
分布式深度学习的数据传输压缩机制研究综述
2022-05-21 08:17杜海舟冯晓杰
上海电力大学学报 2022年2期
杜海舟, 冯晓杰
(上海电力大学 计算机科学与技术学院, 上海 200090)
随着大数据、云计算和物联网需求的日益增长,机器学习尤其是深度学习在图像分类、语音识别、机器翻译以及围棋程序等领域都有了上千万的训练数据以支撑复杂模型的训练,建立了各种数据分析和决策系统。大数据的兴起也伴随着包含数百万甚至数十亿参数的更高维、更复杂的机器学习模型和深度神经网络的出现。如此大规模的计算,离不开硬件的支撑。图形处理器GPU有着比中央处理器CPU 更强的并行计算能力,能使复杂的训练更加高效。为了获得更高的预测精度、支持更智能的任务,需要训练更复杂的神经网络。然而训练大型模型所需的输入数据随模型参数呈指数增长,对这样大规模的数据训练所涉及的深度神经网络已经超过了单一机器的计算和存储能力,因此需要在多台计算机之间分配训练工作量,并从集中式系统转向分布式系统。在这种情况下,利用计算机集群,从大数据中训练性能优良的大模型成为分布式深度学习的目标之一。
1 分布式深度学习简介
分布式深度学习能够充分利用集群资源更快地完成训练。当训练数据或模型太大,无法由单机完成存储和计算时,就需要将数据或模型进行划分,并将其分配到各个计算节点上。这分别对应分布式深度学习中2种重要的并行化方式:数据并行和模型并行。
数据并行是先将数据划分到各个计算节点上,然后各节点利用自身的局部数据对模型进行训练,具体如图1所示,其中D代表数据,W1,W2,W3代表工作节点。
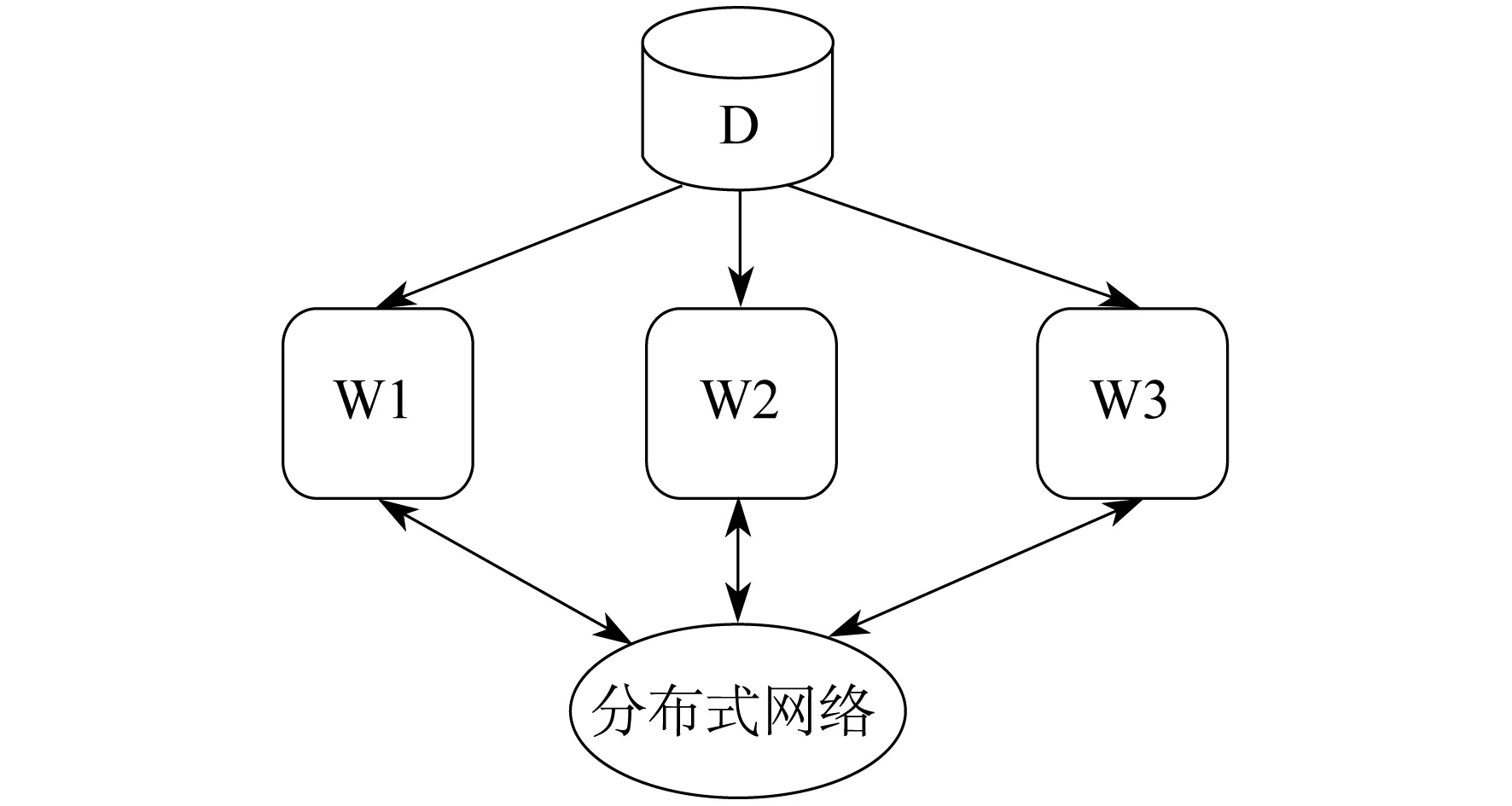
图1 数据并行
模型并行是先把一个大模型划分成许多小块,然后把每小块对应的参数分配在不同的计算节点上执行,具体如图2所示,其中D1,D2,D3表示划分到各个节点的数据。数据并行通过分布式网络传输梯度同步模型,且通过模型并行传输中间计算结果。数据并行和模型并行并不冲突,两者可以混合使用[1-2]。
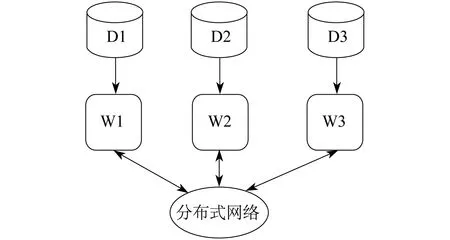
图2 模型并行
