
多节点探测器软着陆的路径规划方法
2022-05-12 05:20:26赵清杰于重重张长春陈涌泉
宇航学报 2022年3期
王 鑫,赵清杰,于重重,张长春,陈涌泉
(1. 北京理工大学计算机学院,北京 100081; 2. 北京工商大学人工智能学院,北京 100048)
0 引 言
小行星探测是一项学科综合、高技术集成的系统工程,体现了一个国家的综合实力和竞争力。探测器的着陆是小行星探测任务中的一个关键阶段,它直接影响整个探测任务的成败。探测器在着陆时会受到空中失效航天器与碎片等动态障碍物的干扰以及小行星表面的岩石、陡坡、陨坑等静态障碍物的干扰,影响自身着陆的安全性和姿态的稳定性,因此规划出一条最优路径是后续安全着陆的保证。此外,由于小行星与地球距离较远,而且小行星环境具有未知性和特殊性,地面控制站无法对着陆实施全程监控,所以探测器需要具有一定的自适应、自学习和自主决策能力。
刘建军等利用启发式搜索算法和动态路径最优算法提出了一种基于可通过性的月面巡视探测器的路径规划算法。Liu等根据激光测距仪的信息对月壤地面的地形进行建模,提出了基于虚拟机体模型的自主避障策略。徐帷等采用Sarsa(λ)强化学习实现空间机械臂的自主路径规划。邓泓等通过建立路径规划的环境模型、综合适应度函数,设计遗传算子,提出了基于遗传算法的攻击卫星安全穿越路径寻优方法。罗汝斌等提出了一种基于深度强化学习的自适应协同探测方法,用以解决行星车探测未知区域的问题。郭继峰等提出了一种全局与局部规划结合的行星车自主探测融合路径规划方法。周思雨等采用D3QNPER方法对行星车在着陆过程中进行路径规划,避免了传统规划算法对先验地图信息的依赖。当面对更加复杂、不确定的环境时,上述方法的稳定性和可行性都面临一定的挑战。
近年来,深度强化学习在很多方面得到了应用,如自动驾驶、机器人、推荐系统、智能电网等。引入深度强化学习,面对不同的着陆环境时,探测器通过与环境交互,接收从环境获得的评价反馈,自主学习,得到不同环境状态下的最优策略,可以实现对环境的自适应能力。自注意力机制和多任务学习可以进一步提升系统对环境的搜索能力,二者在人工智能相关的多个领域已得到应用。
目前的小行星探测器大多是单节点,着陆时容易出现翻转、倾覆、失联等现象。面向小行星探测任务的需要,柔性连接的多节点(多智能体)系统是针对探测器着陆不稳定问题的一种解决方案。本文构建了一种采用柔性连接的三节点探测器并对其着陆情况进行建模研究,进而提出了一种融合时间上下文的自注意力机制的多任务深度强化学习方法,对探测器各节点的速度、加速度等进行协同规划,使得探测器具有更优的着陆自控性能。
1 深空柔性探测器软着陆建模
