
基于深度学习的手机照片分割
2022-04-29 13:12孙煜
计算机应用文摘 2022年16期

摘要:随着智能手机的广泛应用,手机照片的人像抠图、人脸美颜、人物特效等应用均依赖照片分割技术。应用基于人工智能的深度学习技术,可以对手机照片进行快速、精确分割。由于智能手机算力 有限,文章设计了一种轻量级的深度学习模型,将手机照片进行区域划分,并标注区域属性,提取区域轮廓,可实现快速的人体分割、物体分割、场景分割等功能。同时,在智能手机平台进行照片分割实验,实验结果验证了该方法可行。
关键词:深度学习;分割技术;卷积网络;智能手机
中图法分类号:TP391 文献标识码:A
Mobile phone photo segmentation based on deep learning
SUN Yu
(Qualcomm Enterprise Management (Shanghai) Co.? Ltd.? Shanghai 200000? China)
Abstract: With the widespread use of smartphones, applications such as portrait matting, face beautification, and character special effects of mobile phone photos all rely on photo segmentation technology. The application of deep learning technology based on artificial intelligence can quickly and accurately segment mobile phone photos. Due to the limited computing power of smartphones, this paper designs a lightweight deep learning model that divides mobile phone photos into regions, annotates regional attributes,and extracts regional contours,which can achieve fast human body segmentation, object segmentation, scene segmentation and other functions. At the same time,the photo segmentation experiment is carried out on the smartphone platform, and the experimental results verify the feasibility of the method.
Key words: deep learning, image segmentation
1引言
智能手机因具备强劲的运算处理能力,其在日常生活中的应用逐渐广泛。近年来,随着智能手机的图像处理引擎(GPU)日益强大,深度学习技术逐渐应用于智能手机平台,进而使手机照片的人像抠图、人脸美颜、特效叠加、虚拟背景等功能成为标配。以上应用均依赖图像分割技术的照片区域划分功能,包括人体轮廓、场景边界、及物体边沿等。然而,目前针对手机照片的图像分割技术普遍存在人体边沿轮廓粗糙等问题,分割精度有待高,导致应用效果大打折扣,降低了用户体验。国内已有不少图像分割的相关研究,但多数限于AI开放平台和深度学习主机。相较之下,智能手机的算力有限,相关图像分割方法很难移植到智能手机平台,难以实现实时、快速分割图像的目标。在智能手机应用中,运算速度和运算精度始终是一对矛盾。