并行方式需要与具体的通信架构相结合,选择中心化还是去中心的架构取决于诸多因素。中心化架构通常利用特别设计的参数服务器(Param-eter Server,PS)[3]将工作节点(客户端)和模型存储节点(服务器)从逻辑上进行区分。各工作节点负责处理本地的数据训练,并通过参数服务器提供的 PUSH 与 PULL 接口与之进行通信。去中心架构依靠集体通信All-Reduce在节点之间传递数据。
将数据和模型划分到多个工作节点后,再利用单机的并行优化能力进行本地计算,通过分布式通信将局部模型聚合成全局模型。这就是整个分布式深度学习的基本流程。
与一般的分布式计算相比,分布式深度学习在数据传输方面更具挑战。这主要是因为分布式深度学习面临着通信需求与受限带宽的考验,因而其性能和可扩展性受到了极大限制。
(1)通信的频率高、单次通信量大 首先,深度学习采用迭代式的优化算法进行训练,迭代频繁且次数多,使得通信频率很高。其次,分布式深度学习需要在各个工作节点之间传递神经网络参数或梯度(数据并行),或者在每个数据样本的中间计算结果(模型并行),由于需要处理大数据、训练大模型,从而导致每次的通信量很大。
(2)网络带宽低、延迟高 与大数据、大模型对比,分布式系统中的网络传输速度往往受限,导致通信常常成为分布式系统的瓶颈。根据阿姆达尔定律(Amdahl’s Law)[4],如果某个任务中计算与通信的时间占比为1∶1,那么无论使用多少台机器,其加速比都不会超过2倍。
因此,分布式深度学习的关键是降低通信与计算的时间比,从而更加高效地训练高精度的模型。
2 分布式深度学习的数据传输压缩
2.1 参数同步
分布式深度学习中的各个计算节点既要独立地进行本地计算,又可以通过数据交互来确保模型最终能够收敛且收敛到理想的最优点。为了高效地训练高精度模型,需要在更好的模型性能(列表上方)和更快的训练速度(列表下方)之间进行权衡。这种权衡导致了3种主要的同步模式,具体如下:一是整体同步并行(Bulk Synchronous Parallel,BSP)[5],在每个工作节点处理完局部数据后同步所有更新,在所有工作节点获取最新的模型后才进行下一次迭代;二是异步并行(Asynchronous Parallel,AP)[6],完全去掉工作节点间的同步,所有的工作节点都尽最大努力地进行通信;三是延时同步并行(Stale Synchronous Parallel,SSP)[7],允许最快的工作节点比最慢的工作节点多迭代一定次数,但是不能超过阈值。
