
IrisCodeNet:虹膜特征编码网络
2022-05-19 13:29:04贾丁丁沈文忠
计算机工程与应用 2022年10期
贾丁丁,沈文忠
上海电力大学 电子与信息工程学院,上海 201200
虹膜识别是基于虹膜丰富的纹理特征进行身份鉴别的一种生物识别技术,具有稳定性、普遍性、安全性的优点。
完整的虹膜识别流程一般包括虹膜图像采集、图像预处理、特征提取和识别验证四部分,其中特征提取是虹膜识别算法的核心部分。现在应用较广泛的虹膜特征提取方法是由Daugman开创的技术:通过将个体的虹膜投影到Gabor小波上并将向量响应转换为二进制代码,再基于汉明码距计算向量的相似度,根据一定阈值对相似度分数进行归类,最终达到鉴别身份的目的[1]。这种特征提取策略因其具有计算复杂度低、较高的匹配效率和准确率的特点而占据了虹膜识别的主导地位。在Daugman开创性研究的启发下,近10年来,基于一维Log-Gabor[2]、离散余弦变换(discrete cosine transform,DCT)[3]、离散傅立叶变换(discrete Fourier transform,DFT)[4]、序数度量[5]等多种特征描述方法在虹膜识别任务上均表现出不俗的性能。但是这些方法多基于特定的特征提取器,即需要进行繁琐的人工调节参数来适应不同的识别对象,并且对虹膜采集的图像有较高的约束要求,存在灵活性和困难样本效果差的问题。
近些年来,随着深度学习和计算机视觉的深入发展,许多研究结果表明,使用卷积神经网络提取的通用描述符能够更好地表达复杂的图像特征。近些年来,在虹膜特征提取方面已经有不少出色的研究结果。Boyd等人[6]提出问题:Gabor内核是否是虹膜编码的最佳选择?作者使用单层卷积网络,模拟基于虹膜代码的算法,试图通过神经网络训练的方法寻找出用于虹膜识别的内核。最终发现:网络不会收敛于Gabor内核,而是收敛于边缘检测器、斑点检测器和简单波的混合体。Gangwar等人[7]对卷积神经网络应用于虹膜识别的一系列问题(CNN网络输入尺寸、CNN网络规模、不同虹膜分割方法的影响、跨数据集测试等)进行了详细的实验和讨论,为CNN应用在虹膜识别领域做了很好的开创性工作。Gangwar等人[8]提出了一个用于表达可见光和近红外光虹膜图像的CNN框架DeepIrisNet2,并且应用Spatial Transformer对虹膜图像进行了数据增强,并提出了一种二进制编码策略。Nguyen等人[9]探索了当时比较流行的CNN模型(VGG、Inception、ResNet、DenseNet等)在虹膜识别方面的性能表现,最终在CASIA-Iris-Thousand上训练并测试,结果最佳的网络模型是DenseNet,在错误接受率(false accept rate,FAR)为0.001的条件下,达到了TAR=98.8%的水平。Radimpetlík等人[10]介绍了一种新颖的“UnitCircle层”,它取代了CNN管道中的特征提取步骤,并通过网络训练更新参数,在多个数据集上均超越了多个传统的虹膜识别算法。Boyd等人[11]从网络训练的角度出发,基于ResNet50在下面三种训练方式下探索最佳的网络训练策略:(1)仅使用预训练参数;(2)使用预训练参数并微调虹膜数据集;(3)仅在虹膜数据集上训练。最终,通过实验证明最佳的训练策略是第二种。
在以上研究成果的启发下,本文设计了结合Additive Margin Softmax Loss[12]的新的虹膜特征编码网络IrisCodeNet。为了说明该网络突出的虹膜识别性能,本文在虹膜图像预处理输入形式、网络输入图像分辨率、数据增强以及损失函数参数设置等方面对提出的IrisCodeNet进行了细致的研究和讨论。
