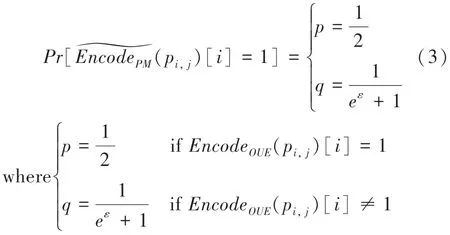

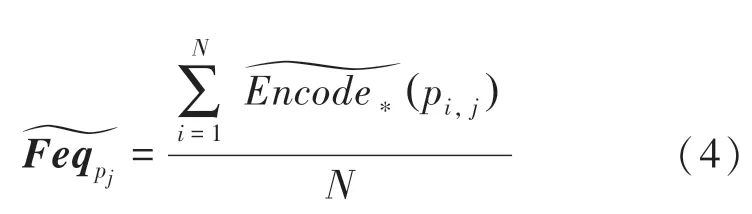
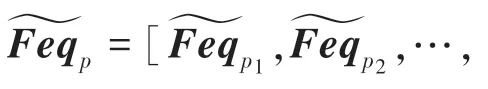
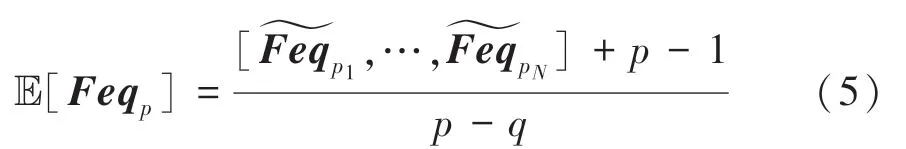
其中,E[Feq ]是一个维的变量矩阵。
然后模型参数的估计状态数频率的矩阵需要转化为真实估计值E[],具体如下:
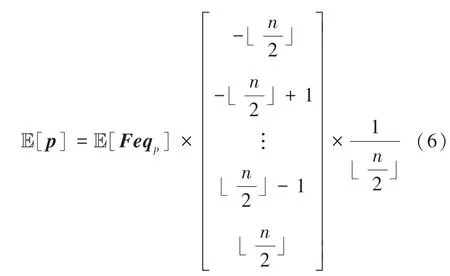
其中,E[]是一个维向量,是聚合后的全局模型参数。
聚合的过程利用到矩阵的乘法,因此时间复杂度从()减少至(1),大大提升服务器端聚合时间的速度,减轻中心服务器的运算压力。而且当模型规模越大,节省的时间越多。
(5)估计方差:为简化讨论,这里只考虑聚合时全局模型的一个模型参数的方差变化,由于每个模型参数是不相关的。所以在Wang等人基础上计算方差,对应的公式可推得为:
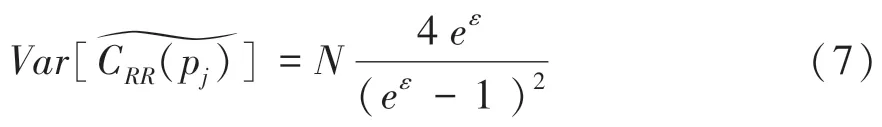
显然,估计模型参数的方差是与正相关,即,更多的参与者会带来更多的方差。
2 自适应隐私预算分配
本文在实验基础上观察同精度不同隐私预算下的收敛速度,提出自适应隐私预算分配的保护策略。该策略能够让联邦学习在训练过程中,保证总隐私预算不变的情况下,动态分配客户端的隐私预算。好处是能够提升模型的收敛速度。
2.1 同精度不同隐私预算的收敛速度
不同扰动机制的收敛速度比较如图1所示。观察图1就会发现,随着隐私预算增加,模型的收敛速度整体是上升的。

图1 不同扰动机制的收敛速度比较Fig.1 Comparison of convergence rate with different perturbation mechanism
2.2 自适应隐私预算策略实现
因此本文考虑到模型最初开始训练时,由于模型没能有效地记住训练集的数据,所以模型能够泄露的训练集数据较少,导致隐私泄露率很低,因此可以用较大的隐私预算来提升模型的收敛速度。当模型逐渐接近于收敛时,模型本身记住有关训练集的信息会逐渐变多,因此需要逐渐减小隐私预算来保护模型,详见算法2。

