
基于模糊K-means聚类算法的区域数据智能分析方法
2022-05-24 11:43支建勋
电子设计工程 2022年10期
支建勋
(河北北方学院附属第一医院,河北 张家口 075000)
随着我国社会经济的发展,医疗保险制度建设不断完善,社会矛盾得到了有效缓解。但在现阶段,医保的报销流程中众多不规范的问题时有发生,医疗保险监管体系亟待完善[1-4]。因此,需要推动信息技术的应用,为智能化的规范管控提供有力的技术保障[5-12]。
文中对医疗行业的区域化群体数据挖掘方法进行了研究,采用模糊K-means 算法对医疗数据进行处理,然后筛选出异常数据。另一方面,针对医保数据量级的不断增长,造成算法运行效率低下的问题,引入Hadoop 平台和MapReduce 编程模型,对算法进行并行化处理,从而提升数据分析的效率[13-14]。
1 理论基础
1.1 K-means算法原理
K-means 是机器学习领域常见的一种无监督学习模型,其将距离作为相似性评价指标。在K-means算法中,将距离较近的同类数据点放入一个簇内,且它们之间的距离应尽可能地接近;而不同簇中心的距离则应尽可能地远,图1 所示为K-means 算法的原理示意图[15-16]。
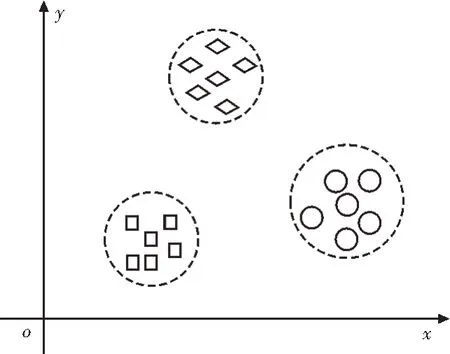
图1 K-means算法原理示意图
在K-means 算法中,定义输入数据{x1,x2,…,xn}的最终聚类数目为k,最终的簇中心为{c1,c2,…,ck},采用欧式距离计算每个数据点与簇中心cj的距离为:
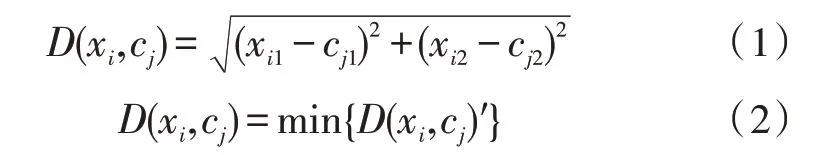
当D(xi,cj)满足式(2)时,则数据xi的分类标记为cj。当所有数据的分类完毕后,计算新的聚类中心为:

接着在新聚类中心下计算误差平方和准则函数:
