
基于音视一致性的音视人眼关注点检测
2022-05-05 13:38于小雨
计算机与现代化 2022年4期
袁 梦,于小雨
(青岛大学计算机科学技术学院,山东 青岛 266071)
0 引 言
人类生活在多模态空间中并拥有多模态感知能力[1],视觉系统和听觉系统对周围事物具有强大的信息感知和处理能力。视觉系统对场景中呈现出的颜色、大小、形状、位置等特性进行处理。听觉系统对所感知声音的响度、音调、音色等特性进行处理。目前人工智能在计算机视觉和自然语言处理领域取得了显著的研究成果,如显著性检测[2]、目标跟踪[3]、语音识别[4]等。人眼关注点检测是显著性检测的一个分支,旨在让计算机通过智能算法模拟人类视觉系统的注意力机制,提取图像中的显著性位置(即人类感兴趣的位置),如图1所示。面对复杂的环境,视听的巧妙结合可以使人类迅速把注意力分配到感兴趣的区域。

图1 人眼关注点检测图
视觉注意是人类视觉系统的一种智能机制,它优先选择视觉场景中最吸引人的位置。基于图像数据的人眼关注点检测方法研究工作起步较早,图片的处理主要是从空间信息这一线索展开。其主要包括早期手工计算的自底向上方法(Bottom-up)以及近期主流的自顶向下方法(Top-down)。基于视频数据的人眼关注点检测方法不同于仅包含空间信息的图像数据,视频数据蕴含着内容更为丰富的时空信息,因而视频显著性检测更具有挑战性。
目前音视结合的人眼关注点检测研究受到的关注较少。尽管已有证据[5-6]表明听觉和视觉线索之间的强相关性以及它们的联合对注意力分配的重要贡献,但迄今为止,大多数人眼关注点检测模型忽略了音频线索,严重依赖时空线索作为检测的信息来源,这不利于计算机模拟人类真实的注意力机制。而视频中的音频不全是与视觉内容相关的信息,为能够充分利用与视觉信息一致的音频信息,本文提出基于音视一致性的音视人眼关注点检测模型,在现有主流音视人眼关注点检测网络[5-6]中加入音视一致性模型,选择音视一致性的特征进行融合。该算法相关代码已开源于https://github.com/GHyuanmeng/AVCN。
1 相关工作
1.1 基于传统学习方式的音视人眼关注点检测
传统方法[7-10]通常以手工方式计算音视频特征。文献[7]根据音频的语义信息检测吸引注意力的说话面孔,计算人脸的音频能量和运动位移之间的同步程度,同步性得分高的面孔将被选为说话人的面孔。文献[8-9]通过对多模态分析定位发声的运动对象,生成音频注意图。然后计算视觉模态的空间和时间注意图。最后融合音频、空间和时间注意图生成最终的视听显著图。文献[10]创建一个自底向上的二维视听显著性模型,用汉明窗对过去和未来的音频信息分配适当的权重,尝试了多种特征提取方式以及融合方式并在6个音视数据集上进行验证。
1.2 基于深度学习方式的音视人眼关注点检测
传统手工方式提取特征泛化能力差,而深度学习是由大数据驱动提取特征,鲁棒性好。现有主流人眼关注点检测方法的网络模型整体结构如图2所示,由提取音视频特征、特征融合、人眼关注点预测3部分组成。文献[11]首次尝试采用一种简单的encoder-decoder网络结构分别对音频和视觉信息提取特征,且音、视频分支具有相同的网络结构。最后把2模态的特征直接进行级联操作得到最终的显著性预测。但音频具有其独特的信息特征,与二维图片所展示的直观性信息存在着区别,应该探索更有效且符合音频信息特征的处理方式。对于视听模型来说,尝试更复杂的网络结构仍然有很大的潜力,这需要有大量的视听眼球追踪数据库支持。文献[5]提出时空音视显著性网络(STAViS),该模型是在时空信息的基础之上加入了音频信息,采用多模态网络形式对提取的多尺度视觉特征与音视定位特征图进行融合,获得最终的显著图。文献[6]提出的音视人眼关注点检测模型(AViNet)采用全卷积网络形式,该网络是在编码器阶段把视觉的动作特征与音频分支对物体和场景分类的特征融合,在解码器阶段通过三线插值的融合方式和3D卷积来预测显著性关注点。该方法使用了大量的数据集来训练。

