
生成式对抗网络应用领域综述
2022-05-21 08:18魏为民孟繁星
上海电力大学学报 2022年2期
才 智, 魏为民, 孟繁星, 刘 畅
(上海电力大学 计算机科学与技术学院, 上海 200090)
深度学习是机器学习的分支,是一种以人工神经网络为架构,对资料进行表征学习的算法[1]。随着数据总量和硬件性能的不断提升,各种神经网络层出不穷,对人工智能技术的发展起到了一定的推动作用。2014年,GOODFELLOW I J等人[2]第一次提出了生成式对抗网络(Generative Adversarial Network,GAN),此后众多学者对其进行了研究,将生成式对抗网络应用于不同领域。
1 生成式对抗网络的原理
生成式对抗网络由生成器G(Generator)和判别器D(Discriminator)两种模型构成,均为多层感知器。它是基于博弈论中的零和博弈思想,通过生成器和判别器二者不断地博弈,进而达到纳什平衡的深度学习神经网络。作为一个具有“无限”生成能力的模型,GAN的直接应用就是建模,生成与真实数据分布一致的数据样本[3]。
生成器和判别器所用的网络通常由包含卷积层和完全连接层的神经网络实现。生成器和判别器必须是可微分的,但不必是直接可逆的[4]。生成器G根据输入的学习噪声,生成新的逼真图像;然后由判别器D对G生成的图像进行评价,根据评价结果,对G的参数进行调整,进而由G再生成新的图像;如此往复,最终生成符合要求的图像。生成式对抗网络工作流程如图1所示。
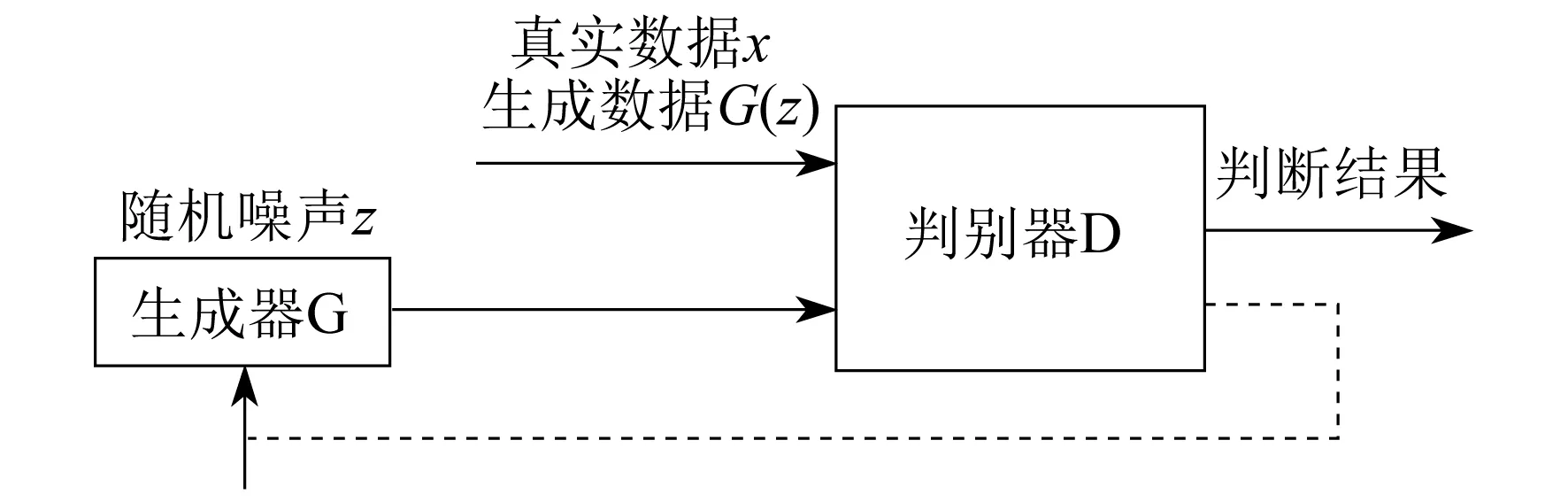
图1 生成式对抗网络工作流程
为了学习输入到生成器的数据x的分布pdt(x),即真实数据的分布情况,将噪声z输入给生成器G(一个可微函数),即用G(z)来表示数据空间的映射。判别器D输出一个标量D(x),表示x来自数据而不是pg(即生成的数据)的概率,其输出的值越大,代表生成的数据越真实。D和G完成一种博弈,其损失函数V(G,D)所示不断地输入真实数据x和噪声z,计算出函数D的表达式,使损失函数的值最大,同时计算出G的表达式,使此时损失函数的值最小[2]。
minGmaxDV(G,D)=Ex~pdt(x)[logD(x)]+
Ez~pz(z)[log(1-D(G(z)))]
(1)
2 生成式对抗网络的应用
生成式对抗网络目前应用于图像、音频和视频3大领域,在不同方向上的应用主要表现在以下几个方面。
2.1 图像处理
人类可以通过视觉感知世界,而机器同样可以通过图片来学习世界。但是在机器学习未得到大规模应用前,机器是无法脱离人的操作来对图片进行处理的,如图像识别是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术[5]。当GAN被提出后,大量基于生成式对抗网络的研究应用到图像处理领域,使得机器自动对图片进行处理成为可能。
2.1.1 图像生成
RADFORD A等人[6]对GAN进行了改进,提出了一种生成清晰图像的神经网络(Deep Convolutional Generative Adversarial Networks,DCGAN)。该方法通过训练生成式对抗网络,将生成器和判别器的一部分重新用作有监督任务的特征提取器;将卷积网络引入生成式模型中进行无监督的训练,利用卷积网络强大的特征提取能力提高生成网络的学习效果;将100维均匀分布Z投影到具有多个特征映射的小空间卷积表示中,通过4次卷积将高维图像转换成64×64像素的图像,但并没有使用完全连接层或池层。DCGAN具有以下4个特点:一是在判别器模型中使用strided convolutions来替代空间池化(pooling),而在生成器模型中使用fractional strided convolutions;二是使用批量标准化(Batch Normalization,BN)加快收敛速度,使网络学习更加稳定,有助于处理初始化不良导致的训练问题;三是去除全连接层,直接使用卷积层连接生成器和判别器的输入层以及输出层,减弱对收敛速度的影响;四是在生成器的输出层使用tanh激活函数,而在其他层使用ReL激活函数。
