
面向拥挤行人检测的CA-YOLOv5
2022-05-15 06:35:42陈一潇阿里甫库尔班林文龙
计算机工程与应用 2022年9期
陈一潇,阿里甫·库尔班,林文龙,袁 旭
新疆大学 软件学院,乌鲁木齐830046
随着我国在经济、教育、医疗等领域的不断发展,以及城镇化进程的加速,我国总人口达到了14.117 8 亿人,其中城镇人口为9.019 9 亿人,相较于2010 年,城镇人口增加了2.364 2 亿人,城镇人口密集程度急剧上升[1]。而高拥挤人群极易发生各种意外事故,这对于城市公共安全、城市人流量监控提出了巨大挑战。因此,提出一种漏检率低的、高精度的、可用于拥挤人群场景的行人目标检测算法具有重要意义。
行人检测通常由于场景复杂、目标众多、大部分目标互相遮挡,以及摄像头距离目标较远等问题具有挑战性,使得国内外学者对其进行深入研究。文献[2]提出利用Gabor 特征结合快速HOG 特征的方法训练分类器对行人进行识别。文献[3]根据行人非刚性的特点,通过三线性插值法获取图像的梯度方向直方图特征,而后使用支持向量机(support vector machine,SVM)对行人进行识别。Tang 等[4]通过可形变部件模型(deformable part model,DPM)设计行人检测器,检测粘连情况严重的行人。但传统的图像处理算法泛化能力差,手工设计的特征对于环境变化鲁棒性差。
目前,基于深度学习的目标检测根据检测的方式可以分为两类,一类是基于Region Proposal的two-stage的目标检测算法,首先根据算法生成目标预选框,即可能包含检测目标的区域,再通过CNN 网络层对这块区域进行分类与回归得到检测框。其中包括R-CNN[5]、Fast R-CNN[6]、Faster R-CNN[7]、SPP Net[8]等。虽然two-stage的目标检测算法具有更高的检测精度,但是训练网络以及检测图片的速度不够快。另一类算法是不需要Region Proposal阶段的one-stage的检测算法,可以直接生成被检测物体的预测分类概率以及预测坐标值,只需要一次检测即可得到结果,因而有着相对于two-stage更快的训练速度和检测速度。其中经典的算法有YOLO系列算法[9-12]、SSDNet[13]、FCOS[14],这些网络因有着轻量的参数以及计算量,通常有着高检测速度,可用于实时检测。现在,许多学者将深度学习应用于行人检测。文献[15]通过简化YOLOv3的主干网络、改进特征融合结构,提高行人检测精度与速率。文献[16]通过改进Faster R-CNN算法进行近红外夜间图像的行人检测。文献[17]使用K-mean++算法选定YOLOv3 先验框,并改进主干网络的结构提取更多行人尺度特征信息,以此实现对行人的检测。上述算法对行人检测领域做出了一定的贡献,但在精度和检测速度上仍有进步空间。