图2 主流人眼关注点检测方法结构图
现有主流方法对提取的音视特征进行融合,并未考虑音视特征是否一致。当音视特征不一致时,仍进行融合,音频特征可能会对最终的结果预测产生消极的影响。针对此问题,本文提出一种音视一致性判断网络。在现有方法STAViS和AViNet网络中加入本文提出的音视一致性网络模型(AVCN),对STAViS和AViNet方法中的特征进行策略性输出。实验数据显示加入AVCN的结果优于STAViS和AViNet方法的原结果。
2 AVCN方法
2.1 网络结构
本文提出的音视一致性网络模型如图3所示,音视一致性判断网络由音频网络分支和视觉网络分支2部分组成。音频特征提取分支采用经典的SoundNet网络[12],使用1D卷积直接对原始的一维音频信息进行特征提取。视觉网络分支使用3D卷积神经网络提取视觉特征。为使音视特征融合,本文对提取的音频特征进行2D卷积操作,在视觉网络分支平均池化后进行降维操作,使用PyTorch深度学习框架中自带的维度压缩函数将三维视觉特征变为二维特征,为了简化网络结构,未在图3中体现。音视特征直接级联后进行2D卷积操作,最后输入全连接层进行二分类得到是否一致性的判断结果。

图3 AVCN网络结构图
2.2 策略性输出结果
根据AVCN网络的二值判断结果:当音视一致时输出音视融合的特征(AV);反之,则输出视觉占主导的特征。
为进一步探究不同融合方式对最后输出结果的影响,本文不单单把V的结果作为音视不一致时的特征输出,还对比了音视特征加视觉特征以及音视特征与视觉特征逐像素相乘的结果分别作为音视不一致的输出。音视不一致所输出视觉占主导特征的3种情况如下所示:
1)直接输出视觉特征(V)作为最后的检测结果,即丢弃音频特征。在分类结果有误的情况下,这种方式会降低预测结果的性能。
2)音视融合特征加视觉特征,如公式(1)所示:
VL=AV+V
(1)
其中,AV是由单独音频特征A和视觉特征V融合的结果,VL为音视不一致时输出视觉占主导的特征。
3)为了验证加入音视一致性模型的可靠性,本文又加入了一组实验,即在二者一致时,仍将AV的特征作为最终的结果,但二者不一致时,输出的人眼关注点检测图,如公式(2)所示:
VL=AV⊙V
(2)
其中,⊙表示逐元素的Hadamard乘积。
3 实验及分析
3.1 实验细节
实验中音视一致性网络的视觉分支基网络是3D ResNet-18,音频分支是SoundNet的前7层并加载其预训练模型。本文使用STAViS方法中第1种训练集和测试集的划分方案,每次选取连续的16帧作为视觉分支的输入,训练前统一将图片裁剪为112×112大小以及对音频信息重采样为22050。对于训练,本文采用的优化器是随机梯度下降的,其参数为0.9,学习率为0.0001。本文的实验环境均在RTX2080 Ti GPU工作站上使用Python3.6语言以PyTorch1.6深度学习框架实现。
3.2 数据集
深度学习离不开大数据的支持,数据集在算法的比较和结果的性能验证方面是至关重要的。本文在现有公开的6个数据集上进行训练和测试,如表1所示,6个数据集分别是DIEM[13]、AVAD[14]、Coutrot1[15]、Coutrot2[16]、SumMe[17]和ETMD[18]。DIEM数据集中有84个视频片段,包括广告、纪录片、新闻剪辑等内容。AVAD在视听环境条件下收集了45段5~10 s时长的短片段眼球追踪数据,其涵盖了演讲、对话、乐器演奏等场景。Coutrot1数据集包含60个视频片段,其中动态自然场景分为4个视觉类别:一个或几个移动对象、风景和面孔。Coutrot2数据集包含15个4人会议的片段。SumMe数据库研究视频摘要相关的任务,包含25段由普通用户拍摄的无规则视频。ETMD是从6部不同的好莱坞电影中截取了12段视频。

表1 数据集信息
3.3 评价指标
为公平评估模型的鲁棒性,需要综合多种评价指标定量分析。本文使用5个通用的评价指标在上述6个公开数据集进行评估,5个指标分别是:线性相关系数(CC)[19]、相似性测度(SIM)[20]、标准化扫描路径显著性(NSS)[21]、sAUC[22]和AUC_J[23]指标。
1)线性相关系数。
线性相关系数是衡量模型预测人眼关注点显著图结果S和真值G之间线性相关性的一种方法。计算方式如公式(3)所示:
(3)
其中,cov( )为协方差,σ(S)和σ(G)分别为显著图和真值的标准差。
2)相似性测度。
SIM计算预测显著性图结果S和真值G之间的相似度,将预测结果S和真值G归一化后,通过计算每一个像素上的最小值,最后加和计算得到SIM,如公式(4)所示:
SIM(S,G)=∑i(S(i),G(i))
(4)
3)标准化扫描路径显著性。
NSS是专用于人眼关注点检测的评价指标。NSS越大说明模型性能越好,如公式(5)所示:
(5)

