
基于三参数Logistic模型Gibbs抽样方法的敏感度分析
2022-05-05 06:21:38付志慧
沈阳师范大学学报(自然科学版) 2022年1期
付志慧, 周 末
(沈阳师范大学 数学与系统科学学院, 沈阳 110034)
0 引 言
项目反应理论(item response theory, IRT)[1]是在经典测量理论受到了局限性限制的背景下逐渐发展起来的一种新的现代测量理论[2]。模型参数估计问题是IRT中比较重要的部分,当前主要采用的估计方法是期望最大化(expectation maximization,EM)算法[3-5]和马尔可夫链蒙特卡罗(Markov chain Monte Carlo, MCMC)算法[6],最简单的MCMC算法之一是Gibbs抽样[7-8],相比于其它算法具有几何遍历性和收敛速度快等优点。Albert(1992)[9]首次将Gibbs抽样应用于IRT模型中。Fu等(2009)[10]基于增加数据的Gibbs抽样方法,提出了一种估计多维3PL模型的贝叶斯方法。然而,针对3PL模型,关于项目参数的先验分布对该抽样方法的估计效果的影响研究甚少。本文基于增加数据的Gibbs抽样方法针对3PL模型讨论了项目参数取不同的先验分布时对估计结果的影响,并进一步研究了不同的样本容量(N)及不同的测试长度(n)下估计结果的差异。
1 3PL模型介绍和先验假设
假设N个被试,n个题目,yij表示第j个被试回答第i个题目的得分,当回答正确时等于1,回答错误时等于0。令pij为第j个被试对于第i个题目正确作答的概率,3PL模型的表达式为
其中:i=1,2,…,n;j=1,2,…,N;θj为第j个被试的能力参数;ai为题目i的区分度参数;bi为题目i的难度参数;ci为题目i的猜测度参数,是模型的下渐近线。令
则有

(1)

2 引进潜变量和Gibbs抽样过程
Gibbs抽样是常用的MCMC方法之一,主要适用于模型联合分布比较复杂而无法直接得出每个参数后验分布的情形。在本文研究的3PL模型中,对于反应数据yij,通过引进2个互相独立的随机变量rij和uij,其中rij~Binomial(1,ci),uij~Uniform(0,1),从而模型各个参数的满条件分布都简单易得。具体地,令

(2)
又由
可把式(2)取期望即得到式(1)。令ξ=(θj,ai,bi,ci),随着潜变量rij和uij的引入,(ξ,rij,uij)的联合后验密度为
由此可得出uij,rij,ci,bi,θj,ai的满条件分布(具体过程参见附录,详见[12])。
3 模拟实验
按照上述抽样过程,在本节模拟分析中考虑以下3个影响因素,即样本容量N(N=1 000,2 000,5 000),测试长度n(n=10,20,40),项目参数的先验分布(假定共2×3=6种先验,详见表1),
总计3×
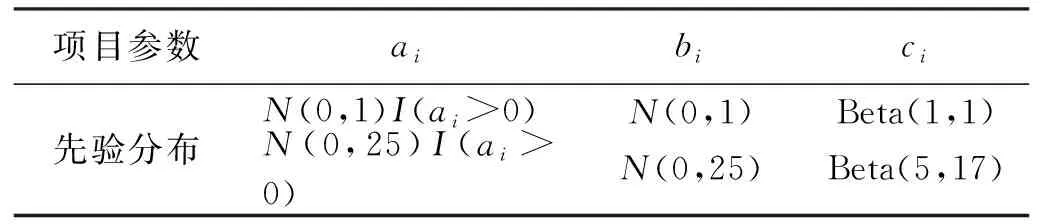
表1 项目参数的先验分布Table 1 Prior distribution of item parameters
3×6=54种模拟条件。进一步,能力参数(θ)和难度参数(b)的真值从标准正态分布N(0,1)中产生,区分度参数(a)的真值从对数正态分布中产生,即lna~N(0,0.2),猜测度参数(c)的真值从贝塔分布中产生,即c~Beta(8,32)。上述每种情形重复进行R=20次实验。
在估计结果汇报中,使用均方根误差(rootmeansquarederror,RMSE)和偏差(bias)评估项目参数估计的准确性[13]。RMSE和bias的定义如下:
其中:τ为项目参数(ai,bi,ci)的真值;tr为第r(r=1,…,R)次重复实验的估计值。