综上,考虑应用终端的计算力,本文以YOLOv5 为基础进行改进,提出CA-YOLOv5的轻量卷积神经网络模型,对拥挤人群场景的图像进行处理,采用Res2Block与CA模块重新设计主干网络,通过结构重参数化方法加快检测速度,引入特征增强模块增强多尺度特征的表达能力,使用EViT模块加强模型关注局部信息的能力,最终提高网络的检测精度。实验表明,CA-YOLOv5 在本文的行人检测任务中具有良好的检测性能。
1 YOLOv5 目标检测算法
1.1 YOLOv5网络概述
YOLOv5 网络是由Ultralytics LLC 公司提出的one-stage目标检测网络,是在YOLOv4网络基础上集成了许多近年来学术界的优秀成果,网络部署更灵活并且具有更高的检测精度和速度,可用于实时性的目标检测研究。YOLOv5的网络结构分为Backbone(主干网络)、Neck(多尺度特征融合网络)、Head(预测分类器)三部分组成。
1.2 Backbone
主干网络通常可以由ResNet[18]、DenseNet[19]、EfficientNet[20]等特征提取网络构成,用于提取图像的识别特征,包括边缘特征、纹理特征、位置信息等。YOLOv5中的主干网络主要由Focus 层、封装后的卷积层CBS、C3层、SPP层、Bottleneck层等结构组成。
1.3 Neck
颈部网络的设计是为了更好地利用主干网络提取的特征。它对不同阶段提取的特征图进行再处理和合理利用。YOLOv5 的Neck 采用的PANet[21](path aggregation network),该结构示意图如图1所示。
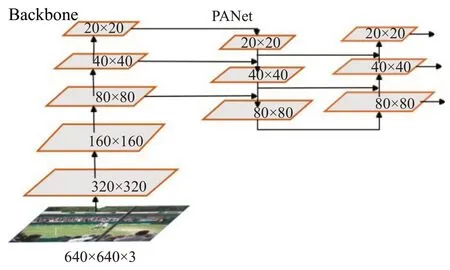
图1 Neck网络示意图Fig.1 Neck network diagram
1.4 Head
Head部分通常被设计成负责通过从主干网络提取的特征图或者从颈部网络中融合的特征图来检测目标对象的位置和类别。YOLOv5 是用三个1×1 卷积层替代全连接层进行预测与分类,分别在20×20、40×40、80×80三种尺度的特征图上预测三种锚定框对应类别概率、目标置信度、预测框坐标。
2 YOLOv5算法改进
2.1 Backbone网络的改进
原YOLOv5网络的C3结构先将基础层特征图在通道维度上映射成两部分,再通过BottleNeck结构使传播的梯度信息组合达到差异最大化。但是,根据文献[22]的分析,通过这种组合方式,网络仍会使用大量重复的梯度信息。而有效地减少重复的梯度信息,能使得网络的学习能力就会大大提高。因而,本文旨在使新的网络结构能在更细粒度的层面进一步增强特征融合能力,从而有效地减少信息集成过程中梯度信息重复的可能性。而Gao 等[23]提出的Res2Net,通过在一个残差块内构建分层残差连接,在更细粒度上表示多尺度特征,并增加了每个网络层的感受野。据此,重建了新的主干网络Res2Block结构。Res2Block结构如图2所示。

