
基于丢包和网络测量的TCP拥塞控制算法研究综述
2022-05-05 09:21李英华崔佳荣
数字通信世界 2022年4期
李英华,崔佳荣
(国家无线电监测中心,北京 100037)
0 引言
随着智能手机和移动互联网的飞速发展,不仅给社会各行各业带来了新的发展机遇,而且通过网络传递的信息流量也变得极其巨大,当信息流量超过网络中部分传输线路的承载能力时,随之而来的问题就是越来越严重的网络拥塞问题。一旦网络中出现了拥塞现象,路由器或交换机将不得不丢弃无法及时传递的数据包,以避免设备的队列缓冲区溢出,因此有可能造成业务中断或服务质量下降,影响用户体验。考虑到互联网中超过95%的信息采用TCP进行传输[1],且TCP的自动重传机制对网络拥塞比较敏感,即使在没有丢包的情况下,也会因为拥塞增加了确认数据包(Acknowledgement,ACK)的排队时延,而导致TCP发送端误认为发生了丢包问题,因此网络拥塞问题的研究也主要集中在通过TCP完成拥塞控制。
1988年,Jacobson等人[2]率先提出了在TCP中增加拥塞控制机制,即著名的“慢启动”“拥塞避免”和“快速重传”等三个算法;1990年又进一步提出了“快速恢复”算法。目前,网络上已经获得广泛部署的TCP大多采用这四个基本算法来实现拥塞控制,但是上述算法也存在网络适应性差、效率低和公平性差的问题,尤其是慢启动算法的问题则更为严重。因此,后续研究者又提出了多个针对性的改进算法,但是基本思想仍然是以丢包作为网络拥塞的判断依据。
以丢包作为网络拥塞的判断依据在有线网络中表现出较好的性能,但是在误码率较高的无线网络,或传播时延较大卫星网络中,将大大降低实际传输速率,因此研究者又提出了基于网络测量的拥塞控制算法,以解决传输效率低和网络适应性差问题。
1 基本丢包的算法
引起网络拥塞的根本原因在于网络中的供需不平衡,当业务流量超过网络所能提供的传输资源,例如链路带宽、缓存容量和计算速度等,就会引起拥塞。而一旦发生拥塞现象,将造成进一步数据包的丢失,因此传统的TCP拥塞控制算法将丢包作为判断网络是否出现拥塞的依据。基于丢包的拥塞控制算法包括Tahoe、Reno、New Reno、BIC TCP、TCP CUBIC等算法。
1.1 Reno算法
Reno算法在早期的Tahoe算法的基础上进行了改进,率先引入快速重传、快速恢复、拥塞避免、慢启动等控制机制,成为众多网络拥塞算法方案的基础。图1给出了Reno算法控制拥塞窗口(Congestion Window,CWnd)的基本控制。
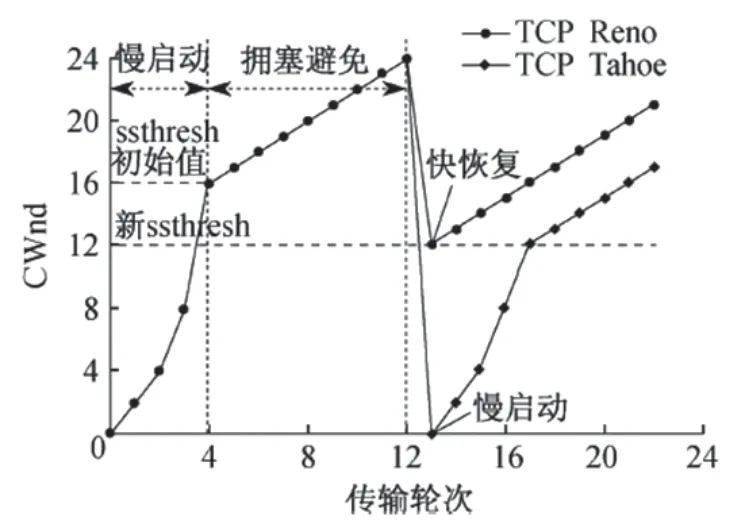
图1 Reno算法拥塞控制窗口调整
Reno算法对网络拥塞状态的判断依据是检测到丢包事件,处理方式是重传所有相关数据包,使得网络传输过早离开快速恢复状态,造成传输速率无法顺序恢复。尤其是在一个发送窗口内存在多个数据包丢失的情况下,传输性能会大幅降低,之后出现的TCP New Reno算法对此问题做了改进。
1.2 New Reno算法
TCP New Reno算法在Reno算法的基础上添加了恢复应答判断功能(RACK),在同时存在多个丢包时,仅当所有报文都被应答后才退出快速恢复状态,因此能够区分出一次拥塞丢失多个包和多次拥塞两种不同的状况,解决了Reno算法过早退出快速恢复状态的问题,提高了网络性能。但是TCP New Reno算法同样存在信道带宽利用率低的问题。
1.3 BIC TCP算法
当发生单个丢包时,传统的AIMD(Additive Increase Multiplicative Decrease)算法需要经过多次往返时间(Round-Trip Time,RTT)才能恢复到最大拥塞窗口,降低了信道带宽利用率。而BIC TCP算法[3]将拥塞窗口控制转化为实际值搜索问题,采用二分查找法通过取所允许窗口范围中点的方式来调整拥塞窗口,以加快最大拥塞窗口的恢复速度,提高资源利用率。但BIC TCP算法的缺点在于需要经历一个RTT时间才能进行一次二分查找,因此对于不同RTT时间的业务流,因为查找的频率不同,造成窗口恢复速度的差异,导致RTT小的数据流更易获得较高的带宽,因此缺乏公平性。
1.4 基于丢包的算法小结
上述TCP拥塞控制算法采用丢包作为拥塞判断信号,在早期简单的有线网络中,由于网络拥塞是引起丢包的主要原因,因此能够获得较好的效果,而在后来出现的无线网络中,除了因拥塞引起的丢包,误码率高、信道信号衰弱等也会引起无线网络中数据包的丢失,此时TCP依然会调用拥塞控制机制进行处理,而这种虚假的拥塞判断使得TCP在无线网络中传输速率被限制,导致性能大幅下降。另外,为了探测网络带宽的上限以充分利用网络资源,基于丢包的算法在没有丢包的情况下,需要不断增加拥塞窗口,会过度占用路由器缓冲区。
2 基于网络测量的算法
基于网络测量的拥塞控制算法,基本思想是通过测量端到端的网络性能参数,以取代丢包作为判断网络拥塞状态和调整拥塞窗口的依据,从而解决信道误码情况下带宽利用率过低和缓冲区被过度占用的问题,其主要采用的性能指标是时延和可用带宽。
2.1 基于时延的算法
基于时延的算法主要以端到端往返时延为参数来调整拥塞控制窗口的大小。由于发送端每收到一个确认信息,即可获得数据包的往返时延,而不必等到出现丢包再进行调整,缩短了响应时间,有利于减少网络丢包现象,主要包括TCP Vegas、FAST TCP和TCP-Illinois等算法。
2.1.1 TCP Vegas算法
TCP Vegas算法[4]的基本思想是以往返时间为单位,分别计算单位时间内的预测吞吐量和实际吞吐量。其中,预测吞吐量为当前拥塞窗口的大小除以最小RTT(如式1),实际吞吐量为发送的数据包数量除以采样的RTT(如式2),即

