
面向空间机械臂的视触融合目标识别系统
2022-04-27 07:27:12沈书馨宋爱国阳雨妍倪江生
载人航天 2022年2期
沈书馨, 宋爱国, 阳雨妍, 倪江生
(东南大学仪器科学与工程学院, 南京 210096)
1 引言
空间机器人是应用于太空环境,辅助或替代机器人完成危险作业的机器人。 自20 世纪起,各国大力发展空间机器人,尤其是空间机械臂相关技术,研制了一系列空间机械臂作业系统,进行了大量遥操作实验。 1981 年哥伦比亚号航天飞机搭载了加拿大机械臂操作系统(Shuttle Remote Manipulator System,SRMS),采用无力反馈的在轨遥操作模式进行作业。 其后NASA 研制的FTS系统和DFT-1 系统、德国航宇中心研制的空间站小型机械臂系统ROTEX 和舱外ROKVISS 系统均搭载多种传感器,实现了基于临场感的在轨或远程遥操作模式。 NASA 于1999 年提出了机器人航天员(Robonaut),其操作主要分为遥操作模式和自主操作模式,开始探索空间机器人自主、半自主操控技术。
目标识别技术是空间机械臂自主操控的核心技术,是空间机械臂智能抓取和操作的前提。 视觉信息和触觉信息是机器人感知系统的重要传感模态。
由于视觉传感器发展较为成熟,基于视觉信息的目标识别是当前机器人进行目标识别的主要方式。 视觉传感器本身具有一定的局限性,在太空环境中视角单一,面对遮挡、光线条件复杂、物体视觉信息相近等情况时,仅凭借视觉信息难以完成识别任务。 随着触觉传感器不断发展,精度等方面逐步完善,触觉信息辅助视觉信息,提取出物体软硬度等特征,很好地解决空间目标识别困难这一问题。
在触觉感知领域,Aggarwal 等使用自研的高分辨率触觉传感器,采集深海物体触觉图像,通过局部特征匹配和全局特征匹配算法,完成了对45 种物体的识别;Chu 等使用安装有BioTac 传感器的PR2 机器人二指爪,对60 个物体采集抓取过程的触觉数据,利用机器学习算法提取特征信息,实现了物体表面材质的分类。
在视 觉 触 觉 融 合 方 面,Watkins⁃Valls 等构建了用于触觉信息与视觉深度信息数据融合的三维卷积神经网络,以预测物体的几何结构;刘华平等提出一种用于视觉触觉信息融合的联合核稀疏编码(Joint Group Kernel Sparse Coding, JGKSC)方法,实现了对18 种常见物品的分类,准确性相比单一触觉或视觉识别有所提高。
本文提出一种基于卷积神经网络和门控循环单元CNN⁃GRU(Convolutional Neural Networks -Gate Recurrent Unit)的面向空间机械臂的视触融合模型目标识别系统。 系统通过点云定位、路径规划实现空间机械臂对目标物视觉及触觉信息的自主采集,利用深度学习在特征提取和数据融合方面的优势,通过CNN⁃GRU 网络对视觉信息和触觉时序信息进行特征提取融合,最终实现对目标物的识别。 基于视触觉融合的目标识别实验构建了目标物体视觉触觉数据库,并初步验证了系统的有效性。
2 系统构成
空间机械臂目标识别系统的基本模块主要包括:Schunk LWA 4D 型七自由度机械臂、Barrett BH8-282 型三指灵巧手、Kinect 深度相机以及基于ROS(Robot Operating System)机器人操作系统的控制与识别系统,如图1 所示。

图1 空间机械臂视触融合目标识别实验系统Fig.1 Visual⁃tactile fusion target recognition experi⁃mental system for space manipulator
控制与识别系统基于ROS 进行开发,分为点云定位模块、路径规划模块、机械臂运动控制模块、灵巧手运动控制模块和目标识别模块,如图2所示。 空间机械臂目标识别系统工作时,Kinect相机置于工作空间前方固定位置,采集目标物三维点云信息和视觉图像,将点云信息送入点云定位模块进行目标物定位;路径规划模块根据定位信息进行运动轨迹规划,交由控制模块控制机械臂和灵巧手完成目标接触及抓取操作;灵巧手上的触觉传感器采集抓握过程的触觉数据;最后由目标识别模块根据触觉数据和视觉图像完成识别任务。
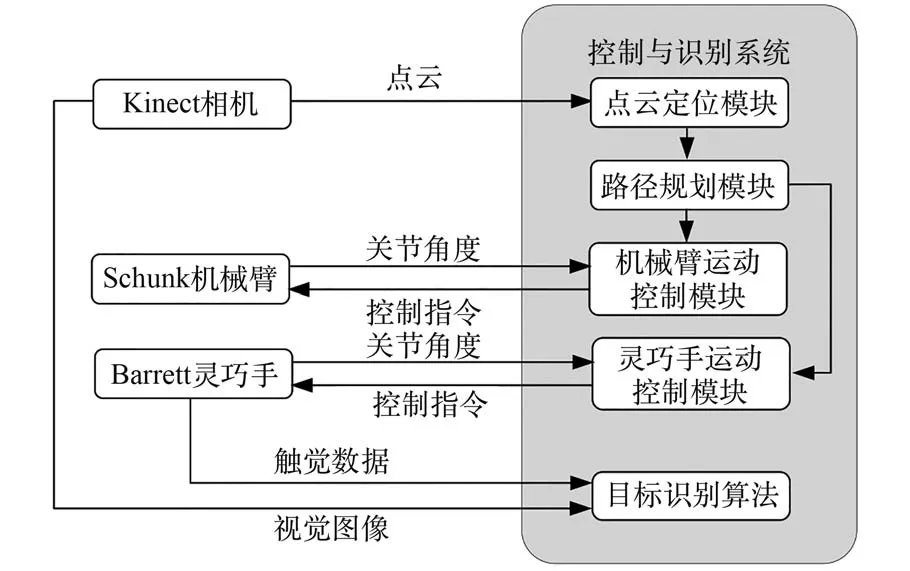
图2 系统工作框图Fig.2 Block diagram of system working
3 目标定位与视触觉数据采集
3.1 基于点云的目标定位与路径规划
对目标物的定位是实现自动抓取,完成触觉数据采集的前提。 Kinect 相机采集的原始点云图像如图3 所示,对其进行如下操作:①采用直通滤波分离背景;②采用随机采样一致算法(Random Sample Consensus,RANSAC)拟合平面,实现桌面分割;③采用Voxelized 网格法降采样;④采用有向包围盒(Oriented Bounding Box,OBB)获取相机坐标系下的目标物位姿信息(,y,) 。

