
基于多尺度特征融合的抓取位姿估计
2022-05-19 13:28:56肖贤鹏李树春
计算机工程与应用 2022年10期
肖贤鹏,胡 莉,张 静,2,李树春,张 华
1.西南科技大学 信息工程学院,四川 绵阳 621010 2.中国科学技术大学 信息科学技术学院,合肥 230026
尽管机器人对操作物体相对容易,但对任意物体的可靠抓取[1-3]仍然是机器人面临的一个难题。这一问题的解决将推动机器人技术在工业领域的应用,比如零件装配、装箱和分类[4-5]。同样,它也将推动辅助机器人领域的发展,即机器人与周围环境进行交互,以满足人类的需求。机器人抓取包括感知、计划和控制[6-7]。作为一个起点,知道抓取哪个对象以及如何做是必要的研究方向。因此,对目标物体的机器人抓取候选对象进行准确多样的检测,将有助于实现更好的抓取路径规划[8],提高基于抓取操作任务的整体性能。
目前,随着深度学习在各种任务中的广泛应用,基于深度学习的抓取位姿估计也取得了一定的研究成果。Redmon等人[9]提出一种基于卷积神经网络的机器人抓取检测的精确、实时方法,对可抓取边界框执行单阶段回归,而不使用标准滑动窗口或区域建议技术,通过使用一个局部受限的预测机制来预测每个对象的多个抓取候选;Kumra等人[10]提出利用场景RGB-D图像预测平行板机器人抓取未知物体的最佳抓取位姿,该模型使用深度卷积神经网络从场景中提取特征,然后使用浅层卷积神经网络预测目标的抓取候选;Guo等人[11]提出了一种融合视觉和触觉感知的融合深度体系结构,用于机器人抓取检测,该模型使用触觉数据辅助网络更好地完成学习机器人抓取检测任务的视觉特征;Chu等人[12]提出一种两阶段的深度学习架构来预测机器人的可抓取位置,将学习问题定义为零假设竞争分类问题而不是回归问题进行预测。上述提到的深度网络从不同方面解决抓取中的定位问题,但都使用单个高层特征图进行回归,使用的特征较少,会降低检测准确率,基于此引入多尺度特征[13]来预测抓取候选,并将抓取网络中的ROI Pooling替换为ROI Align来消除量化误差。
1 抓取位姿
抓取位姿[14]采用五维抓取矩形框表示,描述了平行板夹持器在抓取物体之前的位置、姿态和打开距离。如图1所示,红线表示平行板夹持器,(x,y)表示夹持器的中心点坐标,θ表示夹持器相对于水平方向的角度,w表示夹持器的开口距离,h为夹持器宽度。
