
基于拉马克进化的差分进化算法求解KPC问题
2022-05-19 13:28杨新花周昱帆沈爱玲钟一文
计算机工程与应用 2022年10期
杨新花,周昱帆,沈爱玲,林 娟,钟一文
1.福建农林大学 计算机与信息学院,福州 350002 2.智慧农林福建省高等学校重点实验室(福建农林大学),福州 350002
具有单连续变量的背包问题(knapsack problem with a single continuous variable,KPC)由Marchand和Wolsey于1999年提出[1],是标准0-1背包问题的扩展形式。因为KPC使用连续变量S来控制背包的实际容量,其求解难度比标准0-1背包问题更大。在KPC中,给定n个物品和一个基本容量为C的背包,其中第j个物品的价值和重量分别为p j和w j。背包的实际容量不是固定的,用一个连续变量S表示背包实际容量与基本容量C的差值,系数c代表惩罚率或者奖励率,当S>0时,即背包的实际容量增加S,此时背包内物品的总价值将减去c×S;反之,当S<0,背包的实际容量减少|S|,背包内物品的总价值将加上|c×S|。KPC的求解目标是通过确定S的值和选择物品,在不超过背包实际容量允许范围的情况下,使得装入背包内物品的总价值最大。KPC的基本数学模型定义如下:
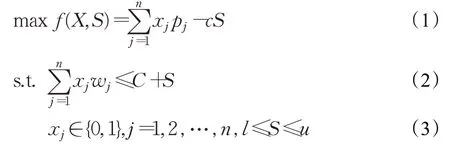
其中,X=[x1,x2,…,x n],x j=1表示第j个物品放入背包内,否则该物品不在背包内,u和l分别为S的上、下界。
目前求解KPC的方法主要有精确算法[2-3]、近似算法[5]和智能优化算法[5-7]等。Lin等[2]根据变量代换的方法将KPC转化为标准0-1背包问题和伪背包问题(pseudoknapsack problem,PKP),并调用新型的动态规划算法[8]求解标准0-1背包问题,采用新型的分支定界算法[9]求解PKP,提出了求解KPC的精确算法。由于算法中使用动态规划算法并需要对PKP进行可行性检查,导致算法实现繁琐且复杂性高。贺毅朝等[3]利用放缩法对KPC进行等价变换,基于动态规划算法提出了求解KPC的精确算法。Buther和Briskorn[10]将KPC的物品集划分为三个子集,并利用启发式策略并对变量的上下界变形,将KPC转化为标准0-1背包问题再进行求解,但是该方法只能求出KPC的近似结果。Zhao和Li[4]将单连续变量S的取值区间划分为两部分,把KPC拆分成两个具有标准0-1背包问题形式的子问题,提出了时间复杂度为O(n2)的2-近似算法。在智能优化算法方面,最早被用于求解KPC的是差分进化(differential evolution,DE)算法。贺毅朝等[5]利用降维法建立KPC的离散数学模型,提出了求解KPC的单种群离散演化算法(single-population binary DE with hybrid encoding,S-HBDE);另外,将单连续变量S的取值区间划分为两个子区间,将KPC划分为两个子问题,提出了求解KPC的双种群离散演化算法(bipopulation binary DE with hybrid encoding,B-HBDE)。He等[6]利用编码转换技术提出了基于编码变换的差分进化算法(encoding transformation-based DE,ETDE)求解KPC。