2.1.1 BSP
BSP要求工作节点完成本轮迭代后,等待集群中的其他未完成节点,当所有节点都完成各自的任务后,才共同进入下一轮迭代。BSP使得每个工作节点都能获得最新且一致的全局模型,保证了分布式算法与单机算法的等价性,从而利于算法的分析和调试,并且能够获得最好的模型性能。但是,由于各个工作节点之间彼此等待,造成计算资源闲置,所以阻碍了训练规模的扩展。在带宽受限的情况下,还会导致各个工作节点集中闲置或争用有限的带宽。
在BSP引入一个全局的同步屏障,构成整体同步并行模式歧化,具体如图3所示。
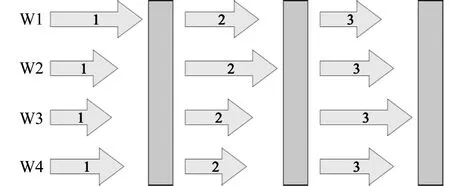
图3 整体同步并行模式
即所有的工作节点会在这个位置被强制停下,直到所有的工作节点都完成了同步屏障之前的操作,整个系统才会进入下一步的计算任务。当使用BSP来实现基于数据并行的分布式优化算法时,需要与具体的聚合方法相结合[8-10]。
2.1.2 AP
AP是指当集群中的一个工作节点完成本轮迭代后,无需等待其他节点就可以继续进行后续训练,具体如图4所示。异步通信不保证模型的一致性,各个工作节点无需互相等待,从而最大化计算和通信资源的利用率。但由于节点之间的模型彼此不一致,因此会因延迟问题,给模型聚合带来挑战。
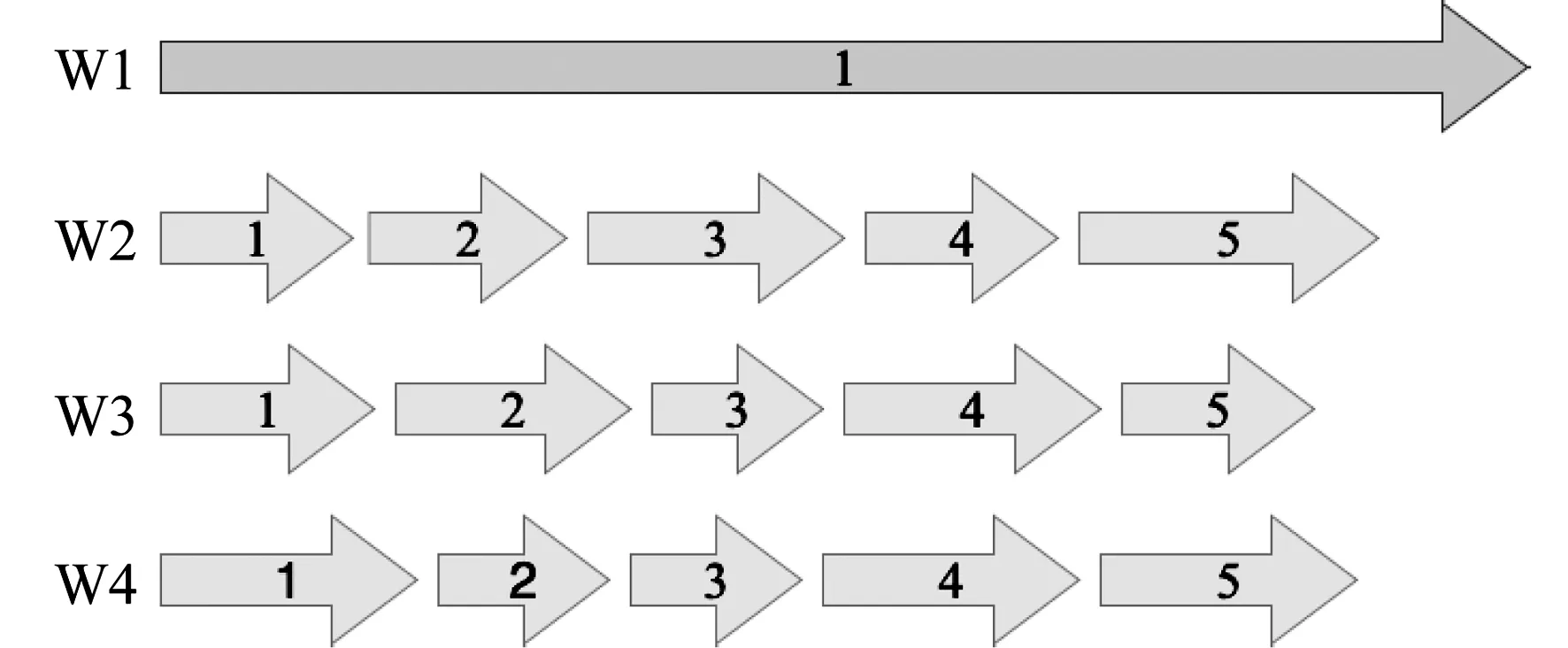
图4 异步并行模式
AP最初在共享内存的单机多线程并行中实现,分为有锁和无锁2种,各有利弊。文献[11]用Dogwild!将各个工作线程直接无锁地读取和写入最新的模型中进行更新,发现在优化目标为凸函数且模型更新比较稀疏的情况下,异步无锁地写入不会对收敛性造成本质影响。此后Dogwild!被扩展到分布式内存系统中,并在深度学习问题上仍能保持收敛性。为了缓和每一步中覆盖参数的影响,在这些实现中传递梯度而不是参数。
2.1.3 SSP
为了结合同步与异步各自的优点,文献[7]提出了在一致和不一致模型之间折中的方案SSP。SSP 控制最快和最慢节点之间相差的迭代次数,使其不超过预设的阈值。延时同步并行模式如图5所示。只要各个工作节点的迭代次数的差不超过阈值,各个节点的计算就可以保持独立进行;但当迭代次数差异太大,就会触发等待机制,避免产生过大的延迟。这种方法在异构环境中特别有效,因为掉队者(stragglers)会受到控制。