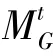
6:()
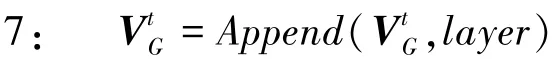
8:end for
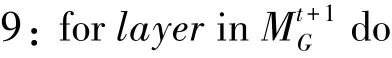
10:()
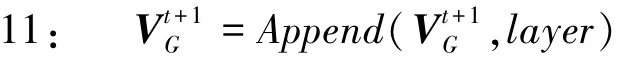
12:end for
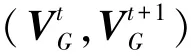
14:returnε
15:
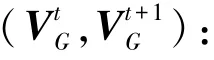
17://cosine similarity
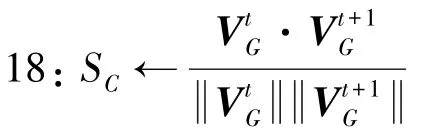
19://Angular distance and similarity
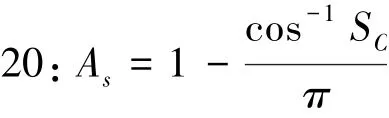
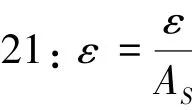
22:return
综合前述可知,对于相关的步骤可给出阐释论述如下。
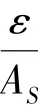
3 实验
3.1 实验设置
本文在pytorch1.8进行实验,实验硬件设置见表1。

表1 隐私保护联邦学习实验硬件配置Tab.1 Privacy-preserving F-L hardware configuration
本文实验中联邦学习的客户端数目为1 000个,默认参与训练比例为0.5。和分别训练500,1 000轮。实验的模型-数据集为LeNet-MNIST和DNN-Purchase-100。MNIST和Purchase-100分别作为常用的数字识别数据集与成员推理攻击的数据集。LeNet和DNN模型的学习率在非扰动情况下,分别为0.1和0.001;扰动情况下,分别为0.1和0.01。LeNet使用SGD优化器,DNN使用Adam优化器。下LeNet和DNN的基准模型精度分别为0.988 5、0.909 8;非下LeNet基准模型精度为0.986 6。
隐私预算的值设为0075*2的幂指数为单位,取值范围为0~7(2代表隐私预算值为0075*2),精度损失率的范围设为0~1,以0.1间隔递增,隐私泄露率为0.45~0.75,以0.1间隔递增。
经过本地差分隐私保护的模型,扰动后模型收敛的精度相较于扰动前模型收敛的精度损失的百分比(%),其值可由如下数学公式计算得出:

当精度损失率接近0时,代表扰动后的模型精度相较于原模型精度几乎无损失。当精度损失率接近于1时,代表扰动后的模型精度损失很高,即扰动后模型几乎不可用。
3.2 隐私保护联邦学习分析
3.2.1个数对精度损失率影响
在扰动模型权重的框架下,无论数据集是还是,精度损失率都会随着数量的增加而减小。对精度损失率影响如图2所示。因此为了此后的研究考虑,在模型尽可能满足收敛的情况下,这里选择最小的(在图2中以红色星号表示)并继续后文的实验。
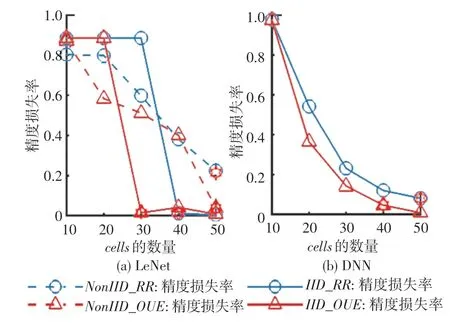
图2 cells对精度损失率影响Fig.2 Impact of cells on accuracy loss
3.2.2 隐私预算对精度损失率影响
隐私预算对精度损失率影响如图3所示。实验结果表明,对于模型的精度损失率来说,精度损失率会随着隐私预算的增加而减小。原因是当隐私预算变大,扰动机制所添加的噪声也会变少,扰动模型权重的变化较小,从而提升模型的精确度。当隐私预算足够大的时候,扰动模型权重的变化几乎可以忽略不计,那么模型收敛后的精度几乎等于不扰动模型收敛后的精度,即精度损失率接近于0。当隐私预算足够小的时候,由于扰动模型权重的变化太大,会导致模型无法收敛,因此模型的精度损失率很高。
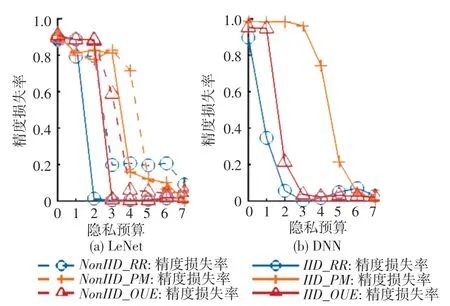
图3 隐私预算对精度损失率影响Fig.3 Impact of privacy budget on accuracy loss
3.2.3 客户端数量对精度损失率影响
客户端数量对精度损失率影响如图4所示。由图4可知,观察到当客户端数量增加,精度损失率会逐渐下降。本文认为原因是当客户端数量比较少的时候,本地差分隐私添加噪声后,虽然估计方差小了,但是估计均值到真实均值附近的概率较小,因此获得的估计值与原先的均值的方差区别较大,导致模型不容易收敛。当客户端数量比较多的时候,纵使算法和算法的方差变大,但是估计值到真实均值附近的概率较大,因此训练扰动模型中间值和正常训练模型中间值近似,所以模型的收敛后精度损失率较小。
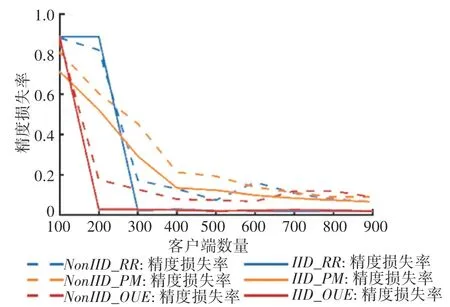
图4 客户端数量对精度损失率影响Fig.4 Impact of number of clients on accuracy loss
3.2.4 自适应隐私预算策略结果
自适应隐私预算策略实现对比如图5所示。在图5中,自适应隐私预算可以提升模型的收敛速度。实验发现LeNet相较于DNN模型能够显著地提升模型的收敛速度,原因是LeNet模型能在初始10个轮次提升精度至0.6~0.8,但是DNN模型却需要100~300轮才大致提升精度至0.5~0.7。因此如果只看2个模型的相邻2轮的近似度,LeNet的相邻轮变化明显,所以提升收敛速度明显。
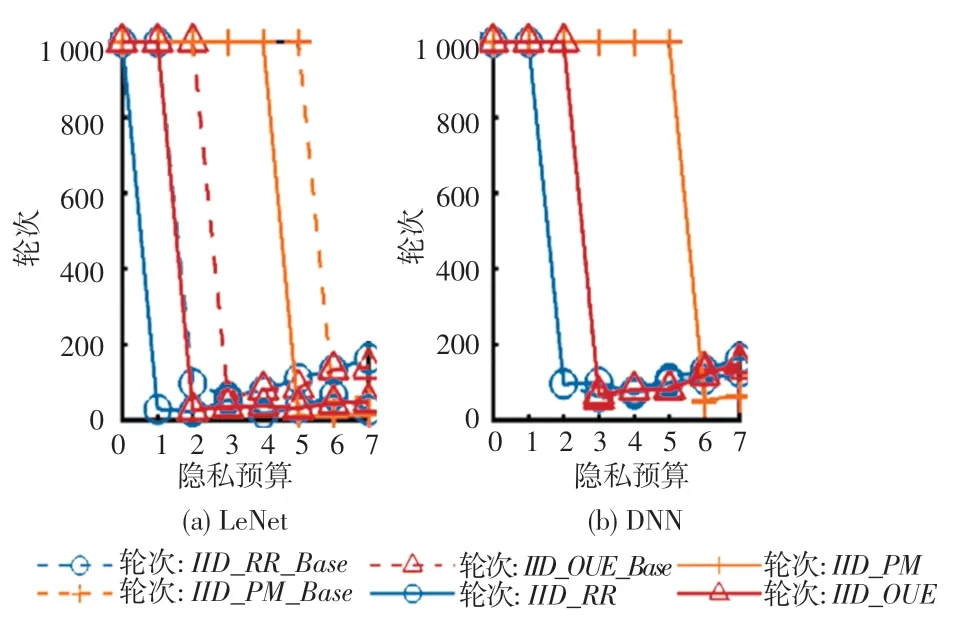
图5 自适应隐私预算策略实现对比Fig.5 Comparison of adaptive privacy budget strategy implementation
4 结束语
本文研究本地差分隐私机制和在权重聚合的联邦学习上实现隐私保护并优化服务端聚合速度近似从()减少为(1),同时评估的个数、、客户端数量、扰动机制和数据分配方式对模型精度影响,精度损失会随着数量、、客户端数量的增加而减小。同等下,会比的精度损失高,和的精度损失类似;同时实现自适应隐私预算策略提升模型训练速度,近似提升一个等级的收敛速度。
在此基础上,本文仍存在需要改进之处。本文并未评估梯度聚合框架下的效果。同时还未评估联邦学习下本地差分隐私对隐私泄露的影响。另外,本文现有的数据集不够全面,只有2类典型数据集,有待进一步研究解决。
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-05-25 12:17:42
今日农业(2021年1期)2021-11-26 07:00:56
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09 06:09:10
家庭影院技术(2020年10期)2020-12-14 07:54:16
应用数学(2020年2期)2020-06-24 06:02:38
家庭影院技术(2019年7期)2019-08-27 02:42:06
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:32
初中生世界·九年级(2017年10期)2017-11-08 21:30:36
海外星云(2016年19期)2016-10-24 11:53:42
中国蜂业(2016年3期)2016-09-06 09:03:17