传统的单节点探测器依靠人类先验知识来确定飞行策略,进而实现探测器着陆。但是,小行星的很多参数未知,单节点探测器在着陆过程中容易失控、倾覆或反弹逃逸,亦或无法实现确定的着陆策略而导致探测器不能实施精确着陆。针对上述问题,本文构建了一种采用柔性连接的三节点探测器,并对其着陆情况进行建模。
深空探测器在着陆过程中,探测器以小行星为参照物来描述自身的状态,可以表示为一个四元组<,,,>,其中,表示探测器的运行速度,表示探测器相对于小行星的角速度,表示探测器相对于小行星的距离,表示探测器相对于小行星的角度。
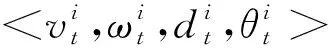
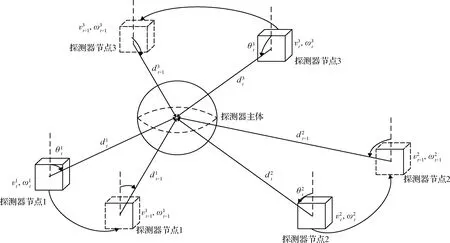
图1 探测器每个节点运动情况图Fig.1 Motion chart of each node of the probe
2 带自注意力机制的多任务深度强化学习
2.1 深度强化学习
深度强化学习是一种将深度学习的感知能力与强化学习的决策能力相结合的一种更接近人类思维的人工智能方法。深度确定策略梯度算法(Deep deterministic policy gradient, DDPG)是将深度学习和确定性策略梯度(Deterministic policy gradient, DPG)进行融合,采用卷积神经网络对actor网络和critic网络进行模拟,然后使用深度学习的方法训练actor网络和critic网络。由于critic网络参数在频繁地进行梯度更新的同时又用于计算critic网络和actor网络的梯度,导致学习过程不稳定,因此DDPG为actor网络和critic网络各创建两个神经网络,一个是Online网络,一个是Target网络,结构如图2所示。其中,Online网络和Target网络均由六个全连接层构成的多感知机(Mulitlayer perceptron, MLP)组成。
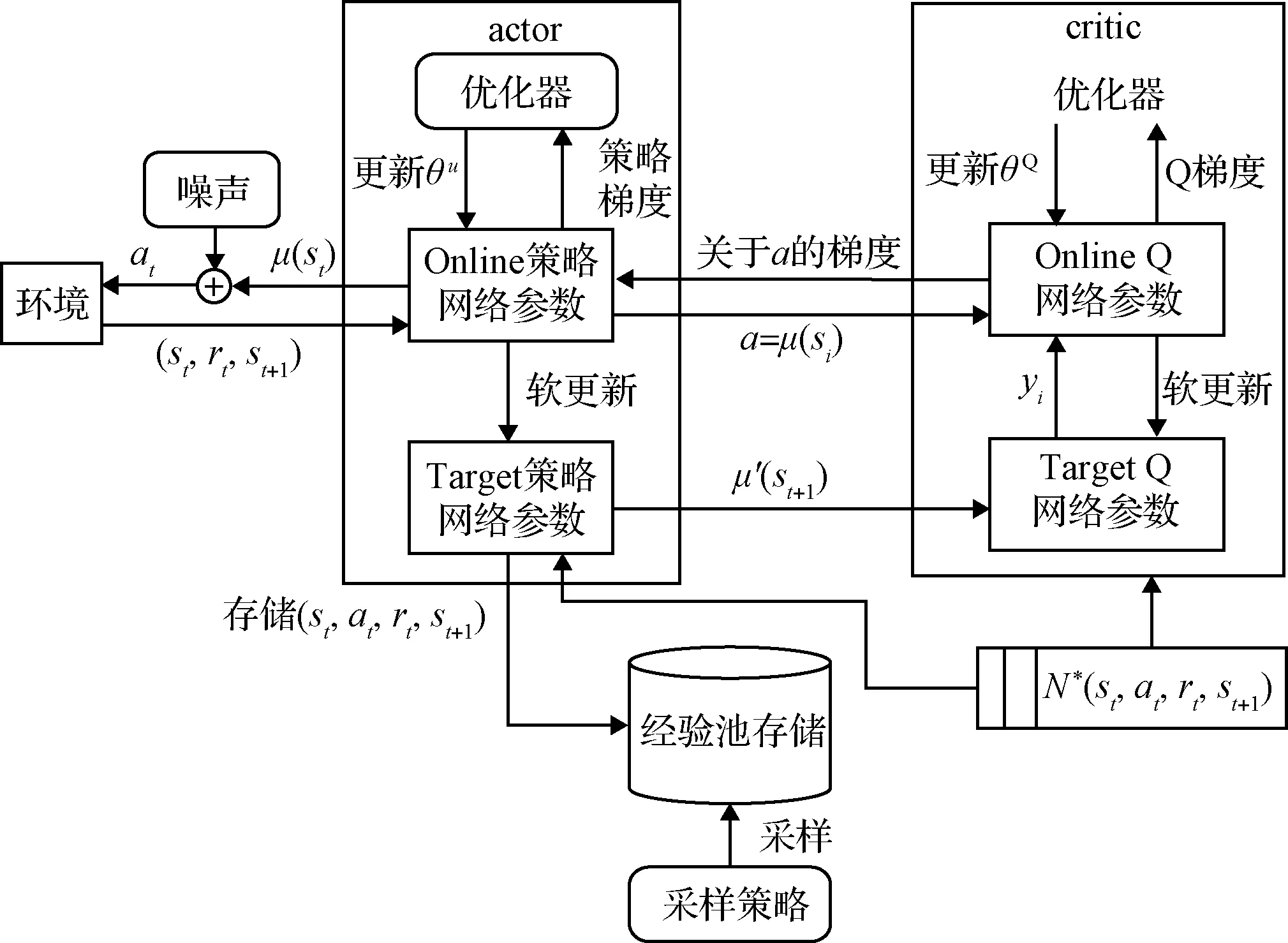
图2 DDPG网络结构图Fig.2 Network structure of DDPG
2.2 多任务学习
多任务学习是一种归纳迁移学习,目的是通过使用给定的多个任务中包含的知识来帮助提升各个任务的性能。近年来,多任务学习与监督学习、半监督学习、主动学习相结合,解决了多个领域的难题。
探测器在着陆过程中,探测器各节点的位置、速度、角速度等都是动态变化的,同时深空中的障碍物也处于运动状态,这些因素都对探测器的稳定成功着陆具有一定的影响。为保证探测器可以成功着陆,需要对探测器的各个节点进行协同规划,以及协同避障。
鉴于多任务学习的优点,本文构建关于探测器节点和障碍物的多任务学习模型,通过将其他节点任务和障碍物任务作为当前正在学习的任务的监督信号来提升自己的学习能力,进一步提高模型整体的性能。由于探测器计算资源有限,基于参数软共享方式的结构需要每个任务具有自己的模型和参数,计算开销较大,而基于参数硬共享方式的结构,任务共享模型及参数,所需的计算资源开销较少。本文选择参数硬共享方式来构建探测器的多任务学习模型,结构如图3所示。