1 IrisCodeNet和AM-Softmax Loss
近些年来,基于深度学习的虹膜识别研究工作大多基于神经网络的设计,比如文献[9-10,13]均使用了残差网络并取得了一定的虹膜识别效果,而在损失函数的选取和设计方面没有太多的研究。本文考虑到基于深度学习的虹膜识别的特殊性——并不只是经典的分类任务而是以计算特征向量距离或相似度的策略来进行身份鉴别的任务,对Additive Margin Softmax进行了研究,并成功应用到虹膜特征编码网络IrisCodeNet。
1.1 IrisCodeNet网络模型设计
IrisCodeNet和ResNet18[14]同样采用18层设计,但针对虹膜识别任务的特殊性,在以下方面做了创新和改进:
(1)首个卷积层采用更小的卷积核和移动步长;
(2)激活函数用Mish[15]代替ReLU;
(3)使用改进的BasicBlock;
(4)使用Additive Margin Softmax Loss;
(5)对IrisCodeNet进行了可视化分析。
IrisCodeNet的一个卷积层使用了具有小感受野的3×3卷积核,而不是采用原始残差网络的7×7大核,移动步长也从2个像素减小为1个像素。这意味着首个卷积操作对输入图像的每一个像素进行了卷积运算。由于虹膜纹理丰富且细微,采用以上策略可以避免在网络一开始就因过大的卷积核和步长丢失过多的虹膜纹理信息。
无论是在IrisCodeNet的主干通道还是在残差块内,激活函数均采用Mish,其表达式见式(1)。和ReLU函数相比,Mish对负值的轻微允许会通过更好的梯度流,而不是像ReLU中那样存在硬性的零边界。不同于ReLU,Mish在零处的导数存在,平滑的函数曲线允许更好的信息进入神经网络,从而得到更好的准确性和泛化性[15]。

IrisCodeNet采用改进的残差块。如图1(b)所示,将BasicBlock中的激活函数ReLU替换为Mish,并且在第一个卷积层前面增加了一个Batch Normalization层来加速网络收敛。设置第二个卷积层中的卷积核的移动步长为2,进行下采样,不同的是,一般BasicBlock的下采样过程设置在第一个卷积层。改进的BasicBlock被称为ImprovedBlock。
IrisCodeNet详细的网络结构见表1,其对应的网络结构如图1(c)所示。训练阶段,IrisCodeNet对虹膜做一般的分类任务;测试阶段,去掉最后的分类层,加载训练好的网络权重,输入虹膜图像,从全连接层输出并保存512维的特征向量,即使用IrisCodeNet对该幅虹膜图像完成了一次特征编码。
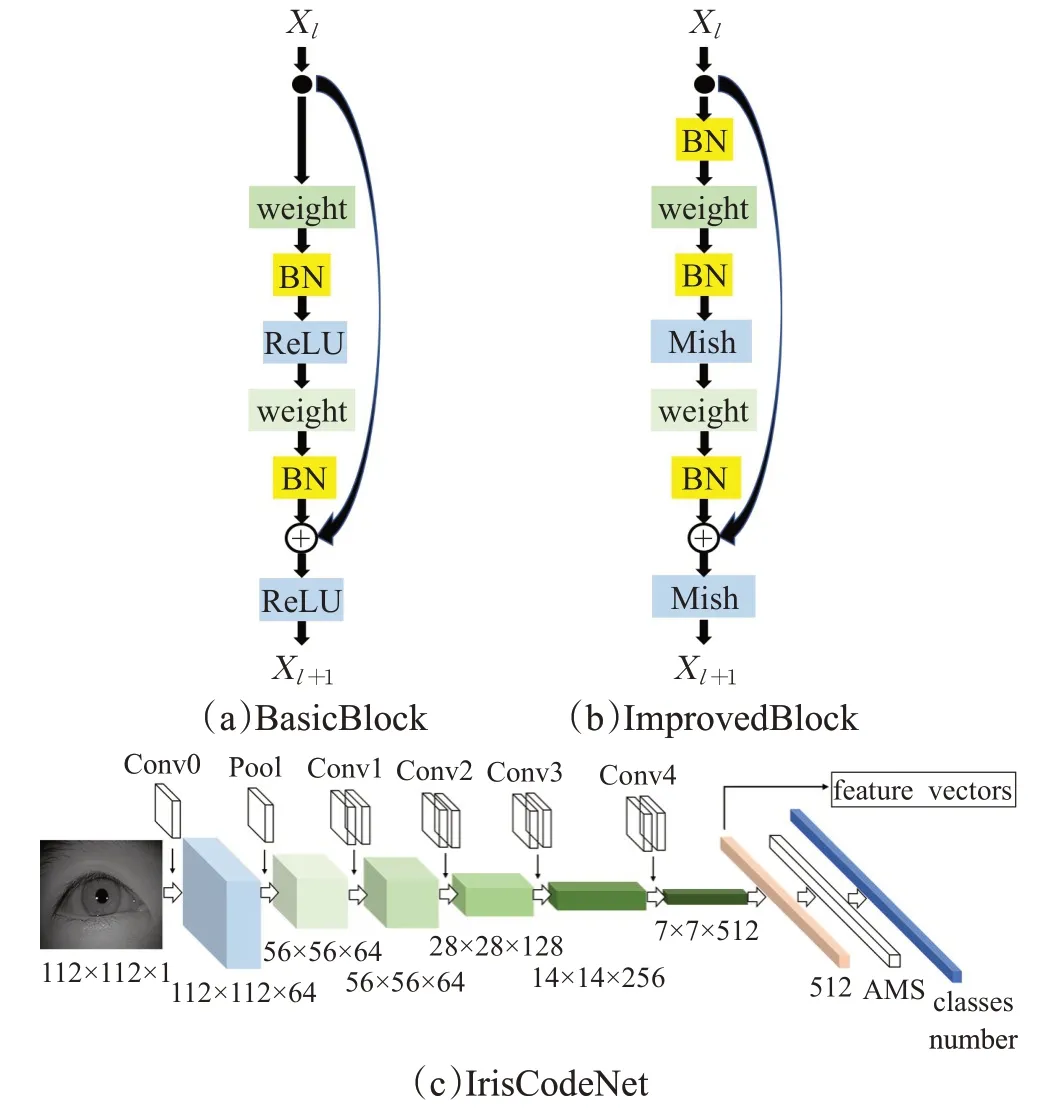
图1 IrisCodeNet网络结构图Fig.1 IrisCodeNet network structure diagram
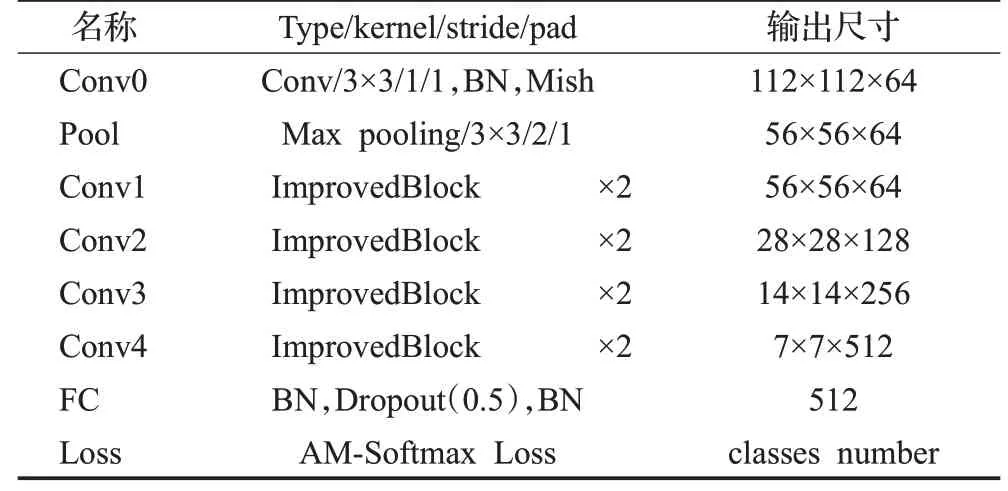
表1 IrisCodeNet网络结构细节Table 1 Network structure details of IrisCodeNet
1.2 Additive Margin Softmax Loss
Additive Margin Softmax Loss和Softmax Loss相比具有更大的优势:在分类任务中,改进后的AM-Softmax Loss可以更好地聚合同类样本,缩小同类距离,在客观上分离异类样本,扩大异类距离。
近些年来,AM-Softmax Loss在人脸识别中已经有很好的应用,而虹膜识别和人脸识别同属身份验证的生物识别技术,即本质上是以计算特征向量相似度的策略来鉴别身份,本文首次在虹膜识别中应用margin函数AM-Softmax Loss。接下来对此函数做简要说明。
