
基于略读模块的神经快速阅读
2022-05-05 07:33侯磊,蒙会民,李旭,兰振平
大连工业大学学报 2022年2期
侯 磊, 蒙 会 民, 李 旭, 兰 振 平
( 大连工业大学 信息科学与工程学院, 辽宁 大连 116034 )
0 引 言
循环神经网络(RNN)是一种高效的深度学习模型[1],长短期记忆网络(LSTM)是RNN的变体,通过引入门控单元来学习长期依赖性,能有效地处理可变长度的序列数据,但LSTM处理这一类任务时存在两个主要问题:一是运算速度慢,占用内存大;二是需要机器阅读整个文本[2],推理时间长。对于分类问题,某些特定词语或句子与当前的分类任务相关[3]。以情感分析为例:当电影评论中出现“这部电影很棒”或“很糟糕”,即使没有阅读其余评论,也能直观判断用户感受。
并非所有输入都有相同的重要性,注意力模型[4]在解码时赋予信息不同的权重。但注意力模型是基于浅层语义的相似度计算,不能提高推理效率。卷积神经网络(CNN)具有高并行计算能力,但无法捕捉单词的全局交互信息。结合自注意力机制可以弥补CNN这一劣势[5],但对硬件设备配置要求高。Yu等[6]提出了一种LSTM-Jump模型,在t时刻选择跳过一个或多个单词来提高推理效率。LSTM-Jump证明忽略文档中的某些单词不会影响预测准确性,但跳转范围是基于固定值,没有考虑文本的固有结构。Yu等[7]用RNN隐藏状态来判断何时停止阅读。当RNN判断模型对上下文有足够理解,将实时停止并产生答案。但仍然存在语义缺失和噪声干扰的问题。Minjoon等[8]提出了Skim-LSTM模型。模型根据输入和上一时刻输出的状态,选择“小”神经网络或“大”神经网络更新状态。该模块的网络结构比较复杂,且对长文本的处理较慢。Fu等[9]提出了一种穿梭模型LSTM-Shuttle。向前移动可以提高效率,向后移动可以让模型恢复丢失的信息,确保较高的准确度。但文本重复阅读,导致阅读速率下降。Hansen等[10]提出一种Structural-Jump-LSTM。该模型由标准LSTM、Jump代理和Skip代理组成。Jump代理能够在阅读前跳过单个单词,Skip代理在4个动作中(跳到下一个词、跳到子句子分隔符(,:)、跳到句子结束符号(.!?)或跳到文本结束标记)选择一个后跳转。该模型2个代理中都包含重复的动作选择,结构复杂,不能准确的有效融合上下文信息。
基于上述模型不足,应用强化学习算法,针对网络结构复杂和文本阅读效率低的问题,提出了一种基于略读模型的LSTM网络。主要设计思路是:模型由标准LSTM网络和略读代理组成。略读代理用来确定哪些输入是必需的(例如,读取下一个词,略读下一个或下几个词)或者模型应该跳转到句末、段尾和文本末尾。将准确率和计算成本作为奖励函数,对略读代理的评分。模型不依赖过多的超参数,实验结果表明略读单词比完全跳过单词具有更高的准确性。
1 模 型
