
基于GA-BP神经网络的雷竹林CO2浓度反演*
2022-05-11 11:53侯志康曾松伟莫路锋周宇峰
林业科学 2022年2期
侯志康 曾松伟 莫路锋 周宇峰
(1.浙江农林大学信息工程学院 杭州 311300; 2.浙江农林大学环境与资源学院 杭州 311300)
全球森林覆盖率为32%,森林碳储量占全球陆地生态系统碳总量的77%。森林生态系统通过同化作用吸收CO2,再以生物量的形式将CO2固定在植被和土壤中,使其成为陆地上最重要的碳汇或碳库(Attrietal., 2018; 刘平奇等, 2020; 王兴昌等, 2015)。森林生态系统通过物理化学的反应过程与大气进行物质和能量交换,进而对全球气候变化产生影响,开展森林碳循环监测研究有助于评价未来气候变化趋势(Leeetal., 2018; Sasaietal., 2007)。森林碳通量观测研究已成为当前研究热点(刘敏等, 2014; 李国栋等, 2013; 陈晓峰等, 2016)。
目前,森林碳通量的观测方法主要包括微气象学法、土壤碳储量清单调查、卫星遥感、大气CO2浓度反演和建立生态系统模型等(于贵瑞等, 2014; 韦志刚等, 2016; Wilsonetal., 2001)。微气象学的代表方法是涡度相关法,涡度相关技术也是唯一能直接测定生态系统与大气间物质能量交换的标准方法,已成为国际碳通量观测(网络)的主流技术(张鑫等, 2011)。Ishtiaq 等(2015)通过研究美国落叶林冠层CO2通量与气候环境变量的相关性后,提出利用环境因素建立碳通量的数据模型,该模型省去了传统搭建生态系统模型反演碳通量的复杂过程; 王海波等(2014)通过气象观测系统研究青藏高原草甸生态系统的碳通量变化特征及其影响因素,认为CO2的浓度与气象因素具有相关性。搭建环境数据反演碳通量模型是目前最简便、高效的碳通量研究方法,无需考虑生物量对试验结果的影响,仅关注于环境数据与反演结果之间的相关性。因此,结合气象因子和人工神经网络对碳通量进行反演是可行的。