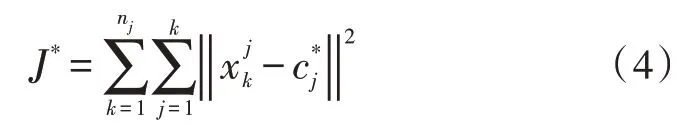
当|J*-J|<ξ时,表示当前的准则函数收敛,当前聚类中心即为各个数据的最终类别;否则,算法将重新搜索新的聚类中心,直至J收敛。
图2 给出了K-means 算法的流程图。相较于其他的聚类算法,K-means 在计算时是相对可伸缩和高效的,所以在计算大型数据集时具有更优的适应性。但由于算法在聚类时需要先进行聚类中心的初始化,所以会导致聚类的不稳定;又因为每次迭代前都需要重新计算聚类中心,因此增加了算法的时间复杂度。针对以上问题,文中引入了模糊聚类的概念对算法进行改进。
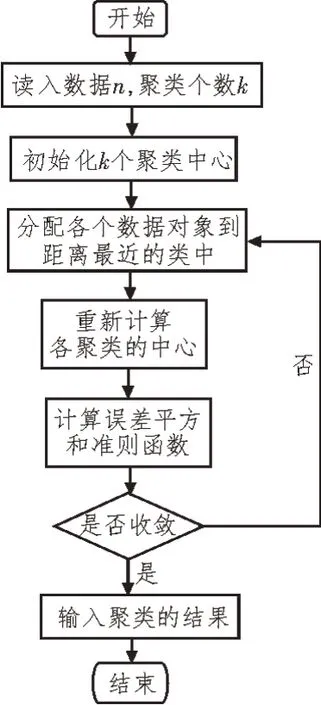
图2 K-means算法流程
1.2 模糊K-means算法
在K-means算法下,每一个数据点x在分类时,均会被严格地放入某一个类别中。但在实际的分类过程中,这一个数据点x却难以严格地被划分到同一个类别中,其可能是以不同的隶属度划分到某一类。此时,对每一个分类结果均可用一个模糊分类矩阵表示:
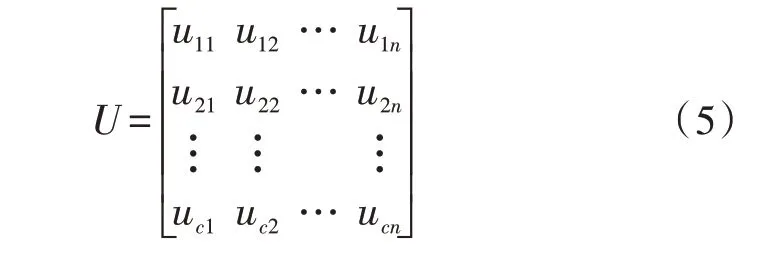
其中,uij∈[0,1]表示某个数据点对于该类别的隶属度。定义模糊分类下的误差平方准则函数为:
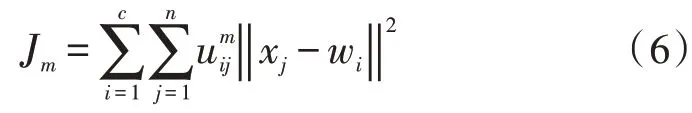
在计算聚类中心时,也需要进行模糊化处理:
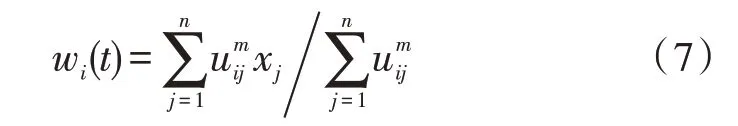
在迭代过程中,也需要对模糊矩阵进行修正:
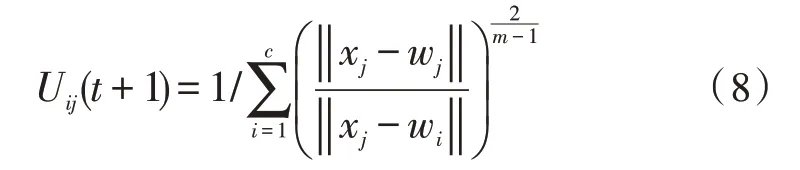
1.3 模糊K-means的并行化
