
基于ResNet和迁移学习的古印章文本识别
2022-05-19 13:28陈娅娅刘全香王凯丽易尧华
计算机工程与应用 2022年10期
陈娅娅,刘全香,王凯丽,易尧华
武汉大学 印刷与包装系,武汉 430079
文本识别领域中,现代文本识别技术已经趋于成熟,在诸多方面取得了商业化应用,如扫描文档的智能识别[1]、手写文本的数字化转换[2]与场景文本的自动翻译[3]等。古文本识别研究中,数量较为丰富的书法[4]、印刷古籍等的识别研究[5]相对较多,由于识别困难和数据有限,较少有人涉及古印章文本的识别。
作为中华文化的重要组成部分,印章在古籍书画中广泛存在,承载着大量史实和人文信息。古印章文本的自动识别可以实现古籍中印章的辅助阅读和数字化转换,对历史文化的传承具有重要意义。古印章文本的主要识别难点如下:(1)结构复杂,字符集大且类间相似度高。(2)类内差异大。如图1(a)所示,同类字符在结构上相差很大。(3)图像退化和边框影响。如图1(b)所示,模糊、粘连、随机噪声和不规则边框等会影响准确的特征提取。此外,部分训练样本不足且类间分布不均衡,会降低深度学习算法的性能。

图1 古印章图像样本Fig.1 Historical Chinese seal samples
古印章文本识别相关研究中,Sun等人[6]提出一种基于图模型匹配的印章文本识别方法,通过提取印章的骨架特征并计算最相似矩阵,在59个类别上实现分类。该方法使用手工设计图像特征的传统机器学习实现,分类数量较少且识别准确率不高,限制了古印章文本识别的推广应用。在古印章前处理方面,Dai等人[7]通过提取印章图像的边界宽度特征和结构特征去除边框干扰并建立决策树分类模型,将古印章分为阴刻和阳刻两类,但没有进行单字符分割的工作。Wang等人[8]将深度学习应用到古印章的图像识别中,建立了古印章图像数据库,并提出基于多任务学习和自动背景生成的印章图识别方法。该方法将整张图而不是印章中的字符作为识别对象,未考虑古印章中所蕴含的具有意义的文本信息。
近年来,很多优秀的卷积神经网络(convolutional neural network,CNN)在多分类任务中取得了良好效果[9],AlexNet[10]、VGGNet[11]、Inception[12]、ResNet[13]等网络被广泛应用于基于分割的文本识别任务中。例如,Zhong等人[14]利用多融合池化(multi-pooling)的CNN网络识别多字体的印刷汉字,并结合数据增强技术提升了CNN的性能。Wang等人[15]结合Inception_v4等多种CNN网络,提出基于多模型融合的方法并应用于多场景古汉字的识别任务中。深度学习方法需要大量有效样本,迁移学习的引入可以提高学习的性能,缓解数据不足问题[16]。例如,姚可欣等人[17]在手写简笔画识别中,利用迁移学习解决样本数据量小的问题,有效提高了识别精度。