AM-Softmax Loss是对Softmax Loss的改进,原始的Softmax Loss公式如下:
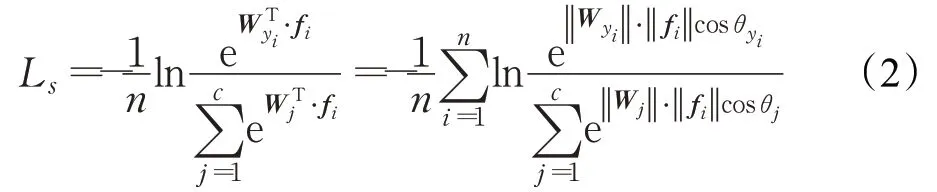
其中,f i是最后一个全连接层的输入(f i表示第i个样本),W j是最后一个全连接层参数矩阵W的第j列。WTyi f i称为第i个样本的目标逻辑[16]。
文献[12]提出了一个特殊的函数φ(θ),它为Softmax Loss引入了一个附加的间隔,公式如下:

值得注意的是,在这个Margin方案中,因为Ψ′(x)=1,即自变量的导数为1,所以并不需要计算反向传播的梯度,在训练过程中参数的更新易于实现。
总的来说,在Softmax Loss的基础上,将特征归一化和权重归一化同时应用到内积层构建了一个余弦层,然后使用超参数s缩放余弦值,最终形成了AM-Softmax Loss,公式为:
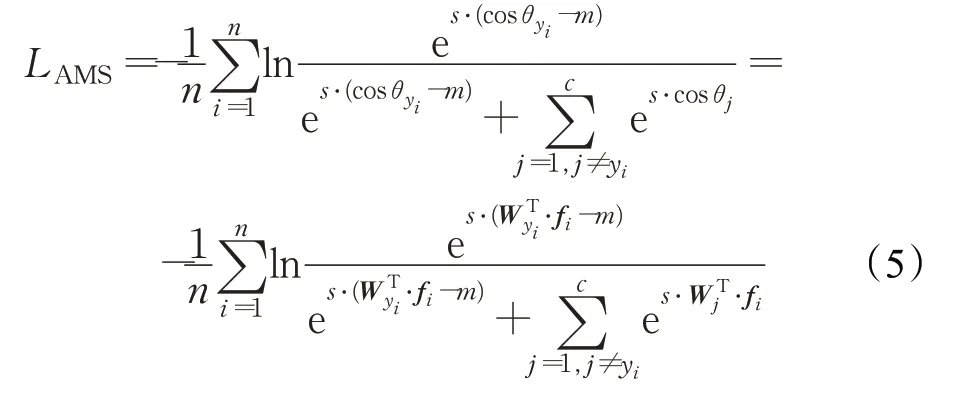
2 实验过程和结果分析
为了说明IrisCodeNet突出的虹膜识别性能,本章将对损失函数参数设置、图像预处理输入形式、网络输入尺寸、数据增强等几个方面做细致的实验和分析。
首先简要介绍实验所涉及到的评价指标、数据集、分割工具、可视化工具、向量匹配等几个概念。
评价指标:本文采用等错误率(EER)和在错误接受率(FAR)为0.001水平下的真实阳性率(即TAR@FAR=1E-3)以及类内类间相似度分数分离度指标作为评价IrisCodeNet性能的依据。另外,根据需要,部分实验采用了更加严格的TAR@FAR=1E-5。
CASIA-Iris-Thousand:该数据集[17]是中国科学院自动化研究所虹膜数据库中的一个子集。该子集一共有1 000个受试者的20 000张虹膜图像,左眼虹膜和右眼虹膜看作两类虹膜,即该数据库总共有2 000个虹膜类别。
CASIA-Iris-Distance:该数据集[17]包含来自142个对象的2 446个脸部图像,每个图像包含两只眼睛。由于原始图像是上半部分的人脸信息,需要使用眼睛检测算法对人眼及其周围区域进行定位。
IITD:该数据集[18]由印度理工学院德里分校提供,一共包括来自224个受试者的2 240个虹膜图像。
分割工具:选择OSIRIS[19]作为虹膜图像的分割工具。开源工具OSIRIS能够对采集到的人眼图像进行预处理,定位瞳孔和虹膜边界,分割出圆环状的虹膜区域,并生成尺寸为512×64的归一化虹膜。
Grad-CAM[20]:通过生成视觉解释可以使任何基于CNN的模型更加透明,突出显示图像中用于预测概念的重要像素区域。本文采用Grad-CAM来验证IrisCodeNet是否真正关注于虹膜细致的纹理特征以区分不同类别。
特征向量匹配:穷举测试集中所有虹膜图像两两之间的匹配对情况并标定每对的同异源,使用训练好的IrisCodeNet对所有匹配对做编码,之后使用余弦相似度计算匹配对中两个编码向量的相似度。基于所有同源和异源相似度分数可以得到不同阈值下的FRR和FAR,进而得到EER。
2.1 AM-Softmax Loss参数设置实验
为了证明IrisCodeNet和AMS-Softmax Loss在虹膜数据集上的有效性。在不同的实验组合下,测试在CASIA-Iris-Thousand上的EER和TAR水平。
数据处理方式或实验方法为:虹膜数据集CASIAIris-Thousand没有进行数据增强;使用OSIRISv4.1分割并归一化虹膜,网络输入尺寸为112×112,有效虹膜的训练集和测试集的比例为13 992∶5 999。经实验测试,IrisCodeNet和AM-Softmax与ResNet18和Softmax在CASIA-Iris-Thousand数据集上的EER和TAR水平如表2所示。