通过对模糊K-means 算法运行的流程分析可以看出,算法的运行时间大多消耗在迭代计算上。而每次迭代需要完成两步计算:1)对每个数据样本计算距离;2)确认新的计算中心。这意味着K-means 算法的运行耗时与数据规模的大小呈正相关。对于医保数据,由于涉及人数众多且数据量极大,需要采用并行化的手段提升数据挖掘的效率。
文中通过MapReduce 对模糊K-means 算法进行并行化处理,具体流程如图3 所示。
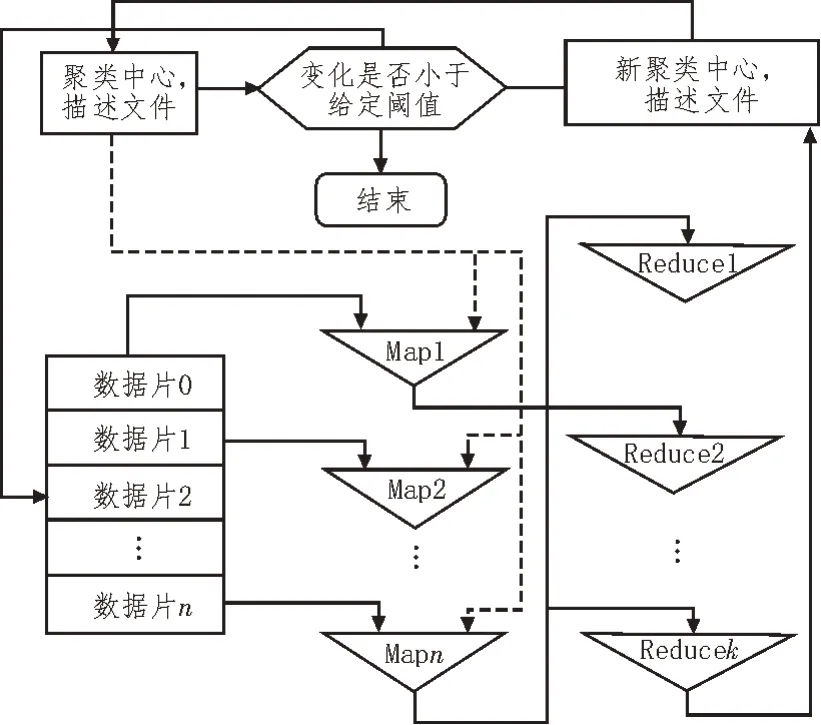
图3 模糊K-means的并行化流程
并行化K-means 算法的核心在于对群体医疗数据的切分,首先将数据划分为不同的数据切片;然后将每个切片发送至不同的运算节点,在不同的计算节点进行聚类。根据MapReduce 的编程模型可知,整个算法包含Map、Combine 和Reduce 3 个过程。
1)Map:在该过程中,将数据划分为若干个数据块,计算数据对象到所有聚类中心的距离,并选择距离最小的聚类中心点,最终形成<数据对象,聚类中心>的key/value 键值对形式。
2)Combine:其是对Map 过程的中间结果进行本地化Reduce 的过程,将属于同一聚类中心的数据对归类到一起。然后计算属于同一聚类中心的数据对象之和,从而得到同一簇的聚类结果,最终的输出结果为<聚类ID,各维坐标的累加和>。
3)Reduce:其是将Combine 得到的结果进行局部聚类,进而得到全局的聚类结果。在Reduce 的过程中,对所有簇的局部结果进行汇总,计算所有簇的新聚类中心。当结果收敛时,算法将该聚类中心作为最终的分类结果。
2 方法实现
2.1 仿真环境设计
为了实现模糊K-means 算法的并行化处理,首先需要搭建Hadoop 计算集群。在Hadoop 平台下,MapReduce 是分布式编程模型,该模型需要分布式文件系统HDFS 的支撑。在HDFS 文件系统下,需要搭建一个NameNode 和若干个DataNode 计算节点。文中的计算节点统一配置为如表1 所示的虚拟机。