表2 区分度参数(a)的RMSE和biasTable 2 RMSE and bias of discrimination parameter (a)
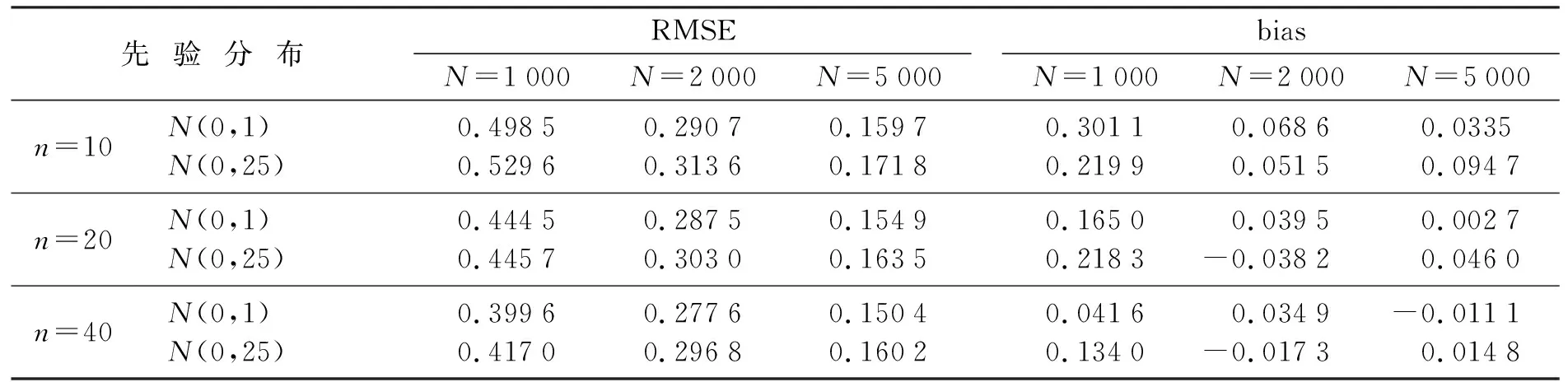
表3 难度参数(b)的RMSE和biasTable 3 RMSE and bias of difficulty parameter (b)
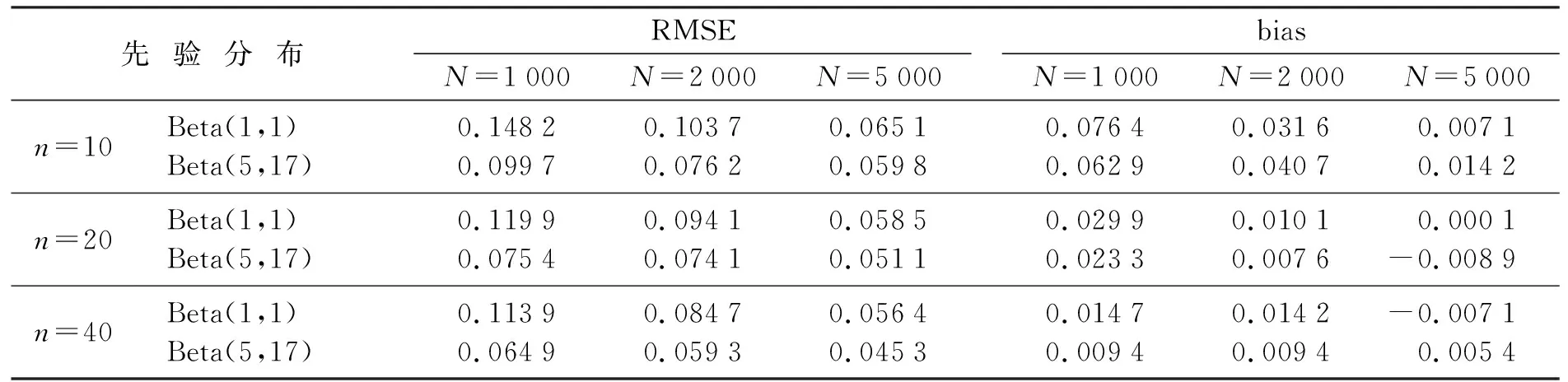
表4 猜测度参数(c)的RMSE和biasTable 4 RMSE and bias of guessing parameter (c)
4 结果分析
1) 对于题目区分度参数(a),随着样本容量N的增加,RMSE的值逐渐减小。例如:当先验分布为N(0,1)I(a>0),测试长度n=10时,样本容量N=(1 000,2 000,5 000),对应的RMSE值为(0.306 9,0.231 2,0.126 1),同时,随着测试长度n的增加,RMSE的值也逐渐减小。例如:当先验分布为N(0,1)I(a>0),样本容量N=1 000时,测试长度n=(10,20,40),对应的RMSE值为(0.306 9,0,291 4,0.243 0)。
2) 对于题目难度参数(b),随着样本容量N的增加,RMSE的值也逐渐减小。例如:当先验分布为N(0,1),测试长度n=20时,样本容量N=(1 000,2 000,5 000),对应的RMSE值为(0.444 5,0.287 5,0.154 9),同时,随着测试长度n的增加,RMSE的值也逐渐减小。例如:当先验分布为N(0,1),样本容量N=2 000时,测试长度n=(10,20,40),对应的RMSE值为(0.290 7,0.287 5,0.277 6)。
3) 同样地,对于题目猜测度参数(c),随着样本容量N的增加,RMSE的值也逐渐减小。例如:当先验分布为Beta(5,17),测试长度n=40时,样本容量N=(1 000,2 000,5 000),对应的RMSE值为(0.064 9,0.059 3,0.045 3),同时,随着测试长度n的增加,RMSE的值也逐渐减小。例如:当先验分布为Beta(5,17),样本容量N=5 000时,测试长度n=(10,20,40),对应的RMSE值为(0.059 8,0.051 1,0.045 3)。