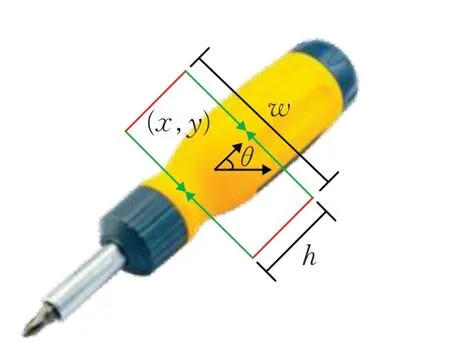
图1 五维抓取框表示Fig.1 Five-dimensional grasp box representation
2 抓取网络介绍
为引入更丰富的特征表示,学习更多的结构线索,本文采用ResNet-50作为主干网络,设计一个更深层次的网络模型,以改进机器人抓取检测的特征提取。ResNet设计的残差网络解决了网络加深所造成的梯度爆炸和梯度消失的问题。残差网络[15]由跳跃连接和标准卷积神经网络组成,该设计允许网络绕过输入,并激励卷积层作为残差网络的最终映射函数,以此来预测残差。
抓取网络具体结构如图2所示,该网络以RGD图像作为输入,并为图像中的抓取对象预测具有方向和矩形边框的多个抓取候选。其中蓝色块表示网络层,灰色块表示特征图,抓取建议网络(grasp proposal network,GPN)预测的输出边框中,黑线表示两指夹持器的开口长度,红线表示夹持器的平行板。
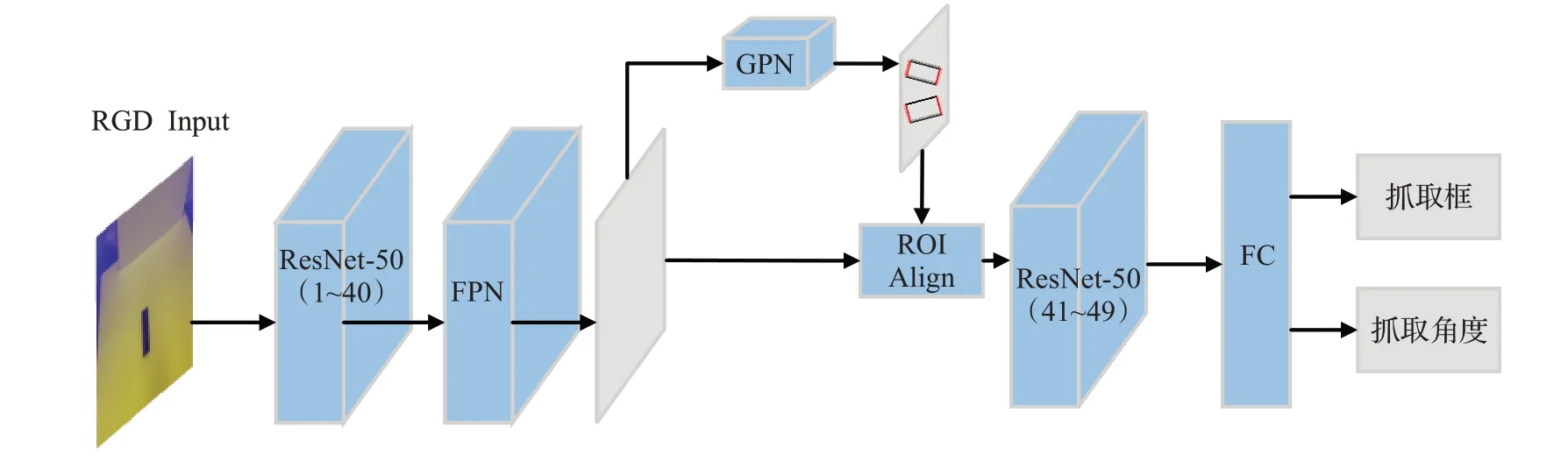
图2 抓取网络结构图Fig.2 Grasp network structure diagram
2.1 特征金字塔网络
抓取检测中,由于小目标本身具有的像素信息较少,容易在下采样过程中丢失特征,若直接利用单个高层特征进行边框回归和角度分类,会降低检测准确率。为提升检测效果,引入特征金字塔网络(feature pyramid networks,FPN)进行多尺度融合,处理检测过程中的尺度变化问题,提高小目标检测的鲁棒性。
如图3所示,左侧为ResNet特征提取网络,选取该网络的2~4卷积层的最后一个残差块特征作为FPN的特征,从高层特征上采样实现特征融合,这样既可以利用顶层的高语义信息,又可以利用底层的高分辨率信息。为了使所有级别的特征层通道数保持一致,先使用1×1卷积压缩通道数,再与2倍上采样后的上层特征图相加。
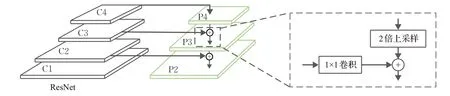
图3 FPN结构图Fig.3 FPN structure chart
2.2 抓取建议网络
作为抓取网络的重要组成部分,抓取建议网络(GPN)主要在整个图像中生成抓取建议。和区域建议网络(region proposal network,RPN)类似,抓取建议网络在特征图上滑动一个3×3的卷积核,使用卷积网络构建与类别无关的候选区域。由于每个真实框具有不同的角度,为降低其在生成抓取建议时的难度,将每个有方向的边框重置为具有垂直高度和水平宽度的矩形,如图4所示,底部为真实框,顶部为重置后的边框。