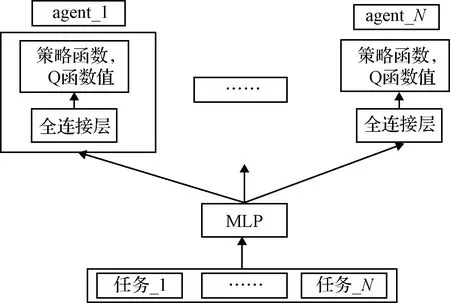
图3 智能体参数共享结构图Fig.3 Parameter-sharing structure chart of agents
2.3 融合时间上下文的自注意力机制
近年来,在人工智能领域,注意力机制已经成为神经网络的重要组成部分,并且在计算机视觉、自然语言处理和统计学习等领域被广泛使用。网络结构中的注意力模块自动学习注意力权重,可以自动地捕获编码器隐藏状态和解码器隐藏状态之间的相关性,即注意力模块可以使模型动态地关注有利于当前任务的某些信息。
自注意力机制是注意力机制的一种,其减少了对外部信息的依赖性,更加擅长捕捉数据或特征的内部相关性。探测器在进行多任务学习时,通过采用自注意力机制有助于探测器节点更加关注有利于使自己获得最大回报的信息进行学习。
深空探测环境不确定,智能体在进行空间状态搜索时,具有时间多样性,为避免探测器陷入最近时间学习的较差局部状态,本文引入时间上下文信息,采用更多的历史先验知识指导探测器学习到最优的状态。
本文按式(1)~(3)构建时间上下文自注意力机制,首先将式(1)自注意力机制的输出与MLP的第个全连接层输出的特征图进行矩阵运算,得到加权特征图,然后将该加权特征图与MLP的第-1个全连接层输出的特征图进行矩阵相加,得到最终的特征图。
=softmax((-1(,)))
(1)
=*
(2)
=+-1
(3)
其中,表示第个智能体的观测值;表示第个智能体的行为,∈{1,2,…,};表示智能体的个数;表示激活函数ReLU;-1表示MLP的第-1层的特征图;softmax表示归一化指数函数,将函数的每个输出都映射到(0,1);表示元素取值为(0,1)的注意力权重矩阵;*表示矩阵对应位置元素相乘;表示MLP的第层的特征图;∈{2,…,-1},表示MLP全连接层的个数。
2.4 带自注意力机制的多任务深度强化学习
为解决柔性连接的三节点探测器着陆问题,本文提出了融合时间上下文自注意力机制的多任务深度强化学习方法AMTDRL(Fusion attention and multi-task in deep reinforcement learning, AMTDRL),探测器节点的观测值和行为作为MLP的输入,MLP通过时间上下文的自注意力机制来获取使自身获得最大收益的特征信息进行学习,之后每个节点学习自己的actor和critic网络,模型结构如图4所示。

图4 AMTDRL模型结构Fig.4 Model structure of AMTDRL