王泽昆等[7]利用新型的S型转换函数将实数向量映射为KPC的解,提出一个新的二进制粒子群优化(new binary particle swarm optimization,NBPSO)算法求解KPC。精确算法求解KPC时间复杂性高,且实现较为繁琐;近似算法虽然算法简单,求解速度快,但是求解精度不够;已有的差分进化算法在低维实例上表现良好,但在高维实例上表现欠佳。NBPSO虽然在大部分实例上表现良好,但算法时间复杂性高。KPC是一个NP完全问题[5],不存在多项式时间精确算法,因此研究时间复杂性低且在高维实例上表现良好、稳定的智能优化算法是很有意义的。
本文针对KPC提出基于拉马克进化的差分进化算法(Lamarckian evolution-based DE,LEDE),将算法在修复优化操作中得到的改进遗传给后代,加快算法收敛速度,解决已有求解KPC的DE算法在高维实例上收敛速度慢而导致算法不稳定,收敛精度低的不足,利用变种群的策略避免算法收敛过快;同时设计基于价值引导的优化算子,提高求解精度,帮助算法跳出局部最优。实验表明LEDE算法在所有大规模KPC实例上表现良好且稳定,性能明显优于现有算法。
1 相关工作
1.1 DE算法
DE算法[11]是一种群体进化算法,标准的DE算法基于实数编码在连续空间内进行搜索。设定种群大小为N,优化问题的维数为D,迭代次数为MAX_G,则初始种群X={x1,x2,…,x N},其中x i表示问题的一个解,x i=[xi,1,xi,2,…,x i,D],DE算法的求解步骤如下:

(2)变异操作。种群内个体的合作产生新的变异个体v i,常用的变异策略包括以下五种:
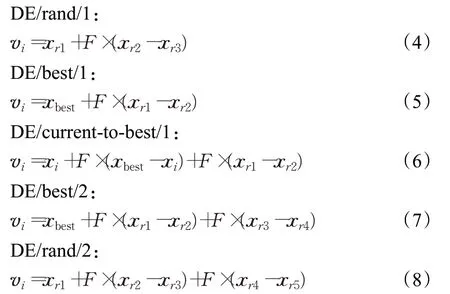
其中,F为缩放比例因子,r1、r2、r3、r4和r5为1到N之间的随机数,且r1≠r2≠r3≠r4≠r5≠i,xbest为种群中最好的个体。
(3)交叉操作。按照式(9)生成实验个体u i:
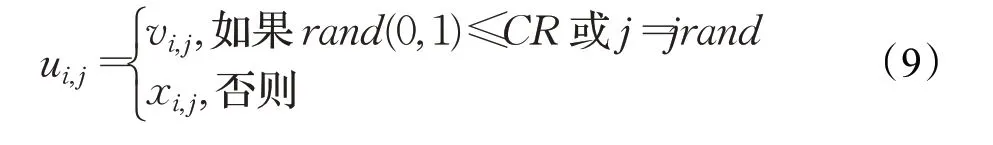
其中,CR∈[0,1]为交叉概率,jrand为[1,D]的随机整数。
(4)选择操作。个体x i和实验个体u i之间的竞争,通过贪婪法选择适应性更好的个体,对于一个最小化问题,选择策略如下:
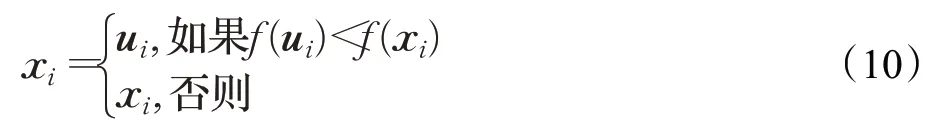
由于DE算法具有良好的性能,许多学者对DE算法的改进及其应用进行了深入的研究,主要的改进方向为控制参数、变异策略、种群设计等方面。在控制参数方面,Cui等[12]提出建立一个参数种群,将好的参数遗传到下一代,而差的参数不断向好参数学习更新。Leon等[13]提出一种新的参数联合自适应方法,将F和CR所有可能的取值进行配对,并利用一个矩阵存储选择一对F和CR的概率,通过更新概率矩阵实现自适应的参数选择。针对变异策略的改进,主要有将已有的变异策略进行混合以及设计新的变异策略。沈鑫等[14]提出一种双变异策略,该策略将DE/rand/1和DE/current-to-best/1结合起来,在进化早期,DE/rand/1的权重更大,而在进化后期,DE/current-to-best/1权重增大,加速算法收敛。