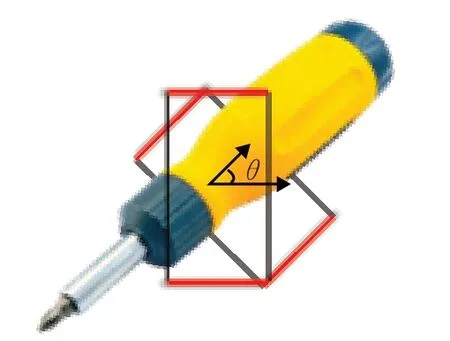
图4 抓取边框Fig.4 Grasp frame
GPN对网络预测的边框进行调整,利用变换参数得到和真实框更为接近的候选框,平移参数t x、t y和伸缩参数t w、t h具体表示如下:
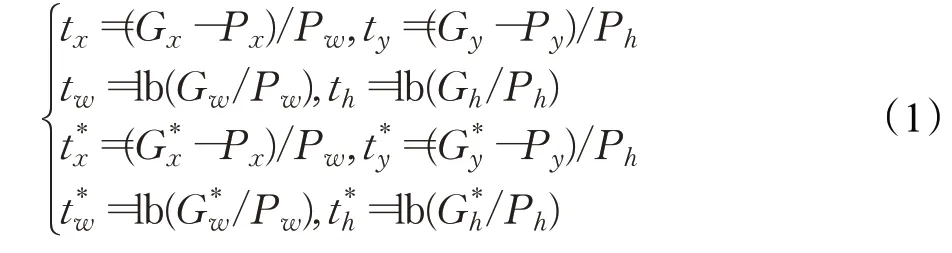
式中,G、P、G*分别表示真实框、预测框和候选框,x、y表示边框中心点坐标,w、h表示宽高。
用t i表示第i个抓取边框的四维向量(x,y,w,h),p i表示对应边框的预测概率,对于所有抓取建议,定义其损失为:
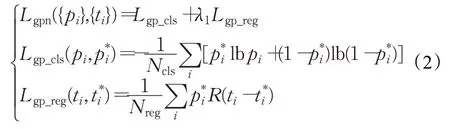
其中,Lgp_cls为抓取建议分类的交叉熵损失,Lgp_reg为抓取建议的L1回归损失,Ncls和Nreg是归一化因子,λ1是两者之间的权重。
2.3 ROI Align
在常见的检测网络中,ROI Pooling的作用是使生成的候选框映射为固定尺寸的特征图。这一操作存在两次将浮点数量化为整数的过程,分别发生在对ROI坐标和对ROI划分为等大子区域上的量化,导致最后的边框定位存在一定的偏差。因此,本文采用RoI Align来进行区域特征映射。ROI Align取消了量化操作,对于量化中产生的坐标为浮点数的像素,采用了双线性内插的方法来获取像素值,从而将感兴趣区域归一化的过程转化为一个连续的操作,解决了ROI Pooling操作中两次量化造成的区域不匹配的问题。
2.4 抓取检测
如果将RGB-D输入图像回归到一个单一的5维抓取表示g={x,y,w,h,θ},在预测非欧几里德(非凸)空间中的坐标时会导致其回归和标准L2损失表现不佳。基于此,将抓取表示的方向坐标θ量化为18个等长间隔,并将输入/输出映射为抓取方向的分类任务。并添加了一个非抓取收集定向类,用于使用零假设进行显式竞争。如果所有方位分类器输出的得分均低于非抓取类,则认为抓取建议不正确并拒绝。
用ρl表示经过Softmax层后得到l类的概率,βl表示对应的预测抓取框,则抓取框损失函数定义为:

其中,Lgrc_cls是抓取建议分类的交叉熵损失,Lgrc_reg是抓取框的L1回归损失,λ2是回归损失的权重,β*是真实抓取框。整个网络总的损失函数为:

为了有效处理抓取建议方案,将ROI Align层集成到网络中,这样可以避免在感兴趣区域内重新计算特征。ROI Align将抓取建议的所有特征叠加在一起,然后将这些特征反馈给两个全连接层进行边界框回归和方向参数分类。
3 模型训练及实验结果分析
3.1 数据集及预处理
本文使用康奈尔抓取数据集,该数据集是最常用的抓取检测数据集,由224个不同对象共885张图像组成,每个物体在不同方向或姿势上拍摄了若干幅图像。
为适应ResNet-50网络的输入格式,用深度通道替换原图中的蓝色通道,深度图由数据集中的点云数据进行欧式距离变换并进行深度图修补得到。由于RGB数据在0~255之间,深度信息被归一化到相同的范围。同时,在训练之前对数据进行扩充。首先,对图像进行中央裁剪,得到一个351×351的区域,然后将裁剪后的图像在0到360°之间随机旋转,中间裁剪为321×321。旋转后的图像在x和y方向上随机平移最多50个像素。预处理为每张图像生成1 000个增强数据。最后,将图像大小调整为227×227,送入网络进行训练。
3.2 训练
对整个网络进行端到端的训练,计算机采用Precision T7610工作站,E5-2600 V2处理器,32 GB内存,单nVidia Titan-XP卡。操作系统为Ubuntu16,在Tensorflow-GPU1.14、cuda-9.0、cudnn7.1下进行训练,epochs和初始学习率分别设置为5和0.000 1,每10 000次迭代将学习率除以10。
3.3 评价标准
抓取参数[9-12]的精度根据预测框和真实框的接近度进行评估,具体指标如下:
(1)预测抓取框gp和真实框gt的夹角在30°以内;
(2)预测抓取框和真实抓取框的Jaccard指数大于0.25。
Jaccard指数如式(5)所示:

3.4 训练结果及分析
为验证网络中各模块的表现力,设计三组不同网络结构进行训练,并对训练好的网络模型进行测试,选择所有抓取候选输出中预测得分最高的边框作为最终输出。对实验结果的计算使用五折交叉验证集,将数据集划分为5份,选取1份作为测试集,剩下4份用来训练。分别逐图像和物体两种方法进行拆分。逐图像拆分即把所有数据随机划分,可以验证模型的泛化能力;逐物体拆分即把所有图像中相同的物体分到相同的交叉验证集中,可以测试网络对新物体的泛化能力。测试结果如表1所示。
