
光学遥感图像舰船目标视觉显著性检测方法
2022-05-06 13:32曾禹龙
电子设计工程 2022年8期
曾禹龙
(上海交通大学,上海 200240)
视觉关注机制是人类的重要感知机制之一,人们在观察图像时,通常会下意识关注图像中的特殊区域,被关注的区域称之为显著性区域。图像显著性区域是指图片中引人注目的区域或比较重要的区域。图像的显著性检测即利用计算机模拟人类的视觉关注机制,自动定位图像或场景的重要目标区域。目前显著性检测的研究成果广泛应用于各种图像分析和理解任务[1],包括目标检测[2]、基于内容的图像检索[3]和图像/视频自适应压缩[4]、机器人等应用领域[5]。
在过去几十年里,已经发展了众多用于显著性区域检测的方法。这些方法通常分为自底向上[6-7]和自顶向下[8-9]两类。近年来,众多深度学习架构也被提出用于显著性检测。这些深度学习解决方案通常能获得比传统自下而上的刺激驱动模型更优的性能[10]。Kummerer 等人使用卷积神经网络(Convolutional Neural Network,CNN)AlexNet 进行特征表示,经过训练可以将120 万幅图像分成1 000 个不同类别。Kummerer[11]还强调了在CNNs 的深层网络中,特征表示对于显著性图预测的重要性。Liu 等人提出了多分辨CNN,用于预测人眼注视点[12]。刘畅等人提出了一种全卷积神经网络,通过端到端训练预测像素显著值[13]。Huang 等人提出的SALICON net,将CNNs的粗特征与细特征相结合,获取多尺度的显著性[14]。
针对遥感图像目标显著性检测,文献[15]提出了基于稀疏表示的显著性检测方法。文献[16]提出一种双流的LVNet 深度网络架构,用于遥感图像显著性检测,并采用手工像素级标注构建遥感图像显著性的检测数据集。但总体而言,遥感图像中目标显著性检测的工作相对较少,大多采用自底向上的方法。显著性检测是模拟人的视觉关注机制,遥感图像目标显著性检测中仍缺少这种直接反映人的视觉关注机制的数据集。为此,文中针对舰船检测场景,采用基于被测的眼动数据构建了一套遥感图像目标显著性数据集。该数据集包含2 000 张图像,每张图像的大小为2 048×2 048 像素。通过眼动跟踪设备记录注视数据,生成显著性图作为真值。同时,提出一种轻量级多尺度卷积神经网络,实现舰船目标显著性图的快速生成。
1 理论与技术
1.1 显著性检测的卷积神经网络和数据集生成
