
基于集成学习与不平衡数据的返贫预测
2022-05-05 13:37龚云翔袁仕芳刘付谦
计算机与现代化 2022年4期
龚云翔,袁仕芳,刘付谦
(五邑大学数学与计算科学学院,广东 江门 529020)
0 引 言
2021年2月25日,习近平总书记在全国脱贫攻坚总结表彰大会上庄严宣告:我国脱贫攻坚战取得了全面胜利。但贫困地区脱贫有不稳定性、脆弱性,如何防范脱贫人口再次返贫是现在巩固脱贫攻坚成果仍需要面对的重点问题。习近平总书记强调:“防止返贫和继续攻坚同样重要,要把防止返贫摆在重要位置,适时组织对脱贫人口开展‘回头看’”。因此为了维护脱贫攻坚的胜利成果,如何精准识别和预测返贫户并且制定出合适的帮扶政策是极其重要的。
当前,不少学者利用大数据时代的红利,结合现代技术对精准扶贫等相关领域展开研究。在国内,阎昊[1]先基于SPAC模型选取影响因子,再利用FP-Growth算法挖掘最大返贫特征集及其关联规则,最后采用贝叶斯正则化算法对搭建的BP神经网络进行训练,为扶贫政策的制定提供了更精确的数据支持;田昆[2]在对进行T检验后提取主要特征的样本在Spark平台下利用Logistic模型进行返贫预测,并用聚类算法分析返贫原因,使得帮扶更加有针对性;朱容波等人[3]提出了优化的FOA-BPNN模型,对扶贫的成效与脱贫时间进行准确刻画;唐小兵等人[4]利用主成分分析建立了县域贫困脆弱性评价模型,得到了不同县域的贫困脆弱性指数、分级阈值和区划图;张学敏等人[5]基于AHP和DP神经网络的方法进行建模,得出年人均收入和义务教育保障对返贫的影响最大的结论。在国外,Xu等人[6]提出一种基于粒子群优化和禁忌搜索混合算法的混沌回波状态网络多时间尺度风电预测模型;Mesina等人[7]利用卫星图像和卷积神经网络架构Alex Net判断菲利普各城市的贫困程度,从而得到一套更宽泛的社会增长指标;Pokhriyal等人[8]针对数据源单一的问题,提出了一个基于贝叶斯算法以最细的空间粒度和覆盖范围准确预测全球多维贫穷指数的计算框架;Sheng等人[9]设计了一个数据驱动的程序来捕捉贫困与相关数据之间的相关性,提出了一个深层神经网络多通道模型来对多类型特征进行编码。
上述研究没有考虑数据集不平衡的情况。现实中,返贫与已脱贫的数据往往是不平衡的,即返贫样本个数显著小于已脱贫样本个数。传统机器学习方法仅适用于样本数量均衡的数据集上,在不均衡的数据集上非常容易将数量少的样本错误分类为数量多的样本,这会极大降低模型分类的敏感度。因此本文提出一种基于SMOTE模型与集成学习结合的返贫预测方法,将数据进行预处理后利用SMOTE算法对少数类别样本进行过采样,使用随机森林(RF)、梯度提升模型(GBDT、XGBoost)、支持向量机(SVM)等4种基学习器进行模型融合,并与单一学习模型和其他融合模型进行对比以验证本文模型的有效性。
1 SMOTE过采样
本文选用的数据集中未返贫家庭有3638户,返贫家庭有230户,比例约为16:1。若以此为样本进行训练,会使得模型正确预测少数样本的类别标签的能力比多数样本更为重要,因此本文利用STMOE算法对少类别的样本进行过采样处理。