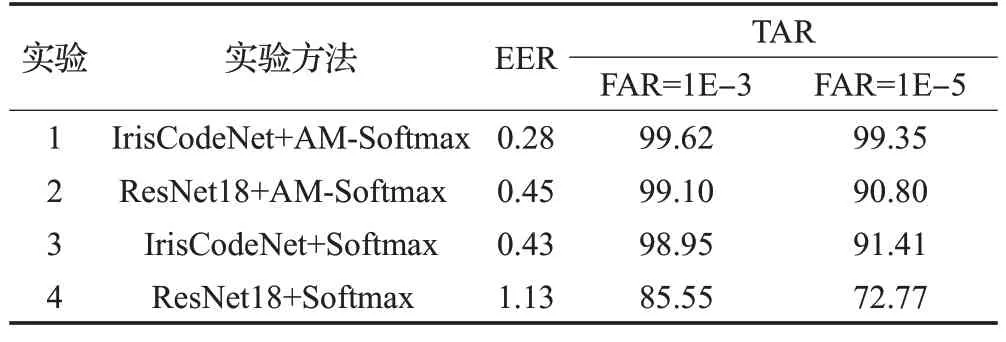
表2 不同实验方法的EER和TAR水平Table 2 EER and TAR levels of different experimental methods %
实验1对比实验2、实验3对比实验4说明使用了改进残差块的IrisCodeNet比使用了BasicBlock的ResNet18有更高的虹膜识别水平。实验1对比实验3、实验2对比实验4说明结合AMS-Softmax Loss比Softmax Loss有更好的实验效果。
由式(5)可以看出,AM-Softmax Loss有s和m两个参数。为了加速并稳定loss的优化过程,参考文献[12]的设置,s被固定为30.0;并且文献[12]在人脸数据集上对m的取值进行了实验并得出结论,m最佳取值区间为0.35到0.40。但是为了更好地应用于虹膜领域,本文对m的取值做了相应的实验。使用没有进行数据增强的虹膜数据集IITD、CASIA-Iris-Thousand、CASIA-Iris-Distance进行评估,m的取值从0.25到0.75,取值变化间隔为0.10。
由表3可以看出,实验结果并没有像文献[12]的实验结果那样随着m的增大,评价指标整体上先是变好再变差,而是出现了饱和现象:EER和TAR水平在m增加的后期基本不再变化。出现这种现象的可能原因是:无论是类别的多样性还是单个类别样本的丰富程度,这三个虹膜数据集均逊于规模可观的人脸数据集。所以在本文的实验中,即使设置更大的margin裕度,在相对较少的类别和图像总数下,AM-Softmax Loss依然可以优化得很好。不过,经过反复实验,发现m大于等于0.55情况下,损失函数曲线会有较大的震荡,且需要较长时间才能收敛,因此为了训练的稳定性和快速收敛,在后面的实验设置中,AM-Softmax Loss的参数m均设置为0.45。
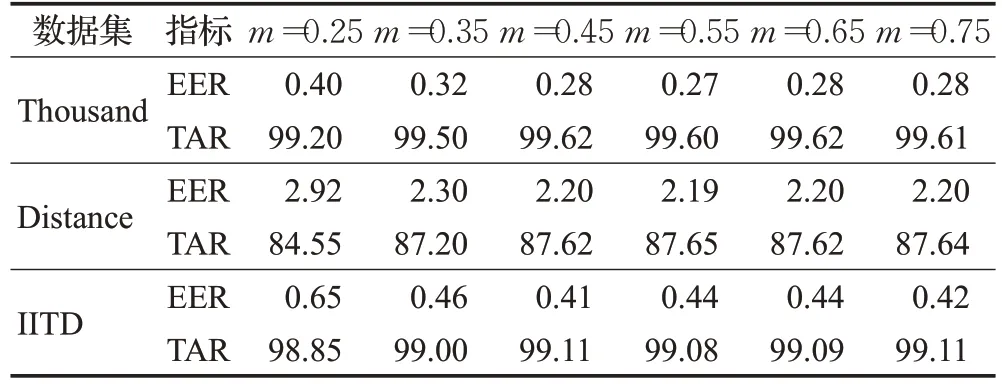
表3 三个数据集上不同m设置下的EER和TAR水平Table 3 EER and TAR levels under different m settings on three datasets %
为了进一步说明损失函数AM-Softmax Loss的优势,统计了表2的IrisCodeNet+AM-Softmax和IrisCodeNet+Softmax两组不同的实验设置分别在CASIA-Iris-Thousand测试集上5 998个类内相似度分数和17 985 003个类间相似度分数的分布图,如图2。
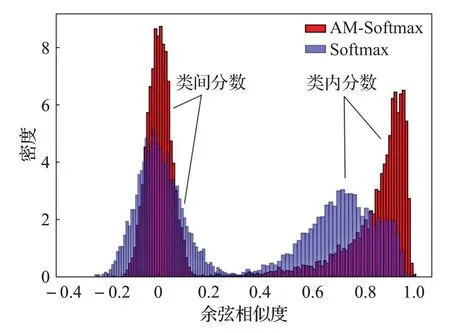
图2 两种损失函数对应的相似度分数分布情况Fig.2 Distribution of similarity scores corresponding to two loss functions
在图2中,红色部分对应于AM-Softmax Loss的相似度分布;紫色部分对应于Softmax Loss的相似度分布。由于采用余弦距离来评估向量相似度,两个向量相似度越高,夹角越小,余弦值就越大,图2中的右半部分区域表示的是类内相似度分数的分布情况。