王怡鸥等(2016)利用三元回声状态网络算法对区域CO2浓度进行预测,提高了预测结果的精度,但其弊端在于模拟计算耗时较长; 汪雪等(2017)通过贝叶斯改进人工神经网络对竹林碳通量进行估算,取得了较好效果。神经网络的初始权值是随机分配,因此收敛性能存在不稳定性,并且模型的参数选择也会对反演结果产生影响(姚仲敏等, 2015; 张宏等, 2014; 王新普等, 2016)。本研究将相关气象因子作为输入,引入遗传分类神经网络(GA-BP)和参数试凑法对CO2浓度反演进行建模,以克服上述缺点。
本研究以浙江省杭州市临安区太湖源镇雷竹(Phyllostachyspraecox)林作为研究对象,研发基于嵌入式的竹林气象因子实时采集系统,并分析竹林CO2浓度与温湿度等气象因子之间的关系,探讨基于GA-BP神经网络的雷竹林CO2浓度反演模型(简称GA-BP模型),以期为竹林碳储量、竹林增汇、竹林固碳能力等研究提供基础数据。
1 研究区概况
研究区位于浙江省杭州市临安区太湖源镇(119°34′104″E,30°18′169″N)国家级自然保护区天目山东麓,其地形为中低山丘陵。气候类型属亚热带季风气候: 全年温暖湿润,雨热同期,气候温和,雨量充沛。春季以阴雨天为主,夏季湿热伴有梅雨期,秋季干爽,冬季干冷。全年降水量1 600 mm,年蒸散量800~850 mm,年均空气相对湿度在80%以上,年均气温16 ℃,全年日照时长1 900 h。研究区土壤以红壤为主,海拔185 m,坡度为东西方向2.5°、南北方向12.5°。
雷竹林群落高7~11 m,胸径4~6 cm,以2、3年生竹为主,总覆盖度达80%,立竹密度为22 500株·hm2,竹林林冠郁闭度>0.7,林下灌木草本少,有竹叶及竹笋保温材料覆盖,竹林地势平坦。
2 研究方法
2.1 竹林气象数据采集
采用涡度相关技术可直接测得生态系统的环境变量,有助于定量理解水、热和CO2在生态系统中的交换过程,可更深层地理解气候变化与生态系统之间的相互影响(刘晨峰等, 2009)。本研究基于涡度相关法设计了一套基于嵌入式的森林碳通量数据远程实时监测系统,该系统主要由嵌入式主控模块、CO2传感器(B530)、三位超声风速仪(Windmater)、大气温湿度传感器(DHT11)、Zigbee通信模块、GPRS(GTM-900)、数据存储模块(AT24C02)、太阳能充电模块等组成。