Li等[15]建立变异策略协作机制,将不同的变异策略结合,平衡算法的全局勘探和局部开发。Lu等[16]提出对传统的DE/rand/1策略进行改进,使得变异个体能更接近种群目前所找到的全局最优解。Feng等[17]提出一种基于自适应群体智能的变异策略,可以有效避免算法陷入局部最优而过早收敛。在种群设计方面,Meng等[18]提出一种基于抛物线型的种群规模缩小策略。王浩等[19]将种群划分为多个子种群,并通过种群优劣因子评价子种群的优劣,子种群在迭代过程中自适应合并与分裂。Chen等[20]将种群分为精英种群和普通种群,并分别应用不同的变异策略。
1.2 求解KPC的DE算法
以文献[6]中的ETDE为例,KPC问题的解用一个n+1维的向量表示,其中前n个元素属于{0,1},表示物品是否放入背包内,第n+1个元素为实数,表示S。设种群大小为N,则初始种群X由N个实数向量表示的个体构成:

其中,每个个体x i含n+1个元素,前n个元素的值域为[-A,A],第n+1个元素的值域为[l,u],它们分别由式(12)和式(13)生成。
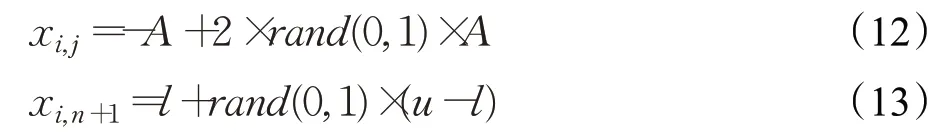
为了将个体x映射为解y,采用式(14)的映射方式,将前n个元素映射为0或者1,而第n+1个元素保留不变。

其中,i=1,2,…,N,j=1,2,…,n+1,A为一个正整数。
ETDE算法采用式(4)对个体进行变异,使用式(9)进行交叉,将变异、交叉后的个体通过式(14)映射为KPC的解,再用式(10)进行选择操作。同时由于S是带有约束的,变异操作可能会使得S越界,ETDE中对S越界采用式(13)的处理方法。
由于KPC是一个约束优化问题,采用启发式方式生成的解可能是不可行解,ETDE采用贪心修复优化算子(greedy repair and optimization algorithm,GROA)对解做进一步处理,以保证解的有效性和解的质量,其贪心策略都是基于价值密度的比较方法。令HD是n个物品的编号按照价值密度p i/wi由大到小排列的数组,其中HD[i]是价值密度第i大的物品的编号,GROA伪代码为算法1。算法第2~8行为贪心修复过程:对不可行解,从HD的尾部开始遍历,依次将背包内价值密度小的物品从背包中取出,直到满足式(2)约束条件,变成可行解;第9~15行为贪心优化过程:对可行解,从HD的头部开始遍历,在不违反式(2)的约束条件下,依次将价值密度大且不在背包内的物品放入背包中。
算法1GROA
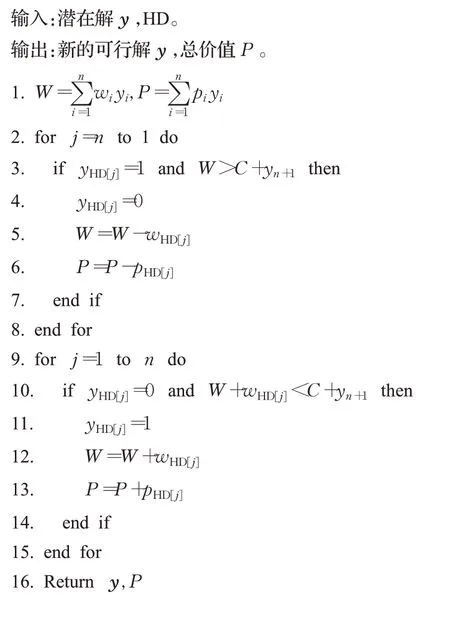
2 基于拉马克进化的DE算法
2.1 拉马克进化
拉马克进化的主要思想为“用进废退、后天获得性遗传”,个体由于环境的影响导致性状发生改变,这种改变会反馈回基因上遗传给后代。相对的,鲍德温效应认为个体性状改变后,仅会导致个体的适应性改变,并不会表达在基因上。拉马克进化被证明能加快算法的收敛速度[21-22],Bereta[23]在文化基因算法的局部搜索过程中应用拉马克进化、鲍德温效应及两者混合的策略,并对这三种策略进行分析。El-Mihoub等[24]在遗传算法中采用拉马克进化和鲍德温效应的混合策略。综上,可以把求解KPC的贪婪修复与优化算子看作是一种后天学习过程,通过该算子个体的性状发生了变化。