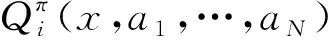
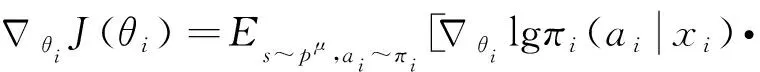

(4)
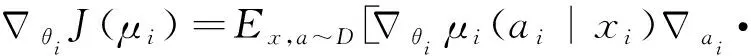
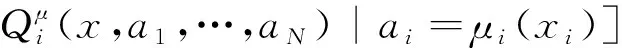
(5)
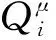
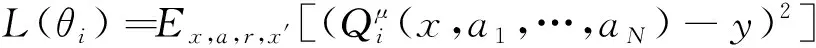
(6)
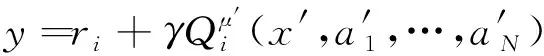
(7)
其中,()表示关于的损失函数;,,,′表示智能体在观测值为、行为为、奖励为、新观测值为′时获得奖励误差的期望值;表示智能体奖励的真实值;′={′,…,′}表示智能体的策略函数,其参数为′;表示第个智能体获得的奖励;表示折扣因子。
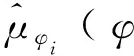
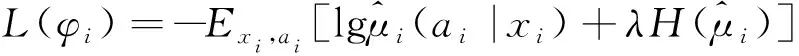
(8)
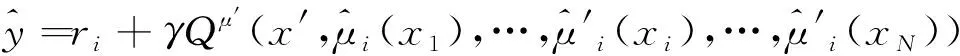
(9)
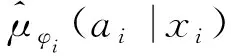
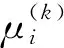
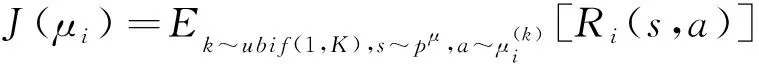
(10)


(11)
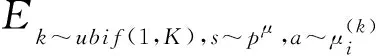
3 仿真校验
3.1 仿真参数
本文探测器设置三个节点,三个动态障碍物,初始速度为3 m/s,加速度为0.5 m/s,最大速度为8 m/s,一个静态障碍物,MLP网络的参数采用高斯初始化,DDPG的噪声采用Ornstein-Uhlenbeck噪声,初始参数均值为0,方差为0.2,为0.15,AMTDRL模型的超参数设置见表1。Online网络和Target网络每迭代20次软更新一次。探测器参数初始参数见表2。根据探测器节点的运行情况奖励函数的设置见表3。

表1 AMTDRL模型超参数Table 1 Hyperparameters of AMTDRL

表2 探测器参数Table 2 Parameters of deep space probe
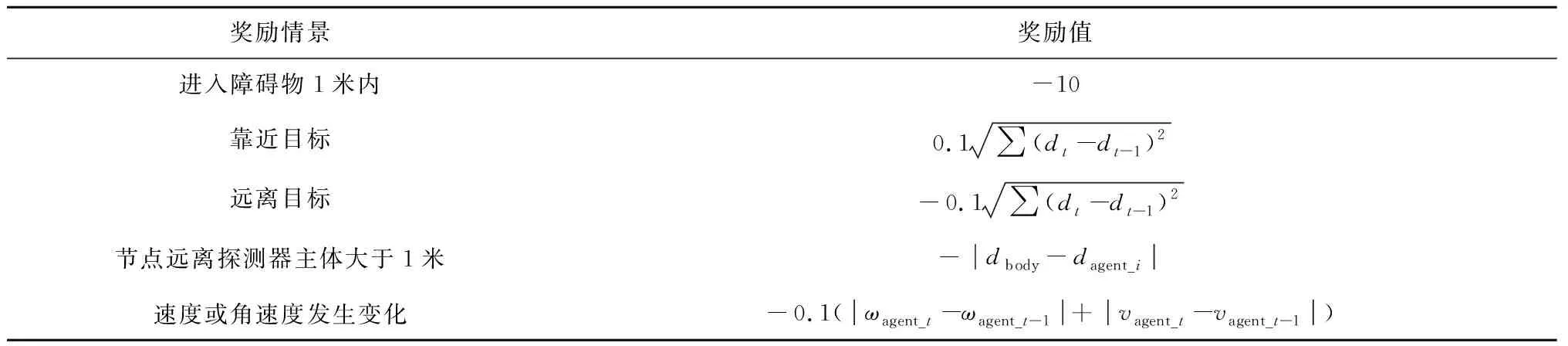
表3 奖励函数Table 3 Function of reward
3.2 仿真结果与分析