监测点实时采集气象因子数据,通过Zigbee无线传输经过无线分组业务,再通过GPRS模块将数据无线传输至后台服务器,服务器再将数据存储在后台数据库,并在Web网页上实时显示,用户通过平台查询和下载数据。碳通量数据监测系统框架如图1所示。系统主要监测的数据有:CO2浓度、大气温湿度、风速和风向等。
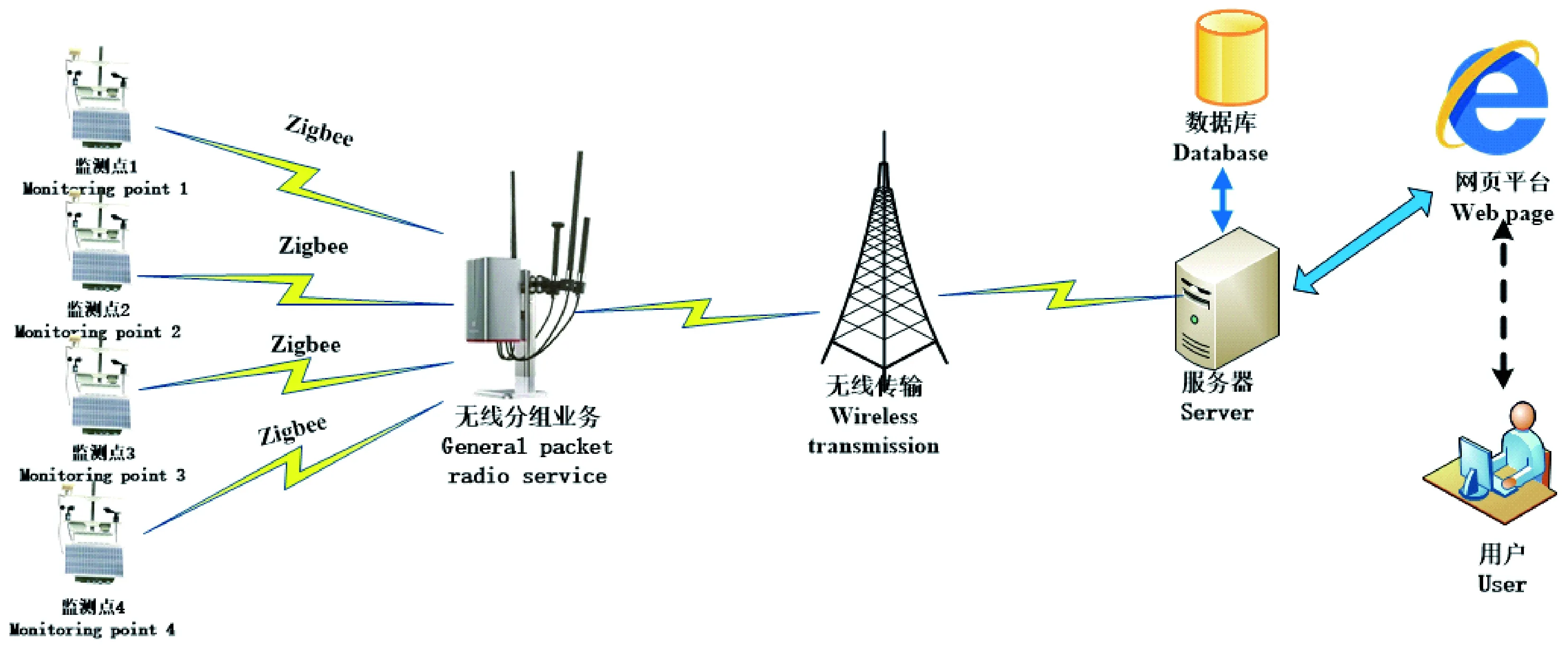
图1 气象因子数据采集系统框架图
2.2 数据处理
本研究所用的原始数据来自4个监测点(均布施在通量塔周围,林冠层盖度>0.7,监测点位于近地面1.5 m处,同时林地品种单一,下垫面覆盖有凋零的竹叶及竹笋保温材料,本试验排除光照强度及其他植物种生物量等因素的影响),采集时间为2019年10—11月(此时当年生新竹已经成熟,光合速率和呼吸速率稳定)。因电源断电及仪器短期故障等因素而导致的某个时间段内丢失的部分气象数据,采用高斯模糊插值法恢复。试验选取每5 min采集的CO2浓度及温湿度等气象数据平均值作为建模所用的数据集。试验数据分为4组,每组1 200个数据样本,其中80%作为训练集, 20%作为测试集。
一般而言,确定某个事象概念需要诉诸逻辑学中演绎、归纳等方法。一个概念的完整界定分为内涵和外延。前者是指某个概念所含括的思维对象的特有属性总和;后者是指该概念所含括的思维对象的数量或范围。二者的关系为,内涵越大越丰富,相应的外延则越小,反之亦然。人们在对世界的认识中,将事物、事件或事实划分成类和属,并确定它们之间的包含关系和排斥关系。根据逻辑学中“类层级结构”思维:任何事物都是世界事物结构中某一层级某一类中的一个单体。人脑在按照内涵、外延的“亲和性”层级归属进行分类建构的同时,还要依据它们之间历史运动的关系。