表1 计算节点配置
每个节点的机器名、IP 地址和用途如表2 所示。
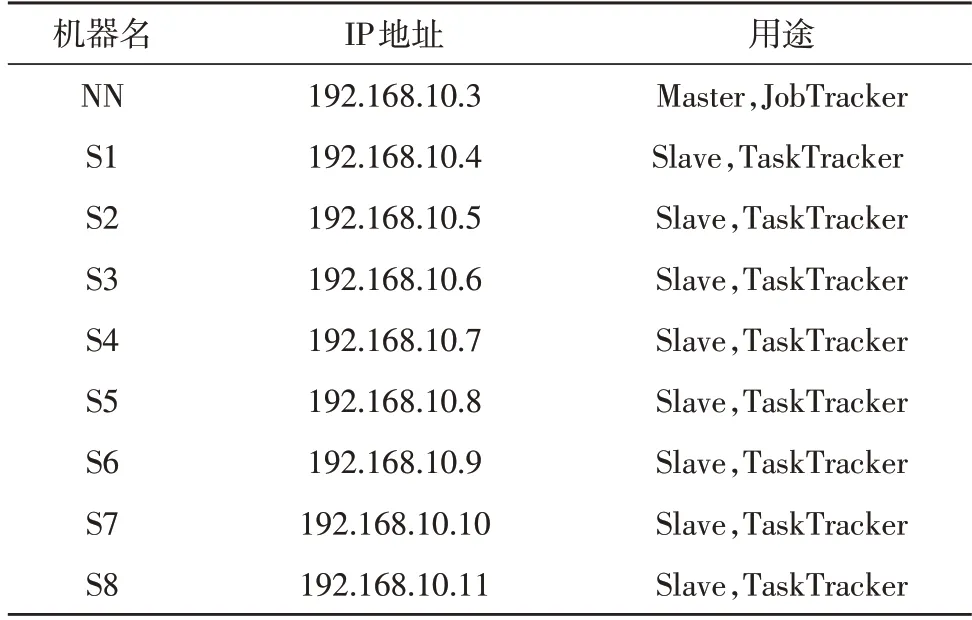
表2 Hadoop环境配置
在每台虚拟机安装Hadoop 并进行格式化后,启动守护进程。将每台虚拟机的Localhost 修改为表2所示的IP 地址,并在conf/.目录下将Hadoop 的参数按照表3 进行设置。
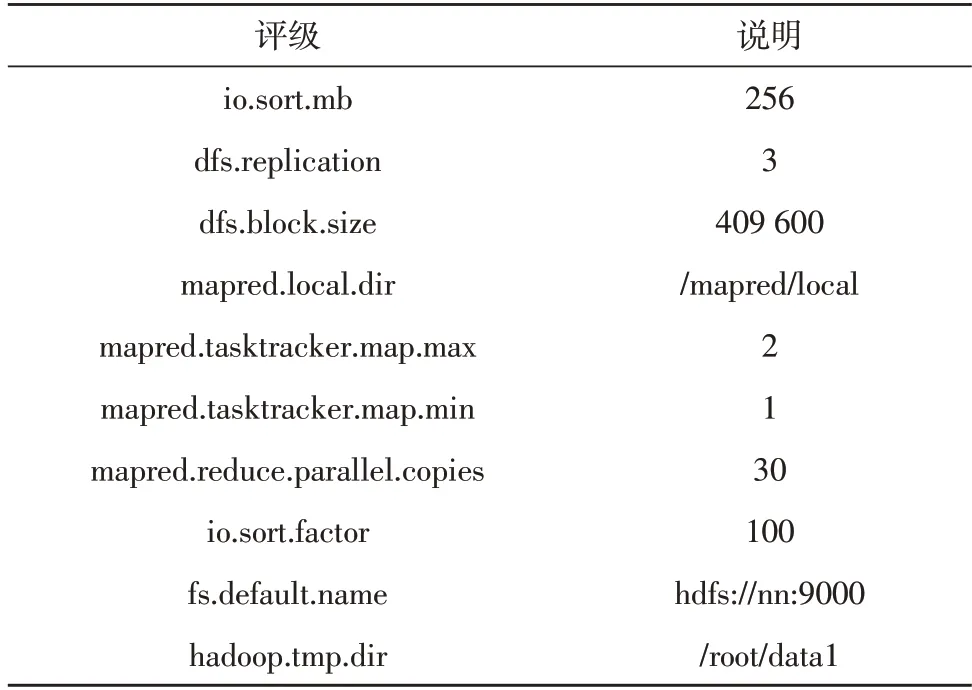
表3 Hadoop参数配置
2.2 仿真分析
文中设计的并行化模糊K-means 算法的应用场景是医疗群体数据的挖掘与分析,以河北省某地区2020 年的医保数据集作为样本。该数据共包含药品费、检查费、手术费、挂号费、床位费等73 个维度的就诊数据,就诊人数共323 213 人。其中,标记的医保失信行为数据约占4.36%,医保失信数据被标记为过度医疗、用药不符、虚假支付、伪造票据、挂名诊疗、虚假套现等6 类。
在进行数据分析仿真时,首先对文中设计的模糊K-means 算法的性能进行分析,算法的相关参数设置如表4 所示。
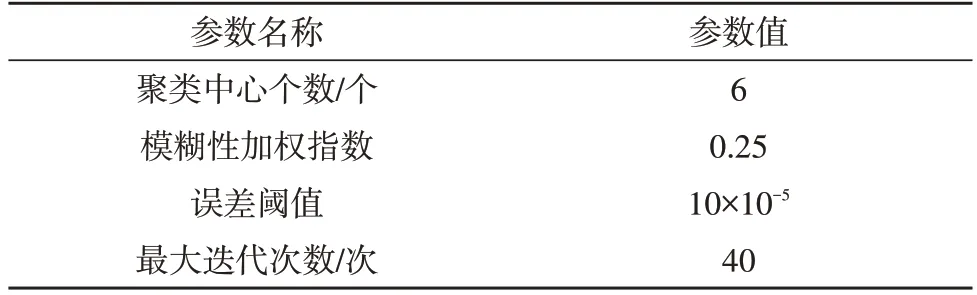
表4 相关参数设置
由于原始的数据集较大,在使用K-means 算法时计算耗时较长,文中在评估算法性能时采用随机抽样的方式,选取了1 000 人的医保数据进行演算。将串行化的模糊K-means 算法和传统K-means 算法的结果进行了对比,串行化算法的性能指标如表5所示。
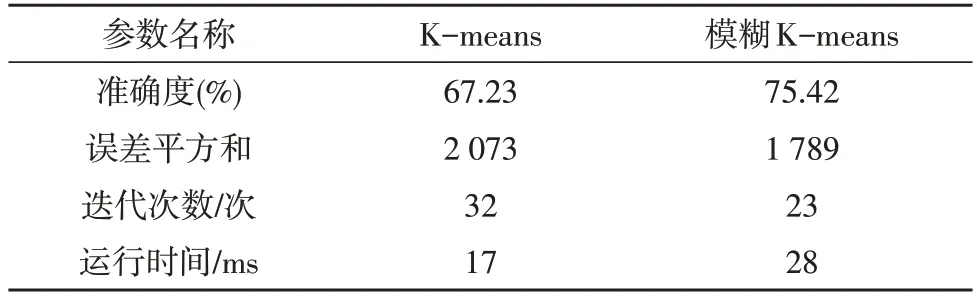
表5 串行化算法的性能指标