卷积神经网络在目标识别、边缘检测、语义分割等图像任务中的出色表现给显著性目标检测提供了新的思路,并在文献[17-18]展示出了大幅度的提升效果。
文中利用桌面眼动仪来获取被测的眼动信号,作为目标图片的显著性真值。如图1 所示,眼动仪器附加在工作屏幕的下部,记录被试的眼动信号工作状态包括注视位置、凝视、目光路径、瞳孔直径等信息。

图1 眼动信号采集场景
实验中使用的眼动仪为TobiiProX3-120 台式眼动仪,采样率为120 Hz。眼动仪扫描的内部算法将每个数据点分为注视、一瞥和丢失3 种事件类型。在实验过程中,文中只提取标记为注视点的样本点。每个注视都有两个属性:注视点坐标和该位置的注视时间。眼动数据处理结果如图2 所示。

图2 眼动数据处理结果图
如图2(b)所示,根据已有的边界框(Boundingbox)标注信息可以计算出每次固定是否有效,即目标对象是否被注视。如图2(c)所示,圆心表示注视点坐标,半径表示该点注视时间的长度,按照注视点在图像中产生时间的先后顺序,可以得到每个被试对每幅图像的扫描路径。如图2 (d)所示,其可以根据被试注视点绘制眼动热力图,从而更直观地显示被试感兴趣的区域。
1.2 基于Deeplab网络提出的显著性区域提取模型
Deeplab是语义分割里比较流行的网络。为了避免池化引起的信息丢失问题,DeepLab V1 中提出了空洞卷积的方式[19-20],这样可以在增大感受野的同时不增加参数量,并保证信息不丢失。为了进一步优化分割精度,还使用了条件随机场。DeepLab V2[21]在之前的基础上,移除部分池化操作,利用不同膨胀因子的空洞卷积融合多尺度信息。DeepLab V3[22]通过串联不同膨胀率的空洞卷积或并行不同膨胀率的空洞卷积,来获取更多上下文信息。DeepLab V3+[23]将原DeepLab V3 当作编码器,添加解码器得到新的模型,如图3 所示。
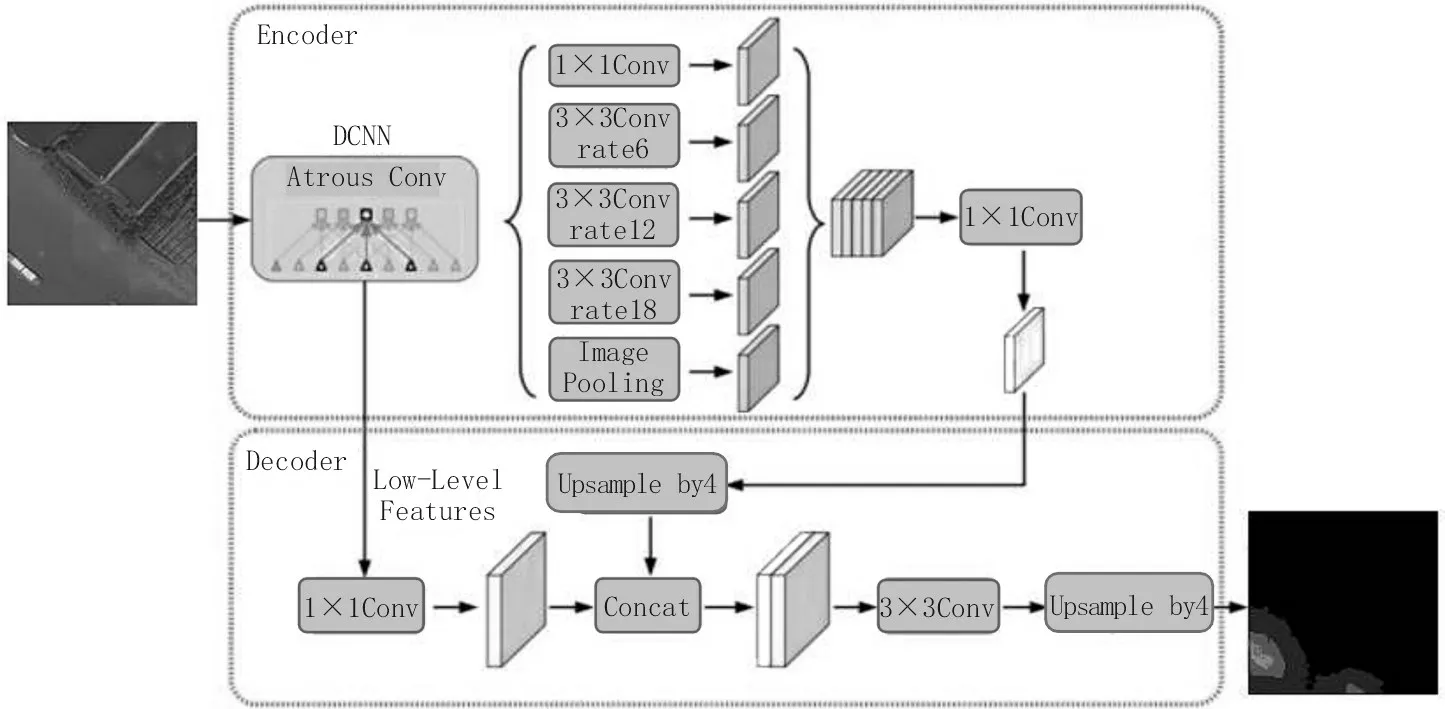
图3 DeeplabV3+架构
解码器是先把编码器的结果上采样4 倍,然后与DCNN 中下采样前的特征合并,再进行3×3 的卷积,最终上采样4 倍得到最终结果。其骨干网络采用更深的Xception 结构,以提高实验运行的速度和稳定性。