现有求解KPC的智能优化算法中修复优化算子是基于鲍德温效应,修复优化操作仅使得个体的适应性改变,并没有编码到基因上。本文利用拉马克进化能够有效加快算法收敛速度的特点,设计基于拉马克进化的修复优化算子,帮助算法在高维数据上加快收敛。即在修复操作中当背包内的第j个物品被拿出来后,个体对应位的基因通过式(15)进行改变。式(15)中rand(μ,1)的值域是[μ,1],其中μ是一个大于0且足够小的正数,以保证x i,j不为0。同理,优化操作中当物品被放入背包内后,个体对应位的基因通过式(16)进行改变。

拉马克进化具有加快算法收敛的优点,但也存在急速降低种群多样性,算法收敛过快导致陷入局部最优的缺陷。针对此不足,本文提出变种群的策略,将算法的迭代过程分为三个时期,每个时期分配不同的种群大小。种群大小N满足式(17)。
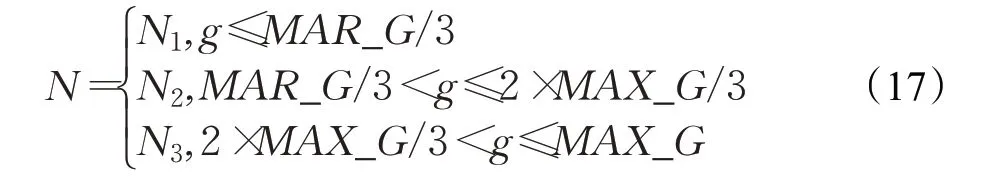
其中,N1>N2>N3,g为当前迭代次数,MAX_G为最大迭代次数。在进化早期种群数量最大,种群的多样性较好,能充分发挥算法的全局探索能力。在完成MAX_G/3次迭代后,为了增强算法的局部求精能力,使得资源更多地用在较优的个体,对个体按照适应值非升序排序,淘汰适应值较小的个体,仅保留前N2个个体。重复上述过程,直到种群大小缩减至N3。
2.2 改进的贪婪修复优化算子
在解的修复和优化过程中,基于价值密度的选择策略使得那些单位价值大的物品优先选入,有助于提高算法的搜索质量,但是修复和优化都基于单一的选择策略会使算法陷入局部最优。因此,提出改进的贪心修复优化算子(improved greedy repair and optimization algorithm,IGROA),在修复操作采用基于价值密度的引导策略,优化操作采用基于价值的引导策略,即优化过程中让价值大的物品优先被选择放入背包内,两种不同的引导策略互相补充。令HV是物品编号按照价值p i由大到小排列的数组,其中HV[i]是价值第i大的物品的编号,IGROA的伪代码为算法2。算法2与算法1的主要差异在于算法2使用拉马克进化加快算法收敛,同时采用基于价值引导优化策略帮助算法跳出局部最优。第5行和第14行实现拉马克进化。第11~18行实现价值引导的优化策略,从HV的头部开始遍历,在不违反式(2)的约束条件下,依次将价值大且不在背包内的物品放入背包中。IGROA的贪心修复和贪心优化过程的时间复杂性都为O(n),因此IGROA的时间复杂性为O(n)。
算法2IGROA

2.3 算法描述
LEDE算法首先采用映射方式生成初始种群的个体集X和解集Y,在DE框架下,进行变异、交叉及选择操作,采用拉马克进化及基于价值密度的选择准则对个体进行修复,并采用基于价值的选择策略进行优化,具体步骤如算法3所示。
第2行得到初始种群个体集X和解集Y,第3~5行调用IGROA对X和Y进行修复和优化,第9~15行生成实验个体Z和中间解V,其中iff函数包含3个参数,如果第1个参数为真,则函数值为第2个参数,否则函数值为第3个参数。第16行调用IGROA对实验个体Z和中间解V进行修复和优化,如果中间解比父代中对应个体的解好,则中间解为下一代种群中的解。