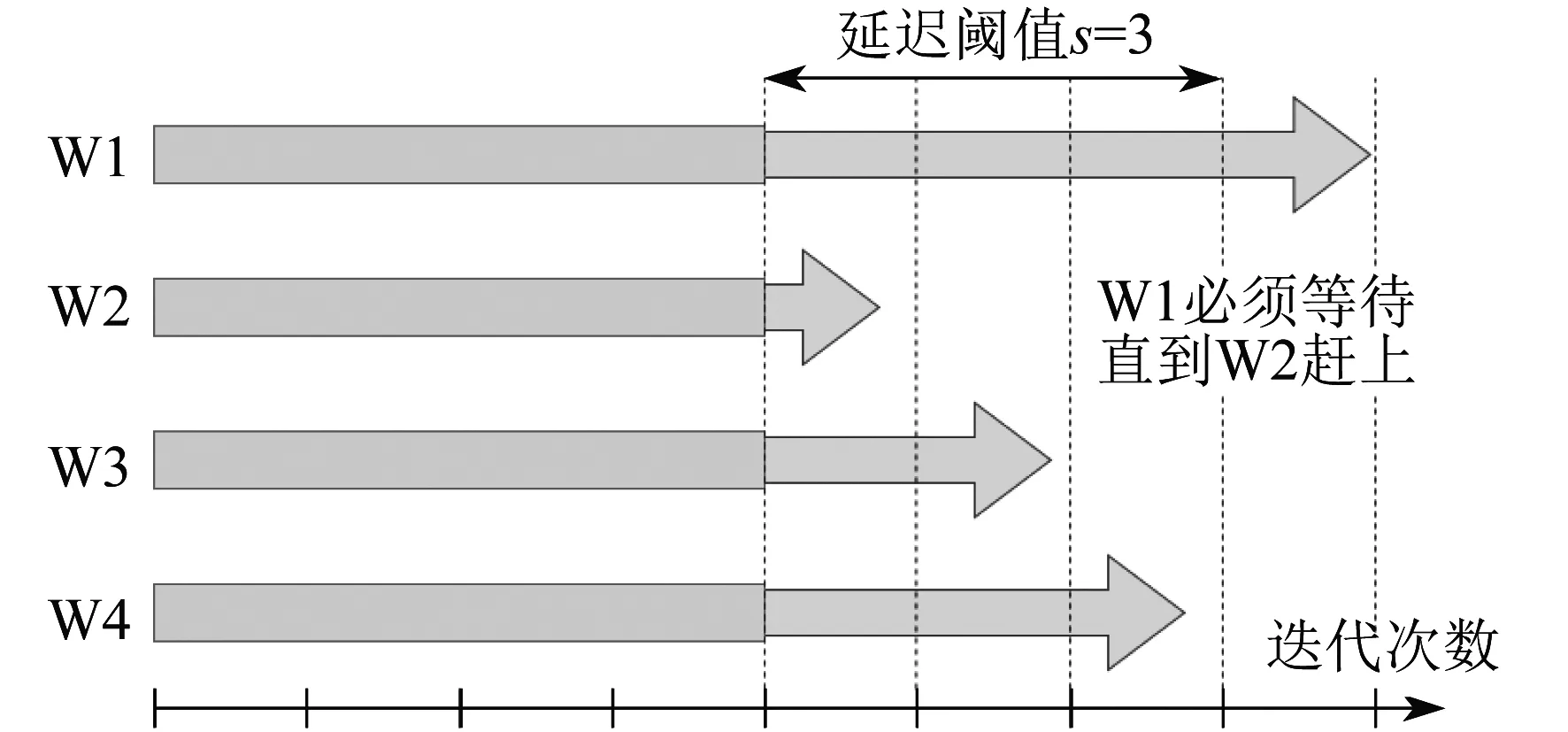
图5 延时同步并行模式
Adam项目不要求最快的工作节点等待,而是维持一个全局时钟,当发现某些工作节点的更新太陈旧时,就将其丢弃并将此工作节点的当前模型刷新成参数服务器上的最新模型,从而既保证有限的延迟,同时也可以让快的工作节点全速前进。
2.2 模型聚合
模型一致性频谱如图6所示。

图6 模型一致性频谱
由图6可知,从一致性的角度看,可以进一步增加模型不一致性,从而推广BSP,SSP,AP。在极端不一致的情况下,数据交换非常少或不存在,虽然减少了通信量,但也意味着必须对接收到的数据采取有效的聚合措施。具体来讲,可以让许多机器分别进行训练,然后在训练结束聚合一次或者在训练期间间隔地聚合。从聚合内容的角度来看,既可以是聚合模型参数或梯度,又可以是聚合模型的输出。其中:集成学习(Ensemble Learning)是在训练结束之后聚合模型输出;模型平均(Model Averaging)是在训练期间间隔地聚合模型参数或梯度。
2.2.1 集成学习
集成学习通过集成多个模型的预测结果,可以取得比单个模型更好的性能,在机器学习中已被广泛使用[12]。分布式集成学习是完全并行的,且训练期间机器之间不需要通信。
鉴于集成后的新模型会消耗m倍的内存和计算资源,故可以通过知识蒸馏(Knowledge Distillation)[13]来减小新模型的大小。首先,使用样本和硬标签训练一个大模型或者模型集成作为教师网络;然后,训练一个小的学生网络来拟合教师网络的软输出。结果显示,学生网络在教师网络的指导下比在原始数据集上更容易训练,蒸馏后的单个模型能够达到10个模型集成相同的错误率。
2.2.2 模型平均
模型平均[14]是在不同的机器上并行执行随机梯度下降(Stochastic Grradient Descent,SGD),仅在训练后聚合一次或每隔几次迭代聚合一次[15]。研究证明,使用SSP的SGD准确性更高。
为了克服由于不频繁平均而导致的精度下降问题,文献[16]在弹性平均SGD中引入了所谓的弹性机制,在当前的全局模型和工作节点的最新更新之间进行权衡,一方面探索新模型,另一方面保留一定的历史状态。结果表明,弹性平均SGD在准确性方面优于DistBelief SGD,在更新延迟方面表现出一定的容忍度。