1.1 模型概述
基于略读模块的神经快速阅读模型示意图如图1所示。模型由标准LSTM网络和略读代理组成。略读代理计算动作分布,采样具体的略读动作。代理动态地选择跳过1,2,…,n个单词(经过测试当n=3时,模型效果最好)、略过整个句子或段落,从而不更新LSTM;或让LSTM读取当前时刻单词,更新神经网络。使用略读代理的目的是:跳过无关信息,加强重要部分,快速准确的完成需要机器阅读文本的自然语言任务。略读代理用全连接层进行选择,其大小比LSTM单元小得多,略读模块通过避免LSTM状态更新来减少FLOP,推理速度比标准LSTM快。

图1 基于略读模块的快速神经阅读模型Fig.1 Schematic drawing of neural fast reading basedon skimming module
1.2 模型推理
如图1所示,t时刻,模型读取的输入分别是:上一时刻略读代理做出的决策statet-1∈Rrn和LSTM输出ot-1∈Rrn以及当前时刻的输入tokeni∈Rd。在t-1时刻,略读代理从动作分布pt-1中选择一个动作at-1。在推理时,动作既可以从分布中采样整体最优解,也可以根据贪心策略只考虑局部最优解。从pt中选取动作at的计算公式为
statet=dReLU(xt⊙ot-1⊙onehot(at-1))
(1)
pt=softmax(dLIN(statet)
(2)
式中:dReLU为全连接层线性整流激活函数,dLIN为全连接层线性激活函数,softmax是逻辑回归模型,符号⊙代表向量的拼接,onehot是文本特征提取的编码方式。
如果at=1,那么LSTM会读取到这个单词,同时计算新的输出状态,生成下一步ot和statet。如果采样的动作at对应跳过一个或多个单词,就跳过当前几个词,同时设置ot=ot-1和statet=statet-1,网络则定位到下一个输入位置。如果所采样的动作at是跳转到下一个句子或段落,当前LSTM的输出和状态将保持不变,忽略后面所有输入,直到新的句子和段落开始。这时如果后面的采样动作没有输入决定,最终预测结果是当前时刻LSTM的输出。如果动作是直接跳到文本末尾,当前输出即为最后结果。
1.3 模型的训练
在训练过程中,针对以下两个目标对模型进行优化,一方面生成可用于分类的输出,另一方面根据输入及其上下文来学习何时略读文本。对于第一个目标将LSTM的输出直接用于分类,计算其交叉损失函数Lclass。对于第二个目标因为采样是不可微分的离散采样,所以将问题重新表述为强化学习问题,定义一个最大化奖励函数。奖励根据读取文本数量和预测是否正确给予。总奖励Rt与采样序列相关。如果网络选择跳过一个单词,则采样序列在该时刻不会跳转。为了减少误差,使用优势动作评价算法[12]来训练模型,演员损失函数为
Vt=dLIN(statet)
(3)
(4)