本文以MADDPG模型为基准进行对比。为了证明算法的收敛性、适应性和鲁棒性,AMTDRL算法和MADDPG算法在参数设置不变情况下,分别进行三次仿真实验,每次仿真实验迭代30000次。每次实验算法都达到了收敛,并且对每次仿真实验得到的平均奖励进行累加,然后再取平均值,探测器最终获得的平均奖励如图5所示。

图5 MADDPG与AMTDRL的平均奖励对比Fig.5 Mean rewards of MADDPG and AMTDRL
通过图5可以看出,在迭代前15000次,探测器的平均奖励在稳步增长,在迭代后15000 次,平均奖励平稳下降,然后保持稳定,说明探测器稳定着陆。此外,将AMTDRL与MADDPG进行对比,可以看出,在每次迭代过程中,AMTDRL获得的奖励均高于MADDPG,30000次迭代过程中,AMTDRL总的平均奖励比MADDPG高9.94,说明AMTDRL学习效果更好,探测器能够更好地避障和着陆。
AMTDRL模型的actor网络和critic网络同时采用attention机制与只有actor网络采用attention机制进行对比,通过图6可以看出,在迭代10000次左右时同时使用attention的效果更好,说明探测器仍在搜索最优的状态,随着迭代次数的增加,当探测器逐渐靠近最优状态时,attention机制对critic来说效果不明显。

图6 只actor网络采用attention (p_attention)与两个网络同时采用attention (pq_attention)的平均奖励Fig.6 Mean rewards of only actor network with attention (p_attention)and both networks with attention (pq_attention)
探测器在着陆过程中,空间中的障碍物也处于运动状态,导致探测器着陆的环境时刻处于变化之中,同时小行星表面也存在陡坡等静态障碍物,面对这些不同的情况,深度强化学习通过及时地调整策略使探测器具有自主规划能力,可以成功避障。
实验仿真环境为长宽高都为40 m的正方体,圆表示空间中失效的航天器与碎片等动态障碍物,三角形表示小行星表面的陡坡或岩石等静态障碍物,十六角星表示探测器。探测器的起点坐标为(-7.5, 18, 17),终点坐标为(14.5, 2.5,-20),动态障碍物1的起始坐标为(-12.5, 16, 13),终点坐标为(-14, 13.5, 7),动态障碍物2的起始坐标为(-17.5, 3, -6),终点坐标为(-13, -2.5, -10.5),动态障碍物3的起始坐标为(-8, -9, -12),终点坐标为(0, -3, -16.5),静态障碍物的坐标为(12.5, -2.5, -20)。探测器的运动路线如图7所示,探测器在着陆过程中,无论是在空间中遇到动态障碍物,还是在附着时遇到小行星表面的静态障碍物,都会根据AMTDRL学习的策略及时调整自身的状态,远离障碍物,实现成功着陆。