在分布式环境下,算法还应进行检查以确保容错性。Krum[17]是一种拜占庭容错[18]SGD算法,最多允许f个拜占庭训练代理。通过组合特定的m-f个梯度,Krum 能够克服来自网络的对抗性梯度输入。同时,任何基于线性组合的梯度聚集规则都无法容忍单个拜占庭代理。
2.3 梯度压缩
深度学习的优化算法具有容错性,可以减少不必要的数据传输开销。一方面,可以通过不一致视图减少传递信息的频率,另一方面,也可以减小每次传输数据的大小。分布式深度学习中有2种节省带宽的通用方法:一是量化(Quantization),用有效的数据表示压缩参数或梯度,减少每个值的占用位数;二是稀疏(Sparsification),避免发送不必要的信息,从而导致稀疏数据的通信。
2.3.1 量 化
基于量化的方法减少了表示浮点数所需的位数。极端的偏差量化1位SGD[19],将每个梯度分量量化为1或-1。该方法在量化过程中首次引入了误差反馈策略,以补偿上次迭代产生的量化误差。具有多数表决的 signSGD[20]在工作节点和服务器之间传输1位的梯度符号,并使用多数表决进行聚合。其动量变体称为具有多数表决的Signum[21]。通过多数表决,signSGD 实现了拜占庭容错。然而,signSGD 在某些简单情况下依然可能不收敛。通过使用误差修正技术可以解决这个问题,从而导致带有错误反馈的SGD(EF-SGD)[22]。通过将梯度划分为块,Dist-EF-SGD 及其动量变体[23]传输 1位符号和每个块的缩放因子,以获得更好的模型性能。
无偏量化[24]和QSGD[25]通过随机量化将梯度分别压缩为3级和多级,并确保压缩后的随机梯度是真实梯度的无偏近似。QSGD 使用均匀分布的量化点对梯度进行随机量化。ZipML[26]通过梯度分布动态地选择量化点从而引入了一种最佳量化策略。实践中,与不使用该技术的无偏量化相比,使用误差补偿技术的偏差量化能够获得更好的模型性能。
2.3.2 稀疏化
基于稀疏化的方法减少了随机梯度中非零项的数量。与量化策略相比,稀疏化能够取得更高的通信压缩率。一种极端有效的Top-k稀疏化方法仅传输绝对值最大的梯度分量。其中,阈值量化[27]和梯度丟弃[28]基于绝对值的两个或单个阈值稀疏梯度。由于在实践中很难选择该阈值,Adacomp[29]根据局部梯度活动自动选择梯度残差。为了解决由于稀疏而导致的精度损失,深度梯度压缩[30]利用动量校正、局部梯度裁剪、动量因子掩蔽和热身训练实现更高的稀疏度而不降低精度。此类方法只能通过使用某种误差累积才能工作,否则某些坐标将永远无法更新。