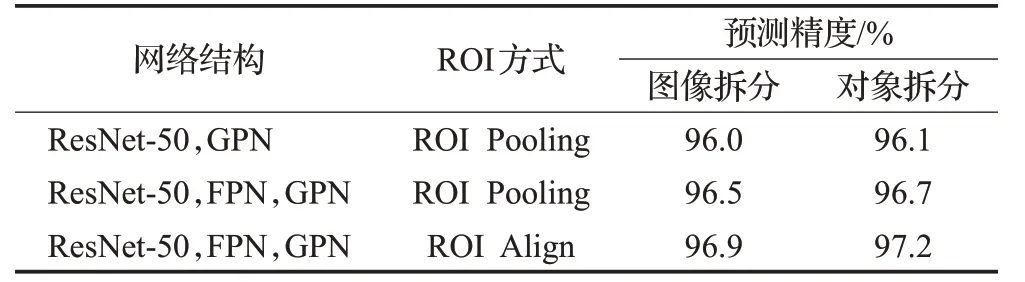
表1 不同网络模型抓取检测结果Table 1 Grasp detection results of different network models
由表1可以看出,在网络结构中增加FPN结构,两种测试精度分别提升0.5个百分点和0.6个百分点,将原结构中的ROI Pooling替换为ROI Align,检测精度分别提升0.4个百分点和0.5个百分点,说明FPN和ROI Align可以提高网络的检测精度。
真实场景下,可行的抓取操作一般与物体自身的形状和放置角度有关,仅给出一个抓取候选框可能完成不了抓取操作。因此,网络输出多个高置信度的候选抓取,以供后续计划选择。图5为网络输出的检测结果,其中图(a)为不同测试对象输出多个候选抓取框的检测结果,图(b)为输出最高置信度候选框的检测结果,图(c)为同一个抓取对象不同角度放置的检测结果。

图5 抓取网络检测结果Fig.5 Grasp network detection results
表2为康奈尔RGB-D抓取数据集的矩形抓取检测精度与之前工作的比较结果,所有实验均在相同数据集和相同评价指标下完成,可以看到本文算法在以RGD图像作为输入时,预测精度均高于其他算法。逐图像拆分时检测精度为96.9%,逐对象拆分时,对新目标的检测精度达到了97.2%。此外,在没有深度信息的RGB图像上进行实验,图像和对象拆分的检测结果都低于RGD图像,说明了深度图像在检测中的有效性。
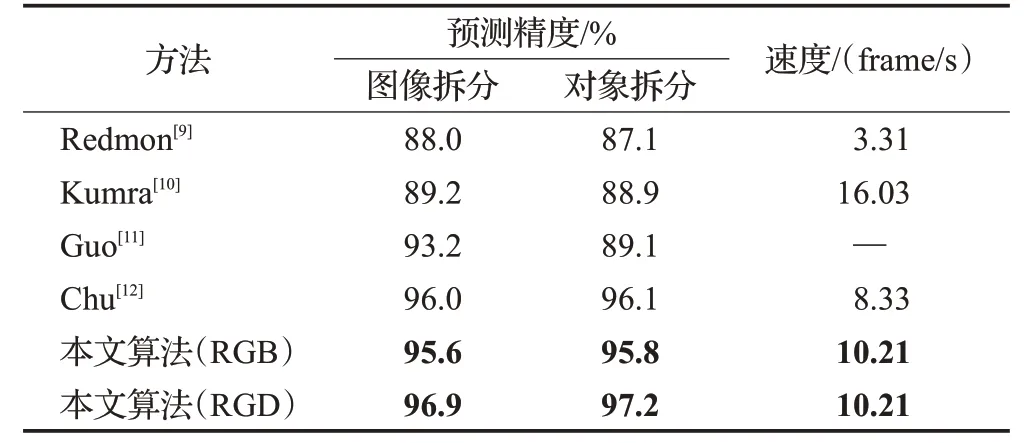
表2 不同算法抓取检测结果Table 2 Grasp detection results of different algorithms
比较表2的指标参数发现,本文算法为达到较高的抓取检测精度,采用的抓取网络结构相对复杂,计算速率比表中Kumra等人所提出单结构网络有所下降。但本文算法检测一幅图像耗时约0.098 s,可满足在真实场景下进行实时检测和抓取操作的应用要求。
表3为检测模型中不同Jaccard指数下的结果。随着Jaccard指数的升高,抓取检测的精度会逐渐下降,但即使在0.40 IOU的情况下,检测精度仍具有竞争力。
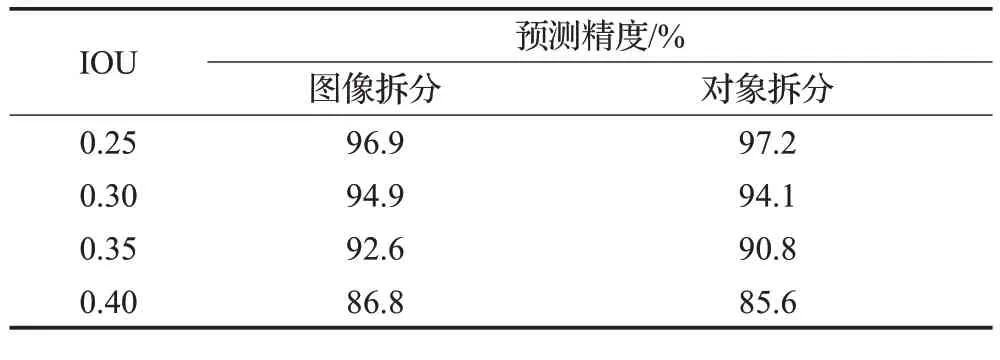