式中,Bexp是预测带宽;Bact是实际带宽;Pi是实际发送的第i个数据包大小。以δ值的大小判断路径拥挤状况,当δ大于高阈值时,表示该路径发生严重拥挤,因此需要重新降低发送速率,否则保持当前的发送速率。
2.1.2 FAST TCP算法
FAST TCP算法[5]的基本思想是将结合往返时延和丢包状态,调整拥塞窗口大小以控制网络拥塞。该算法利用往返实验估计排队时延,当排队时延远低于阈值时,则快速地增加拥塞窗口;当排队时延接近阈值时,则缓慢降低拥塞窗口增速;一旦排队延迟高于阈值,则迅速降低拥塞窗口。当出现丢包时,则采用与经典TCP算法类似的处理策略,这样对于由误码引起的丢包,由于排队时延不会因丢包而发生变化,因此可以快速地恢复拥塞窗口,从而提高了信道带宽的利用率。
2.1.3 TCP Illinois算法
TCP Illinois算法[6]基本思想是首先根据排队时延确定增加因子α和乘减因子β,然后再利用上述因子实时调整拥塞窗口的大小。在平均排队时延较小时,表示网络拥塞状态并不严重,因而可以设置一个较大的α值和一个较小的β值,以充分利用信道带宽;而当平均排队时延较大时,表示网络拥塞状态将迅速恶化,则降低α值、增大β值,以快速避免拥塞状态。TCP Illinois算法通过动态调整α和β值,在拥塞避免和带宽利用之间取得一定的平衡。
基于时延的算法主要将时延作为判断拥塞状态的依据,同样也存在一定的片面性,因为时延增大不一定代表网络出现了拥塞,尤其是在异构网络环境下,如果传输路径中包含卫星链路,则会严重影响业务的实际吞吐量。
2.2 基于可用带宽的算法
基于可用带宽的算法主要通过测量端到端的可用带宽来直接设置拥塞控制窗口的大小,从而能够在避免拥塞的情况下,快速逼近最大传输速率,以充分利用信道带宽资源,同时降低了时延参数的依赖性,并且对使用卫星链路的业务流更加友好,主要包括TCPwestwood和BBR两种。
2.2.1 TCP Westwood算法
TCP Westwood算法[7]的基本思想是通过计算接收端返回的ACK数据包的速率来估算端到端的可用带宽,然后再根据可用带宽来调整拥塞窗口(如式4)。