与上述Top-k方案不同,文献[31]提出了一种随机稀疏化方法,该方法通过求解约束线性规划来平衡稀疏性和方差,无偏且不采用误差补偿。
2.3.3 低秩分解和草图方法
低秩分解(Low-rank Factorization)和草图方法(Sketch)也可以视为基于稀疏化的方案。Atomo[32]对梯度的奇异矢量(非坐标)进行重要性采样,是一种无偏压缩方案。但是,它的每次迭代都需要完整的奇异值分解,因而计算代价太大。PowerSGD[33]基于空间迭代和误差反馈提出了一种计算效率更高的偏差低秩梯度压缩方法。
SketchML[34]将梯度值量化到诸多桶中,然后通过相应的桶索引对每个值进行编码,同时提出了一种 MinMaxSketch 算法来近似压缩桶索引。SketchSGD[35]将所有梯度压缩到草图中,传输各个节点的草图,然后在合并的草图中恢复最重要的梯度坐标。SketchSGD 在模型很大或者工作节点较多时,会有极高的压缩率和额外计算开销。
3 结 语
利用分布式深度学习,高效地训练高精度的深度神经网络面临着有限网络带宽和大量传输数据的挑战。针对这个问题,本文从参数同步的角度,阐述同步、异步和延迟同步3类并行方式;从模型聚合的角度,总结集成学习和模型平均2类聚合策略;从梯度压缩的角度,讨论量化和稀疏2类压缩方法。可以预见,分布式深度学习未来将会在这3个方面得到更多的应用和发展。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
湖南电力(2022年3期)2022-07-07
快乐学习报·教育周刊(2022年16期)2022-05-01
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年6期)2019-05-28
电子制作(2018年1期)2018-04-04
制导与引信(2017年3期)2017-11-02
北京航空航天大学学报(2017年12期)2017-04-23
燕山大学学报(2015年4期)2015-12-25