本文针对古印章文本标注数据不足等问题,提出使用深度残差网络并引入迁移学习实现古印章文本的识别。主要工作如下:
(1)自建古印章文本识别数据集,通过基于投影和统计的前处理方法分割出字符区域,选用ResNet作为基础识别网络,并对比不同网络下的识别结果,验证了本文所用网络的优越性。
(2)通过预训练人工合成样本,引入迁移学习进行目标域的训练,从而建立文本识别分类模型,同时利用数据增强和标签平滑进一步优化模型。实验结果表明,引入迁移学习可以有效提升古印章文本的识别准确率。
1 数据集简介和前处理
1.1 数据集简介
古印章文本识别数据集(historical Chinese seal text recognition,HCSTR)通过网络爬虫获取,共包括印章拓本图像27 520幅,覆盖了从夏商至近现代的各个历史时期。印文以姓名、字号、鉴藏、斋馆名等为主,包含2 602个字符类别,其中收录于GB2312字符集的字符占约95%。数据集中的字体主要有大篆、小篆、方篆、九叠篆、鸟虫篆5类,还包括隶书、楷书、行草书等书体以及部分装饰性文字,如图2所示,不同字体间结构相差较大。

图2 HCSTR数据集中的字体分类Fig.2 Font classification of HCSTR dataset
1.2 数据集前处理
为了准确提取古印章的字符特征,本文通过数据集前处理分割出单字符样本。如图3所示,前处理包括去边框和字符分割两部分。先根据图像像素投影特点将图像分成阴刻和阳刻,利用边缘结构特征去除边框区域,然后通过垂直投影轮廓确定两个相邻字符之间的分割点实现单字符分割。
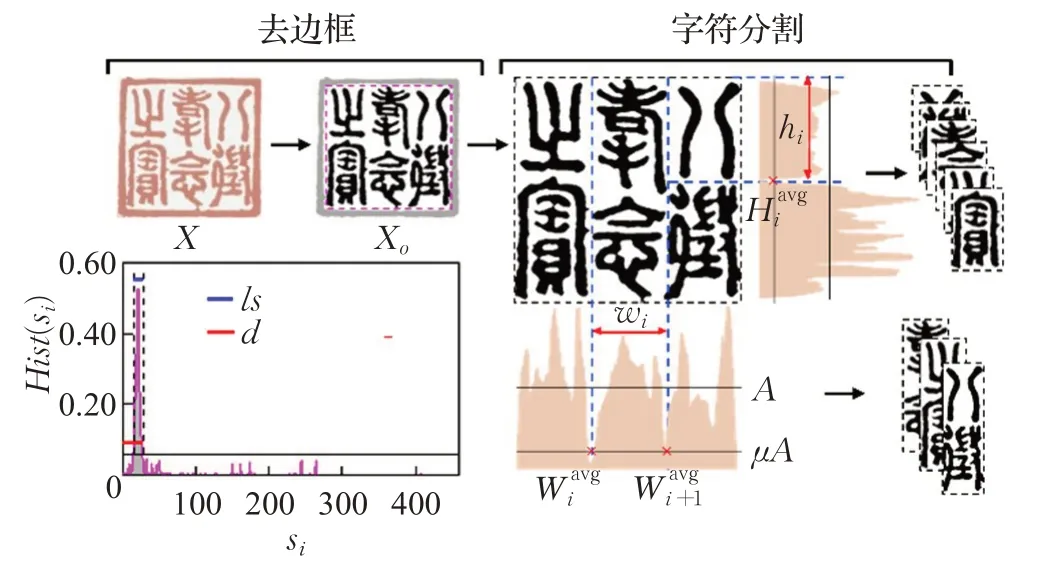
图3 印章图像前处理阶段Fig.3 Preprocessing phase of seal images
1.2.1 去边框
采用最大类间方差法[18]和开运算进行二值化及去噪处理,处理后的图像记为Xo。参考文献[7]中的方法,遍历Xo每行每列并计算所在列或行第一个和最后一个黑色像素线段长度s i,则s i的平均概率密度为:
式中,r为s i的数量,Hist(·)表示直方图操作,S为s i的集合。判断为阴刻印章的条件为:
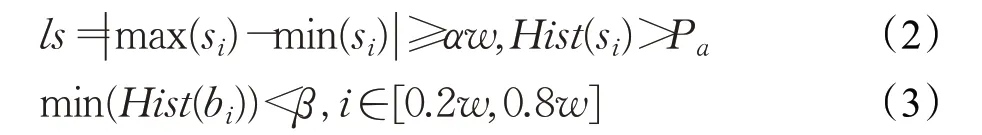
其中,ls表示边框跨度,b i为Xo每列的亮度值,w为图像宽度。本文中α=0.25,β=0.2,为自定义参数。最佳边框宽度定义为当边框概率分布在50%以上的最大宽度,作为最终需去除的边框宽度:

1.2.2 字符分割
对于阳刻印章,设去边框后每个像素位置(x,y)对应的像素值为f(x,y),当图像为白色像素时,f(x,y)=0,否则f(x,y)=1。设H、W分别为去边框后的高度和宽度,其垂直投影函数可以表示为:

垂直和水平像素投影如图5所示,其中垂直投影各部分由式(6)~(8)给出:
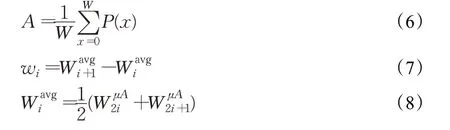
其中,A为平均投影密度,wi为第i列位置字符的宽度值,投影图与μA交叉点处的平均值定义为Wiavg,μ取0.2。行分割采取同样的投影方式,鉴于字符位置的不确定性,对此进行人工干预,设每列字符数为j,公式如下:

2 基于ResNet和迁移学习的文本识别
本文提出基于ResNet和迁移学习的古印章文本识别方法,识别流程如图4所示。
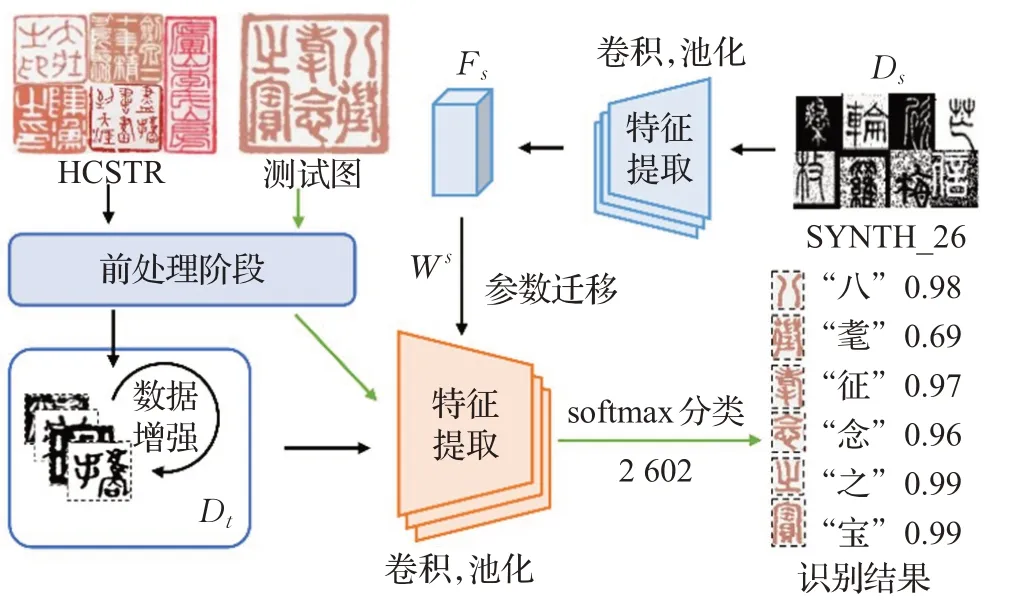
图4 古印章文本识别流程Fig.4 Text recognition process of seal images
2.1 基于ResNet的特征提取网络
传统CNN网络在层数加深时,面临网络退化的问题,本文选用ResNet作为预训练和微调模型的特征提取网络,该网络增加层数的方式是在浅层网络上叠加恒等映射层,从而构建出残差学习单元。残差单元结构如图5所示,通过学习残差,将部分原始输入的信息经过恒等映射层直接输到下一层,在一定程度上避免了卷积层在进行信息传递时的特征丢失,可以在输入特征的基础上学习到新的特征,拥有更好的性能。
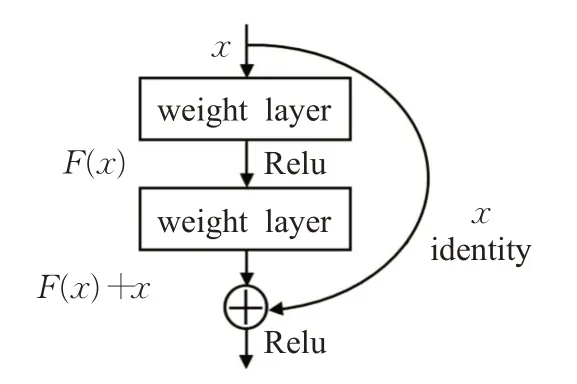
图5 残差单元结构Fig.5 Residual unit structure
设输入为x时所学特征为H(x),F(x)=H(x)-x为网络学习残差,则残差单元可以表示为:

其中,x l、y l表示第l层的输入和输出,W l为权重矩阵,f(·)表示Relu激活函数。对于L层残差单元,从浅层到深层的学习特征为:


表1 ResNet_152结构设置Table 1 Architecture of ResNet_152
