
基于知识图谱视域的Web服务推荐技术研究
2022-04-29 17:48王棒钧
计算机应用文摘 2022年18期
关键词:知识图谱
王棒钧
关键词:知识图谱;Web服务推荐技术;物品协同推荐;GN计算方法
知识图谱下的Web服务推荐技术实质上是为了能够快速、有效地解决网页问题而出现,其核心思想是通过特殊技术,将用户与物品之间建立的联系进行深入挖掘,从而获取有效信息,以实现用户画像的准确描述,并将其感兴趣的信息和数据有效推送,以此满足用户的使用需求[1]。
1概述
1.1知识图谱
知识图谱基础概论是由互联网公司提出来的,其主要的目的和功能是优化搜索引擎,以关系数据知识库为基础,对数据进行标准化、确定性的关联与检索,从而提升搜索服务质量,提高平台探索结果关联性、可解释性。为了丰富知识图谱关联探索结构,技术人员要进行全面分析,合理利用知识图谱,结合知识图谱实体之间的关联,将搜索内容作为真实实体结构,构建一个完整、真实的知识系统性组织。
在知识图谱中,“反映现实世界的概念或者是具体事物的形式”一般是通过节点数据形式,即将知识、信息建立成一个实体结构。在知识库的基础上,将不同种类的知识系统进行完善,从而形成知识图谱。并且,为了反映实体间的关联,需要进行结构标识,将实体结构、关系等组合形成知识图谱中的基础单位,确保实体与实体之间相关属性,丰富了知识图谱节点内容。比如,当用户在平台结构上关注了B平台,就可以利用组合平台组合标识-A关注为B。由于此知识图谱通过组合形式针对现实世界实体以及内部关系进行结构标识,所以就本质上而言,知识图谱是结构化语义知识库。
1.2Web服务推荐
Web服务推荐在实施过程中,其目的是有效解决用户服务的现实问题,使其成为服务计算机领域研究的重点内容,而现代Web服务推荐发展中,知识图谱的引进与应用就有着重要意义。同时,在Web服务推荐的过程中,借助服务注册治理平台可以获取服务详细信息、用户详细信息以及用户调查等相关数据,从而结合数据特点以及模型自身重点建立有关推荐模型,进而有效提升用户服务质量。当前,在Web服务推荐技术产业发展中,其系统需要使用专业技术在用户协同推荐、物品协同推荐的基础上为用户提供准确服务。
1.2.1用户协同推荐
用户协同推荐就是在用户协同推荐规律和原则下,首先找到相近偏好的邻居,利用目标用户邻居对物品的评价进行全面预测,随后根据预测评分的实际顺序进行推送,并建立用于协同过滤推荐用户行为表,为后续的用户服务提供数据参考。
1.2.2物品协同推荐
物品协同推荐是以物品协同过滤为重点,对物品的相似性进行详细分析,物品协同过滤计算方式同样需要依靠用户行为表格,通过用户基础行为表格,详细计算出物品之间的相似度,随后根据服务评分开展信息预测,以此为用户提供针对性的推荐服务。
2基于知识图谱视域的Web服务推荐技术的算法架构
2.1图聚类算法
图聚类算法是一种将数据与信息以分组形式进行的计算方式。其计算原理是将一个初始数据结合之后进行连续分类,最后得到不同子集,确保相同子集中不同元素之间具有较高相似度,在對知识图谱结构进行区域划分后的实际计算中,需要采用的计算方法包含GN计算法、标签传播计算法以及Fastunfolding计算法[2]。因此,图聚类算法从本质上来看是系统结构具有紧密节点的聚合类计算方法。
2.1.1CN计算法
CN计算法作为典型的分裂结构计算模式,在实施环节上需要根据社区内部高聚合以及不同社区之间的低聚合特点进行综合分析,由于该计算方法能够有效去除连接不同社区的边缘线,使不同社区之间更加聚合,所以该计算方法针对边缘判断主要通过边缘所产生介质数量完成。
利用CN计算法开展信息计算时,边缘介质数是一个固定参数,主要为节点两边最短距离所需要经过频率次数,所以如果两个社区需要通过某一条边缘结构进行相互连接,则两个社区之间的节点最短路线通过边缘次数和频率会不断增加。因此,在实际开展信息和参数计算时,应根据边缘介数的核心定义,确保经过此边缘参数更大,CN计算法就是以这种计算原理,对删除边缘参数不断重复操作,直至社区满足划分需求。
2.1.2标签传播计算法
标签传播计算法从本质上来看是一种典型从下至上的社区分类计算方法,标签传播计算方法的分类核心思想则是节点标签标注,直接取决于相邻节点的数据标签,所以利用此计算法时,需针对每个节点统计当下节点所有连接属性标签,将具备节点数量最多的标签赋予当下节点,利用标签传播计算法,首先需要为每一个节点建立初始化的标签;其次,实现传播。并且,在每一次的更新迭代中传播思想,并不断发展,最终使得在标签不断传播过程中,将一些具备共同社区的标签阶段划分在相同社区环境中。
2.1.3Fast unfolding计算法
关于使用图聚类算法,无论是分裂型CN计算法,还是凝聚性标签传播计算法,都没有一个量化的指标针对社区划分质量开展优化与衡量。换言之,社区无论是运算到什么程度都会被认定为最佳结果。比如,以CN计算法作为实际案例,通过从上至下的社会分裂开展划分,其分裂终止条件无法开展最优化的项目设定,所以社区划分质量需要根据基础条件设定出不同类型的较大波动。
使用标签传播计算法时,更新迭代次数与频率同样无法被有效设定,由于图谱存在异常节点数据时会出现标签震动等情况,无法得到高质量、高水平的社区划分,所以模块化概念被广泛使用。