需要说明的是,ETDE算法针对S越界处理方法为式(13),而本文采用式(18)约束S,即当S越界时以边界值替换。同时,由式(12)可知个体集中x i的前n个元素的值域为[-A,A],为避免某个元素过大或者过小使得该元素在变异操作中起决定性作用,降低变异操作的效果,将x i在进化过程中也限制在[-A,A]。

在算法时间复杂性上,第1行为快速排序,时间复杂性为O(n×lbn),第2行的时间复杂性O(N×n),IGOA的时间复杂性为O(n),因此第3~5行的时间复杂性为O(N×n)。第6行的时间复杂性为O(N),第7~25行的时间复杂性为O(MAX_G×N×n),因此LEDE算法的时间复杂性为O(n×lbn)+O(N×n)+O(N×n)+O(N)+O(MAX_G×N×n)=O(MAX_G×N×n)。
算法3LEDE


3 实验设计和结果分析
3.1 实验数据与环境
本文将LEDE算法与NBPSO、S-HBDE、B-HBDE和ETDE算法进行对比,验证LEDE算法的优化效率。实验数据采用文献[6]中的4类KPC问题实例,每类包含10个物品数从100到1 000的实例:不相关KPC实例,标记为ukpc100~ukpc1000;弱相关KPC实例,标记为wkpc100~wkpc1000;强相关KPC实例,标记为skpc100~skpc1000;逆强相关KPC实例,标记为ikpc100~ikpc1000。表1列出了这40个测试实例的最优解(OPT)[3]。实验环境为Windows10 OS,Intel®CoreTMi5-5200U CPU@2.2 GHz,4 GB RAM,64位操作系统。
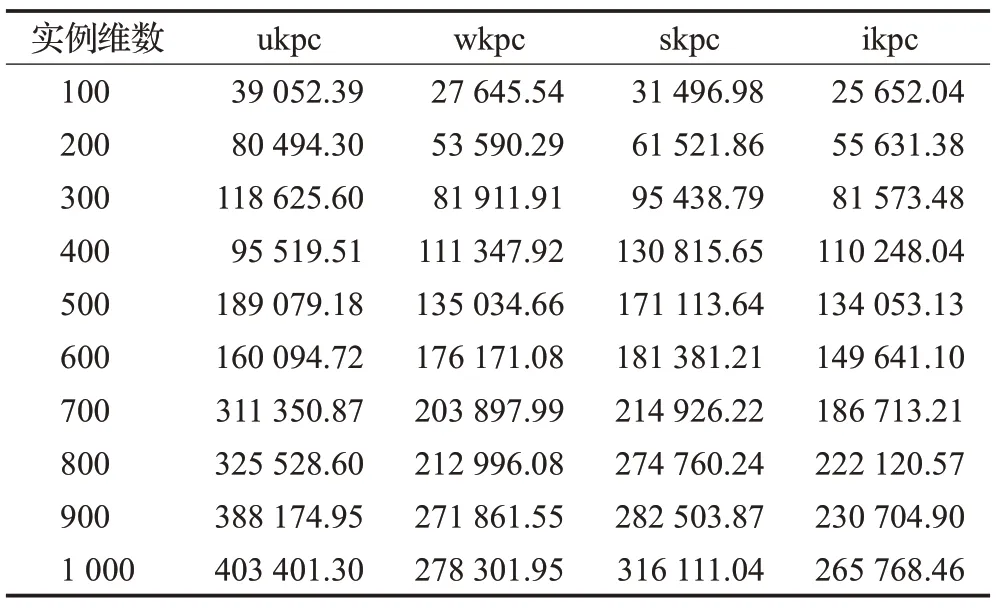
表1 4类实例的OPTTable 1 OPT of 4 classes of KPC instances
3.2 实验参数设置
LEDE算法的参数A使用ETDE算法建议的值。缩放比例因子F和交叉概率CR采用全因子实验来确定,实验中F的取值范围[0.3,0.8],CR的取值范围在[0.1,0.5],步长均为0.1,实验结果表明当F=0.3,CR=0.3时,LEDE算法的整体性能最好。算法迭代次数和种群大小保证LEDE和其他算法所生成解的数量相同。实验参数具体设置为:迭代次数MAX_G为3n,N1=90,N2=20,N3=10,实数A为3,F为0.3,CR为0.3。
3.3 实验结果分析
与ETDE算法相同,LEDE算法在每个测试用例上独立运行50次,记录获得的最好解Best、平均解Mean,并计算Best与OPT的差(EB)、Mean与OPT的差(EM),表2~表3列出LEDE算法的实验结果并与NBPSO、SHBDE、B-HBDE和ETDE算法进行比较,对5种算法在每个实例上进行排名,并计算其EB和EM均值及排名均值,“+/=/-”表示LEDE优于、等于、差于与之比较算法的实例个数。其中NBPSO、S-HBDE、B-HBDE和ETDE算法的数据来源于原文献,表中对5种算法中最好的EB和EM进行加粗显示。为了更清晰地展示算法之间的优劣,把100~1 000维的实例标记序号为1~10,将各算法的EM值绘制成图1~图4进行比较。
