
基于爬虫技术的安全评价指标数据主动采集的研究
2022-05-25 14:08张元
华北科技学院学报 2022年1期
张 元
(华北科技学院,北京 东燕郊 065201)
0 引言
爬虫技术因其能够快速主动地采集数据被广泛应用于各行各业当中。闫志国等[1]使用爬虫技术对销售药品的网店进行数据采集并进行分析,获取药品销售情况,为顾客网购药品时提供帮助。曹睿娟等[2]为了探究如何应对城市内涝时的网络舆情,通过以真实城市内涝事件作为样本,使用爬虫技术动态采集城市内涝时网络舆情数据,经过对数据分析后得出了城市内涝时网络舆情关注的重点内容及其演化过程,为城市内涝时网络舆情的应对提供了帮助。于凤芹等[3]通过运用爬虫技术采集商业银行金融科技发展的相关数据,并且借助动态面板模型和多重中介效应模型分析得出了金融科技与商业银行盈利能力间的关系及传导机制。饶加旺等[4]运用爬虫技术采集了网上近期以智慧城市为关键词的各类研究数据,通过构建智慧城市文本库与分类模型,深入分析了智慧城市的研究主题、热点及现状,指出了当前智慧城市建设中的问题,为智慧城市的建设提供了参考。目前行业信息透明化的程度在不断增加,企业在安全评价过程中所需要的指标数据大多可以在各企业对应网站内采集到,因此爬虫技术也可以应用在安全评价指标数据主动采集阶段。
1 安全评价指标数据主动采集与被动采集的对比
企业在进行安全评价时安全评价指标数据的采集分为被动采集和主动采集,在过去很长一段时间受制于技术等相关因素,安全评价指标数据的采集大多依赖于被动式采集,传统安全评价指标数据的被动采集容易使安全评价结果具有主观性和滞后性,同时还造成安全评价的低效率,而现代企业要求安全评价具有客观性、及时性、高效性,显然继续对安全评价指标数据进行被动采集已经不能满足企业的需求,故实现安全评价指标数据主动采集十分必要。
2 基于爬虫技术的安全评价指标采集
随着互联网的不断发展以及大数据时代的到来,从大数据中获取有价值的信息数据,已经是目前热门的研究及实践方向的一种。Python是该领域中使用较多的程序语言,成为数据采集过程中不可或缺的工具,原因就是Python技术库具有突出的计算能力和丰富的计算方法。对于安全评价指标数据的主动采集,主要属于对非结构化数据的采集,因此可以采用爬虫技术来实现这一目标,具体是通过数据采集与存储、数据量化、数据预处理来得到量化的相关安全评价指标数据,来完成安全评价指标数据的采集工作。
