
基于MATLAB的复合因子方差分析与主成分分析算法
2022-05-26 06:59薛亚宏程喜林
绵阳师范学院学报 2022年5期
薛亚宏,王 嘉,程喜林
(1.甘肃工业职业技术学院电信学院,甘肃天水 741025; 2.兰州大学信息科学与工程学院,甘肃兰州 730000;3.西北大学城市与环境学院,陕西西安 741069)
0 引言
方差分析(Analysis of variance,ANOVA)是英国统计学家兼遗传学家Gitbert C G提出的一种分析方法,在林业遗传、科学试验、医学研究等众多领域有极其广泛的应用[1].方差是统计量分析中的一类,是假设检验与区间估计的推广和延伸,随着试验样本的成因方式不同,一般采用的分析方法也有所差异,在统计学界,通常用单因子(one-way)、复因子(double-way)或多因子(N-way)方法.
主成分分析是根据已有数据推断假设数据受某主要因素影响程度的的一种分析方法,其本质仍为假设检验[2].通常需要提供理论样本结果和实测样本结果,两者通过矩阵排列得到回归模型,最终得到影响总体数据分布的主要因素及数值,一般要采用二维或三维曲线进行二次以上模拟,在误差允许范围内满足达到精度即终止计算.
1 复合因子方差分析

以上采取药物作为分组的依据,称为复因子(Complex factor),它们的差异均值称为复水平.其中m值与p值较为关键,直接影响概率值p<∝的置信度及拒绝假设目标H0,否则假设不成立,疗效分析验证为假.
在MATLAB中,函数anova1()、anova2()可分别进行单因子、复因子分析,并能得到较为精确的结果,以anova1()为例,其基本格式为[p,Tab,Stats]=anova1(Q)[3].其中,Q为需要分析的数据,该数据是一个k×w矩阵,其行对应于分组号,运算结果会返回概率p、方差表Tab、统计量Stats;该函数还将打开两个主程序窗口viewer,power,分别以表式、盒式结构呈现.
1.1 单因子分析(疗效分析方向)

案例1:以非吗啡类中枢型镇痛药物盐酸曲马多(Tramadol)为例[4],现将40个病人(医学低于30为小样本)样本分为6组、每组5人,患者(patient)使用同一药物(假定无其他辅助药物),记录从用药到痊愈时间(h),观测所用药物的疗效是否存在显著差异,观测数据如表1所示.
算法设计:
基于以上监测数据,现构造出一个6×5型矩阵,命名为矩阵Q,对各组数据采用复因子方差分析,得出以下分析结果:
t=[5.6,3.9,6.2322,5.2355,7.1112],p=[0.00551];
执行anova1( ):
》Q=[3,5,8,5,2;8,7,6,8,4;5,1,3,5,6;6,8,4,5,6;3,4,4,4,6;3,5,7,4,4];
m=mean(Q);
[p,Tab,Stats]=anova1(Q);
在程序运行过程中,anova1( )会自动呈现两个窗口,分别是盒式图、分析表,同时显示概率值p=0.005 51<α,其中α=0.03或0.04表示置信水平,显然从结果来看应拒绝假设,即药物对痊愈时间有显著影响.
1.2 双因子分析(植物培育方向)
案例2:以岩松、油松、赤松3种松树树种在甘肃省天水市小陇山林区党川、利桥、草川、草滩4地(林场)的生长情况为例,每地每类树种选择6株,测量其胸径,并进行双因子方差分析,观测数据如表2所示:

表2 甘肃省小陇山林区岩松等3类松树生长观测数据Tab.2 Observation data on the growth of three types of pine trees including Yansong in Xiaolongshan Forest Area, Gansu Province
数据来源:甘肃省小陇山林业实验局林业科学研究所
算法设计:
根据表中观测数据,构建矩阵H.然后调用anova2( )函数进行双因子分析,对各组数据采用双因子方差分析,anova2( )命令及矩阵列排列如下:
》H=[25,14,17,30,21,27,31,23,13,19,22,13,31,28,27,13,28,21,13,16,16,18,21,21;
12,23,24,21,16,16,16,23,19,14,21,23,22,23,31,17,29,16,14,19,26,25,14,21;
21,26,20,12,16,19,12,18,18,16,20,13,12,23,14,13,13,21,13,26,22,30,16,19];
anova2(H',6);
执行结果:
Totalmm=0.139 3,ColumnSS=358.1,RowsMS=16.55,Interactiondf=0.475 5
从结果来看,由于PA=0.013 93,所以应该拒绝H1假设.可以初步推断,列数据对监测结果有显著影响,即小陇山林区下辖党川等4地3类松树树种对其胸径有显著影响.
以下计算均值,以反映不同树种在同一林场生长差异:
》D=[];
for m=1:4,for n=1:3,
R(m,n)=mean(H(m,[1:6]+(n-1)*6));
end,end
R=[R;mean(H)];
R=[R mean(R')']
均值计算结果如下:

根据结果分析,赤松胸径明显大于岩松和油松.PH与PHQ的距较大,从而判断假设为真,故接受假设[5].即党川等4地各自对3类松树树种的胸径有轻微影响,不同区域(林场)对不同松树树种胸径成长无显著影响.
2 主成分分析
主成分分析是一种常见的多因素分析方法,在信息模拟、疾病预防、地理信息采集、工程造价测算、农作物产量分析等领域有着广泛应用.通常采用SPSS、R等平台进行分析,但受限于源数据类型的多样性,输出图形的特征的两极分化(异端非同步)现象较为普遍,经与实际监测比对出现较大偏差,结论不稳定,因此不具有代表性.在这种情况下,利用MATLAB在数据降维处理方面的精度、效度以及在图象表现上的多维仿真优势,通过调用Corr( )函数(Corr( )用来计算两组列向量a和b的相关性,表达式为Corr(a,b)),建立协方差矩阵及特征向量、主成分贡献率及累计贡献率、建立变量指标方程组对数据进行降维处理,实现源数据分析从多维到低维的转化.
2.1 基于MATLAB的主成成分析算法原理
假设某事件受N个因素(可记为k1,k2,…,kN)影响,监测数据有M组,可构建M×N监测数据矩阵K,再基于K建立协方差矩阵R,其矩阵元素为相关系数ri,j

其中:

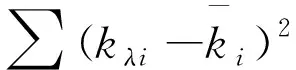
根据R计算出特征向量ei及特征值,做反序处理;然后计算主成分贡献率τi,累计贡献率δi(基于主成分贡献率的并行求和);最后,通过转换变量(降维),构建平面坐标方程zi=azi+bzi+Ri,获取主体变量影响因素间的关系构成,即主成分分析的基本表达式.
2.2 三元主成分降维分析(高程测量方向)
案例3:以甘肃省天水市李子园铅锌矿第四纪浅层地貌特征分析为例,某测量点三维坐标参数分别为x=ωcos2ω,y=ωsin2ω,z=0.887x+3.463y,现通过MATLAB生成一维数组,并输出以2个测量数位为基本单位矢量模拟表达式.
算法设计如下:
》ω=[0:0.2:3*pi]';
x=ω.*cos(2*ω);
y=ω.*sin(2*ω);
z=0.887*x+3.463*y;
S=(x y h);
R=corr(S);
[e,d]=eig(R),d=diag(d);
plot3(x,y,z)
显然,基于对降维矢量输出原理的分析,进一步利用空间坐标变换,对三维源数据做放样投影,得到二维数组[6].
执行以上命令,输出结果为:
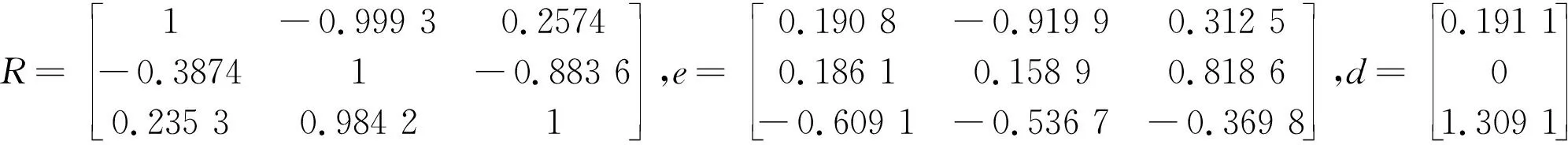
值得注意的是,结果中的d向量、e向量非测量高程测序排列,要通过fliplr()函数和real()函数执行反序和翻转输出,目地是使特征值按常规测序呈现,为RNSS测绘系统数据导入做必要的前期配置.
具体语句如下:
》d=(end:-1:1); %对矩阵d进行反序处理
e=fliplr(e); %对矩阵e进行左右翻转
D=[d';d';d']; %对矩阵d进行转置
M=real(sqrt(d)).*e; %对矩阵d求平方根取实部
Z=S*M; %三维坐标矩阵与主成分矩阵M做积运算
plot(Z(:,1),Z(:,2)) %第1、2列散点输出
主成分贡献率γi和累计贡献率δi可分别用以下公式求得:
本例主要侧重对主成分降维分析,故转换后的3*3矩阵提供二维数据(z列为0)如下:

故新坐标系可表示为:
该坐标方程实现了对三维高程测量数组的降维(纵向投影),通过坐标转化使RNSS源数据压缩于二维平面上,一方面能准确表现该区域第四纪地貌分布特征,另一方面在同类型矿区主要作业区域地形图绘制(表层、浅层)中提供了满足绘制精度要求的一种新的计算途径,其误差范围与多基点均匀采样在同一水平[7].但其在数据生成原理、仿真形式以及中间变量转换等多个方面集成了ArcGIS、C++的优势,有效降低了测图成本.
3 结语
基于MATLAB的方差分析与主成分分析数学原理清晰,算法逻辑性强,语法较为灵活.在实践中,以数理统计基本实义为基础,利用矩阵计算、坐标变换等方法,通过MATLAB实现对样本数据的处理,能有效弥补SPSS、R等工具无法进行数据降维的不足.特别是在三维数字测图、工程概预算、造价分析等领域能大幅降低数据交互,在一定精度范围内能有效降低项目成本,具有较强的实用意义.
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
海峡姐妹(2019年12期)2020-01-14
读与写·教育教学版(2017年10期)2017-11-10
领导文萃(2017年11期)2017-06-12
科技视界(2016年16期)2016-06-29
高教探索(2015年10期)2015-10-29
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