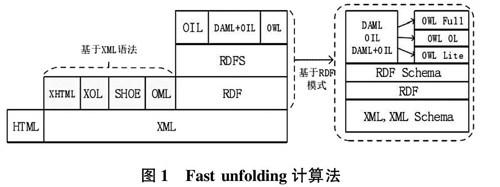
Fast unfolding计算法主要通过模块进行社区划分,判断出社区发现计算方法,一般来说,将模块化最大程度社区划分作为最优的区域。Fast unfolding计算法在实施过程中,首先将社区内每个节点初始化不同社区管理区域中,对每个节点开展详细划分,将计算阶段与相邻节点划分至相同社区环境中,以此作为基础条件。计算划分之后的模块与没划分的模块数据,如果两者之间差值为正值,则表示模块增加,如果差值为负值,则视为错误参数需要放弃。Fastunfolding计算法如图1所示。
2.2基于知识图谱的算法框架
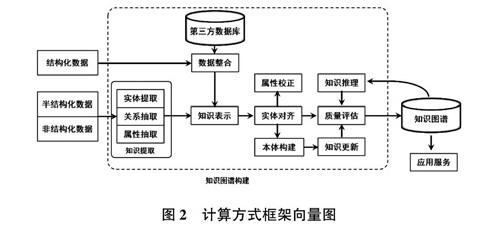
从本质上来看,知识图谱计算方式框架制定是对专业知识的抽象管理,所以框架主要使用本体知识模型建立方式,将本体概念建立在数据结构层上,其中知识图谱的本体结构是知识库的概念模板,通过本体数据所形成的知识库,不仅自身结构层次划分清晰,并且所产生的数据与信息冗余度较小。计算方式框架向量图如图2所示。
综上可知,本体所描述的语言作为知识图谱的算法框架基础语言模式,是框架语言的一种宽泛表示,让用户为框架编写清晰、表面化的概念描述。针对此现状,本体语言通常具有语言清晰、含义清晰以及便利性优势和特点,能够按照标记语法进行种类划分。
3Web服务知识图谱的构建分析
3.1数据采集
在Web服务知识图谱构建过程中,若要保证图谱构建合理性,首先须对知识图谱结构所产生的数据和信息全面收集[3],如利用程序软件针对Web服务网站中相关数据进行全面收集和分析时,会借助Programmable Web。由于Programmable Web网站是全球范围内网站的主要服务平台,由此,不少互联网企业都需要通过该网站发布相应的服务,这样才能够实现用户使用的便利性。
Programmable Web网站在实际建设环节上还发布了大量网页API以及APP等,并且数据收集方面还包含世界地圖、城市旅游以及自然天气等大量实时信息。由于该网站的服务数据与信息主要通过网页管理模式所呈现,并且大多数属于半结构数据,所以对其进行使用时需要利用专业技术针对网页中的半结构化数据和信息予以全面抽取,获得大量与服务相关的网页数据,并将相关数据初步存储在关系型数据库中。
3.2Web服务知识图谱的可视化
在知识图谱下的Web服务推荐技术实施过程中,图谱中的知识通过大量信息联系在一起,因此当平台数据被频繁查询和更新时,关系数据库处理会产生许多信息连接查询,造成平台性能问题。为此,使用图库能够对数据储存与提取方式合理规划,使图谱数据库在使用环境下较关系型数据库来说具有更高性能,同时在图谱数据库中以更加直观的图形展现。由此可见,图谱数据库在建设过程中能够针对平台进行图谱可视化操作。
本次研究主要使用谱图数据库进行Web服务,以确保图谱数据储存和可视化操作。NE04J是一种基于图谱的非关系数据库,现阶段该数据库应用范围比较广,尤其在数据搜索或者推荐等领域中被广泛使用,如电商平台以及沃尔玛等大型超市均使用该平台。除此之外,NE04J平台上的节点可以与其他任何节点构建出连接关系,并且以每个节点作为基础条件设置多个属性,其中每一个关系必须具有开始节点或者结束节点,以有效构成一个系统小组。现阶段,谱图数据库种类较为复杂,除了NE04J平台以外,同样有其他类型的平台结构,但是NE04J平台在实施过程中,无论是信息储存还是查询都需要使用图形结构开展参数计算,该平台在数据库储存时,即使没有使用谱图结构,各个阶层同样利用关系型数据库进行数据和信息储存。由此可见,NE04J平台管理效率更高。
知识图谱的实际情况与关系在平台上主要以节点与边缘呈现,确保实体的信息与数据能够直接储存在节点中,在信息查询时能十分直观清晰地观察到各个数据节点的使用属性。在Web服务推荐技术应用中,知识图谱中单个节点质保函的实体基础属性信息与数据并不能包含之间的关系,如Mashup FollowFly关联了三个服务——YouTube,Facebook和Twitter。显然,借助知识图谱可以较好地表示这种联系,从而实现信息与数据之间关联性确定。
4总结
互联网的高速发展让网络服务的类型逐渐增多,功能也更加复杂,为了解决传统开发模式中面临的问题,面向服务架构应运而生。随着面向服务架构的逐渐成熟,互联网中大量的Web服务涌现出来,需要不断加强对知识图谱下的Web服务推荐技术的研究,以推动互联网技术的持续发展。
猜你喜欢
现代情报(2016年11期)2016-12-21
现代情报(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
现代情报(2016年10期)2016-12-15
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
商场现代化(2016年23期)2016-11-17
中国教育信息化·基础教育(2016年9期)2016-10-18
电脑知识与技术(2016年7期)2016-05-19