图2 Res2Block示意图Fig.2 Diagram of Res2Block
Res2Block 以更细粒度表示多尺度特征,同时增加块内感受野,从而加强神经网络检测物体的能力。Res2Block 通过一系列通道划分、分组卷积、块间融合、通道拼接等操作实现细颗粒特征融合,具体过程如式(1)所示。其中,输入特征X经过通道划分,划分为s块特征图,xi表示第i块特征图,Ki表示融合第i块特征图的卷积层,yi表示融合xi之后获得的特征图。
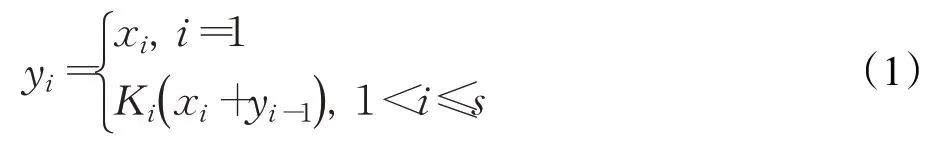
因此,Res2Block 的这种设计使神经网络能融合更细粒度信息,从而达到增强特征融合能力的目的。同时,这种设置多条融合支路的设计能有效地减少信息集成过程中梯度信息重复的可能性。
重建后的backbone网络详细参数如表1所示,所示参数对应位置含义为[output channel,kernel size,stride,padding]。具体网络结构则如图3所示。
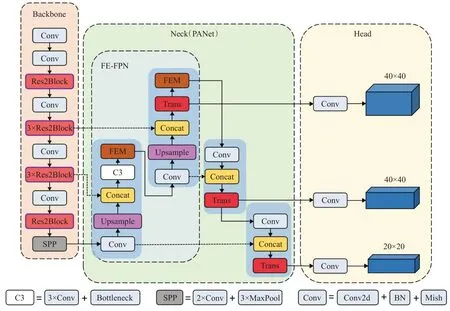
图3 CA-YOLOv5结构示意图Fig.3 Network structure diagram of CA-YOLOv5
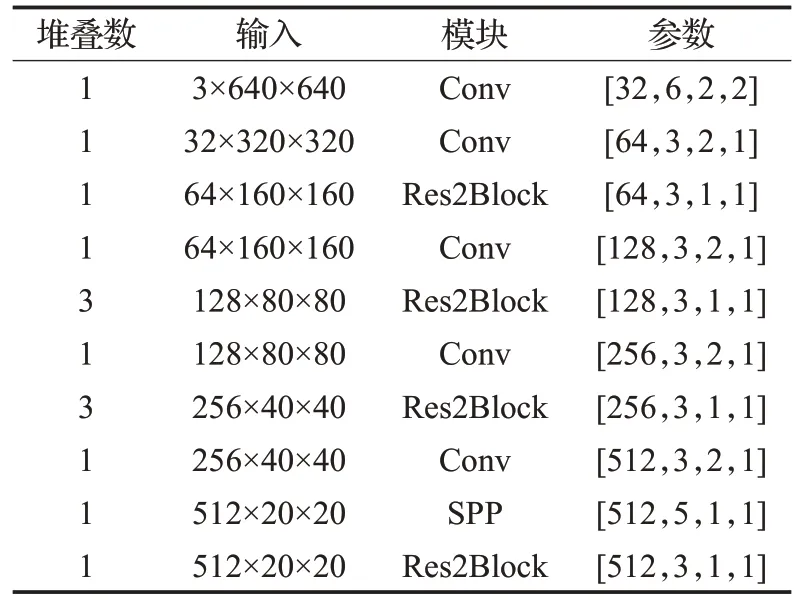
表1 主干网络结构表Table 1 Backbone network structure table
2.2 CA模块
Hou 等[24]在CVPR2021 中提出了坐标注意力(coordinate attention,CA)模块,针对SE 注意力只考虑通过建模通道关系来重新衡量每个通道的重要性,而忽略了位置信息的问题进行改进。CA模块不仅能捕获跨通道信息,还能捕获方向感知与位置信息。CA 模块沿着水平和垂直的空间方向编码特征图的通道信息,既能获取到空间方向的长期依赖关系,还能保存精确的位置信息,同时扩大网络的全局感受野。如图4为本文所用数据集的样本分布图,可见样本检测框尺度存在不均衡的情况。因此引入CA 模块增强网络的全局感受野以及对目标的精确定位能力,以适应本文图像尺度变化大的问题。
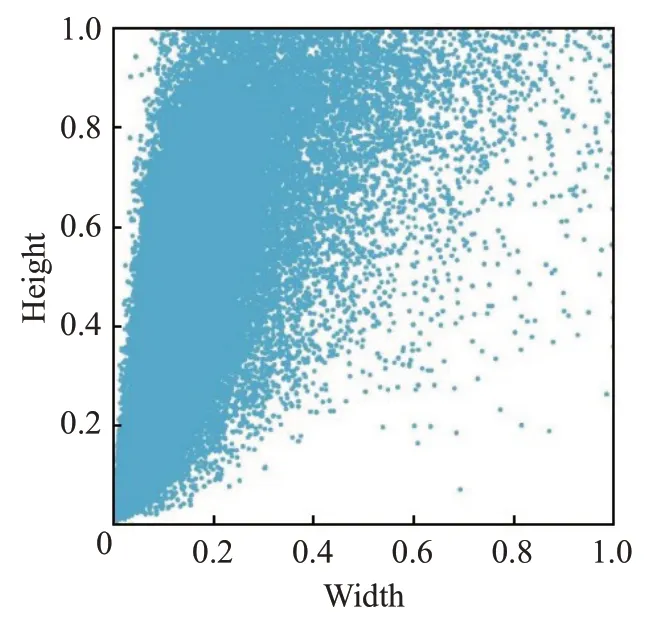
图4 检测框分布图Fig.4 Detection box distribution