可以明显看出,使用AM-Softmax Loss的红色类内的相似度分数在0.7到1.0区间内的轮廓更加“陡峭”,分数集中分布在0.8以上。而紫色类内部分,即对应于Softmax Loss的类内分数分布,则多集中在0.5到0.9区间内,分布相对均匀,并且仍有不少分数分布在0.3到0.4区间内,模糊的“边界”将增加异类被判断为同类的风险,从而导致更大的误识率。而红色类内区域的分数分布更加“紧凑”,极少的类间分数分布在右边界,AMSoftmax Loss把类内和类间的边界控制得更加清晰。
另外,分别计算了在两种损失函数下,类内、类间相似度分数的均值μ和标准差σ,并通过式(6)计算了二者的分离度d′,表达式如下:

其中,μ1和σ1分别表示在某个损失函数下类内相似度分数的均值和标准差;μ2和σ2表示类间相似度分数的均值和标准差。
由表4可知,AM-Softmax Loss的分离度8.74大于Softmax的6.03,d′越大,不同类别分开得越明显,分类效果就越好。
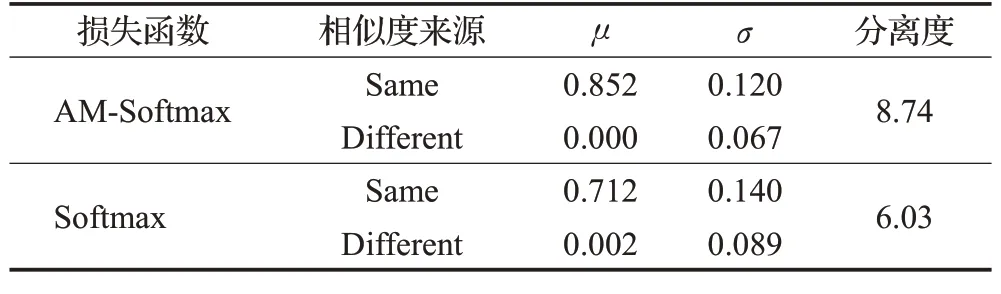
表4 在AM-Softmax Loss和Softmax Loss下匹配分数的分离度Table 4 Degree of separation of matching scores under AM-Softmax Loss and Softmax Loss
2.2 图像预处理输入形式
虹膜预处理是将传感器采集到的包含人眼和眼周的原始图像进行信息处理的过程:先把虹膜ROI定位出来,再把虹膜与眼睑、睫毛、巩膜等干扰信息分割开来,一般还要将分离出来的虹膜圆环进行归一化处理。图像预处理是虹膜识别系统中的关键步骤,在虹膜识别系统中,图像预处理的好坏将直接影响特征提取算法的有效性,进而影响虹膜识别的准确率。
为了探究IrisCodeNet在不同虹膜图像预处理程度下的性能表现,本文把预处理结果分为“ROI裁剪”“ROI掩码”“虹膜归一化”三种形式,为表述方便,分别用ROICrop、ROIMasked、IrisNormalized表示。
ROICrop是指仅仅定位并裁剪出虹膜ROI区域。如图3(a)所示,该矩形区域除了含有能够用来提取特征的虹膜有效信息,还包含有瞳孔、巩膜,以及一些眼睑等干扰信息,ROICrop本质上是对眼球的一种初步定位。
ROIMasked是指在ROICrop的基础上加上了掩码。如图3(b),掩码遮挡住了瞳孔、巩膜、眼睑等非重要信息,其意义在于在一定程度上“帮助”IrisCodeNet更加专注于对虹膜纹理进行特征提取。
IrisNormalized对应于传统算法中必不可少的归一化步骤。首先使用霍夫变换圆等方法把瞳孔和虹膜之间的内椭圆以及虹膜和巩膜之间的外椭圆检测出来,之后使用弹性模型将包含有虹膜的椭圆环映射到极坐标下,掩码也做相应的变换。最终,归一化的圆环区域结合归一化的掩码生成归一化虹膜。归一化虹膜图像如图3(c)所示。
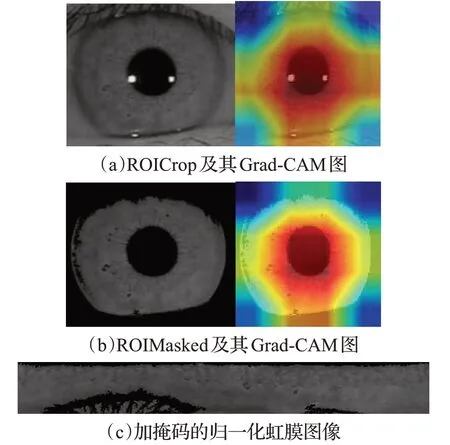
图3 不同预处理程度下的虹膜图像及Grad-CAMFig.3 Iris images and Grad-CAM under different preprocessing levels
2.2.1 ROICrop和ROIMasked识别实验
经过上述实验和讨论,网络输入尺寸设置为112×112,并且使用本文提出的数据增强方式,最后在数据库CASIA-Iris-Thousand上评估。