4)AUC指标。
AUC指标表示ROC曲线下面积,该曲线的横坐标是假阳性概率(False Positive Rate, FPR),纵坐标是真阳性概率(True Positive Rate, TPR),如公式(6)所示:
(6)
其中:TP表示预测是正例,真实情况也是正例;TN表示预测是反例,真实情况也是反例;FP表示预测是正例,真实情况是反例;FN表示预测是反例,真实情况是正例。
AUC指标对人眼关注点的中心偏向较为敏感。由于对FPR以及TPR理解的不同,AUC指标有不同的计算方式,AUC-Judd (AUC_J)和shuffled AUC (sAUC)是用得较多的2种计算方式。限于篇幅,本文不展开叙述。
3.4 消融性研究
为了验证提出模型的有效性,本文定量分析了STAViS和AViNet方法加入音视一致性模型后的结果,如表2所示。表中“↑”表示数据的值越大性能越好,加粗显示的数据表示结果最好。其中,符号[AV]表示音视融合的预测结果;[V]表示只考虑视觉特征的预测结果;[avc-AV_V]表示加入音视一致性判断模型且音视不一致时只考虑视觉特征的预测结果;[AV+V]表示音视融合结果与视觉特征结果的加和作为最后的预测图;[avc-AV+V]表示加入音视一致性判断模型且音视不一致时音视融合结果与视觉特征结果的加和作为最后的预测图;[AV*V]表示音视融合结果与视觉特征结果的逐像素乘积作为最后的预测图;[avc-AV*V]表示加入音视一致性判断模型且音视不一致时音视融合结果与视觉特征结果的逐像素乘积作为最后的预测图。在STAViS和AViNet方法加入音视一致性判断模型的实验中,音视一致时输出的结果是音视融合的预测结果[AV]。
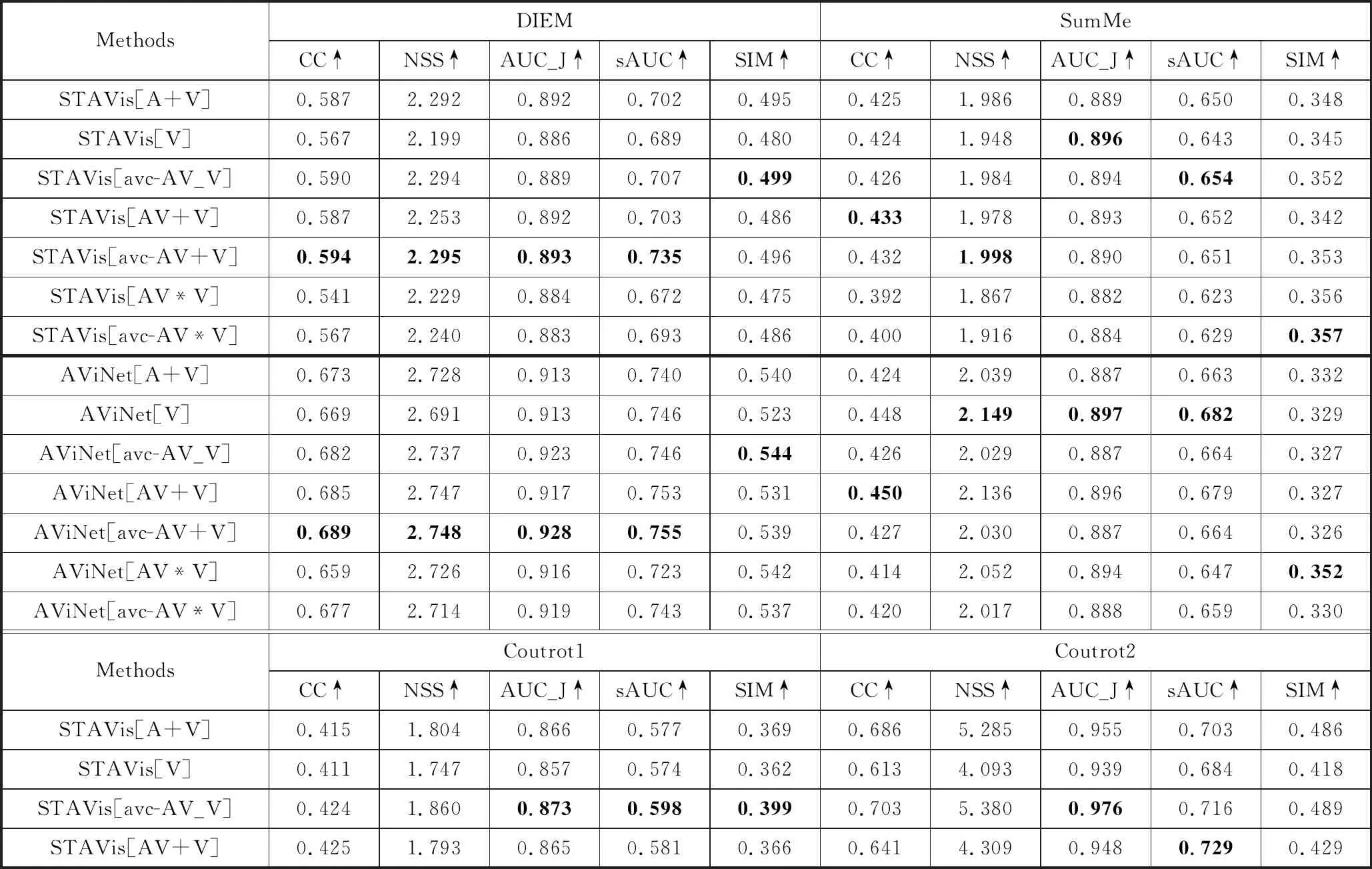
表2 在STAViS和AViNet方法中加入AVCN模型消融比较结果