森林生态系统碳通量表示生态系统中单位时间单位面积上碳增减的数量(PgC·a-1)。森林生态系统碳循环过程由两部分组成: 光合作用将CO2固定进入生态系统;自养呼吸将CO2释放进入大气。在森林生态系统中,地面与大气间的碳通量成分由空气中的微量成分CO2和痕量成分CO、CH4等组成,在测量的过程中发现痕量成分CO、CH4等与CO2存在数量级上的差距,且大气中痕量成分的含量是默认不变的。因此,本研究以CO2浓度作为碳通量的研究对象,将痕量成分忽略。
影响CO2浓度的环境因素很多。研究环境参数与CO2浓度的相关性有利于模型参数的选取分析。本研究首先对CO2浓度与各环境参数进行了相关性分析。
2.3 反演模型建立
本研究将基于传统BP神经网络和基于GA-BP神经网络的CO2浓度反演方法进行对比分析。GA-BP模型克服了传统基于BP神经网络反演CO2浓度模型(简称BP模型)的一些不足,其通过种群初始化、计算适应度、选择、交叉、变异、搜索等操作得到最优的初始化权值和阈值传递给BP神经网络,从而纠正神经网络易陷入局部极小值和网络收敛速度慢的缺点,同时可以提高模型的精确度。
GA-BP神经网络的结构分为输入层、隐含层和输出层。输入层的节点数量取决于输入参数的种类。隐含层的节点数量决定了神经网络的训练时间和预测精度,其节点数的选取首先根据公式(1)~(3)确定范围,再利用试凑法进一步选择,最后确定最佳的节点个数。
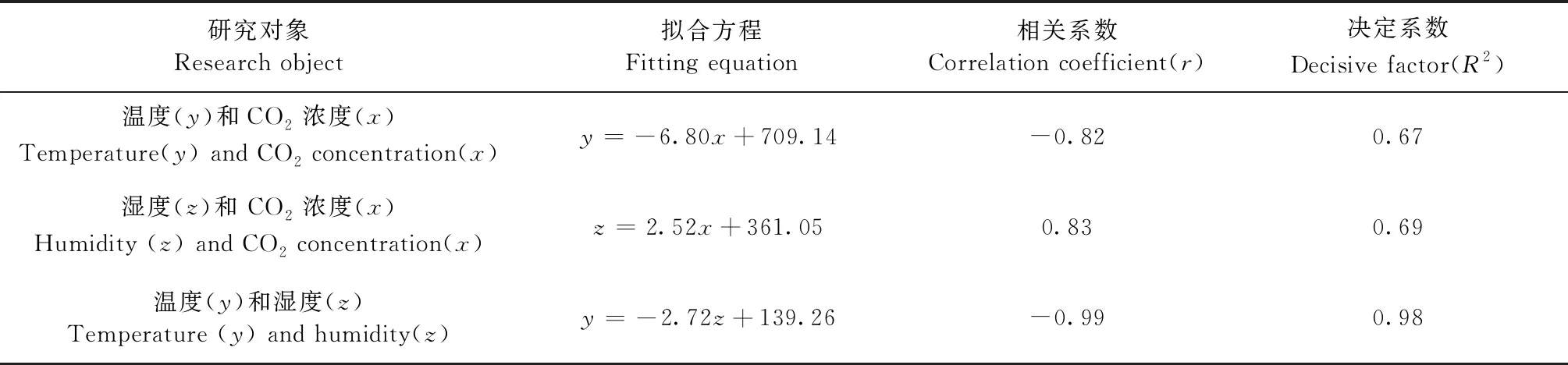
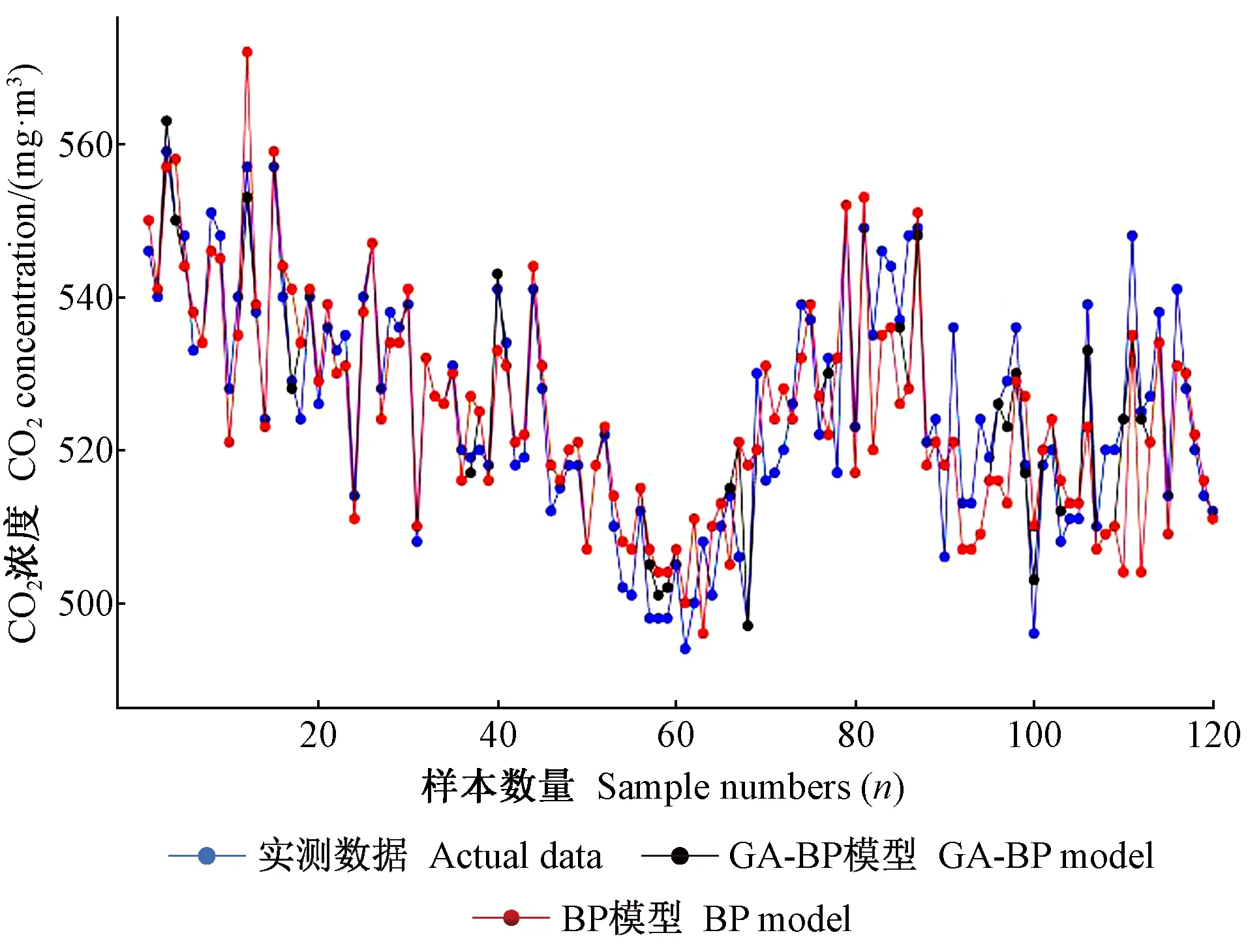
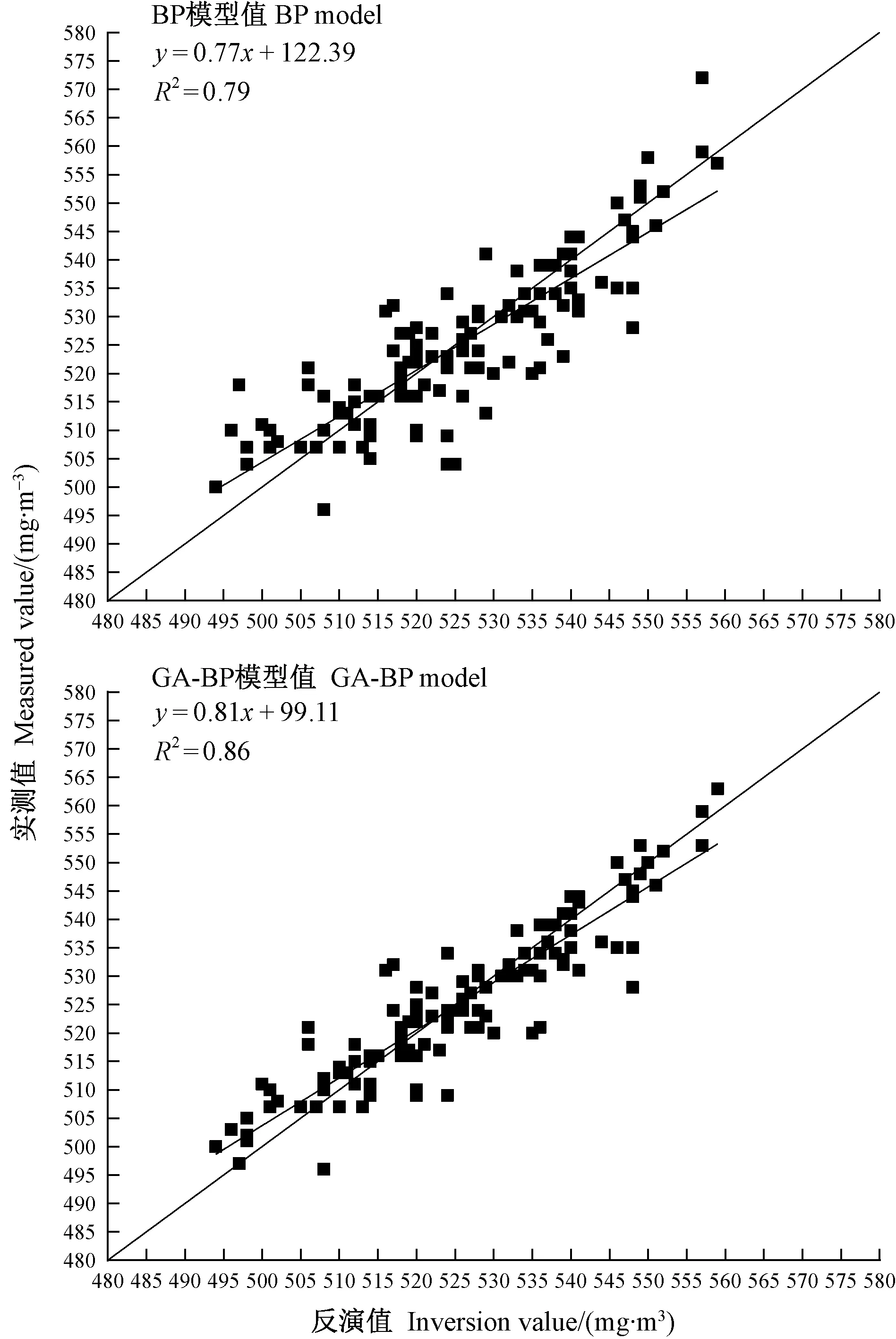
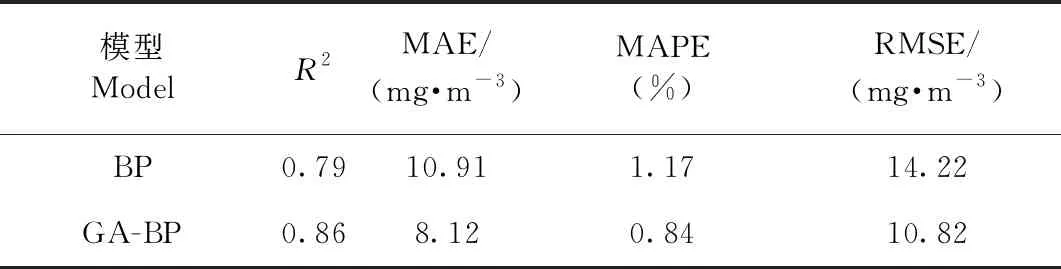
l (1) (2) l=log2n。 (3) 式中:n为输入层节点数;l为隐含层节点数;m为输出层节点数; a为0~10之间的常数。 通过遗传算法的选择、交叉和变异操作,在神经网络的初始权值和阈值种群中进行全局搜索,找到适应度最优的权值和阈值传递给BP神经网络,最终通过BP神经网络算法局部寻优计算得到最优解。算法流程如下。 1) 种群初始化: 将输入参数的原始数据转换成二进制编码,随机组成初始种群。 