运用爬虫技术实现安全评价指标数据采集的过程如下,第一步是使用Xpath Helper访问并返回DOM的根节点,第二步是运用Scrapy框架爬取煤企网站中相关的数据,第三步中对于数据的存取运用了Sqlalchemy引擎,第四步数据清洗使用的是Numpy、Pandas库中的相关函数,完成上述操作最终得到有效数据。
2.1 Scrapy框架介绍
Scrapy框架编写的目的是根据用户需求爬取网站数据,其可以广泛应用于数据挖掘和信息处理中。Scrapy框架主要由调度器、下载器、爬虫和实体管道、Scrapy引擎五大组件构成[5-6]。调度器的功能有两点,分别是确定下一个抓取的网址和对网址进行去重处理,调度器可由用户自主设置。Scrapy下载器的功能是下载网页内容。用户可以根据自己的需求定制爬虫,爬虫能够执行两个操作,一个是向目标网页爬取信息,另一个是可以从目标网页中提取出链接,让Scrapy继续抓取下一个网页。实体管道负责处理爬虫从网页中抽取的实体,它的主要的功能有三个,分别是持久化实体、验证实体的有效性和清除不需要的信息[7-8]。
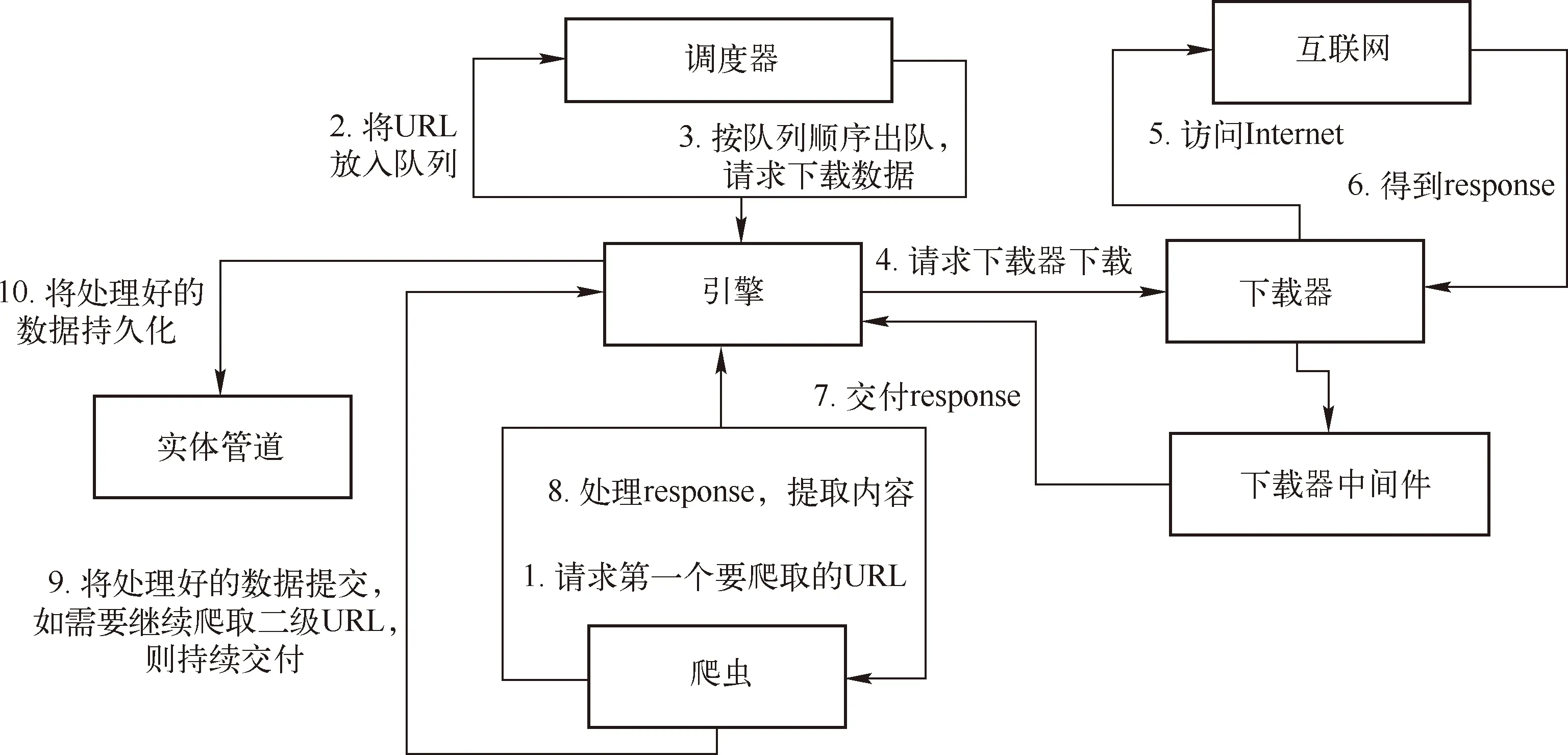
图1 Scrapy爬虫框架
2.2 安全评价指标数据采集、量化和预处理
2.2.1 安全评价指标数据采集
前期调研阶段,通过对《企业安全生产标准化基本规范》、《职业健康安全管理体系》等相关法律法规进行研究[9-10],在参考相关文献基础上形成通用安全评价指标体系包括7个一级指标,19个二级指标,7个一级指标具体包括:组织所处的环境、领导作用和员工参与、策划、支持、运行、绩效评价和改进。其中组织所处的环境包含四个二级指标分别是组织及其所处的环境、员工需求和期望、管理体系的范围、管理体系。领导作用和员工参与包含四个二级指标分别是管理层承诺、方针、职责与权限、员工参与。策划包含两个二级指标分别是应对风险的措施、目标及其策划。支持包含五个二级指标分别是资源、能力、意识、沟通、文件化信息。运行包含两个二级指标是危险源辨识和风险控制、应急准备和响应。绩效评价包含三个二级指标分别是绩效测量和监视、内部审核、管理评审。改进包括两个二级指标分别是事件、不符合和纠正措施、持续改进。根据安全评价指标体系设计出如图1所示的数据表结构。选择某煤企官方网站及第三方统计网站作为数据来源。

表1 统一字段数据表结构
安全评价指标具体信息的采集过程如下:首先,当进入指定网页内,通过网页源码查看页面内所有的信息标签,找到用户所需的信息标签,进而爬取该信息标下用户所需的数据。然后,通过使用相关插件获取已爬取数据的标签间的关系,并且对已爬取数据进行正误检验。第三个操作是在不违法违规的前提下向Headers中加入代理IP地址,原因是一部分网站存在反爬虫机制。最后,使用SqlAlchemy对数据进行操作。