2.2 引入迁移学习的模型训练
为了充分利用有效的数据资源,缓解古印章部分字符对应样本不足问题,本文在训练过程中引入迁移学习。
使用人工合成样本作为源域D s,数据增强后的训练集为目标域Dt,源域和目标域样本遵循相同的标签分布。来自D s的数据经过预训练模型并保存参数,记权重参数矩阵为W s,使用W s对目标网络的参数进行初始化,用目标域数据重新训练整个网络,通过微调得到新的模型,预训练和微调模型可以表示为:
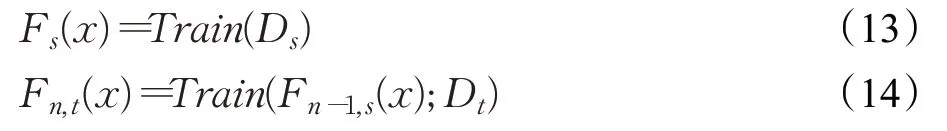
其中,n表示训练次数,Train(·)表示模型训练过程。训练过程中将损失值进行反向传播从而进行参数更新,权重参数可以很快适应目标域的数据,从而加快微调模型性能提高的速度。
2.3 分类预测与损失函数

式中,c为预测标签,N为批处理大小。由于标注错误的样本会抑制识别准确率的提升,本文引入标签平滑策略来避免标签错误产生的影响。设r(x i)为样本xi的逻辑表达式,当预测标签正确时r(xi)=1,标签错误时r(x i)=0。采用标签平滑后的损失函数表示如下:
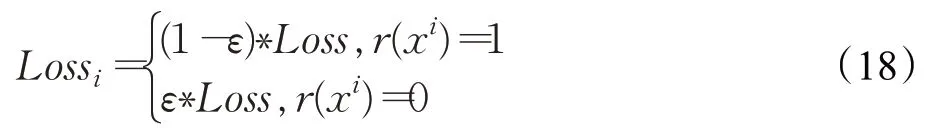
式中,标签平滑参数ε=0.1,该损失函数通过为标签加入噪声,减少真实样本在损失计算时的权重来提升整体性能。
2.4 算法时间复杂度分析
通常以浮点运算次数(floating point operations,FLOPs)来表示算法的时间复杂度。预训练模型的时间成本体现在特征提取和分类上,主要为通过卷积层和全连接层的时间,其他附加层可以忽略不计。通过单个卷积层的通过全连接层的FLOPs=O(2I-1)[20]。其中Ml为特征图的边长,Kl为卷积核窗口边长,Cin和Cout分别表示该层输入通道数和输出通道个数,I代表全连接层输入维度,O代表输出维度。以O(·)代表时间复杂度函数,则单层卷积的时间复杂度为全连接层的时间复杂度为O(IO)。总时间复杂度可以表示为
引入迁移学习后的微调模型在不改变网络结构和初始参数的基础上,对整个网络进行了微调。因此,微调模型的时间复杂度与预训练模型复杂度相比,减少了参数初始化的时间消耗,整体的时间复杂度数量级与预训练模型相当。
对于教师而言,要和学生打成一片、亲密无间,要了解他们的喜怒哀乐,观察学生的能力差异,弄清每个学生的个性特长,这是优秀教师的重要标志。
3 实验
3.1 数据集