2) 适应度寻优: 根据个体得到BP神经网络的初始权值和阈值,传递进入BP神经网络进行模型训练,按误差绝对值大小寻找最优适应度的函数值。 3) 训练: 经过适应度寻优、选择、交叉、变异的多次迭代,最终满足程序终止条件,模型训练完成。 4) 数据输出: 将输入参数带入模型,输出具有最大适应度的反演数据作为结果。 建模时,每组试验在相同条件下重复10次,试验结果取平均值。另外,由于影响碳通量的各环境参数之间的数值范围和单位相差很大,这对模型训练和预测效果会产生显著影响。因此,在试验前对数据进行归一化处理。 为了验证模型的稳定性和精度,本研究采用决定系数(R2)、平均绝对误差(mean absolute error,MAE)、均方根误差(root mean square error,RMSE)、平均百分比误差(mean absolute percentage error,MAPE)和标准偏差(standard deviation,StdDev)这5个指标对模型进行评价。模型的决定系数R2越大,MAE、MAPE和RMSE值越小,模型StdDev与实测值的StdDev越接近,说明模型的反演准确度越高。相关公式如下: (4) (5) (6) (7) (8) 所采集的气象因子中,温度和湿度对CO2浓度具有明显的强相关性,同时湿度与CO2浓度之间的相关性略强于温度与CO2浓度之间的相关性。温度、湿度与CO2浓度间的相关性分析结果见表1。 温度与 CO2浓度之间呈负相关,相关系数r为-0.82,决定系数R2为0.67; 湿度与 CO2浓度之间呈正相关,r为0.83,R2为0.69; 温度和湿度之间呈强负相关,r达到-0.99,R2为0.98。 表1 温度、湿度和CO2浓度间的相关性 由图2可知,BP模型能够有效反演CO2浓度,BP模型的反演值与实测值变化趋势基本相符,但两者间的某些样本数据存在明显误差。相较于前者,基于GA-BP模型的反演结果与实测数据的误差明显减小。 2种反演模型的比较结果见表2,实测值的标准偏差为26.99 mg·m-3,BP模型反演结果的标准偏差是24.71 mg·m-3,而GA-BP模型反演结果的标准偏差为26.51 mg·m-3,GA-BP模型反演结果的标准偏差与实测值的误差更小。