如图5 所示,为避免全局平均池化(global average pooling,GAP)导致的位置信息丢失的问题,同时能有效地将空间坐标信息编码成注意力权重图。CA对输入特征图X分别使用H×1和1×W大小的池化核沿着水平与垂直方向并行地进行一维自适应平均池化(adaptive average pooling,AAP),进而产生水平和垂直的两个独立方向感知特征图zh与zw,大小分别为C×1×H和C×1×W。接着,在第三维度对两个带有特定方向信息的特征图进行拼接,再通过权重共享的1×1卷积与非线性激活函数,生成过程特征图f∈R(C/r)×1×(H+W),其中r为卷积中的通道下采样比例。再接着,将f在通道维度上拆分成两个特征向量fh、fw,并调整特征向量在第二、第三维度的大小,使其大小分别为fh∈R(C/r)×H×1和fh∈R(C/r)×1×W。再分别通过1×1 大小的卷积核进行通道转换,使fh、fw大小分别为fh∈RC×H×1和fh∈RC×1×W,最终经过激活函Sigmoid(x)得到两个空间方向的注意力权重图gh和gw,每个注意力权重图都带有特征图沿着特定空间方向的长程依赖。
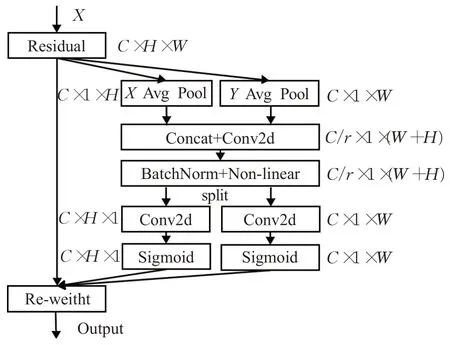
图5 CA结构编码注意力的过程Fig.5 CA structure encodes attention process
最后,输入特征图与两个权重图相乘,进而加强了特征图的表示能力。
如图6 所示,本文将CA 模块添加至Res2Block 中,用以增强主干网络感受野以及捕获位置信息的能力。
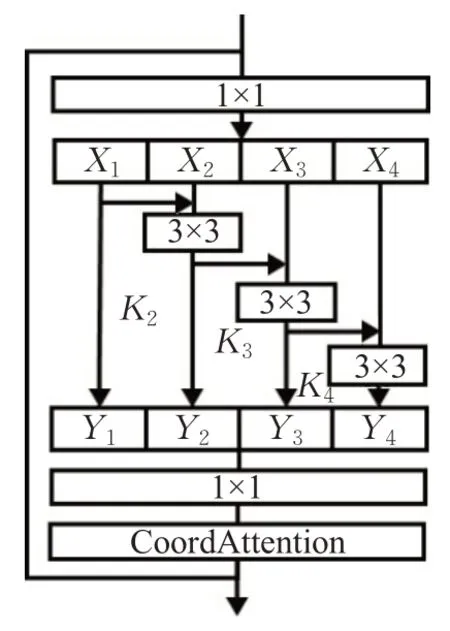
图6 改进后的Res2BlockFig.6 Improved Res2Block
2.3 特征增强模块的设计
根据Guo等[25]分析,Neck网络中的FPN结构直接将不同阶段的特征图融合时,不同尺度特征图学习到的特征感受野是不一样的,包含的语义信息也不同,把两个语义信息差距较大的特征直接融合,会减弱多尺度特征的表达能力。因此,本文使用空洞卷积[26]与分组卷积设计了特征增强模块(feature enhancement module,FEM)以增强多尺度特征的表达能力,FEM 结构如图7 所示,其中In、Out分别为输入通道数与输出通道数。
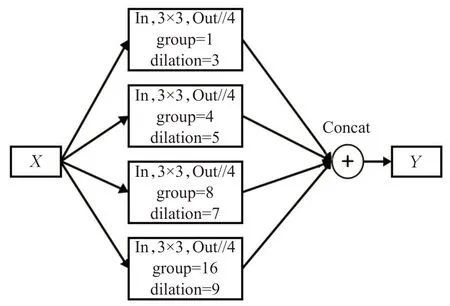
图7 FEM结构图Fig.7 Structure of FEM
FEM 结构不需要通过分辨率的下采样去提升感受野,而是采用了4个不同空间膨胀系数的空洞卷积增强感受野并提取不同尺度特征,然后再进行通道维度上的特征拼接,从而达到多尺度特征提取与融合的目的。其次,为了尽可能地减少计算量与参数量,还在每一组卷积中设置了分组卷积。在本文中,FEM结构设置在Neck网络中的第一个FPN结构中,本文将其命名为FE-FPN。
2.4 结构重参数化
结构重参数化(structural re-parameterization)概念,指的是首先构造一系列神经网络结构进行训练,然后在推理过程中将其中的神经网络参数转换为另一组参数,将一种结构等价转换为另一种结构,从而减少参数量,加快推理速度。只要参数的转换等价,那么这种结构的替换便是等价的。