表3 不同Jaccard指数下检测准确率Table 3 Detection accuracy under different Jaccard indexes
4 抓取实验与分析
4.1 硬件系统
为评估真实场景下视觉检测和随后执行的抓取运动的性能,搭建了实物实验抓取系统,如图6所示。该系统主要由UR5机械臂、工作台和Inter Realsense D415深度相机三部分组成,其中深度相机被固定在刚性支架上,与机械臂形成Eye-to-Hand手眼结构,并进行手眼标定,完成相机坐标系和机械臂末端坐标系的转换工作。
4.2 实验设计
为了较全面地评估系统性能,实际抓取操作抽样得到以下12种实验对象。如图7所示,将实验对象分为手动工具和生活用品两组,每组6种实验对象,手动工具组有钳子、活动扳手、扳手、卷尺和大小螺丝刀,生活用品有美工刀、纸盒、纸杯、鼠标、网球和瓶子。
图8为目标抓取流程图。首先深度相机获取工作台上物体的彩色信息和深度信息,将深度信息进行深度图修复后和彩色图融合得到目标对象的RGD图;然后将图像以中心点为中点裁剪为227×227的图像输入网络模型进行抓取框预测,得到多个预测框;最后通过手眼转换矩阵将相机坐标系下的预测框信息转换到机械臂末端工具坐标系执行抓取。
4.3 实验分析
实物实验时,将每个物体按不同角度不同方向放置在工作台上进行视觉检测和实物抓取,每个物体进行50次实验,视觉检测以物体是否被预测出抓取框为检测标准,抓取检测以实际抓取成功与否作为评价指标。图9为不同物体的检测结果,其中图(a)展示了抓取对象中较为典型的几个物体的检测结果,这几个对象具有厚度小、形状小、不规则的特征;图(b)展示了同一对象在不同方向下的检测结果。

图9 实物检测结果Fig.9 Physical test results
为了从多个候选框中选取具有代表性的抓取框进行一次性实物抓取,对一次视觉检测中所有抓取框分别做置信度排序和距离中心点距离排序,选择最高置信度和最靠近中心点的两个框分别做抓取检测,检测结果如表4所示。
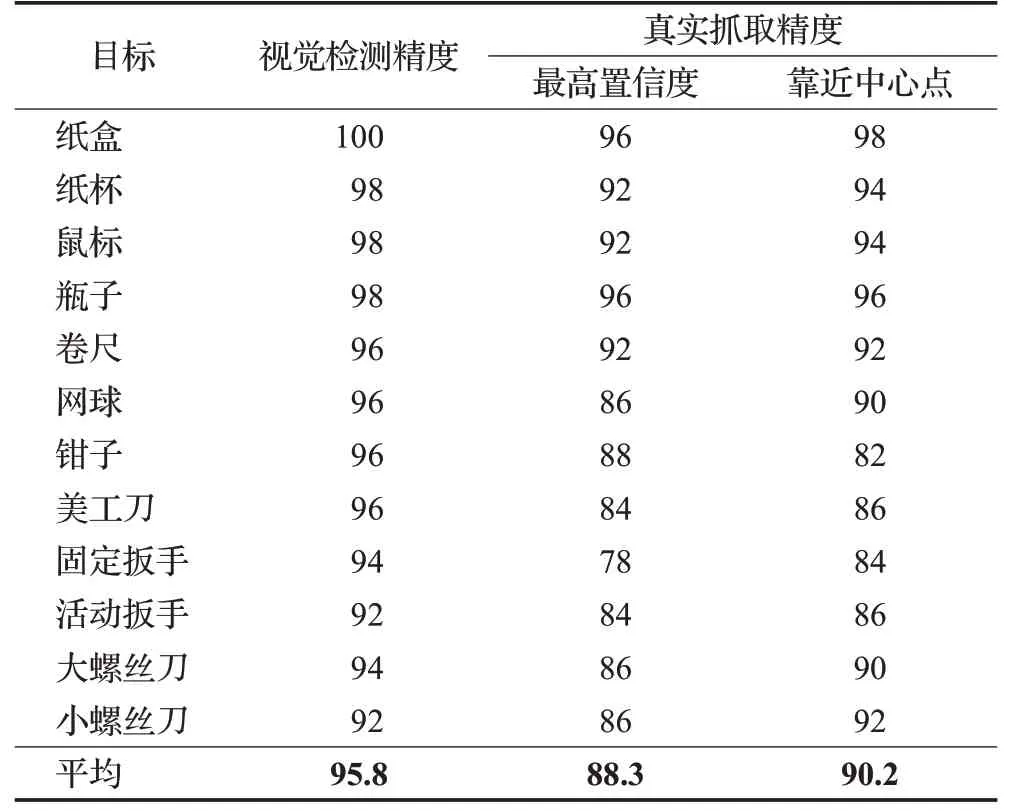
表4 实物抓取结果Table 4 Object grasp results %