文中对并行化的模糊K-means 算法进行分析。表6 给出了随着DataNode 的增加,算法相关指标的变化情况。
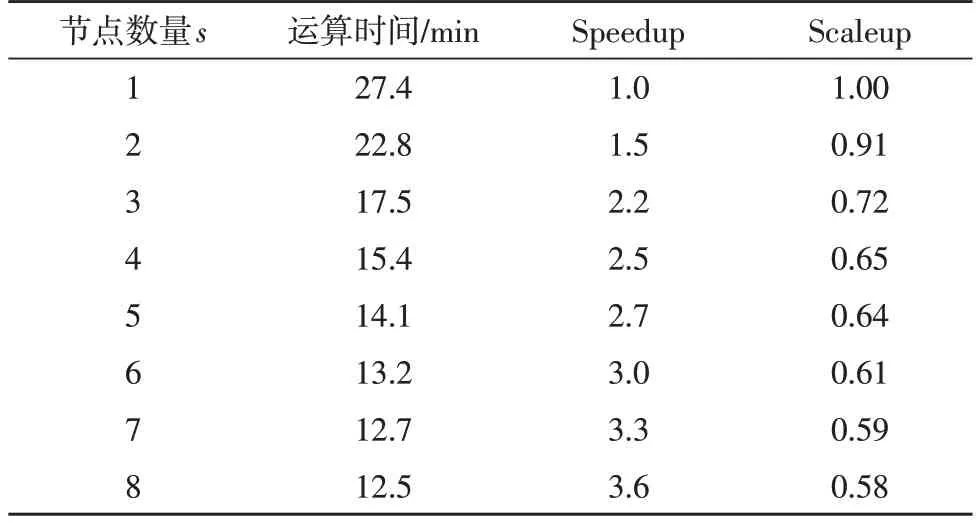
表6 并行化算法的性能指标
表6 中,算法的运行时间随着节点数量s的变大而不断减小,这说明对模糊K-means 的并行化切实提升了算法的运行速度,算法具有较好的扩展性。Speedup 是算法的加速比,该指标为算法在一台计算机上的运行时间与在s台计算机上运行时间的比值,这意味着多计算节点的引入可以缩短算法的运行时间;Scaleup 是算法在计算节点上执行效率的评价指标。从表中可以看出,随着计算节点数量的增长,Scaleup不断降低,说明每个新增的节点计算资源均未浪费,并行后的算法对于数据集具有较强的适应性。
3 结束语
文中对当前医疗环境下,提升医保流程智能度、规范度的相关数据算法进行了研究。通过引入模糊K-means 算法,提升数据挖掘算法的数据处理精度;通过借助分布式文件存储和MapReduce 编程模型,实现模糊K-means 算法的并行化,提升了数据挖掘算法的处理速度。经过在实际医疗数据上的仿真验证可知,文中的研究内容对于医疗群体数据的处理精度和处理效率均有明显的提高,为医疗大数据分析方法提供了参考。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
小学生导刊(2018年34期)2018-12-18
雷达学报(2017年6期)2017-03-26
电子技术与软件工程(2016年24期)2017-02-23
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
山东青年(2016年3期)2016-02-28
母子健康(2015年1期)2015-02-28