实验结果如表5所示,ROICrop和ROIMasked的EER和TAR水平相当,各自分别为0.25%和99.65%、0.22%和99.72%。从评价指标上可以得出结论:即使存在干扰信息,IrisCodeNet依然可以很好地关注虹膜的纹理区域。为了进一步直观体现IrisCodeNet的特征提取效果,使用Grad-CAM对ROICrop和ROIMasked进行可视化,如图3所示,颜色冷暖程度代表了图像像素被特征提取器索引的频率,索引频率从高到低对应的颜色依次为红色>黄色>绿色>蓝色。可以发现,在瞳孔周围的虹膜区域,红色斑块较多,而绿色或蓝色斑块多分布于虹膜和巩膜圆形边界和边界以外的区域。Grad-CAM从可视化的角度再次证明了即使识别的是初步定位的虹膜ROI,IrisCodeNet依然可以很好地对虹膜特征进行表达。这在一定程度上降低了对分割精度的要求,甚至可能没有必要再进行更为细致的分割步骤。这具有深远的意义,将大大减少图像预处理时间,从而提高整个虹膜识别系统的工作效率。同时还发现,如图3(b),ROIMasked的热力图颜色的轮廓更加清晰,红色区域即索引较多的像素密集分布在靠近瞳孔边缘侧,这和掩码对干扰信息的遮挡有密不可分的关系。
2.2.2 IrisNormalized和ROIMasked识别实验
为探究不同分辨率的归一化虹膜图像对识别精度的影响,遵循文献[7]的归一化图像处理方法:先使用OSIRISv4.1工具将虹膜归一化为160×40、224×56、320×80的不同尺寸的图像,再将图像裁剪并拼接为80×80、112×112和160×160三种尺寸,如图4所示。
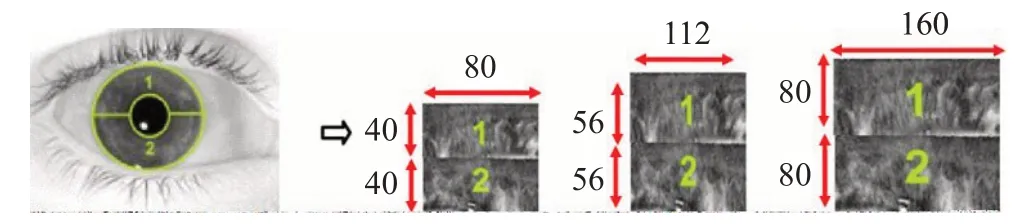
图4 不同归一化尺寸图像的处理过程Fig.4 Processing process of different IrisNormalized size images
实验结果如表5所示。在三个网络输入尺寸中,IrisNormalized-80的效果最差,这可以解释为过度的下采样丢失了大量的虹膜信息;相反的,为了送入网络更多的虹膜纹理信息,试图增大网络的输入分辨率,但是实验发现,更大分辨率的IrisNormalized-160和IrisNormalized-112相比虹膜识别效果却稍微变差,这个现象和文献[7]关于网络输入尺寸实验所得结果一致。对IrisCodeNet来说,可以认为112×112是相对最优的归一化尺寸。
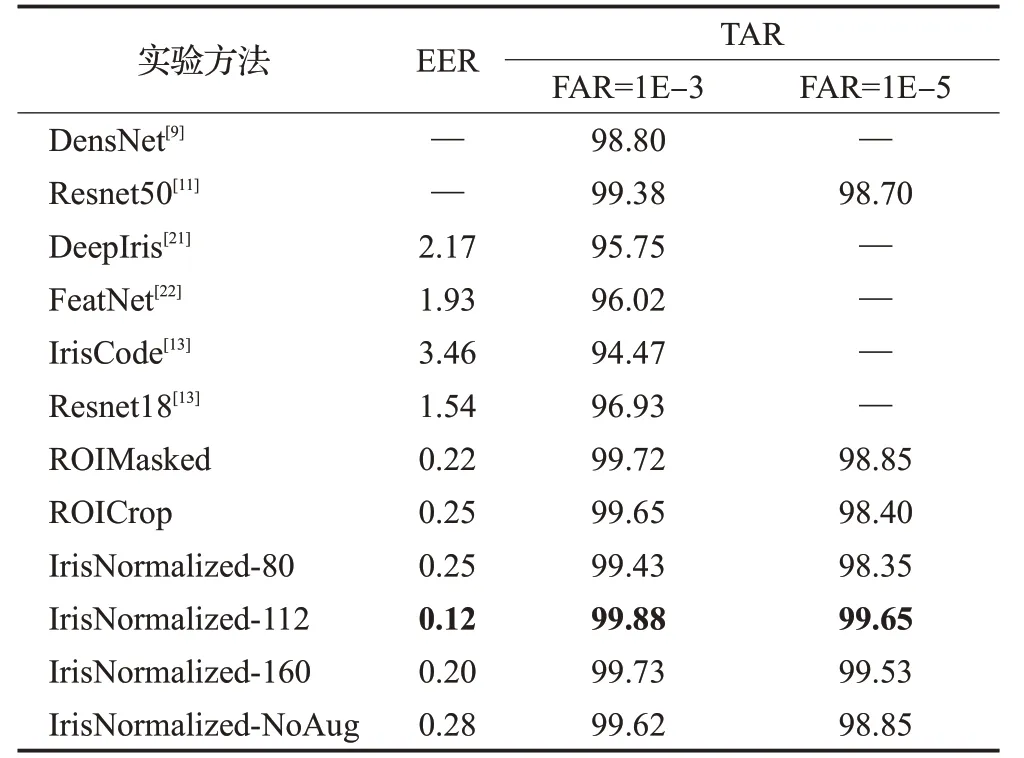
表5 Thousand不同实验方法下的实验结果Table 5 Experimental results under different experimental methods of Thousand %
IrisNormalized-112和IrisNormalized-160实验组的EER均低于ROIMasked的0.22%;TAR均高于ROIMasked的99.72%。网络输入尺寸为112×112时,即IrisNormalized-112取得了最佳的虹膜识别水平:EER=0.12%,TAR=99.88%。这和ROIMasked相比性能水平有了较大的提升,说明基于CNN的特征提取算法和传统虹膜识别算法一样,在预处理阶段非常有必要对虹膜图像进行归一化处理。这可以解释为:在虹膜图像采集过程中,瞳孔因光照会发生缩放,并且按照放射方向较大范围地影响虹膜纹理的分布,将会影响在相似度匹配时卷积核沿水平方向进行滤波的结果,而虹膜归一化将沿瞳孔边缘呈放射状分布的虹膜纹理映射为沿着水平轴分布的细带状纹理,在很大程度上解决了因瞳孔缩放带来的相似度匹配时存在的配准问题。
2.2.3 和现有算法的比较
实验组IrisNormalized-112达到了EER=0.12%,TAR=99.88%的最高识别水平。无论是和基于Gabor的IrisCode[13]传统算法相比较,还是近些年来同样使用卷积神经网络的新型算法相比较,IrisCodeNet-IrisNormalized-112均具有更低的EER和更高的TAR水平。特别地,即使不进行归一化步骤,单纯考虑ROIMasked和ROICrop,其虹膜水平都远远优于传统算法,甚至也优于使用归一化虹膜图像的ResNet50[11]、DeepIris[21]、FeatNet[22]、ResNet18[13]等深度神经网络算法。