从表中可以看出,实物抓取实验中物体平均检测精度为95.8%,最高置信度和靠近中心点的平均抓取精度分别为88.3%和90.2%,且中心点抓取比最高置信度抓取平均精度高1.9个百分点,除钳子外的其他物体中心点抓取精度均高于最高置信度抓取。这是因为钳子的手柄开合度会随机变化,对抓取位姿的估计带来了较大的干扰。
为进一步分析表4中不同目标检测成功率、抓取成功率与目标特性之间的关系,绘制了图10所示的物体检测-抓取成功率折线图。从图中可以清晰看到:(1)目标检测精度方面,纸盒、纸杯、鼠标、瓶子这几种物体的检测精度明显优于螺丝刀和扳手,原因是同样距离成像时,前者外形尺寸大,图像中有效像素占比高(扳手和螺丝刀因金属镜面反光,导致有效像素降低);(2)在抓取精度上,纸盒、纸杯、鼠标、瓶子、卷尺这几种物体的抓取精度明显优于扳手、美工刀、钳子,前者相比后者,物体形态固定,且由于目标物体外形对称性较强,外观较为规则,摆放姿态有限,抓取成功率高。
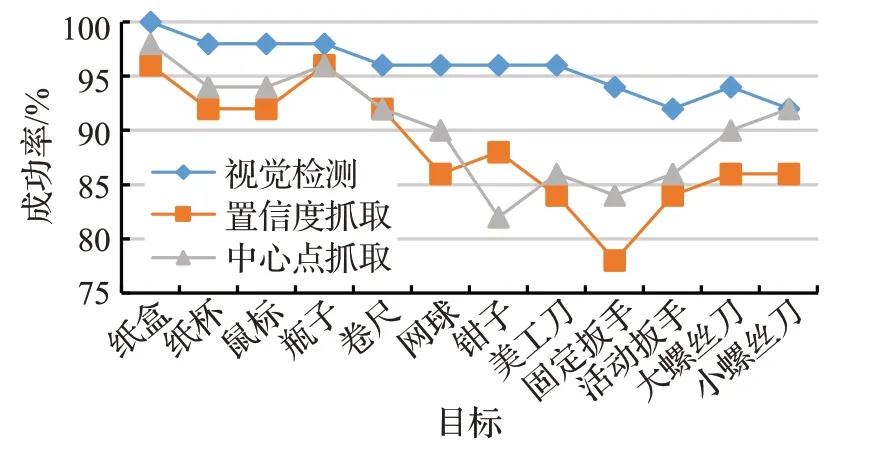
图10 物体检测-抓取成功率折线图Fig.10 Line graph of object detection-grasp success rate
5 结束语
本文针对机器人抓取成功率优化问题,提出一种融合多尺度特征的抓取位姿估计方法,以改善抓取目标多样性、位姿随机性对机器人抓取任务适应性的不利影响。实验结果表明,与当前主流算法相比,本文所提算法目标检测准确率有明显提升,在基于康奈尔抓取数据集开展的抓取位姿估计实验中,仿真抓取位姿估计准确度达到了96.9%;实物抓取实验中抓取目标检测成功率达95.8%,机器人抓取成功率为90.2%,抓取成功率得到明显改善。在接下来的工作中,将围绕如何提高检测准确率和抓取成功率继续展开具体研究。
猜你喜欢
智能制造(2022年4期)2022-08-18 16:21:14
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
摄影之友(影像视觉)(2018年1期)2018-03-22 01:12:04
摄影之友(影像视觉)(2017年11期)2017-11-27 02:39:53
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
中国照明(2016年6期)2016-06-15 20:30:14
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