表2(续)
由于SumMe数据集中视频是由普通用户拍摄的,音频来源杂乱,多数音频信息是与视觉无关的干扰音,所以加入AVCN模型后性能并未有明显的提升。但在其他数据集中,可以看出加入音视一致性判断模型的性能有所提升。
3.5 性能分析
由于现有音视人眼关注点检测方法较少,本文在上述6个公开的数据集上将所提出的AVCN加入STAViS和AViNet网络后采用[avc-AV+V]方法的结果和5种视频显著性检测方法进行比较,5种方法包括传统方法和深度学习方法。比较的模型包括SBF[24]、WSSA[25]、MWS[26]、DeepVS[27]和ACLNet[28]。
由表3中定量的比较结果可知,音视人眼关注点检测加入音频特征的效果优于未考虑音频特征的视频人眼关注点检测方法,音视融合的研究更符合机器学习的发展趋势。
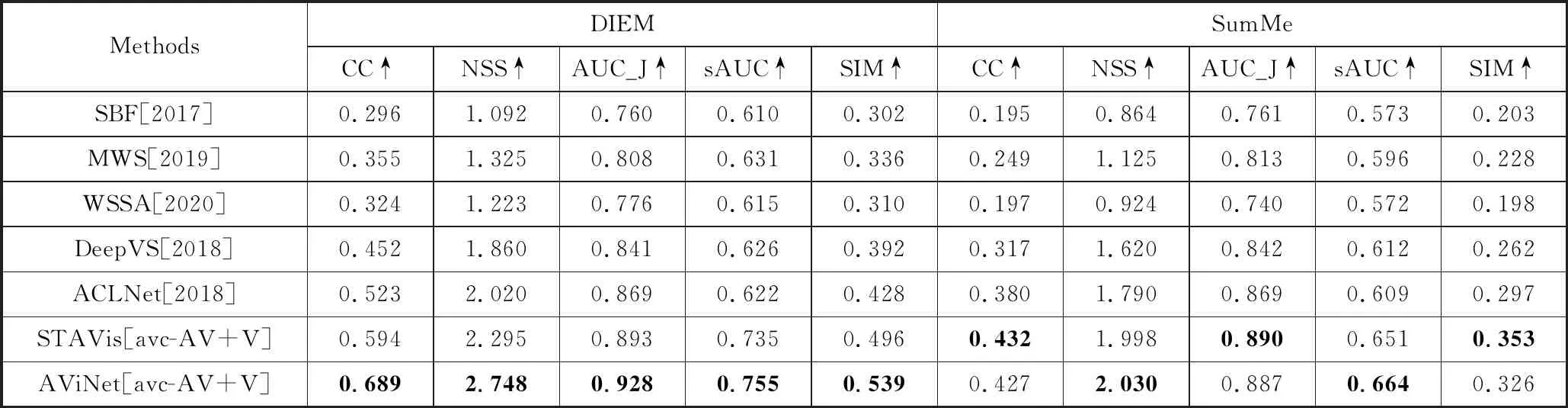
表3 与未考虑音频信息的视频显著性算法比较结果

表3(续)
4 结束语
本文针对当前音视人眼关注点检测未能考虑音视一致性的问题,提出了音视一致性判断模型。该模型采用双流形式分别提取音视特征,经过融合最后得到二分类结果。实验结果表明,在现有方法加入所提出的AVCN模型后性能有所提升,但整体而言提升效果不是特别明显。未来的研究方向是提出新的音视人眼关注点检测模型,在新的模型中加入AVCN与主流音视人眼关注点检测模型作对比,同时再进一步提升音视一致性判断精度,重新训练网络,更进一步提高音视人眼关注点检测的性能。
猜你喜欢
新体育(2022年2期)2022-02-09
甘肃教育(2020年14期)2020-09-11
今日农业(2019年12期)2019-08-13
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
快乐语文(2019年9期)2019-06-22
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