图7 路径规划结果Fig.7 Path planning result
由于更多的节点数会使系统的复杂性明显提升,因此我们只对两节点和三节点情况进行对比研究。以迭代10000 次为例,分析DDPG、MADDPG和AMTDRL三种方法的表现,结果如图8所示。
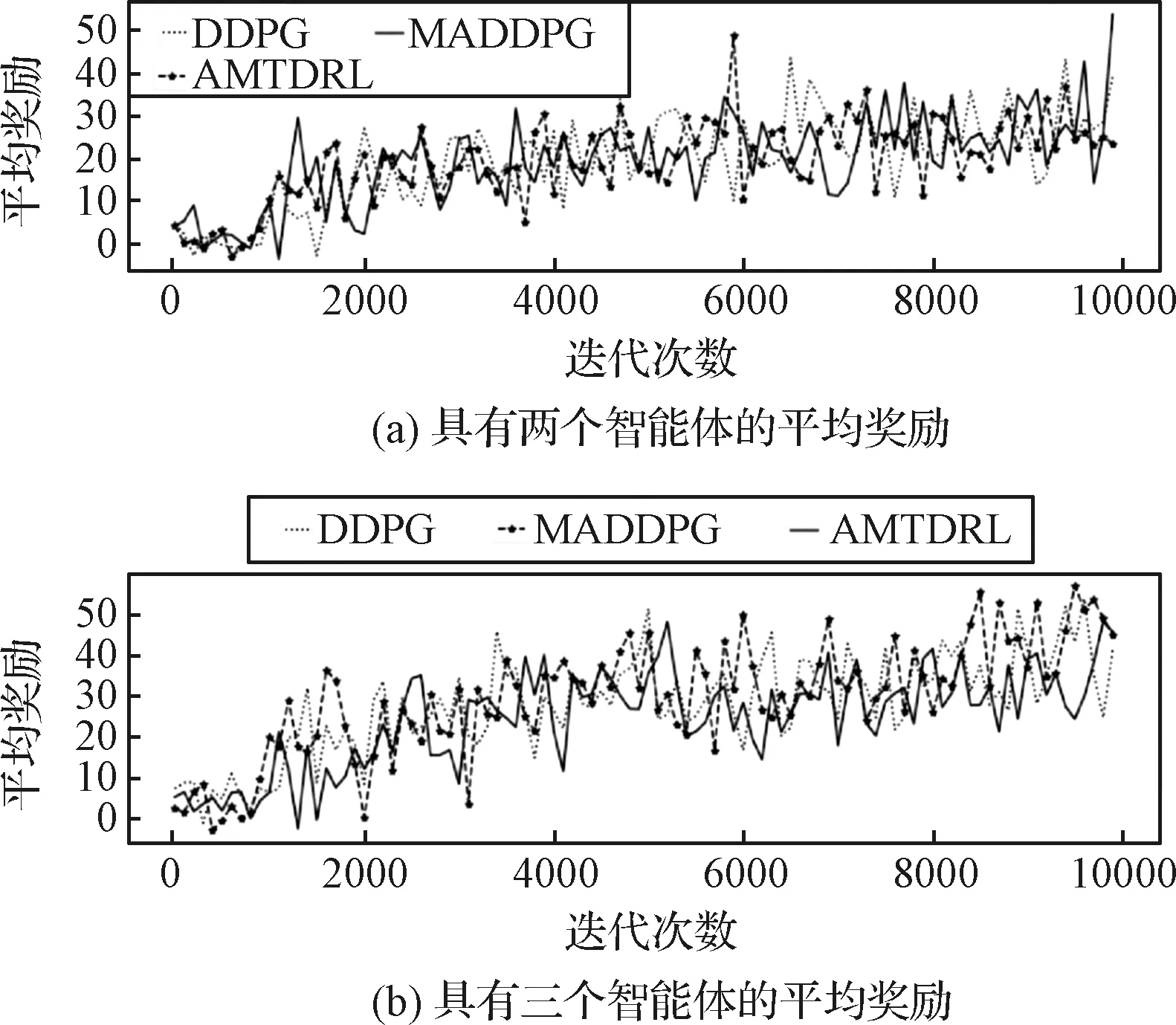
图8 DDPG、MADDPG及AMTDRL分别在两节点和三节点情况的平均奖励Fig.8 Mean rewards of DDPG, MADDPG and AMTDRL for 2 & 3 nodes
从图8(a)中可以看出,具有两个节点的探测器在运行过程中获得的奖励在20~30之间;从图8(b)中可以看出,随着训练次数的增加,具有两个节点的探测器在运行过程中获得的奖励在30~40之间,三节点探测器的平均奖励比两节点的奖励高出10左右,说明三节点探测器运行更加稳定。另外可以看出,DDPG方法获得的奖励相对较低,说明探测器在运行过程中节点之间或者与障碍物之间容易发生碰撞;MADDPG方法波动较大,说明探测器运行状态不稳定;AMTDRL具有较高的奖励,而且波动较小,说明探测器在运行过程中比较稳定。
4 结 论
针对传统的单节点探测器在着陆过程中因缺乏自主规划能力而导致着陆失败的问题,本文提出了一种融合自注意力机制的多任务多智能体深度强化学习方法,实现柔性连接的多节点探测器的成功软着陆。我们以柔性连接的三节点探测器为例进行研究,以探测器主体为参照物来描述节点自身的状态,探测器节点与节点之间、节点与障碍物之间通过联合学习,来提高各智能体的适应能力;在对探测器和障碍物进行特征提取时,采用注意力机制来提高对自己任务的关注,从而获得最大的奖励。通过与其他方法的对比,证明了本文提出的方法更有利于探测器稳定地着陆。
猜你喜欢
军事文摘(2022年24期)2023-01-05 03:38:22
今日农业(2022年2期)2022-11-16 12:29:47
动漫界·幼教365(中班)(2020年3期)2020-04-20 11:03:27
铁道通信信号(2020年9期)2020-02-06 09:15:54
中国生物医学工程学报(2019年6期)2019-07-16 07:52:40
自动化学报(2016年3期)2016-08-23 12:02:56
太空探索(2016年1期)2016-07-12 09:55:54
电测与仪表(2016年5期)2016-04-22 01:13:46
太空探索(2014年11期)2014-07-12 15:17:00
计算机工程(2014年6期)2014-02-28 01:26:17