由于DCGAN输入随机噪声来生成符合真实数据分布的图片,所以不能指定生成相似结构的照片,有一定的随机性。研究者通过有监督的学习,在原有GAN的基础上,对损失函数进行改进,提出了条件生成网络(Conditional Generative Adversarial Network,CGAN)[7]。其损失函数表示D和G完成一种博弈,通过不断地输入真实数据x与条件y的叠加(x|y)和噪声z与条件y的叠加(z|y),计算出函数D的表达式,使损失函数的值最大,同时计算出G的表达式,使损失函数的值最小。计算公式为
Ez~pz(z)[log(1-D(G(z|y)))]
(2)
CGAN在G和D的输入端添加了条件,使得对G生成的图片做了一定的控制,生成的数据就有了具体的方向。
变频发电时,增加1台4 000 kW发电机(6 kV/50Hz)和 1台 4 300 kW电动机(3 kV/25Hz)及相应附件,变频机组转速107 r/min。变频机组约需250万元,增加厂房造价约60万元,相应辅助设备约需50万元,合计360万元,其余费用相同。
2.1.2 风格转换
风格转换可以看作是将样式从一个图像转移到另一个图像的纹理转移问题。在纹理传输中,目标是从源图像合成纹理,同时约束纹理合成,以保持目标图像的语义内容[8]。
Pix2pix[9]是对CGAN的应用,通过输入成对的训练数据,实现图片到图片的翻译,将图片从一种风格转换成另一种风格。这种网络不仅学习输入图像到输出图像的映射,而且还学习一个损失函数来训练这种映射。这使得采用相同的方法,解决传统上需要不同损失公式的问题成为可能。Pix2pix研究结果表明,条件生成网络适用于许多图像-图像转换任务,特别是涉及高度结构化图形输出的任务。该网络根据任务和数据学习损失,适用于各种各样的设置。
针对Pix2pix成对训练数据不好获取的问题,ZHU J等人[10]提出了一种在没有成对例子的情况下,能够将图像从源域X转换到目标域Y的方法。通过学习一个映射G:X→Y,使来自G(X)图像的分布与目标分布Y高度相似,得到Y风格的X图像。该模型包含两个生成器G:X→Y和F:Y→X,以及相关的判别器DY和DX。前向循环一致性损失为x→G(x)→F(G(x))≈x,后向循环一致性损失为y→F(y)→G(F(y))≈y。
2.1.3 图像修复
YU J等人[11]提出了一种新的基于深度生成模型的方法,不仅可以合成新的图像结构,而且可以在网络训练过程中显式地利用周围的图像特征作为参考,以做出更好的预测。该模型是一个前向的、完全卷积的神经网络,能够在测试期间处理任意位置和可变大小的多个孔的图像。
桑亮等人[12]提出了一个复原由运动而导致模糊图像的解决方案。该方案利用了模糊核估计过程,采用端对端的方式直接获取复原图像,并且通过引入GAN对抗损失和对残差网络进行改进,有效地复原了图像的细节信息。
CAI W等人[13]提出了PiiGAN模型,配备了一种全新的风格提取器,可以从基础事实中提取风格特征,摒弃了传统修复图片产生单一最优结果的缺陷,而是考虑了修复任务的不确定性。对于一个缺失区域的单一输入图像,该模型可以生成大量具有可信内容的不同结果。
在信息安全方面,应用GAN来提升隐写质量,得到了众多研究者的关注。