综上所述,GA-BP模型反演结果与实测值的离散程度更接近。 图2 2种模型反演值与实测值对比 对BP模型和GA-BP模型的反演结果进行交叉验证,结果如图3所示。BP模型的R2为0.79,表明BP模型对CO2浓度的反演结果可靠,反演结果能整体上表现出CO2浓度的变化趋势。但是,其反演结果与实测值之间存在较大误差,BP模型反演结果的不稳定。而GA-BP模型的R2相较于BP模型有显著提高,R2从0.79上升到0.86,较优化前提高了6%。GA-BP模型的拟合效果更好,反演值与实测值的相关性更强,利用GA-BP模型对CO2浓度反演的结果更接近实测结果。 表2 CO2浓度实测值及BP模型和GA-BP模型反演结果 图3 BP模型和GA-BP模型的交叉验证结果 BP模型和GA-BP模型反演验证结果如表3所示: GA-BP模型反演结果的MAE为8.12 mg·m-3,较BP模型反演结果的10.91 mg·m-3低2.79 mg·m-3; 前者的MEAP为0.84%,而后者的MAPE为1.17%; 同时,前者将RMSE从14.22 mg·m-3优化到10.82 mg·m-3,这表明GA-BP模型的反演值与实测值之间的偏差范围小于BP模型,GA-BP模型反演结果的准确性更高。通过比较模型的5种评价指标发现,GA-BP模型相较BP模型在CO2浓度反演上具有更优的表现。 表3 BP模型和GA-BP模型反演结果验证 影响CO2浓度反演结果的因素主要有2个: 一是算法本身导致的误差,主要是建模时数据采集不完整或模型参数选择不当产生的误差(王晓辉等, 2021); 二是相关气象因子选择的遗漏导致的误差(范德成等, 2021)。本研究提出基于GA-BP的CO2浓度反演模型首先通过GA优化得到最优的网络初始权值和阈值,再利用试凑法确定最优的网络节点数,有效提高了反演模型的精度,减少了误差。