Ding 等[27]于CVPR2021 上提出的RepVGG 网络则对结构重参数化进行了很好的实践与创新。本文主要采用了其中的卷积层与归一化层合并的思想。
在深度神经网络中,归一化(batch normalization,BN)层的引入,加速了网络的训练和收敛速度,可以有效缓解梯度爆炸与梯度消失,还有一定的防止过拟合能力。但BN层在拥有诸多好处的同时,也带来了昂贵的计算开销,计算均值等操作均需在内存中保存临时变量,增大了内存的开销,影响模型性能。为了加快模型检测速度,以及减小硬件的计算压力。本文采取卷积层与BN层融合的方式,加快模型的推理速度。以下是卷积层与BN层融合的公式推导过程:
卷积层公式如公式(2)所示,其中W为权重,b为偏置:

而BN 层的公式如公式(3)所示,其中γ与β为学习参数,mean为批次样本数据均值,σ为方差,ε为极小但不为零的数:

将卷积层结果代入到BN公式(3)中得:

令BN(Conv(x))=y,进一步化简为:
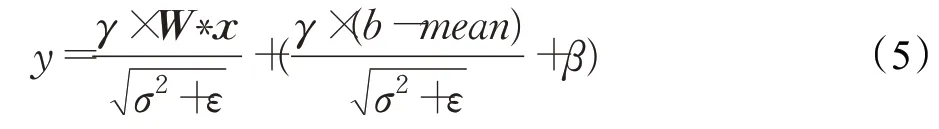
又令:

最终得到:
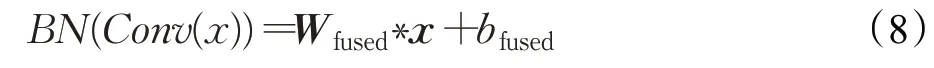
因此,融合后的结构仍是由权重与偏置构成,该过程实质上是对卷积核参数的修改,在不增加卷积层参数量的同时,略去了BN层的计算开销。
2.5 EViT模块
针对行人检测任务中普遍存在的拥挤行人问题,本文基于Dosovitskiy等[28]提出的Vision Transformer,设计了EViT(enhanced vision transformer)模块。如图8 所示,EViT模块包含两个子层,MHA(multi-head attention)层和MLP(multi-layer perceptron)层,并在两个子层前后加入LayerNorm层和Dropout层使网络更好地收敛以及防止网络过度拟合。
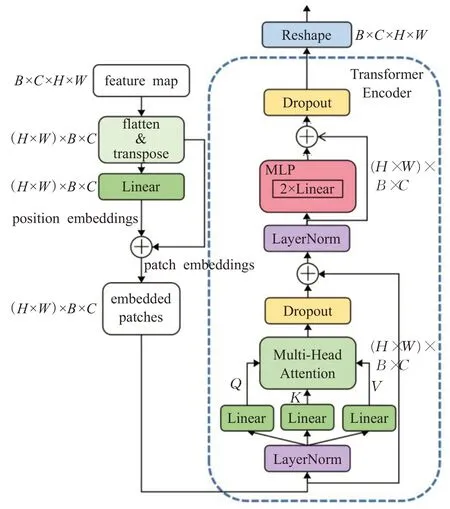
图8 EViT结构图Fig.8 Structure of EViT
在EViT 模块中,大小为B×C×H×W的输入特征图X首先进行patch 处理阶段,生成(H×W)×B×C大小的patch embedding 向量P1与position embedding 向量P2,并进行相加形成embedded patches 向量P。在经过Transformer 编码器阶段时,向量P分别通过三个线性层映射为Q、K、V三个向量并进入MHA 层。MHA层具体计算过程如下所示:
首先根据MHA层注意力头的个数s,将Q、K、V分别切分为s个向量:
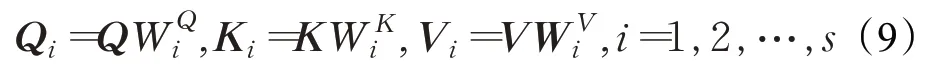
之后再计算每个注意力头的注意力权重矩阵,其中dk=C/s:
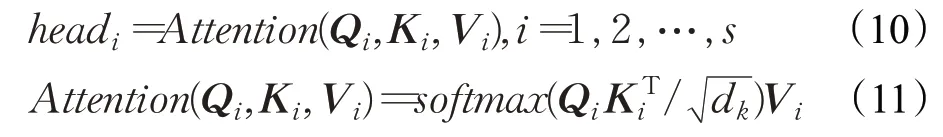
再然后将每个注意力权重矩阵进行合并,同时进行线性映射得到:
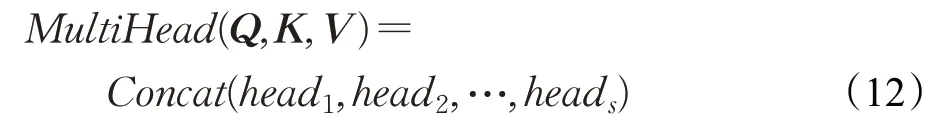
令M=MultiHead(Q,K,V),通过残存连接得到:

由MHA 层计算得到的向量Z最后再经过MLP 层与Reshape层,得到了经过EViT处理后的特征图。
在EViT模块中,Transformer Encoder通过MHA层扩展了模型关注不同位置的局部信息的能力,进而捕获更丰富的上下文信息。因此,本文在原始YOLOv5中所有与检测头相连接的位置使用EViT 模块,以便模型更好地检测拥挤行人,具体位置如图8所示。
3 实验对比与分析
3.1 数据集的划分
实验的图像数据来源于开源的CrowdPose Dataset和CrowdHuman Dataset[29],两者图像背景复杂多样,检测目标重叠密集。Li 等[30]制作了CrowdPose Dataset,其中包含20 000 张图像,标注人体共有80 000 个。CrowdHuman Dataset 常用于行人检测,包含约24 000张图片,总共有470 000个标注实例,平均每张图有23个人体标注,同时具有多种多样的遮挡。本实验从两个数据集中取出共17 000张图像,对可见的行人身体进行标注,图9为数据集中普遍存在的拥挤人群示例图。按比例随机抽取10 000张图像作为成训练集,2 000 张作为验证集,5 000 张作为测试集,总共约有120 000个标注人体框。

图9 部分数据展示Fig.9 Partial data set display
3.2 实验分析
本文实验使用Pytorch深度学习框架,训练环境:
CUDA 版本为11.1,GPU 为NVIDIA GeForce RTX 2060 SUPER,显存8 GB,编译语言为Python3.8,训练最小批次为16,总共训练200个epoch。
为验证本文提出的CA-YOLOv5 算法在行人检测任务的有效性,本文设置了4 个消融实验,1 个对比实验。第一个实验是验证使用Res2Block构建的主干网络性能,对比了YOLOv5 与CA-YOLOv5。第二个实验是为了验证本文提出的FE-FPN 结构的有效性,对比了普通FPN 结构与本文提出的FE-FPN 结构。第三个实验验证了卷积层与BN 层融合对网络检测速度的加速效果。第四个实验是为了验证加入了CA模块对模型的提升效果,第五个实验是为了测试使用EViT 模块后与当前主流算法在行人检测任务中的表现性能进行对比,以证明CA-YOLOv5算法的性能优势。
训练时对设置输入图像大小为640×640,采用SGD优化器对网络进行训练,初始学习率为0.2,使用余弦退火策略调整学习率。本文的消融实验采取和原始YOLOv5一样的图像增强方法。