YANG J H等人[14]提出了一种生成隐写框架的失真函数。利用3个模块:一个模块是以U-Net为框架的生成器,使封面图像转化为嵌入变化概率图;一个模块以不需要预训练的双tanh函数来逼近最优嵌入模型,同时在对抗式训练的反向传播过程中保持梯度范数;一个模块以卷积神经网络和多个高通滤波器作为判别器的增强型隐写分析器。隐写生成对抗网络(Steganographic Generative Adversarial Networks,SGAN)[15]是在DCGAN的基础上加了一个由CNN实现的判别器网络,对输入给该网络的图像进行隐写分析。
2.2 音频处理
2.2.1 音频合成
GAN在生成本地和全局一致的图像方面已经得到了广泛的应用,但在音频生成方面的应用却很少。这是因为一方面音频具有较高的时间分辨率(通常至少为每秒16 000个样本),另一方面在不同时间尺度上存在短期和长期依赖性的结构,使得音频的生成较为困难。
DONAHUE C等人[16]提出了WaveGAN,首次尝试将其应用于原始波形音频的无监督合成。WaveGAN能够合成具有全局相干性的音频波形片段,也适合于产生声音效果,如生成鼓、鸟叫声和钢琴声等。WaveGAN架构基于DCGAN,但是与DCGAN的生成器使用转置卷积操作,迭代地将低分辨率特征映射采样到高分辨率图像中不同,它修改了这种转置积运算[16]。此外,DCGAN使用较小的(5×5)二维滤波器,而WaveGAN使用较长的(长度为25)一维滤波器和较大的上采样因子。两种策略的参数和数值运算数目相同。
KUMAR K等人[17]提出了MelGAN,通过引入一组简单的训练技术,证明了可靠地训练GAN,生成高质量的相干波形是可能的。
2.2.2 文本转语音

2.3 视频处理
TULYAKOV S等人[19]提出了基于运动和内容分解的生成对抗网络(MoCoGAN)视频生成框架。该框架通过将随机向量序列映射到视频帧序列来生成视频。每个随机向量由一个内容部分和一个运动部分组成。当内容部分保持固定时,运动部分为一个随机过程。为了在无监督的情况下学习运动和内容分解,该框架提出了一种新的基于图像和视频判别器的对抗学习方案。
CLARK A等人[20]提出了一种生成高保真视频的对抗网络DVD-GAN。这种模型通过利用判别器的计算效率分解将原视频扩展为更长、更高分辨率的视频。通过评估视频合成和视频预测的相关任务,该研究为Kinetics-600预测提供了最先进的Frechet初始距离,为UCF-101数据集的合成提供了最先进的初始分数,也为Kinetics-600的合成建立了强有力的基线。
3 结 语
GAN开始时大多应用于图像处理中,近期应用GAN对音频、视频处理的研究逐渐增多。相对于音频处理,由于视频和图像易于编码,因此利用GAN能够相对容易地完成对图像和视频的处理。音频具有较高的时间分辨率,在目前阶段,由于基本上是以波形图为中间步骤来进行音频生成的,所以有一定的复杂性;但随着技术的发展,相信在未来GAN会更多地应用于音频领域。
GAN逻辑是一种类比、对抗进化的思想。如果能够将这种思想应用在机器人行为模式上,通过输入人类行为,让机器在学习现有的人类行为的基础上,创造出类似的行为,将加速机器通过图灵测试的时间。
当然,GAN也存在一些问题:一方面,GAN的训练过程复杂,需要使用高性能的硬件,尤其对显卡的要求较高;另一方面,GAN训练效果不够稳定,若使用小数据集训练,就达不到理想结果,而若使用大训练集,则有可能导致训练崩溃。此外,GAN也存在一定的伦理问题。如生成一些名人的虚假照片以达到宣传的目的,从而造成重大的社会问题。技术本身是无罪的,研究人员应保持对技术的敬畏之心,用技术去创造更好的世界。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年11期)2019-01-21
今日农业(2019年15期)2019-01-03
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