本文致力于突破智能手机运算速度和运算精度的瓶颈,设计了一种高效、轻量级的深度学习网络,建立了基于手机照片进行图像分割的模型,可以将手机照片进行快速、精确分割,有利于提高手机照片的应用效率,增强了用户体验。实验结果表明,本文设计的手机照片分割方法,在保持较高的分割精度前提下,极大提高了其在智能手机上的运算速度。
2图像分割算法
2.1深度学习框架
深度学习最早由Hinton等人于2006年提出,是基于机器学习和神经网络发展而来,拥有更深层的特征学习和任务感知结构。深度学习通过学习样本数据的内在规律和表示层次,并提取数据的不同维度的特征,从而使模型的感知能力逼近人工感知的精度,让模型能够像人一样具有分析和学习能力。常见的深度学习模块可分为卷积神经网络(CNN)、循环神经网络(RNN)、注意力机制(Attention),以及Google团队在2017年提出的Transformer模块等。
卷积神经网络(CNN)由普通神经网络进化而来,包含一个由卷积层、子采样层(池化层)和全连接层构成的特征抽取器[1]。其中,卷积层通过不同权值的卷积核,提取由不同通道排列而成的神经元,从而生成具备强大表达能力的特征图。同时,通过池化层降低特征的维度,使特征具备更高级的表达能力。此外,全连接层将特征转化为任务输出,包括分类任务(图像分类)和回归任务(图像分割)。得益于其强大的特征表达能力和任务学习能力,CNN广泛应用于各种场景。本文将CNN应用于图像分割任务,并为智能手机设计了一套精确、快速的图像分割算法。
2.2圖像分割算法
在深度学习技术中,图像分割算法的目的是清晰、精确地切割出物体的轮廓。目前,经典的图像分割深度神经网络结构UNet等已经取得了不错的分割效果。而Mask-RCNN则能够在一个模型中同时实现分割和物体分类,进一步提升了分割效果[2]。然而,目前还有几个问题对图像分割领域造成困扰:(1)轮廓精度有待提高,包括边缘缺失及边缘泄露至背景等问题;(2)部分应用(如人物抠图)要求图像分割算法能够精确勾勒出人物的毛发轮廓;(3)运算速度瓶颈,包括在开放AI平台(如Pytorch)的深度学习主机(搭载先进的Nvidia2080TiGPU)上,也很难做到快速、实时分割;(3)运行速度慢的问题在智能手机上尤其明显。目前,国内已有不少团队致力于突破“精度-速度”这一对矛盾的瓶颈,但效果有限。本文将经典的UNet网络进行了轻量化设计,并应用于智能手机的照片分割中,在保持高精确度的同时,大幅度提高了运行速度。
3手机照片分割算法
3.1算法流程
手机照片的分割算法为UNet,输入的手机照片经过UNet网络进行特征提取和分割轮廓计算,最终输出分割后的图片[3]。UNet拥有一个对称的结构,左半边是编码器,右半边是解码器。图像先经过编码处理,再经过解码处理,最终实现图像分割。它们的作用如下:编码器—使模型理解图像的内容,但是丢弃了图像的位置信息;解码器—使模型结合编码器对图像内容进行理解,恢复图像的位置信息,同时保留了图像内容信息。
图片经过编解码器之后,得到包含图像位置和内容信息的特征图,再经过回归网络,输出图片分割结果。分割后的图像将人像和背景清晰地分离开,并且精确勾勒出了人像轮廓[4]。
除了编解码器之外,UNet还具备以下几方面特性:(1)通过卷积和下采样池化层,提取不同分辨率的特征图,从而保留不同图像尺寸下的特征,如小尺寸特征图可保留人体在图中的位置信息,排除其他细节的干扰。而大尺寸特征图可保留人体轮廓的细节,如毛发和五官等;(2)编解码器之间拷贝多个不同尺寸的特征图,从而共享各自模块的优势;(3)通过1×1的卷积核,实现更深度的卷积操作。
3.2UNet网络的优化和加速
目前,UNet结构存在如下问题:采用3×3卷积模块,虽然特征提取精度较高,但计算速度缓慢,这是图像分割存在速度瓶颈的主要因素[5]。本文将UNet中所有的3×3卷积模块(ConvNode)替换成了一种深度可分离卷积模块(Separable-ConvNode),在保留图像分割精度的基础上,极大提高了UNet的运算速度。因此,本文将UNet升级为全新的Separable-UNet。卷积模块的替换方式如图1所示。