SMOTE是一种基于随机过采样方法改进的算法[10],其根据少数类属性特征随机产生相似样本,有效地平衡少数类与多数类之间数量,减少数据集过度倾斜[11]。SMOTE过采样的策略是对于每一个少数样本x,基于KNN算法随机选取一个少数样本y,在样本x与y之间的连线上随机选取一点生成新的少数样本xnew,计算公式如下:
xnew=xi+rand(0,1)(yi-xi),i=1,2,…,n
为了能够更直观地解释SMOTE的采样思想,本文将其可视化,圆圈代表类别为多数的样本,五角星表示类别少数的样本,三角形表示基于SMOTE模型新生成的样本,如图1所示。
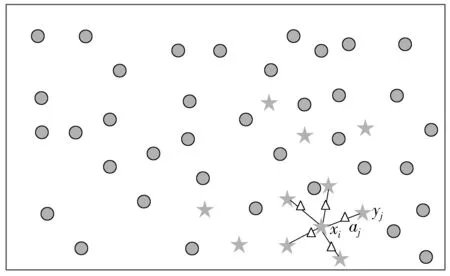
图1 SMOTE过采样示意图
2 模型的构建
Stacking模型[12]是由Wolpert提出的,其本质是一种串行结构的多层学习模型。不同于传统的集成学习模型装袋法(Bagging)和提升法(Boosting),Stacking框架是将不同的基学习器组合起来进行模型融合[13],如图2所示。
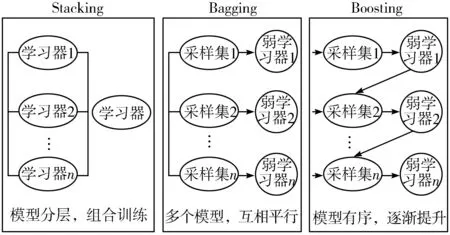
图2 不同集成学习模型的比较
Stacking算法的第1层学习器为基学习器,第2层学习器为元分类器,元分类器一般为简单模型。其简要工作步骤为:利用k折交叉验证对n个基学习器训练,每一个基学习器取k-1折训练,剩余1折预测,将n个基学习器预测结果合并组成新的训练集,输入到第2层的元学习器进行训练。
2.1 随机森林原理
随机森林模型是Bagging的典型代表,其是一种将决策树作为Bagging算法元分类器的集成学习方法[14]。该算法具体步骤如下:
1)假设数据集有N个样本,依据Bootstrap方法抽取数量不大于N的训练子集,重复k次得到k个训练子集。
2)从原始R维特征中随机选取n维子特征空间,重复k次得到k个特征子空间。
3)随机选取一个训练子集和一个子特征空间,按照决策树算法生成一棵决策树,有k个训练子集和k个子特征空间,即生成k棵决策树。
4)k棵决策树集成在一起构成随机森林,对新的样本进行分类时,新的样本首先会由决策树进行投票,以票数较多的类别作为输出结果。
2.2 GBDT原理
GBDT回归模型[15-16]是以二叉回归CART树作为基学习器的一种集成学习算法。每一次迭代计算都是为了减少上一次的残差,在残差减少的梯度方向上建立一棵新的决策树,模型最终输出结果为生成决策树的累加。具体过程如下:
设有T轮迭代,损失函数为L(yi,f(xi)),则第t次迭代的第i个样本的残差为:
每棵树的每一个叶子节点计算最小的损失函数,得到最优的叶子节点作为输出值:
θtj=argmin∑xi∈RtjL(yi,ft-1(xi)+θ)
其中Rtj表示新回归树对于的叶子节点区域,j为一棵树中叶子节点数量,θ为初始值,经过T轮迭代最终得到GBDT模型为:
其中I为指示函数,若x∈Rtj,则I=1,否则I=0。
2.3 XGBoost原理
XGBoost是GBDT的一种高效系统实现,其融合多个弱学习器(树模型)构成一个强学习器,该算法可以有效地控制模型复杂度,防止过拟合现象[17-18],其具体原理如下:

XGBoost的核心思想是最小化第k棵树的残差,其利用二阶泰勒展开式来求解目标函数[19],展开后为:

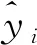
2.4 SVM原理
本文选取SVM模型[20]作为Stacking中的第2层分类器,其核心思想是将特征信息通过核函数的特征变换映射到高维空间,在高维空间内求取将不同类别的样本准确分开并使安全间隔最大的最优超平面ωx+b=0。选择核函数K,构造目标函数和约束条件为:
通过求偏导计算出ω*和b*,最终得到最优分类函数公式:
2.5 评价指标
对于二分类问题,基于真实类别和预测类别组合,可形成分类结果的混淆矩阵[21],如表1所示。基于混淆矩阵,本文选取正确率(Accuracy)与F1-score[22-23]作为模型的评价指标。正确率是模型最常用的评价指标,可以在一定程度上反应模型预测或是分类的性能。

表1 混淆矩阵
在表1中,TN表示真实值为0且预测值也为0的样本数量;FP表示真实值为0但预测值为1的样本数量;FN表示真实值为1但预测值为0的样本数量;TP表示真实值为1且预测值也为1的样本数量。
在不平衡数据集下,还需引入F1-score作为评价指标,F1-score综合了精准率(Precision)和召回率(Recall)这2种评价指标。评价指标计算公式如下:
3 实验结果与分析
本实验数据集来源于江门市大数据局的脱敏数据,该数据集共有22个特征,本文利用平均值来填补住房面积、耕地面积、低保金、距村主干路距离等特征,利用众数来填补贫困户属性、饮水是否安全、入户类型等特征。在经过SMOTE算法过采样后,将原本230户返贫户样本增加至1300户,标签为返贫与标签为未返贫的样本数据比例约为3∶1,总计样本数共4708条,属于正常范围。
图3显示了PCA降维算法各个维度的特征值贡献率以及累计贡献率。当特征值累计贡献达到80%时,就认为保留了原始数据集的主要特征。因此从图3可以看出,数据集由原本22个维度可以降至13个维度。

图3 数据集特征贡献率
3.1 模型参数选择
本文划分数据集的80%作为训练集,20%作为测试集,利用网格搜索法[24]和交叉验证法[25]相结合的方式对模型进行参数优化。首先在较大步长下进行随机搜索选择出最优参数值,接着采用较小步长在最优点附近进行划分,利用10折交叉验证确定出得分最高的参数组合,从而确定出全局最优参数值。各个子模型寻优后的参数值具体见表2~表5。

表2 SVM模型参数解释与优化值

表3 RF模型参数解释与优化值

表4 GBDT模型参数解释与优化值

表5 XGBoost模型参数解释与优化值
3.2 模型结果比较
为了进一步验证Stacking集成学习模型的有效性,本文将每一个基学习器与不同的融合模型进行比较,在测试集上评价指标结果如表6所示。