2.3 虹膜数据增强
在虹膜采集过程中,往往因为光照、被拍摄者头部的移动和一定角度的旋转等非协作因素导致图像质量参差不齐;另外现有的虹膜数据集的丰富程度和体量规模受到一定限制,因此,非常有必要针对训练集进行数据增强,以满足神经网络参数的训练。
本文没有使用线上增强对归一化的虹膜图像直接进行图像增强操作,因为这并不符合实际;而是对未进行任何预处理的人眼原图进行本地数据增强,选择了改变亮度、增加噪声、图像模糊、角度旋转四种变换方式来模拟图像采集的真实场景。增强后样本再使用OSIRISv4.1工具进行预处理,根据网络训练任务的需要,生成不同预处理程度的虹膜图像。表6展示了三种不同预处理形式的数据集统计信息。
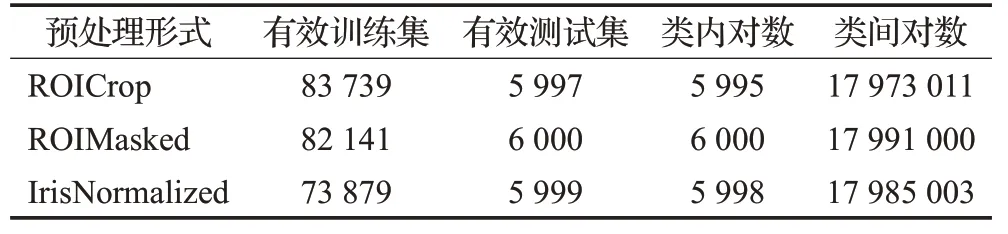
表6 Thousand不同预处理形式下的统计信息Table 6 Statistics under different preprocessing levels of Thousand
下面展示了在CASIA-Iris-Thousand上详细的数据处理流程:
(1)遵循文献[10]的做法,将CASIA-Iris-Thousand数据集的20 000张原始虹膜图像按类别7∶3分割为原始训练集和测试集,总数比例为14 000∶6 000。
(2)原始训练集经过本地数据增强,每个样本扩增5张,最终得到有60 000张图像的增强训练集。
(3)把60 000张增强训练集图像、14 000张原始训练集图像、6 000张测试集图像送入OSIRISv4.1工具,进行图像预处理,并剔除掉预处理失败的样本,分别生成有效增强训练集、有效原始训练集和有效测试集。
(4)将有效的增强训练集和有效的原始训练集合并为有效训练集,用于网络特征提取器的训练;6 000张测试样本经过OSIRISv4.1工具预处理并经过筛选之后,生成了用于匹配测试的有效测试集。由测试集生成的类内匹配对以及类间匹配对的数量信息见表6。
最终的实验结果统计于表5中,对比进行了样本数据增强的IrisNormalized-112和没有进行样本数据增强的IrisNormalized-NoAug,发现前者有更好的识别性能,证明了本文提出的本地数据增强方式的有效性。
值得注意的是,无论是含有大量干扰信息的ROICrop还是在其基础上加了掩码的ROIMasked以及进一步归一化的IrisNormalized,甚至没有数据增强的IrisNormalized-NoAug,所有的实验指标均优于本文所列出的传统算法和新型的神经网络算法。对应于表6的ROC曲线如图5所示。其中,符号“×”是文献[11]使用ResNet50网络得到的最佳识别结果,TAR=99.38%;符号“*”是文献[9]使用DenseNet网络得到的最佳识别结果,TAR=98.80%。其他算法的TAR水平均低于本文所有实验方法得到的结果,由于坐标限制,并没有在图中体现。
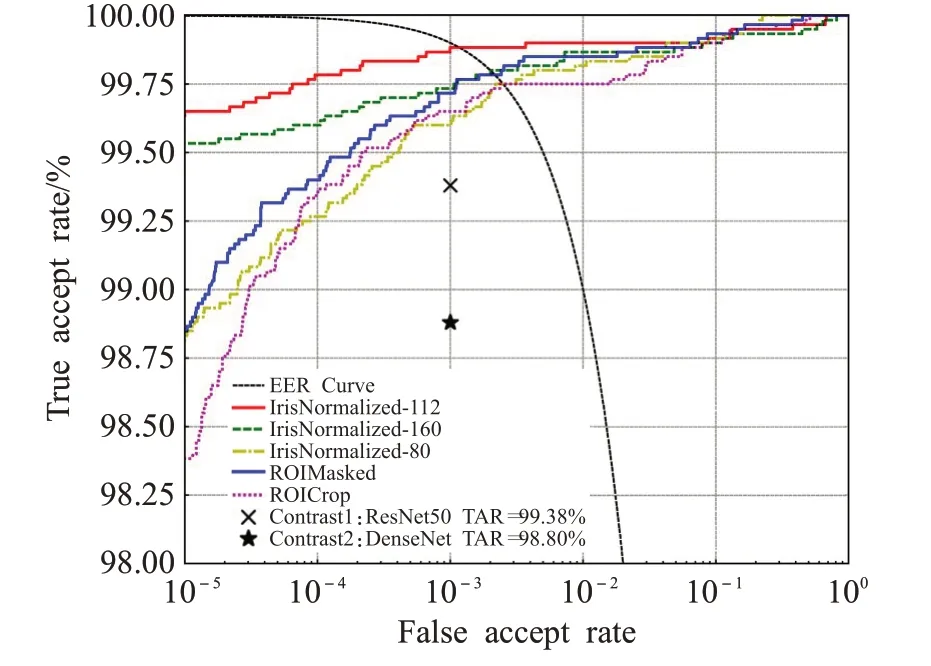
图5 Thousand不同实验方法下的ROCFig.5 ROC under different experimental methods of Thousand
2.4 在其他数据集上的实验结果
对于CASIA-Iris-Distance、IITD数据集,本文遵循文献[22]的实验设置:全部的右眼虹膜用于训练,全部的左眼用于测试。因为CASIA-Iris-Distance原始图像是整张人脸,所以先使用文献[23]的定位算法定位眼睛及其眼周区域,再使用本文提出的本地数据增强方法进行数据增强,然后送入OSIRISv4.1进行归一化,并剔除掉预处理失败的样本。