实验以平均精度均值(mean average precision)、模型每秒检测的图像数量(FPS)、params(参数量)、GFLOPs(计算量)、权重大小等评价指标对模型进行评价。
实验一对比了以Res2Block 作为主干网络的Res2-YOLOv5 与YOLOv5 的效果,结果如表2 所示。从两种网络模型在mAP指标上的数据可知,Res2Block结构使网络的mAP 从81.11%提升到了82.91%,提升了1.8 个百分点,说明由Res2Block 构成的主干网络对于提升整个网络的检测精度是有帮助的。
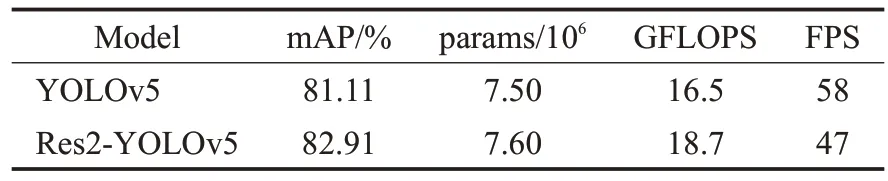
表2 Res2-YOLOv5的性能对比Table 2 Performance of Res2-YOLOv5
为了进一步加强多尺度特征的表达能力,本文在FPN结构中加入了特征增强模块构成FE-FPN。实验二对比了FE-FPN 结构和FPN 结构的检测效果,结果如表3 所示。观察mAP 可知,使用FE-FPN 时相对于FPN 结构,mAP提升了0.89个百分点。
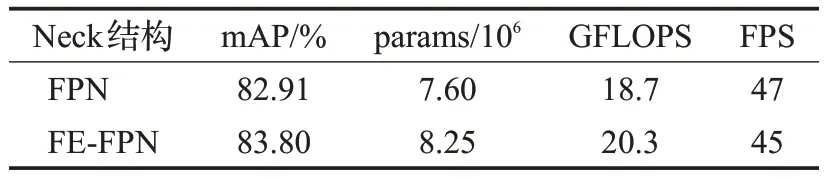
表3 FE-FPN与FPN性能对比Table 3 Comparison between FE-FPN and FPN
行人检测通常应用于工商业的监控设备中,因此为满足实时检测的要求,加快模型检测速度,便于在监控终端部署,本文使用卷积层与BN层融合的方式,减少计算开销。本文通过实验三验证该方式的有效性。表4为对比结构参数化前后模型的性能表现,虽然融合后的模型权重文件大小、参数量、计算量下降不多,但是FPS增加了15。这是因为融合卷积层和BN 层后的模型不再经过BN 层,节省了原先用于BN 层的计算开销。经实验证明,使用结构重参数化方法后的模型有效地提升了检测速度,更好地满足行人检测任务对检测速度的要求。
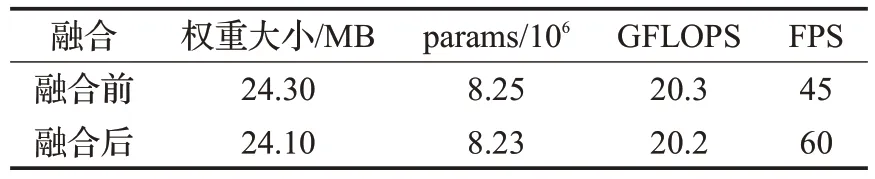
表4 结构重参数化前后的性能对比Table 4 Performance comparison before and after structural re-parameterization
本文引入了CA 注意力模块,用于增强网络的全局感受野。实验四对比了增加CA模块前后的性能表现。具体数据如表5 所示,观察mAP 可知,在Res2Block 模块中增加CA 模块后,mAP 增加了0.63 个百分点,同时参数量、计算量、FPS不变。

表5 融合CA模块前后性能对比Table 5 Comparison before and after integration of CA