从表2可以看出,在40个实例中,LEDE的EB均值为0.01最小,排名均值为1.125最靠前,性能最佳。其次为S-HBDE,虽然NBPSO的EB均值小于B-HBDE,但是由于其在部分实例上较差,导致其排名低于B-HBDE,B-HBDE的EB均值最差,ETDE的排名均值最差。采用Wilcoxon符号秩检验(α=0.05)比较LEDE算法与其他4个算法的EB值,对于LEDE和NBPSO,计算得到的R+、R-和p值分别为778、2和6.43E-04;对于LEDE和S-HBDE,计算得到的R+、R-和p值分别为777、3和4.74E-03;对于LEDE和B-HBDE,计算得到的R+、R-和p值分别为777、3和1.20E-03;对于LEDE和ETDE,计算得到的R+、R-和p值分别为780、0和5.58E-06。这说明在获得最优解方面,LEDE明显优于其他4个算法。
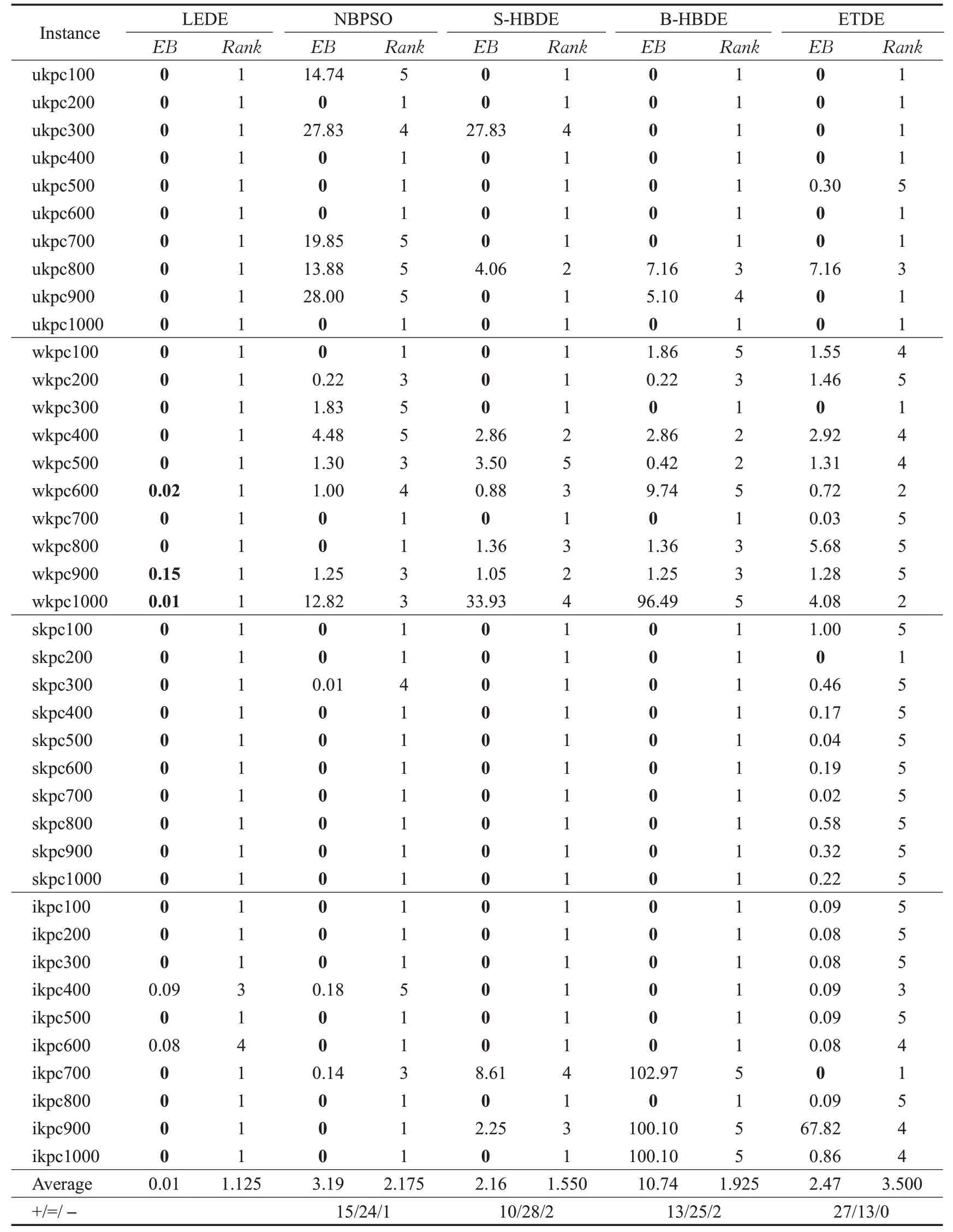
表2 LEDE、NBPSO、S-HBDE、B-HBDE和ETDE算法的EB性能比较Table 2 EB performance comparison of LEDE,NBPSO,S-HBDE,B-HBDE and ETDE algorithms
从表3可以看出,LEDE的EM均值为0.27最小,排名均值为1.45最靠前,NBPSO次之。采用Wilcoxon符号秩检验(α=0.05)比较LEDE算法与其他4个算法的EM值,对于LEDE和NBPSO,计算得到的R+、R-和p值分别为515、265和4.13E-01;对于LEDE和S-HBDE,计算得到的R+、R-和p值分别为720、60和4.12E-06;对于LEDE和B-HBDE,计算得到的R+、R-和p值分别为740、40和6.58E-07;对于LEDE和ETDE,计算得到的R+、R-和p值分别为774、6和5.63E-08。这说明在获得平均解方面,LEDE明显优于S-HBDE、B-HBDE和ETDE,略优于NBPSO,且LEDE的时间复杂性优于NBPSO的时间复杂性,由于NBPSO的修复和优化算子需要反复计算目标函数,导致其时间复杂性为O(MAX_G×N×n2),而LEDE时间复杂性为O(MAX_G×N×n)。
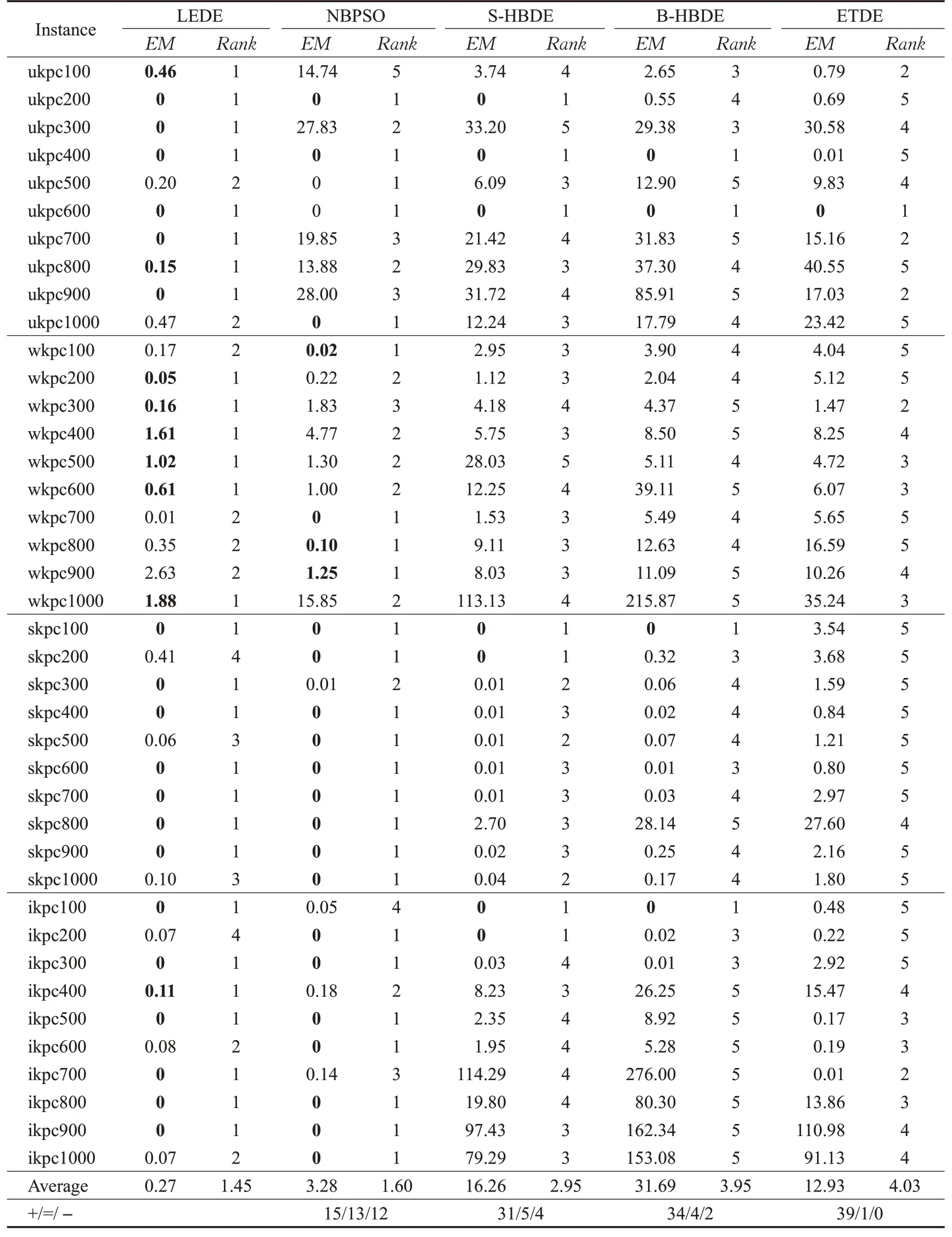
表3 LEDE、NBPSO、S-HBDE、B-HBDE和ETDE算法的EM性能比较Table 3 EM performance comparison of LEDE,NBPSO,S-HBDE,B-HBDE and ETDE algorithms
观察图1,LEDE在所有实例上表现良好,尤其是在高维数据上,LEDE更显优越性。而NBPSO在ukpc100、ukpc300、ukpc700-900都表现不好,S-HBDE、B-HBDE和ETDE只在ukpc100、ukpc200、ukpc400、ukpc600表现良好。
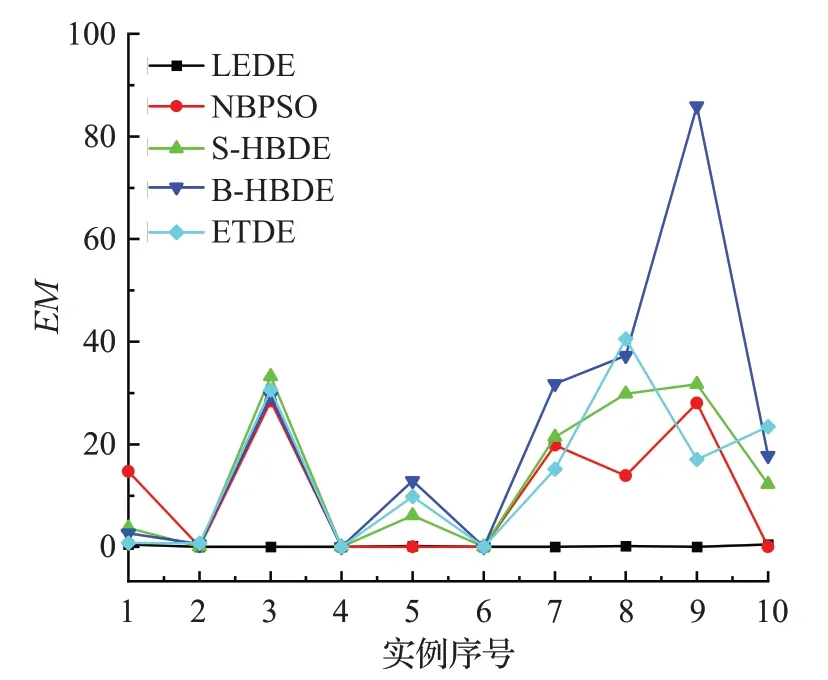
图1 实例ukpc100~ukpc1000上的EM曲线Fig.1 Curve of EM on ukpc100~ukpc1000 instances
观察图2,wkpc100~wkpc400前4个数据中5个算法差距不明显,从wkpc500开始,LEDE算法明显优于S-HBDE、B-HBDE和ETDE,且在wkpc1000数据中,另外4个算法效果很差,LEDE效果良好。