在控制样本选择误差方面,与王楷等(2014)利用草原环境因子对碳含量进行预测相比,本研究选取10—11月份的成熟雷竹林作为研究对象,充分利用了竹林生态环境的稳定性,满足GA-BP模型需要稳定可靠的气象因子作为输入的建模条件,减少了可能存在的选择误差。本试验结果表明,实测值与反演值的百分比误差为0.84%,说明GA-BP模型的CO2浓度反演效果优良。 本研究提出GA-BP神经网络反演算法不仅适用于CO2浓度的反演,根据其模型特点也可以推广至生态环境监测领域其他环境参数的反演,这既可以简化系统也可以降低相关监测系统的硬件成本。但本研究依然存在一些局限性,如受到试验环境、仪器精度和时间等限制,也未考虑到其他碳汇相关因子的影响,在后续研究中,还需考虑时空、研究区内灌木和草本的生物量等因素的影响。 利用竹林气象因子采集系统可获取相关气象数据;基于CO2浓度与温湿度等气象因子之间的相关性,本研究提出的基于GA-BP神经网络的CO2浓度反演模型能够有效反演该研究区的CO2浓度。
2.4 模型评价指标
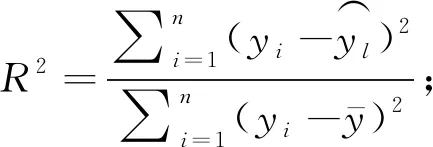
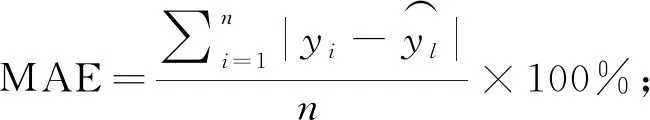
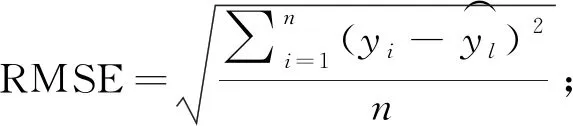
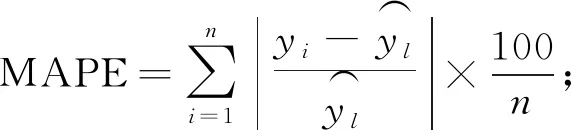
3 结果与分析
3.1 环境因子与CO2浓度相关性分析
3.2 GA-BP反演结果分析
3.3 模型评价分析

4 讨论
5 结论
猜你喜欢
探测与控制学报(2022年4期)2022-08-30
中等数学(2022年5期)2022-08-29
宁夏大学学报(自然科学版)(2022年2期)2022-07-18
北京大学学报(自然科学版)(2022年3期)2022-06-17
农业灾害研究(2022年1期)2022-05-07
环境(2021年5期)2021-06-20
中国房地产业·下旬(2020年12期)2020-01-11
大气科学学报(2018年4期)2018-09-10
学校教育研究(2018年8期)2018-07-09
地震研究(2017年3期)2017-11-06