经过替换,可比较卷积的参数量以及计算速度的提升:(1)3×3卷积核的参数量为3×3×c1×c2,其中c1和c2为卷积模块的输入和输出通道数;(2)本文设计的3×3可分离卷积模块参数量为3×3×c1+1×1×c1×c2。例如,在c1=128,c2=256的情况下,一个3×3卷积模块的参数量为294192,而本文设计的一个3×3可分离卷积核的参数量为1152+32768=33920,参数量降低为之前的11.54%。通过实验证明,图像分割运算可以获得3倍的加速效果。
4实验
4.1实验环境搭建
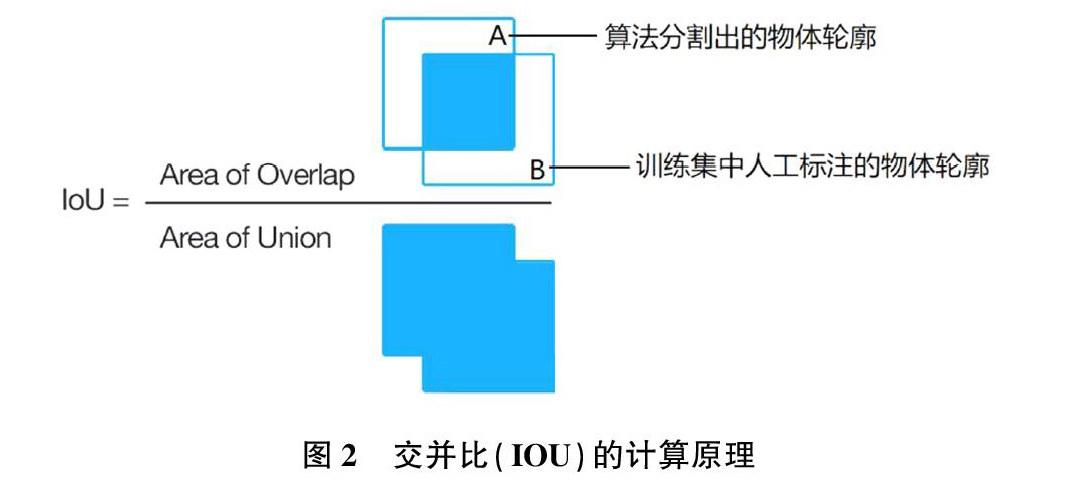
本文的实验在两种环境下完成:(1)算法训练平台为深度学习主机—GPU为Nvidia2080Ti(12GB显存),CPU为Inteli7-12700;(2)算法测试平台为智能手机—小米12Pro。图片分割的训练集采用了通用的COCO数据集。该数据集包含大量图片分割训练样本,包括人脸、人体、动物、日用品、交通工具等轮廓标注,训练成的模型具有优良的分割精度和泛化性。分割精度的衡量指标为交并比(IOU),计算方式如图2所示。
IOU可理解为算法分割出的轮廓和理想(人工标注)的轮廓之间的偏差,该算法的IOU值越大,表明偏差越小,分割精度越高。
4.2实验对比
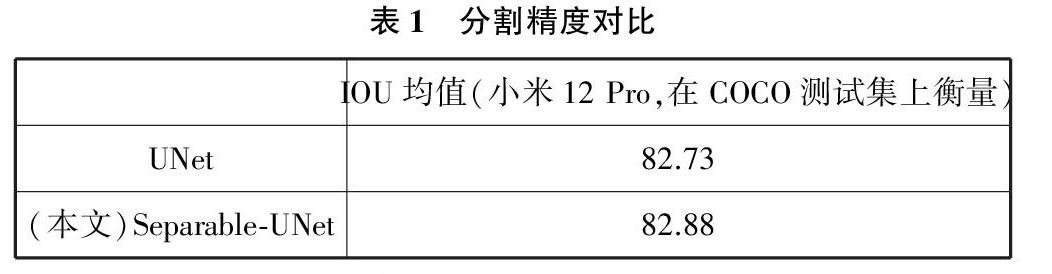
图像分割网络的训练采用COCO数据集,分别训练了传统的UNet和本文设计的Separable-UNet,并对两者的精度和运行速度进行了全面比较,从而展示了Separable-UNet的高精度和分割速度大幅度提升。比较图集为COCO测试集,包含分割轮廓的人工标注。如表1和表2所示,IOU和分割速度两个指标均为所有图片上取的平均值。从表1可见,本文方法和传统UNet相比,保留了较好的分割精度,两者精度几乎一致。从表2可见,本文方法实现了3倍的速度提升,在智能手机上,实现了每张图68.1毫秒的分割速度。实验结果验证了本文的结论,即Separable-UNet在保留高精度的前提下,在分割運算速度上大幅提升,为手机照片的分割提供了高速解决方案。
4结论
本文在经典图片分割网络UNet上进行改进,设计了全新的Separable-UNet网络。在保留较高精度的基础上,将UNet的分割速度提升了3倍,在智能手机平台上的分割速度达到了每张图68毫秒,大幅度提升了运算速度,提高了用户体验和手机运行的流畅度,并且使图像分割技术更有效地应用于智能手机上层,包括人像抠图、人脸美颜、特效叠加、虚拟背景等,促使智能手机更广泛地应用于生活中的各种场景。接下来,我们的目标是进一步改进Separable-UNet网络,将分割技术从手机照片扩展到手机视频,服务于网络直播、短视频创作等更广阔的应用场景。
参考文献:
[1]刘颖,刘红燕,范九伦,等.基于深度学习的小目标检测研究与应用综述[J].电子学报,2020,48(3):590-601.
[2]马原东,罗子江,倪照风,等.改进SSD算法的多目标检测[J].计算机工程与应用,2020,56(23):23-30.
[3]张新明,祝晓斌,蔡强,等.图像语义分割深度学习模型综述[J].高技术通讯,2017(9):808-815.
[4]杜星悦,董洪伟,杨振.基于深度网络的人脸区域分割方法[J].计算机工程与应用,2019,55(8):171-174.
[5]韩贵金,朱虹.一种基于图结构模型的人体姿态估计算法[J].计算机工程与应用,2013,49(14):30-33.
作者简介:
孙煜(1983—),博士,工程师,研究方向:人工智能。
猜你喜欢
红领巾·萌芽(2022年9期)2022-11-24
军事文摘(2019年18期)2019-09-25
趣味(语文)(2018年8期)2018-11-15
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
现代工业经济和信息化(2016年4期)2016-05-17