本文实验中使用到的数据集分布如表2所示,其中“HCSTR+DA”表示HCSTR中的训练集和数据增强之后的总样本数据,即目标域数据。目标域数据通过对训练集添加椒盐噪声、高斯模糊和随机裁剪进行数据增强得到。
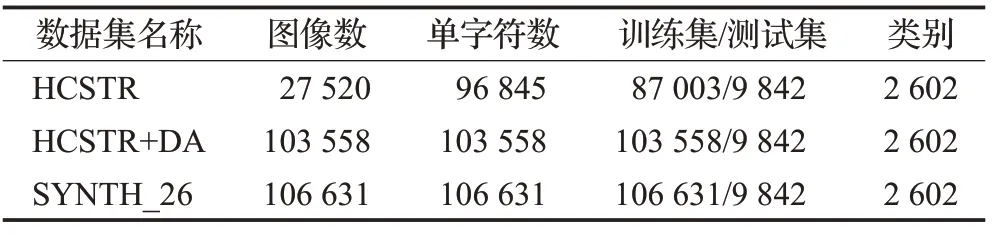
表2 本文使用的数据集Table 2 Datasets used in this paper
本文提出了基于人工设计规则的单字符数据集(SYNTH_26)作为预训练样本,具体合成方法如下:
(1)选择与印章文本相近的字体文件获取古汉字图像,本文共筛选出26种字体文件合成所需字符,像素大小设为80×80。
(2)随机添加颜色反转模拟阴刻和阳刻。对样本进行边缘随机裁剪模拟字符位置的变化,裁剪大小控制在10像素以内。
(3)通过控制参数添加椒盐噪声,随机执行膨胀或腐蚀变换,模拟不同程度的结构残缺和笔画粗细。
3.2 评价指标
本文采用字识别准确率作为模型测试的评价标准,字识别准确率反映了所有识别正确的样本数占总测试样本数的百分比,具体公式如下:
其中,M为所有测试集样本数量,Y i代表测试样本n i∈{n1,n2,…,n k}的预测标签集合,G i代表ni的真值标签集合。
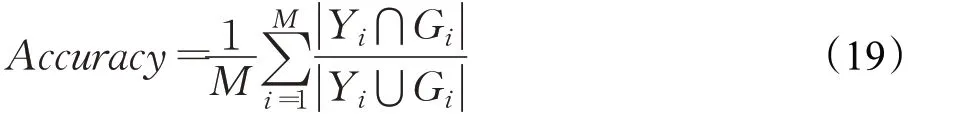
3.3 实验环境及参数设置
本文实验的运行环境均为Ubuntu 16.04,运行内存为8 GB,GPU设备为GTX1080ti,并在TensorFlow框架[21]上进行训练与测试。选择RMSProp作为预训练和微调网络的优化函数,动量(momentum)设为0.9,初始与终止学习率(learning rate)分别为10-2和10-4,衰减因子为0.94,指数衰减步数为4×105,网络训练的迭代次数为10万,批尺寸(batch size)大小均设置为64。
实验中SYNTH_26作为源域全部用于预训练,在ResNet_v2_152网络上迭代10万次得到预训练模型。使用HCSTR+DA作为目标域参与微调训练。模型测试过程全部使用测试集样本。
4 实验结果与分析
4.1 识别结果对比
为了评估不同网络的识别性能,在相同训练和测试条件下,将本文网络与其他较为流行的CNN网络识别结果进行对比,结果如表3所示。可以看出,相比其他网络,ResNet_v2_152网络的Top-1、Top-3和Top-5的识别准确率均取得了最优的结果。AlexNet_v2由于提取不到深层特征,准确率最低。Inception_v4和Inception_ResNet_v2网络下的Top-1准确率介于ResNet_v2_50和ResNet_v2_101网络之间。