式中:Vt是给定状态估计值,该值由输出大小为1的全连接层生成。Vt表示该状态获得的奖励数量,dLIN是网络期望以后获得的奖励数量的线性函数。损失函数取决于在给定状态下所获得的报酬是高于还是低于预期报酬,使用最新的异步优势动作评价算法中的损失函数[11]。模型的演员损失函数是Lactor。评论家损失函数Lcritics的目标是每种状态的观察值,用平方差损失训练代理的价值估计。其中代理的动作分布是均匀分布,为了保证动作的多样性、增加模型的探索能力和避免梯度爆炸,添加熵损失函数Lentropies。网络总损失函数为
L=αLclass+βLactor+γLcritics+δLentropies
(5)
式中:α,β,γ和δ是控制各损失函数之间平衡的参数。
对于模型的每个动作,代理都会给予奖励rt。
(6)
式中:|doc|是文档单词总数量,跳过一个单词的收益会随文档长度的变化而变化。cs是比重参数,其值为0~1的实数。阅读或跳过都需付出代价,所以奖励都是负面的。根据预测是否正确给予额外的奖励,t时刻奖励总和Rt为
(7)
式中:p(yt)是网络正确给出目标类的概率。ωr是控制滚动奖励和基于模型绩效奖励之间平衡的参数。Rt的设计思路:做出正确预测时,给定的奖励接近1;做出错误预测时,因为增加了正确类别的概率,给定的奖励也不为0。
2 实 验
2.1 参数设置
使用TensorFlow开源深度学习库,实验在如表1所示的数据集上验证。在自然语言处理的下游任务中,LSTM网络的表现优于CNN和RNN等神经网络。因此选取LSTM读取完整的文本作为基线实验,对比了多个基于LSTM的快速阅读模型。
对于情感和主题分类数据集,在LSTM输出时加入了一个全连接层,全连接层与LSTM单元大小相同,使用softmax预测。在回答问题数据集上实验时,遵循Hansen的方法,选择具有最大化softmax指数的候选答案CWo∈R10。其中C∈R10×d为候选答案的单词嵌入矩阵,d为嵌入层大小,W∈Rd×cell_size是权重矩阵,o为LSTM输出状态。将问答任务转换为有10个类的分类问题,先读取问题,然后读取文档,通过问题来限制文档内容的读取。用GloVe[12]表示词向量,将其作为略读代理和LSTM的输入。
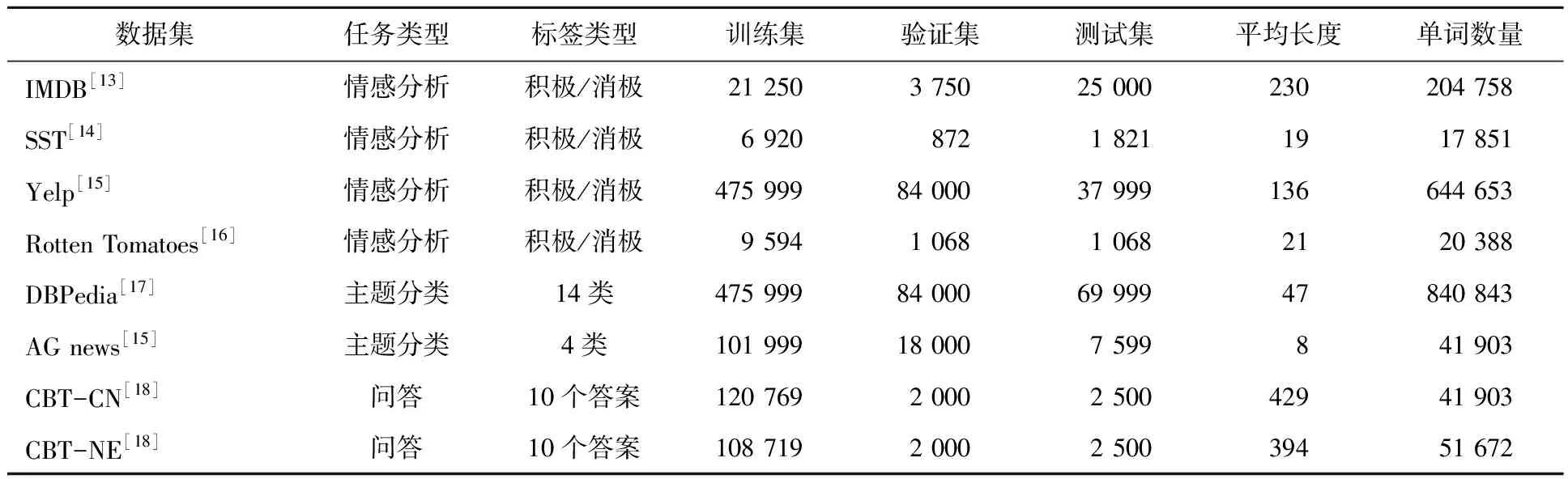
表1 数据集统计表Tab.1 The statistical list of datasets
把IMDB、SST、CBT-CN和CBT-NE分为预定义的训练集、验证集和测试集,把训练集中15%的训练数据分为验证集。Rotten Tomatoes数据集留出10%作为测试集。为了训练模型,学习率从集合{0.001,0.000 5}中选择,问答数据集(CBT-C和CBT-NE)学习率的最优值是0.001,主题分类和情感分析数据集学习率的最优值为0.000 5。在AG news、Rotten Tomatoes和SST上使用的batch size是32,其余数据集batch size为100。用dropout来减少过拟合,LSTM隐藏层和输入层单元丢失概率均为0.1。使用的LSTM单元大小为128,应用阈值为0.1的梯度剪裁。略读代理连接的全连接层大小是25。