表6 单一模型与融合模型评价结果汇总
从图4可以看出,在对脱贫家庭进行是否返贫预测时,大多单一模型的Accuracy与融合模型相差无几,但融合模型的F1-score明显都要优于单一的模型,这表明在面对不平衡数据集的情况下,单一模型更容易出现误判。在4种融合模型的预测中,XGBoos+GBDT+SVM的综合评价得分相较于其他3种模型最差,因为在模型融合中,GBDT与XGBoost的原理都是提升法,属于相近的模型,融合后的效果往往不如之间差异较大的模型,其Precision的值最高,意味着把未返贫家庭错误预测为返贫的可能性更小,但较低的Recall,意味着把已返贫的家庭错误预测为未返贫的可能性更大。通过比较RF+GBDT+SVM和RF+XGBoost+SVM可以发现,单一模型的预测效果越好,模型融合后的预测效果相对更好。F1-score是Precision和Recall的加权平均,RF+XGBoost+GBDT+SVM模型的此项得分最高,可以在一定程度上保证模型的误判率更低,从而实现扶贫工作精准度与人力资源的平衡。
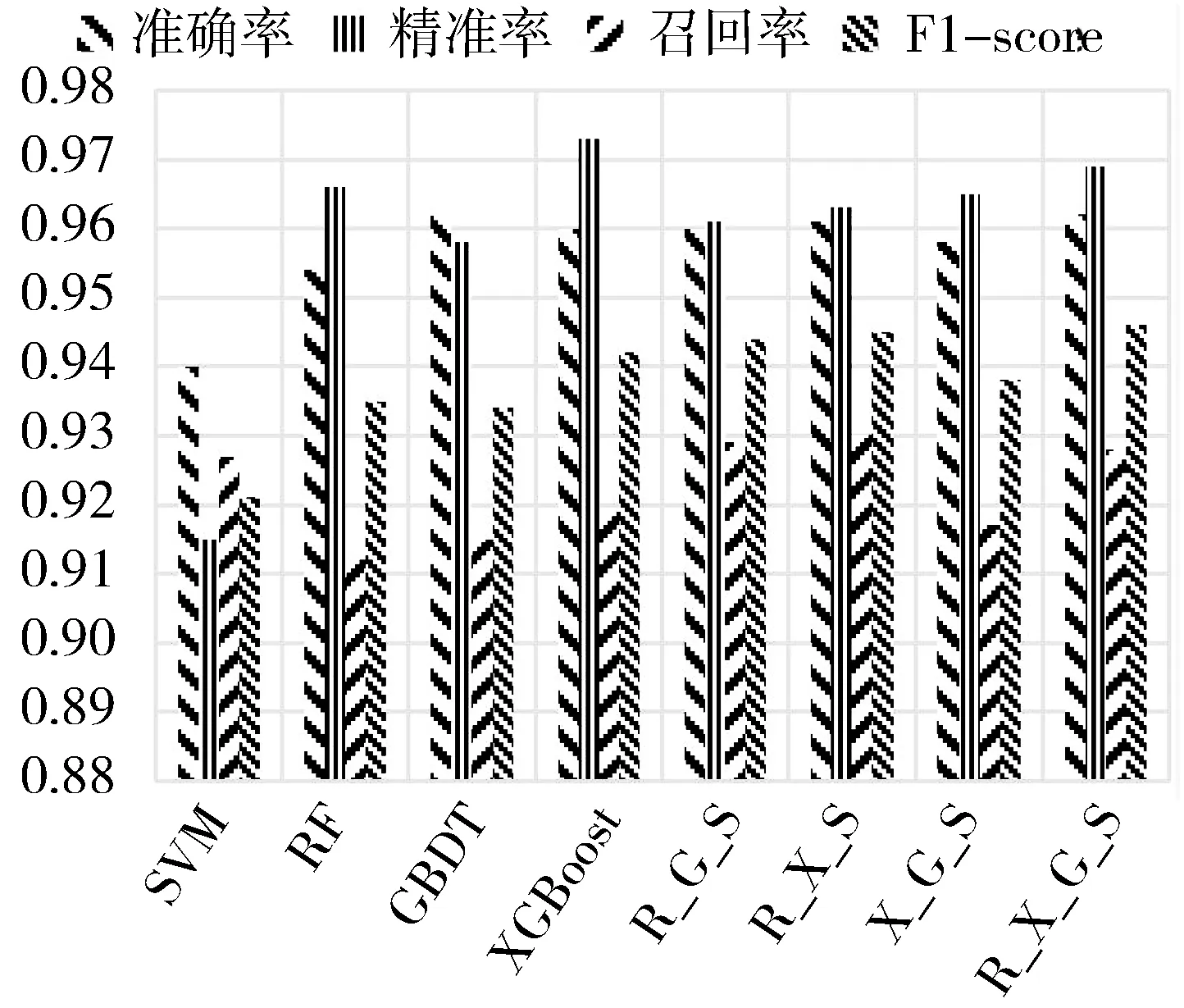
图4 8种不同模型的预测结果对比
3.3 模型泛化能力验证
为了进一步验证模型的泛化能力,本文选取经典不平衡信用卡欺诈数据集进行验证,信用卡欺诈数据集包含30个属性,其中标签分布为284315∶492,比例约为578∶1,同样利用SMOTE算法对该数据集进行操作,过采样后的样本类别比例仍为3∶1,利用3.2节中的RF+XGBoost+GBDT+SVM融合模型来测试分类效果。图5为融合模型与SVM模型测试结果的ROC曲线对比。ROC曲线是绘制真阳性率与假阳性率的二维图,ROC的曲线下面积AUC能将ROC曲线简化为一个单一的量化指标[26-27]。

(a) 融合模型ROC曲线
由图5可知,融合模型在信用卡欺诈数据集上的AUC为95.07%,并且F1得分也达到0.9367,而传统的SVM模型的AUC只有73.78%,F1得分仅有0.6244。这表明本文选取的融合模型有较强的泛化能力,优于传统的机器学习模型,不仅能够有效地预测脱贫家庭是否返贫,还可以很好地迁移到其他领域。
4 结束语
针对不平衡数据集的返贫预测任务,本文首先利用SMOTE算法进行过采样处理,其次提出了Stacking模型融合的算法,Stacking结合了随机森林模型、GBDT和XGBoost模型作为第1层的基分类器,集成融合了SVM作为第2层的元分类器,将不同的融合模型和单一模型进行比较,最终得到融合模型的准确率和稳定性都要优于单一模型。
本文模型可理解性强并且预测准确率较高,能够满足相关部门精准识别返贫家庭需求,对巩固维护脱贫攻坚的胜利成果具有重要意义。
猜你喜欢
世界科学技术-中医药现代化(2021年8期)2021-12-21
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年2期)2021-02-23
少儿画王(3-6岁)(2020年4期)2020-09-13
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
电子制作(2017年24期)2017-02-02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
航天返回与遥感(2014年5期)2014-07-31