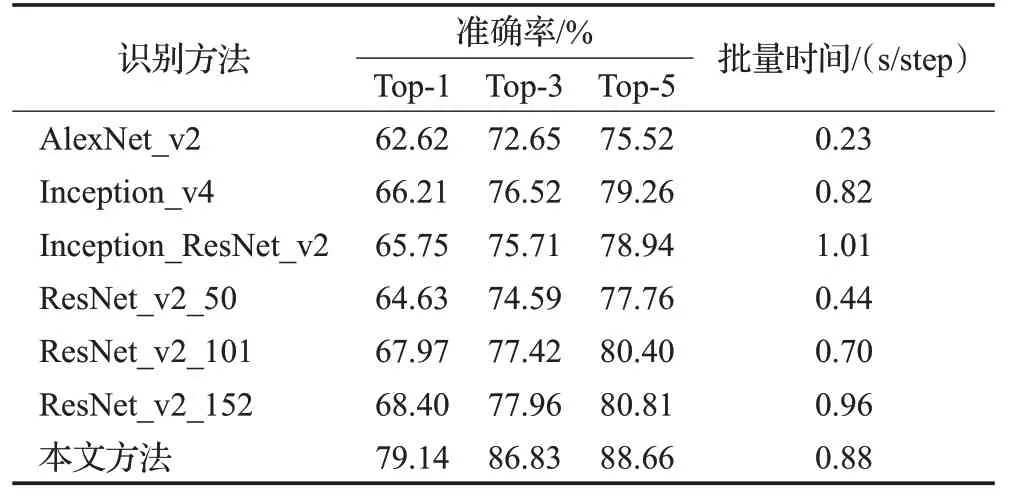
表3 识别结果对比Table 3 Comparison of recognition results
表3中批量时间指模型迭代一个批尺寸所用的时间。从批量时间对比可以看出,AlexNet_v2网络的时间复杂度最低,Inception_ResNet_v2由于结合了两种网络结构,时间复杂度最高。ResNet_v2_152网络直接进行训练所需的时间成本相比较高,但可以取得优于其他网络的效果。本文方法的批量时间指引入迁移学习后的微调模型的批处理时长,预训练的时间成本不计入在内。微调模型的批处理时长相比引入迁移学习前有所降低,并且在相同的迭代步数下,本文方法可以使损失值下降更快。因此,在已有预训练模型的情况下,引入迁移学习有利于提前终止训练,降低了时间成本,可以有效提升训练的效率。
4.2 迁移学习有效性分析
为了证明迁移学习的有效性,分析标签平滑、数据增强策略对结果的影响,本文在ResNet_v2_152网络上进行了消融实验,结果如表4所示。三种策略均对准确率提升有所帮助,只使用标签平滑时结果提升1.10个百分点,只使用数据增强的结果提升了5.53个百分点,人工合成样本与真实样本具有相似的结构特征,引入迁移学习有效提升了识别准确率,相比引入迁移学习前提升了9.94个百分点。两两融合的对比实验中,迁移学习和标签平滑结合的结果可以有效提升准确率。本文方法,即三种策略融合的实验中,相比引入迁移学习前的Top-1准确率提升了10.74个百分点,相比只使用标签平滑和数据增强的结果提升了4.63个百分点,其他Top-2到Top-5的结果提升了0.51个百分点~3.96个百分点,充分证明了本文有效地学习到了可以进行知识迁移的信息。
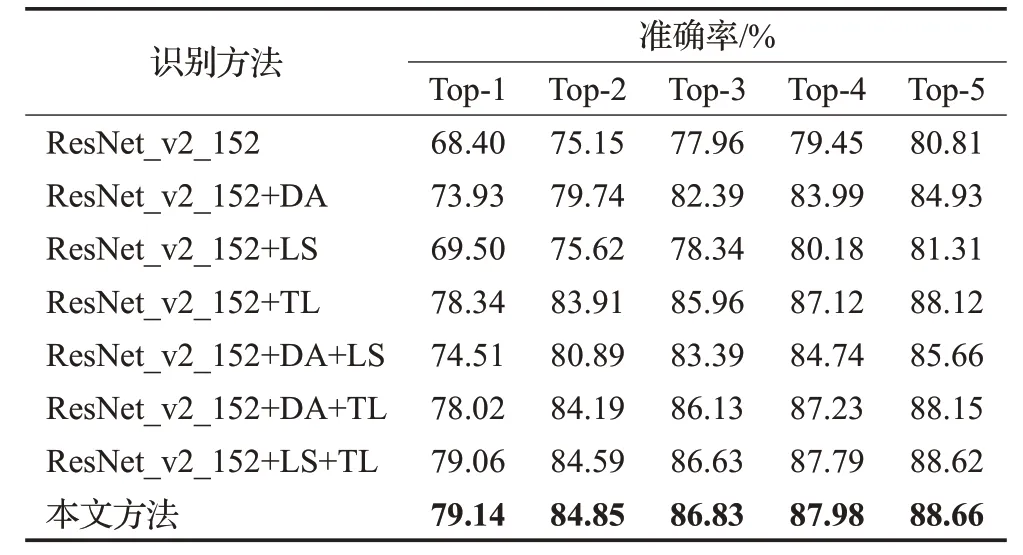
表4 消融实验结果Table 4 Ablation experiment results
4.3 识别置信度分析
本文还分别对引入迁移学习前后样本的识别置信度分布做出分析,结果分别如图6(a)和图6(b)所示。图中的散点代表样本,曲线表示具有不同置信度的样本量。可以看出,Top-1样本的置信度相对较高,相比引入迁移学习前的结果,基于ResNet和迁移学习的方法的置信度有所提高,其中Top-1的置信度更接近于1.0,说明本文在一定程度上提升了模型的鲁棒性,也反映出置信度高的样本一般具有较高的识别准确率。