在Deeplab V3+的基础上,提出用于生成舰船目标显著性图的模型架构,如图4 所示。因为眼动热力图只表明目标大致位置,而不能完备地显示目标显著性区域。文中将眼动数据作为弱监督信号来训练网络,并在中间层输出忽略网络的高层部分,提取局部显著性信息生成热点图。这是因为网络高层特征只反映了注视信息,而中层特征蕴含了对注视预测起作用的目标区域信息,同时该方法还可以有效避免过拟合眼动噪声。眼动仪在通过追踪人眼注视位置标注图像时容易产生一些异常值,文中提出的方法能更优地挖掘目标显著性特征,减少眼动噪声在显著性图预测中的影响[24-25]。
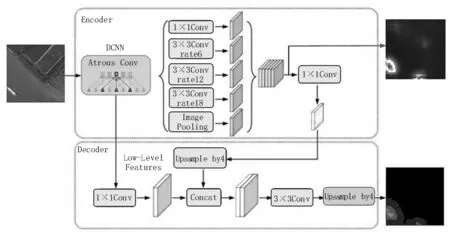
图4 提出的网络架构
2 结果与讨论
2.1 数据集与训练方案
数据集中的光学遥感图像来自谷歌地球,分辨率为0.7 m,大小约为2 000×2 000像素,通过TobiiProX3-120台式眼动仪来跟踪受试者在一定时间段内眼睛的注意数据,得到眼动图像。目标主要为舰船,训练集为20 000 张,测试集为1 000 张。在实验中,文中对数据进行了裁剪和扩展。数据被划分为512×512的图像块,每个图像块对应一个显著性热点图。为了扩展数据,通过镜像和旋转得到扩展后的图像。最终的数据集中,训练集有20 000 张图像,验证集有9 889 张图像。
文中所提的深度显著性网络使用TensorFlow 库进行实现。在训练时,编码器网络的滤波器权重从Xception65 初始化,Xception65 在coco 数据 库上进行训练,用于分类任务。对眼动数据集的20 000 张图像进行网络训练,在每次迭代中将batch 大小设为4张,初始化学习率为0.000 1,采取的学习率衰减策略为poly,如图5所示。模型在Tesla V100 GPU和32 GB内存的PC 上达到了0.1 张/秒的处理速度。
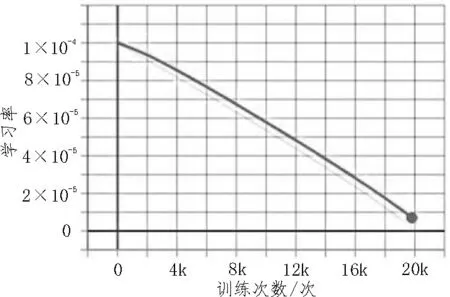
图5 学习率衰减策略
2.2 评价指标
目前有几种方法可以衡量模型预测和人眼注视之间的一致性。使用EMD(Earth Move Distance)和CC(Correction Coefficient)两种不同的度量来评价所提的模型,文中用G表示显著性图的真值,用S表示显著性图的预测结果。
1)EMD。EMD 测量的是两个二维图像G和S之间的差距。其是将估计的显著性图像S的概率分布转化为地面真值图像G概率分布的最小代价,因此低的EMD 对应高质量的显著性地图。