训练时,快速阅读模型从读取全文开始,动作分布初始化为仅读取,确保准确性达到最大值后,再激活略读代理。快速阅读模型训练时,对于问答数据集,词向量的初始化是固定值,可以在其余部分进行训练。其他数据集词向量都是固定值。
如式(5)所示,总损失函数是预测损失、演员损失、评论家损失和熵损失之和,演员损失缩小1/10,使其大小与其他损失相当。熵损失系数(δ)通过交叉验证从{0.01,0.05,0.1,0.15}中选择,表现最佳的是0.1。交叉验证整体最优动作和局部最优动作两种动作选择方式,对于问答数据集,整体最优动作选择实验效果更好,而非阅读理解数据集采样局部最优动作。如式(6)所示,为了简化实验,将Cs固定为0.5,跳过单词的代价为阅读单词的一半,促进模型选择跳跃动作。如式(7)所示,在{0.05,0.1,0.15}中交叉验证,大部分数据集表现最佳的ωr为0.1。
2.2 实验结果
2.2.1 略读模型和全读模型对比
神经快速阅读模型的目的是读取最少的单词,得到更高的准确率。如表2所示,将准确率(Acc)、跳过文本百分比(Skim)和读取文本百分比(Read)作为评价指标。与标准LSTM相比,本模型获得相同甚至更好的精确度,在DBPedia数据集读取文本百分比降低到19.8%。读取速度最慢的是AG news数据集,读取文本百分比为59.4%,读取的速度随不同的数据集而变化。在7个数据集上显著地提高了准确率,只有SST准确率与标准LSTM相同。
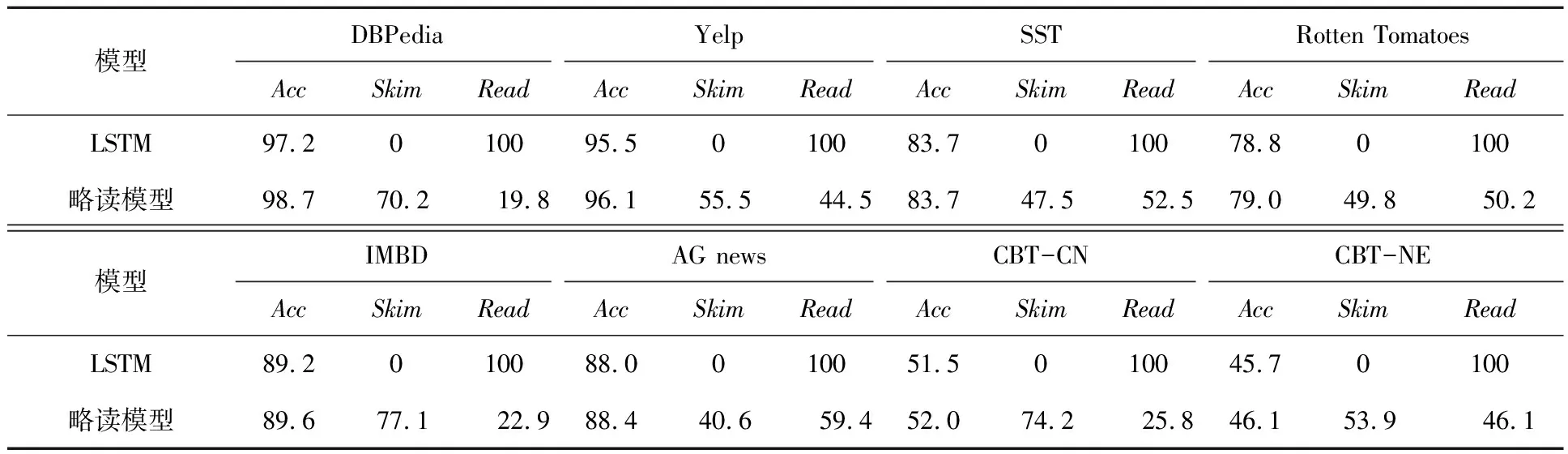
表2 略读模型和全读模型评价指标对比表Tab.2 The comparison of evaluation indicators between skimming model and full reading model %
在所有数据集上,模型所读取的文本均比基线实验少,占文本的19.8%~59.4%。,说明模型的跳过是有意义的。图2是来自DBPedia数据集的快速阅读行为示例。该模型学会跳过一些无用单词,阅读对预测重要的单词。但模型不会直接跳到句尾,而是检查最后一句的前两个单词。

图2 快速阅读行为示例Fig.2 An example of speed reading action
2.2.2 略读模型和其他快速阅读模型的对比
与其他模型对比时,由于硬件设置不同,不能仅计算模型使用的总浮点运算次数(FLOP),还需计算全读模型和快速阅读模型之间的浮点运算次数减少量(FLOP-r),这样可以有效避免实验结果存在差异。