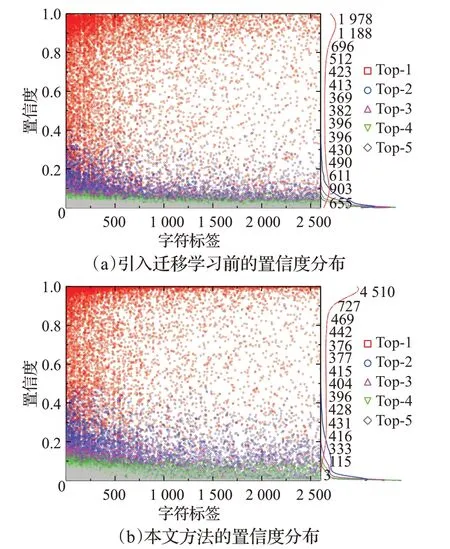
图6 测试集样本置信度分布Fig.6 Confidence distribution of test set samples
部分识别错误样本及其置信度如图7所示,图中文字部分分别为“真值标签-识别结果(置信度)”,每一行代表一种错误类型。(1)低分辨率、严重模糊或残缺的样本。此类样本无法有效提取到有效特征,一般置信度较低,如“长-良(0.21)”“字-丹(0.20)”。(2)具有不规则边框的样本。难以去除的不规则边框会影响特征的准确提取,造成分类错误,如“岩-乐(0.28)”“峡-悔(0.18)”。(3)字符分割有误的样本。印章存在字符之间和字符内部间隙一致的情况,不可避免地会产生欠分割或者过分割,提取到错误的文本特征,如“十-春(0.30)”。(4)结构相似的样本。部分样本的结构相似,如“闭-开(0.78)”“处-代(0.65)”等,容易造成分类错误。因此,需要更灵活的前处理和更具鲁棒性的识别方法来提升这些错误样本的准确率。

图7 错误识别结果图Fig.7 Wrong recognition results
部分识别正确的单字符样本及其置信度如图8所示,可以看出,细边框对特征提取影响较小,如“嘉(0.78)”“奴(0.62)”,具有少量噪声的样本依然可以正确识别,具有较高的置信度,如“从(0.77)”“宁(0.88)”。以上结果表明,本文在一定程度上实现了古印章文本的识别,样本具有笔画清晰、结构相对完整的特点,也说明本文在前处理和特征提取方面还具有一定的局限性。

图8 正确识别结果图Fig.8 Correct recognition results
5 结束语
本文提出基于ResNet和迁移学习的古印章文本识别方法。该方法首先自建数据集并完成前处理,其次使用人工合成样本在ResNet_v2_152网络上获取预训练参数,最后利用可迁移参数学习目标域特征,将源域知识迁移到目标域,从而提升识别准确率和模型泛化性能。下一步的工作中,考虑改进数据扩充方法,利用置信度决策函数实现更具有鲁棒性的模型性能,在此基础上,实现古印章文本端到端的数字化识别。
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
计算机应用(2018年5期)2018-07-25
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