2.2.2 安全评价指标数据量化
存在部分安全评价指标并非以定量形式存在而是以文字描述的形式,对于这类数据应结合企业管理实际的现状,分析数据并使用一定方法使其量化,数值范围介于0到1之间,使其经过采集后以定量的形式存储于数据库,以便于进行后续的安全评价。
2.2.3 安全评价指标数据清洗
安全评价指标数据清洗阶段主要包括对缺失值的检验,去除所采集到的重复数据以及统一所采集到数据的数据格式等。
在数据清洗阶段,首先对爬取的全部数据进行检测,对于其中的缺失值用pandas中的fillna()方法填充。数据去重阶段首先确认重复数据并计算其个数。为了对确认的重复数据的准确性进行检验,通常的方法是用query()函数对任意一个标题执行选择行操作,接着使用count()方法计算该数据表余下的数据量,清除数据表中的重复项可使用pandas库的drop_duplicates()函数。当需要再次清除数据表中重复项时可以使用一张新数据表。
数据格式统一:去除重复项后的数据存储在数据库中。表2是数据库中存储的部分数据。
表2 数据库中部分数据结果
2.2.4 小结
经过以上安全评价指标的数据采集、数据量化、数据清洗等步骤,即可以得到可用于企业安全评价的有效数据,完成了安全评价指标数据的主动采集,验证了安全评价指标主动采集的可行性和有效性。
3 结论
(1) 运用大数据技术可以实现安全评价指标数据的主动采集,提高了安全评价指标数据的客观性和公正性,同样使安全评价结果的客观性和公正性也得到了提高。
(2) 安全评价指标主动采集相对于被动采集的优点在于能够及时地对所采集的指标数据进行更新,避免因信息的滞后性导致安全评价的结果不准确,提高了安全评价的准确性。
(3) 相较于传统的安全评价指标被动采集方法,安全评价指标的主动采集更加符合新时代企业及社会对于生产安全的要求,同时节约了人工时间成本,提高了安全评价的效率。
(4) 经过安全评价指标主动采集得到的大量数据还可以进行更深入的研究,得出指标数据本身之间的关联性,这又为安全评价的研究提供了新的方向。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
债券(2021年1期)2021-02-04
债券(2020年4期)2020-08-04
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
债券(2018年11期)2018-02-21