本文加入了EViT模块,能更好地捕获局部信息,所提算法称为CA-YOLOv5。在实验五中,本文算法与目前一些主流算法在行人检测任务中的性能表现,目的在于验证本文所提算法的有效性。如表6所示,本文对比了以下算法:YOLOv5、Mobilenetv3-YOLOv5、YOLOv3、YOLOv3-spp、YOLOv3-tiny、Mobilenetv3-SSD-Lite、VGG16-SSD、ResNet50-FCOS。实验表明,本文CAYOLOv5 算法在拥挤行人检测任务上可达到84.86%的检测精度。相较于原YOLOv5 算法,本文算法增加了30%参数量和28%计算量,提高了3.75个百分点的检测精度。虽然YOLOv3-spp算法的精度与本文算法相当,然而其参数量为6.15×107以及GFLOPs 高达154.90,远大于本文算法。经实验验证,CA-YOLOv5 算法在单个GTX2060s 显卡中检测速度可达到51 FPS,可满足硬件终端上行人检测任务的实时性需求,保证了比原网络稍高的检测速度,在所有对比模型中综合性能最好。
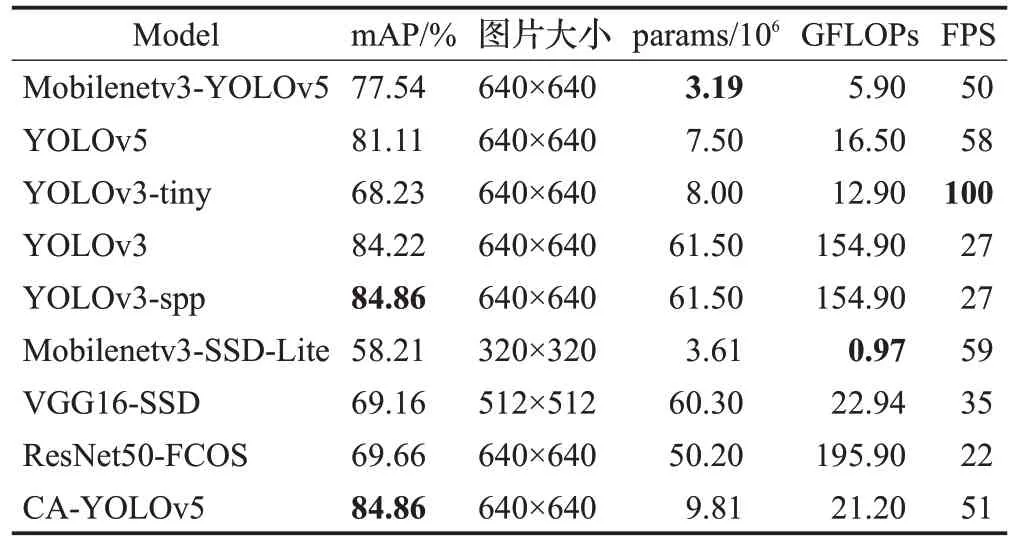
表6 不同算法检测结果比较Table 6 Comparison of detection results of different algorithms
本文将CA 模块与ResBlock 融合,用于构建新的主干网络,提出新的特征增强模块,同时应用EViT 模块,并在实验中验证了该算法的有效性,图10 为CAYOLOv5算法的检测效果。

图10 CA-YOLOv5算法检测结果Fig.10 CA-YOLOv5 algorithm detection results
4 结束语
本文提出了一个实时高效的基于YOLOv5 算法的拥挤行人检测算法——CA-YOLOv5。针对原网络的主干网络特征融合不充分的问题,提出以Res2Block 构建主干网络,同时使用结构重参数化方法加快模型检测速度。针对数据集目标尺度变化大的问题,引入CA模块增强感受野,增强模型对目标的精确定位能力,提高检测精度。为解决颈部网络的FPN 结构在特征融合时导致多尺度特征表达能力下降的问题,提出FEM结构以增强颈部网络中多尺度特征的表达能力,采用EViT 模块以加强模型捕获局部信息的能力,提高网络检测精度。实验证明,CA-YOLOv5 算法具有优秀的检测精度和实时检测效果,能很好地应用于拥挤行人检测任务中。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林(2021年5期)2021-04-18 12:21:17
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
扬子江(2019年1期)2019-03-08 02:52:34
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
电视技术(2014年19期)2014-03-11 15:38:20