2)CC。CC 是一种统计方法,通常用来度量两个变量的相关程度。CC 可以将显著性与真值图G和S理解为随机变量,测量其之间的线性关系:cov(S,G)是S和G的协方差,取值范围为-1~+1。CC 接近+1 的值表示两幅图像完全对齐。
2.3 实验结果与讨论
图6 显示了部分实验结果,第一列是输入图像,第二列是将眼动数据生成的热力图作为真值的结果,第三列是Deeplab 实验结果,第四列是深度监督模型(DVA)的[19]实验结果,第五列是提出模型的预测结果。DVA 是一种基于CNN 的光学图像显著性预测模型,其架构来源于UNET,从网络深层提取全局显著性信息、从网络浅层获取局部显著性信息,并将所有信息合并到网络的最后一层,得到最终的显著性图像。从第二列眼动数据生成的热力图可以看出眼动数据热力图只表明了目标的大致位置信息,一方面存在较大的噪声,且不能直接显示目标的轮廓区域。从第三、四列的结果来看,将DeepLab 和DVA 方法直接过拟合到注视热点图数据,而不能预测目标本身的显著图,而文中提出的方法能够较好地恢复目标的显著性区域。因此从表1 评价指标来看,DVA 对注视点具有比较好的预测能力,所以导致DVA 的CC 指标明显优于所提出的模型,反而不能很好地预测目标显著性区域。
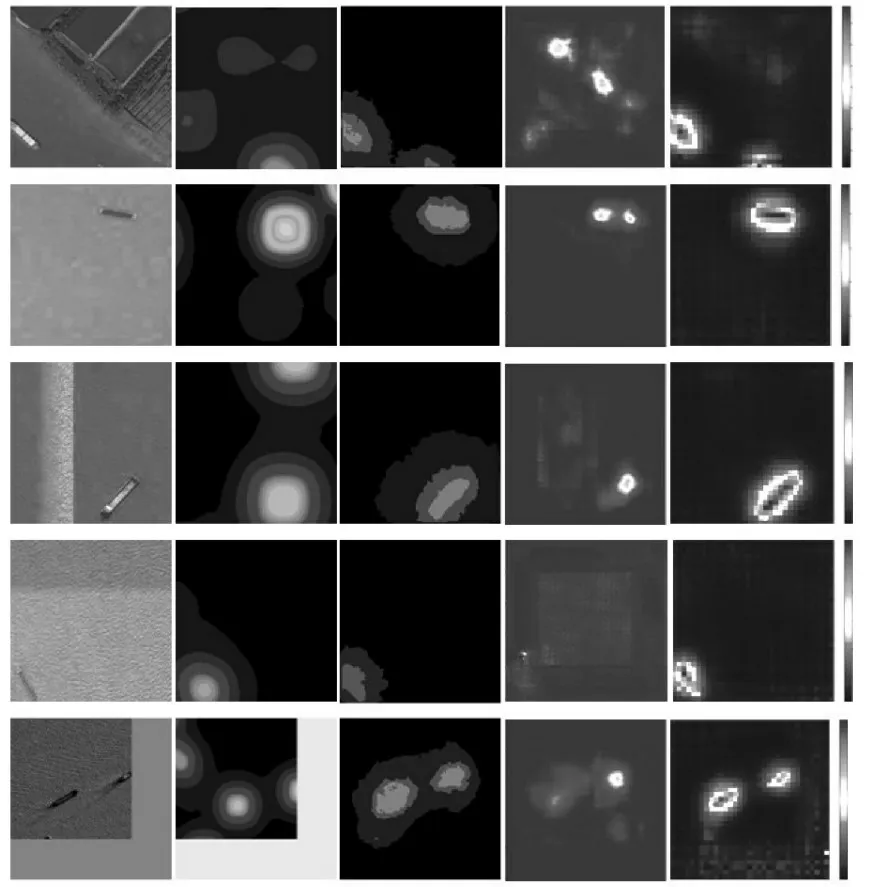
图6 实验结果

表1 文中方法和DVA方法的对比
3 结论
文中提出了一种基于Deeplab V3+多尺度全卷积的显著性检测方法,采用膨胀卷积增加感受野,获取多尺度信息,解决遥感图像舰船目标显著性区域与背景不连续、边界模糊等问题。文中提出的方法利用编码层的网络浅层特征输出显著性图,不仅增强了舰船目标显著性检测的算法精度,且减少了模型的参数量。在后续工作中,将继续优化网络结构,提高检测精度。
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
智能建筑与智慧城市(2022年9期)2022-09-28
汽车实用技术(2022年7期)2022-04-20
载人航天(2021年5期)2021-11-20
兰州理工大学学报(2021年5期)2021-11-02
大自然探索(2019年7期)2019-12-13
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
体育时空(2017年6期)2017-07-14
天津体育学院学报(2016年3期)2016-12-18