式中,BWcurrent是估算出来的可用带宽;RTTmin是最小往返时延。当连续收到3个ACK后,就将SSthresh设置为拥塞窗口的当前值,这样算法可以根据可用带宽的变化,实时动态地调整拥塞窗口的大小,以解决缓冲区过度被占用问题。另外,TCP Westwood算法还将丢包结合进来,一旦发现丢包,则根据一个估计数来设置慢启动,而不是直接将窗口减半,以避免在信道误码的情况下传输速率急剧下降。
2.2.2 BBR算法
BBR算法[8]是Google公司在2016年提出的基于可用带宽和往返时延的拥塞控制算法,且已应用于最新的Linux内核中。BBR算法首先根据往返时延的变化测量网络的最大可用带宽(BWmax),然后再根据最小往返时延计算出拥塞窗口的大小(如式5)。

由此可见,BBR算法能够完全忽视丢包状态,因此具有更好的网络适应性。BBR算法的收敛点如图2所示。基于丢包的算法一般都要等到缓冲区溢出(B点)时,才开始实施拥塞控制。而早在A点时,网络传输速率就已停止增长,之后发送的数据包除了加重网络拥塞状态,并不会提高传输速率。BBR算法则早在A点就实现了收敛,即在网络即将发生拥塞之前及时进行控制,因此降低了拥塞的概率。

图2 BBR算法的收敛点
2.3 基于网络测量的算法小结
基于可用带宽的拥塞算法通过对网络带宽以及RTT等相关信息的测量,来调整拥塞窗口大小以实现传输速率的增长,本质上不区分拥塞状态和非拥塞状态,而是逼近当前估计出的最大可用带宽,因而可进一步提高吞吐量。但上述算法仍有一些不足,比如计算过程采用了一些经验值(如BBR中的采样次数),这些经验值的选取是在训练大量的数据后得出的,缺乏数学理论的支持,而且对训练数据集依赖性较大,当实际网络环境与训练环境差异性较大时,该算法的性能可能会急剧下降。表1分别从判决时机和决策函数等两个方面,对基于网络测量的拥塞控制算法进行了比较。

表1 基于网络测量的拥塞控制算法
3 结束语
传统的基于丢包的网络拥塞控制算法因为无法准确地识别出丢包的原因,而导致TCP传输性能严重下降。基于网络测量的拥塞控制算法,虽然可以直接评估网络的拥塞状态,但是并不能够准确地掌握瓶颈链路的网络带宽使用情况,因而在复杂的网络环境无法做出最优的决策,造成网络资源的浪费。随着网络技术的不断进步,未来网络环境可能更加复杂和难于预测,传统的数学建模方法所面临的困难将更大,但是机器学习、深度学习和强化学习的兴起,给拥塞控制提供了新的研究思路。
猜你喜欢
选煤技术(2022年2期)2022-06-06
计算机与数字工程(2022年3期)2022-04-07
湖北工业大学学报(2021年2期)2021-04-28
民用飞机设计与研究(2020年4期)2021-01-21
中国计算机报(2020年15期)2020-05-13
物联网技术(2018年8期)2018-12-06
北京航空航天大学学报(2017年1期)2017-11-24
绿色科技(2017年2期)2017-03-23
汽车文摘(2016年11期)2016-12-08
CHIP新电脑(2016年9期)2016-09-21