4) 在不同的先验假定下,随着先验方差的增大,对应参数的RMSE值逐渐增加。例如:对于题目区分度参数(a),当测试长度n=10,样本容量N=1 000时,取先验为N(0,1)I(a>0)的RMSE值为0.306 9,取先验为N(0,25)I(a>0)的RMSE值为0.423 9;对于题目难度参数(b),当测试长度n=20,样本容量N=2 000时,取先验为N(0,1)的RMSE值为0.287 5,取先验为N(0,25)的RMSE值为0.303 0;同样地,对于题目猜测度参数(c),当测试长度n=40,样本容量N=5 000时,取先验为Beta(5,17)的RMSE值为0.045 3,取先验为Beta(1,1)的RMSE值为0.056 4。
5) 对于题目区分度参数(a),bias的绝对值最大为0.143 9,最小为0.000 1;对于题目难度参数(b),bias的绝对值最大为0.301 1,最小为0.002 7;对于题目猜测度参数(c),bias的绝对值最大为0.076 4,最小为0.000 1。在本文的模拟设置下,得出的这些估计结果都在可接受的范围内。
5 结 语
本文基于增加数据的Gibbs抽样方法针对3PL模型探讨了在不同模拟设置条件下的估计效果。模拟实验结果表明,随着样本容量或测试长度的增加,估计结果的准确性将会有所提高,并且对于项目参数的先验分布采用方差较小的先验时,获得的估计结果比较准确。本文只考虑了样本容量为1 000,2 000和5 000的情况,对于小样本(比如500)和大样本(比如10 000)的情况还有待研究。进一步的,这种数据增加的Gibbs抽样方法也可以推广到4PL模型[14]和多级评分模型[15]中。
附录
在给定yij,rij,ξ下,uij的满条件分布为
在给定yij,uij,ξ下,rij的满条件分布为
在给定rij下,ci的满条件分布为
给定其他所有参数和uij,rij,yij下,bi的满条件分布为
其中

同理,θj的满条件分布为

(a5)
其中
给定其他所有参数和uij,rij,yij下,ai的满条件分布为

(a6)
其中
具体的Gibbs抽样步骤为从(a1)~(a6)中依次抽取uij,rij,ci,bi,θj,ai。
猜你喜欢
筑路机械与施工机械化(2020年7期)2020-08-20 04:24:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
中国校外教育(2019年12期)2019-04-15 11:14:34
江淮论坛(2018年4期)2018-08-24 01:22:30
自动化学报(2017年5期)2017-05-14 06:20:44
福建中学数学(2016年5期)2016-11-29 02:45:52
心理学探新(2015年3期)2015-12-27 06:25:14
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
测绘通报(2013年2期)2013-12-11 07:27:44