在两个数据集上,用于训练和测试的有效样本数量以及测试集产生的同类验证对、异类验证对信息如表7所示。

表7 Distance、IITD分配和验证对统计信息Table 7 Allocation and verification pair statistics of Distance and IITD
实验结果如表8所示,在CASIA-Iris-Distance、IITD数据上,无论EER还是TAR,IrisCodeNet和传统算法OSIRIS和log-Gabor以及Ordinal相比显示出更加优异的分数。唯一的是,在两个数据集上的EER好于ICCV17的算法,TAR水平略低于其算法。

表8 在Distance、IITD上的实验结果Table 8 Experimental results on Distance and IITD%
3 结束语
为了实现对虹膜纹理准确的特征表达,针对虹膜识别任务的特点,提出了一种新的虹膜特征编码网络IrisCodeNet。该网络结合了改进BasicBlock网络结构和可以扩大决策边界的margin损失函数AM-Softmax Loss。
本文进行了多组对比实验,评估了损失函数AMSoftmax Loss参数m、虹膜图像预处理输入形式、网络输入尺寸、数据增强等多个因素对IrisCodeNet性能的影响。结果发现,IrisCodeNet在多个数据集上均取得了卓越的虹膜识别效果。本文得出结论:
(1)由于可以增加扩大决策边界,聚合同类样本,AM-Softmax Loss比Softmax Loss更加适用于基于特征向量相似度匹配的虹膜识别任务。
(2)IrisCodeNet在预处理程度为ROICrop的CASIAIris-thousand数据库上,表现出了比传统经典算法和新型算法更高的性能水平,并结合梯度热力图,说明了IrisCodeNet生成的特征提取器对粗略定位的虹膜ROI也有很强的特征描述能力。另外,因为匹配验证存在模板间的配准问题,所以无论是传统算法的Gabor算法还是基于CNN训练的特征提取器,虹膜归一化依然是最佳的预处理方式。
(3)适当地对归一化图像进行降采样,即减小网络输入尺寸,将提高IrisCodeNet的特征提取性能。
(4)为了增加训练样本的丰富性,模拟实际采集场景,采用改变亮度、增加噪声和模糊、平移和旋转图像的方式丰富了训练数据,在一定程度上提高了IrisCodeNet的虹膜识别效果。
(5)IrisCodeNet在CASIA-Iris-Thousand、IITD、CASIA-Iris-Distance三个虹膜数据集上的EER和TAR@FAR=1E-3水平均优于传统算法和一些深度神经网络的算法。
猜你喜欢
中国典型病例大全(2022年11期)2022-05-13 17:54:50
电子制作(2018年19期)2018-11-14 02:37:08
文萃报·周二版(2018年51期)2018-08-04 06:05:18
制导与引信(2017年3期)2017-11-02 05:16:56
自动化学报(2017年11期)2017-04-04 02:52:58
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
电网与清洁能源(2015年2期)2015-02-28 16:03:07
警察技术(2015年3期)2015-02-27 15:37:15
噪声与振动控制(2015年4期)2015-01-01 07:08:21