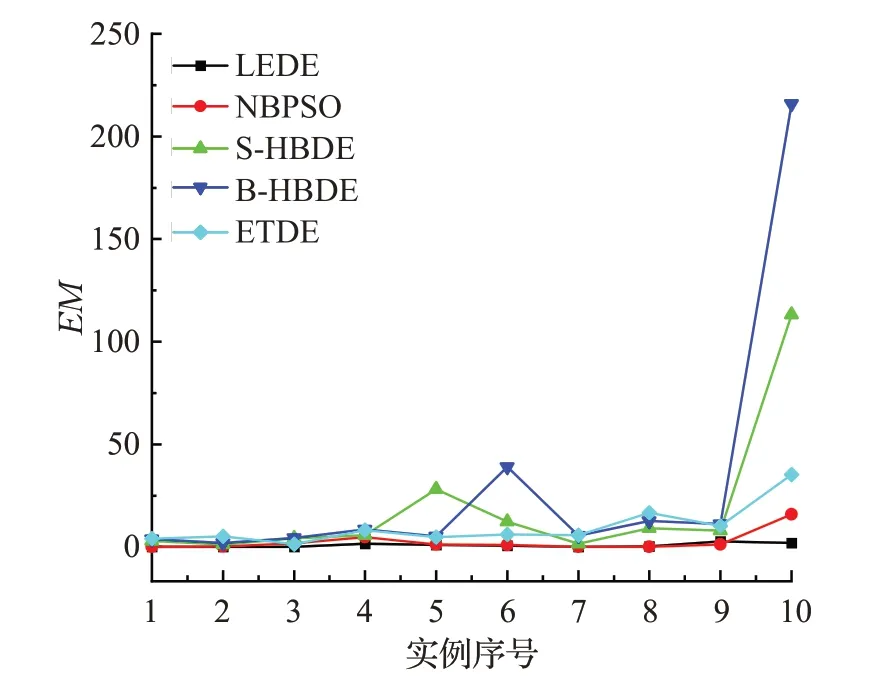
图2 实例wkpc100~wkpc1000上的EM曲线Fig.2 Curve of EM on wkpc100~wkpc1000 instances
观察图3,ETDE算法在这类数据上表现欠佳,LEDE、NBPSO、S-HBDE和B-HBDE在大部分实例上表现良好,其中在skpc800上LEDE和NBPSO明显优于其他3个算法。
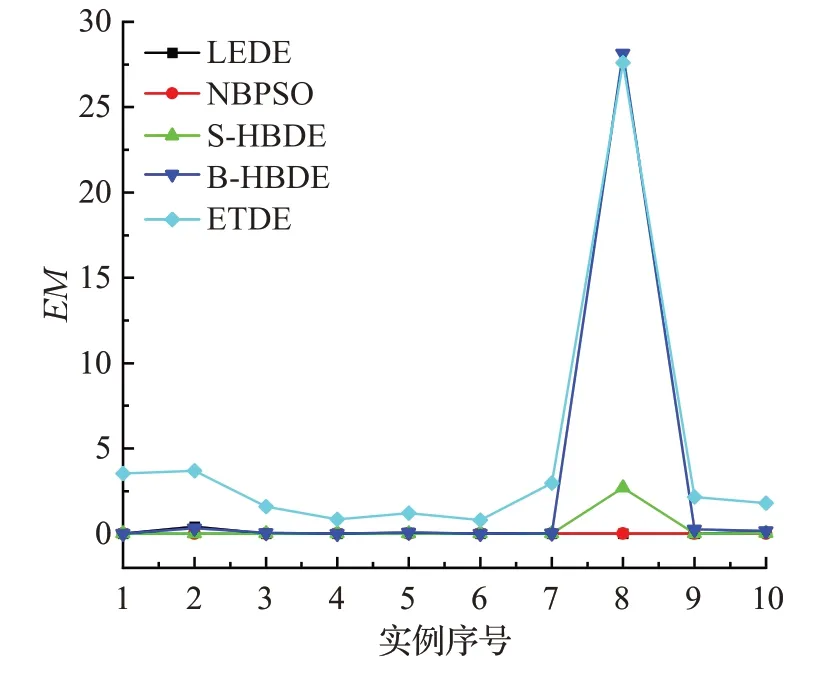
图3 实例skpc100~skpc1000上的EM曲线Fig.3 Curve of EM on skpc100~skpc1000 instances
观察图4,可以发现B-HBDE算法效果较差,且S-HBDE、B-HBDE、ETDE算法都存在随着实例的维度增大求解结果变差的情况,LEDE和NPBSO在所有的实例上都表现良好。
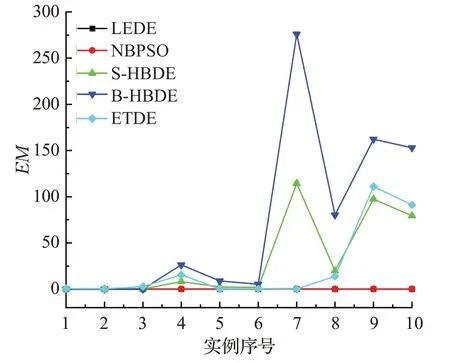
图4 实例ikpc100~ikpc1000上的EM曲线Fig.4 Curve of EM on ikpc100~ikpc1000 instances
4 算法行为分析
4.1 基于价值引导优化分析
为了分析在贪婪修复优化算子中使用价值引导优化策略的效果,在第3章使用的4类40个实例上进行基于价值密度和基于价值引导优化的比较实验,Mean p和Mean p/w分别为价值引导优化和价值密度引导优化运行50次的均值。记ER=Mean p-Mean p/w,40个实例上的ER值如表4所示,正数表示价值引导优于价值密度引导,表中对价值引导不差于价值密度引导的E R值加粗显示。
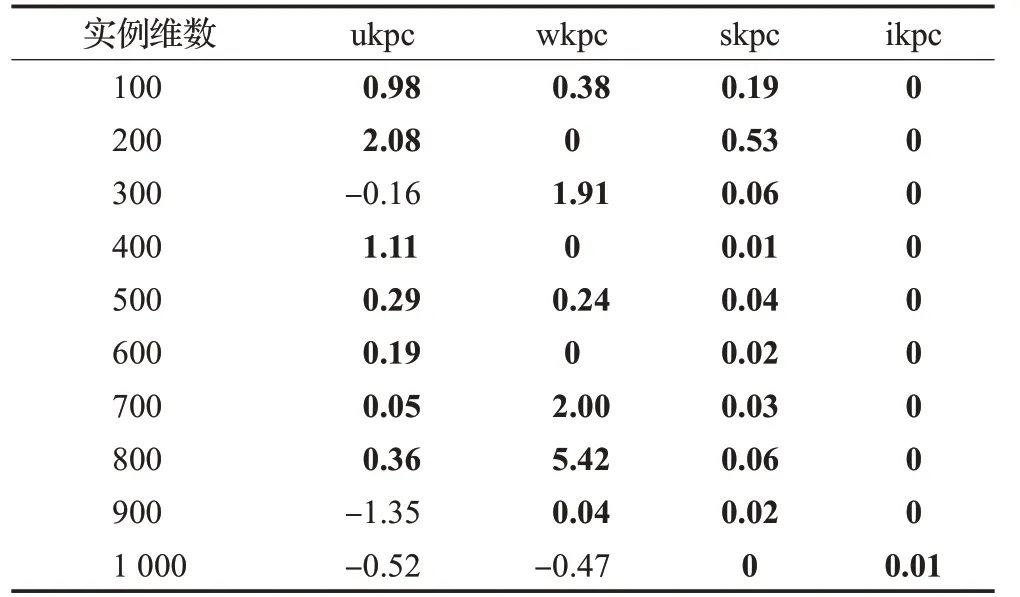
表4 4类KPC实例的ER值Table 4 ER values of 4 classes of KPC instances
观察表4可以看出,价值引导优化在36个实例上不差于价值密度引导优化,其中23个实例更好,13个实例相等。为更准确地比较这两种引导策略,依据文献[2,8]给出的KPC实例生成方法,对4类100维~1 000维问题,每种类型每个维度的数据分别生成10个实例,即4×10×10个实例。每个实例运行50次取均值Mean,统计每类实例中价值引导优化优于(记为p>p/w)、相等(记为p=p/w)、差于(记为p<p/w)价值密度引导优化的个数。采用Wilcoxon符号秩检验比较两种策略是否存在显著性差异,统计结果如表5所示。通过表5可以看出价值引导的策略能够在ukpc、wkpc和skpc上明显提高算法的性能,在ikpc类实例上两种策略无明显差异,因为对ikpc类问题,任意两个物品之间价值相对大小关系和价值密度相对大小关系完全相同,所以在ikpc类问题上两种策略实际没有区别。

表5 基于价值引导和基于价值密度引导优化的性能比较Table 5 Performance comparison between profit guided and profit weight ratio guided optimization
4.2 拉马克进化及收敛性分析