表3列出了略读模型和多个基于LSTM的快速阅读模型的指标预测结果。ΔAcc是快速阅读模型和全读模型的精度之差(越高越好)。由于模型使用不同网络配置的RNN和训练方案,导致不同的全读模型和快速阅读模型精度不同。为了对每种速度阅读模型的效果进行一致的比较,实验报告了每篇论文的全读和快速阅读模型准确度之间的差异。FLOP-r是与完全读取模型相比的浮点运算次数的减少量。星形(*)表示原始论文只提供了一个速度增益,可以认为是FLOP-r的下界。

表3 各个模型评价指标对比表Tab.3 The comparison of evaluation indicators for different models
除了在CBT-CN数据集上,Yu-LSTM提供了6.1x的速度增益,在其他数据集上都提供了最少的浮点运算次数(FLOP)。其次是Structural-Jump-LSTM模型,在各个数据集上也取得了不错的效果。但该模型主要问题训练两个代理所需的参数多,占用的计算时间长。最差的是LSTM-Jump的模型,整个模型建立在传统的LSTM上,隐藏层后加一个分类器,分类器的作用是通过对softmax采样,确定当前状态下一步需要跳过的单词数量,模型在读入词向量和跳过词向量之间交替,直到满足结束条件。与他们工作不同的是,本模型使用强化学习中的异步优势动作评价算法,模拟了类人的略读机构,不是单纯的跳过单词,而是动态的调整LSTM的输入。最后设计包含负面奖励的奖励机制,使用价值网络来减少方差。
Yu-LSTM的模型在数据集CBT-CN和CBT-NE给出最高准确率。与其他的方法相比,它的优势是:问题中高信息级别的先验知识可以编码到预训练中,Yu-LSTM的模型中对于CBT-CN数据集使用1跳转,CBT-NE数据集使用5跳转获得更高的准确率。对于问答数据集来说,如果可以获取有关文档的先验信息,对模型是有益的。
3 结 论
为了解决文本阅读推理速度慢的问题,提出了一种基于略读模块的神经快速阅读模型,该模型根据文本结构动态的决定跳过1,2,…,n个单词、跳到下一个句子、跳到下一个段落还是直接跳转到文本末尾,允许在不更新LSTM状态的情况下,观察一个单词后跳过它。为了更好地优化模型,将准确率和计算成本作为奖励函数,对略读代理评分。与5个同类的快速阅读模型对比实验,略读型的浮点运算次数得到最大程度地减少,消耗计算资源少,达到了预期相同或较高准确率。
猜你喜欢
今日农业(2022年15期)2022-09-20
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
汽车维修技师(2019年7期)2020-01-16
小天使·二年级语数英综合(2019年10期)2019-11-08
红领巾·成长(2019年3期)2019-04-16
航空模型(2017年4期)2017-07-29
学生天地·小学中高年级(2016年8期)2016-05-14