为了分析拉马克进化的效果及LEDE算法的收敛性,将LEDE算法和基于鲍德温效应的DE算法在ukpc800、wkpc800、skpc800和ikpc800上进行比较,算法参数均保持一致。将种群中解的平均值作为适应值,观察两种算法的收敛速度及收敛精度。
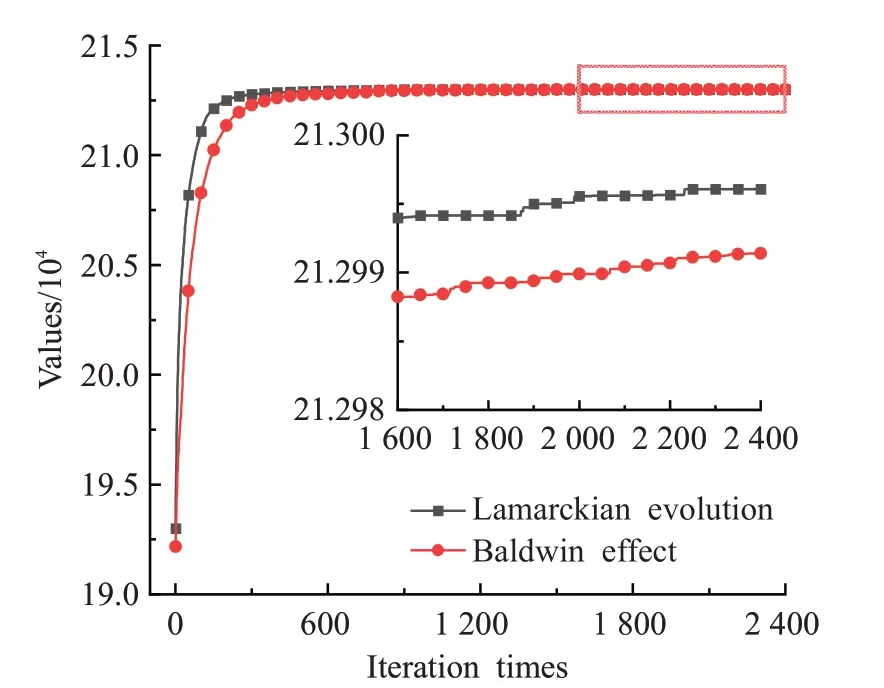
图6 wkpc800上拉马克进化和鲍德温效应的收敛曲线图Fig.6 Convergence curve of Lamarckian evolution and Baldwin effect on wkpc800
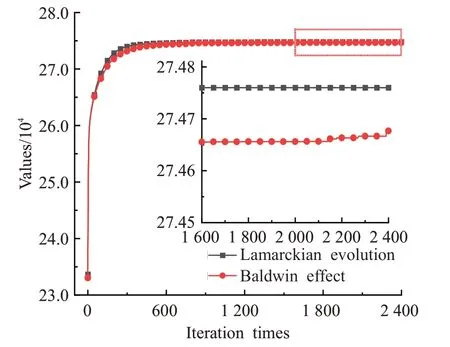
图7 skpc800上拉马克进化和鲍德温效应的收敛曲线图Fig.7 Convergence curve of Lamarckian evolution and Baldwin effect on skpc800
观察图5~图8可以看出,拉马克进化比鲍德温效应收敛速度更快,收敛精度更高。在ukpc800、wkpc800和skpc800上收敛精度明显高于鲍德温效应,ikpc800上两种算法虽然在求解精度上差异不大,但是拉马克进化在进化早期收敛速度比鲍德温效应快。
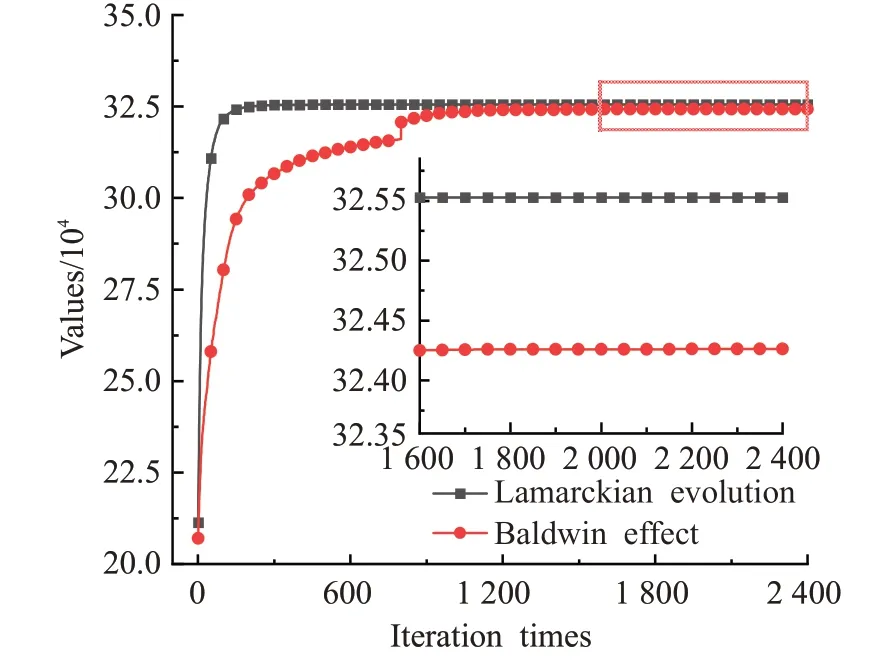
图5 ukpc800上拉马克进化和鲍德温效应的收敛曲线图Fig.5 Convergence curve of Lamarckian evolution and Baldwin effect on ukpc800
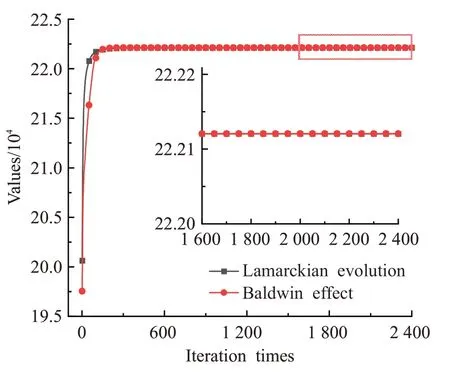
图8 ikpc800上拉马克进化和鲍德温效应的收敛曲线图Fig.8 Convergence curve of Lamarckian evolution and Baldwin effect on ikpc800
5 结束语
本文对求解KPC的DE算法进行了研究,把贪婪修复优化算子看作一种后天学习过程,将拉马克进化的思想引入到DE算法中,提出了基于拉马克进化的DE算法,以加快算法的收敛速度,提高算法的求解精度和稳定性。同时将价值引导的优化策略引入到贪婪修复优化算子,进一步提高了算法的全局寻优能力,使用变种群大小的策略保证算法在前期有足够的勘探能力。实验分析表明采用的拉马克进化策略和价值引导的优化策略是有效的,提出的LEDE算法性能明显优于现有基于DE的算法,在获取最优解方面性能显著优于NBPSO算法,在获取平均解方面也略优于NBPSO算法,且LEDE算法的时间复杂性优于NBPSO算法。本文提出的优化策略对求解KPC的智能优化算法具有通用性,下一步计划将拉马克进化策略和价值引导的优化策略引入到其他智能优化算法中,研究这些算法在KPC中的应用。
猜你喜欢
今日农业(2022年15期)2022-09-20
湖南电力(2021年1期)2021-04-13
农民文摘(2019年11期)2019-11-15
红土地(2018年7期)2018-09-26
摄影之友(影像视觉)(2017年10期)2017-11-07
作文周刊·小学一年级版(2016年42期)2017-06-06
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中学生物学(2008年6期)2008-08-29