图3 点云定位处理Fig.3 Point cloud positioning processing
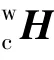
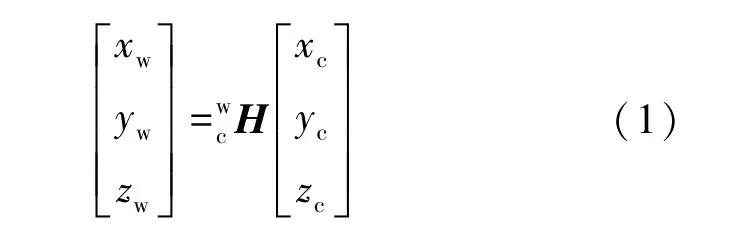
选择ROS 系统中运动规划库OMPL(the Open Motion Planning Library)内置的快速扩展随机树(Rapidly Exploring Random Tree,RRT)算法作为本系统中的路径规划模块。
RRT 是一种基于采样的多维空间规划算法。将轨迹的初始点作为根节点,在节点周围三维空间中进行随机采样作为叶子节点,经过层层采样,进而生成随机扩展树。 若生成的随机树中的叶子节点包含了目标点,则可以在随机树中找到一条由从初始点到目标点的路径。 该算法能高效地在高维空间进行路径规划,并对采样点进行碰撞检测。
3.2 触觉数据采集与预处理
触觉数据采用Barrett 灵巧手指尖搭载的阵列式触觉传感器采集,如图4 所示。 灵巧手每个指尖部位安装有独立的触觉传感阵列,每个阵列包含24 个采集通道。 由控制系统根据目标物位姿信息自主规划,引导机械臂和灵巧手完成抓取动作,采集抓握过程触觉信号,采样频率为20 Hz。

图4 触觉数据采集Fig.4 Tactile data collection
选取3 个指尖触觉阵列的共72 个通道数据组建触觉数据集。 触觉数据的处理过程主要包括平滑滤波、降维、拼接、滑动窗口采样以及归一化。
1)平滑滤波。 对每个通道数据进行平滑滤波,去除噪声。 采用大小为5、步长为1 的滑动窗口,去除最大值和最小值后,进行均值滤波,计算过程如公式(2)所示:
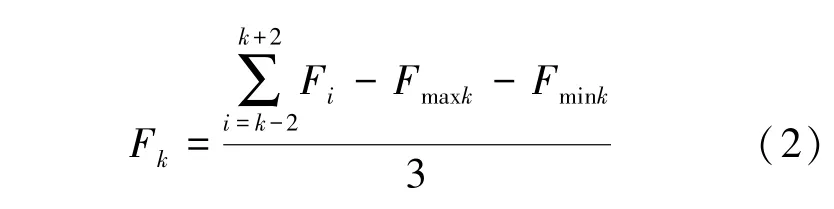
式中,F表示时刻该通道采集到的触觉数据,滑动窗口为[-2,+2],表示该滑动窗口内触觉数据最大值,表示该滑动窗口内触觉数据最小值。
2)降维与拼接。 如图5 所示,某时刻单个手指采集到二维触觉阵列,将其按编号1 ~24 的顺序展开为一行24 列的一维序列,再将3 个手指的数据头尾相连拼接为一行72 列的一维序列。 将一次完整抓取过程中的触觉采样序列,在行方向按时间顺序拼接,形成触觉时间序列,如图6所示。

图5 触觉数据处理Fig.5 Tactile data processing
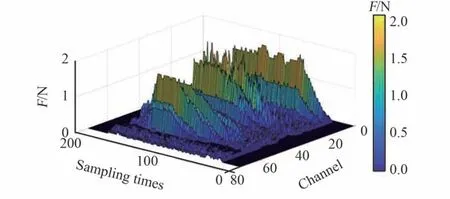
图6 抓取全程触觉时间序列Fig.6 Tactile time sequence of crawling
3)滑动窗口采样。 使用滑动窗口的方式,沿时间方向,窗口长度为40,滑动步长为5,形成大小为40× 72 的触觉样本,如图7 所示。

图7 触觉时间序列样本Fig.7 Samples of tactile time sequence
4)归一化。 对触觉样本进行归一化处理,将每个触觉数据除以该抓取模式下的抓取力最大值。
4 视触融合神经网络模型
深度学习是一种区别于传统机器学习的特殊机器学习方式,由网状层级结构构成,其中含多隐层的多层感知器就是一种深度学习结构。 深度学习模型主要有卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Networks, RNN)、生成式对抗网络(Gener⁃ative Adversarial Networks, GAN)等,适用于不同的应用场景。
4.1 卷积神经网络CNN
CNN 的结构如图8 所示,主要有输入层、卷积层、池化层和输出层组成。
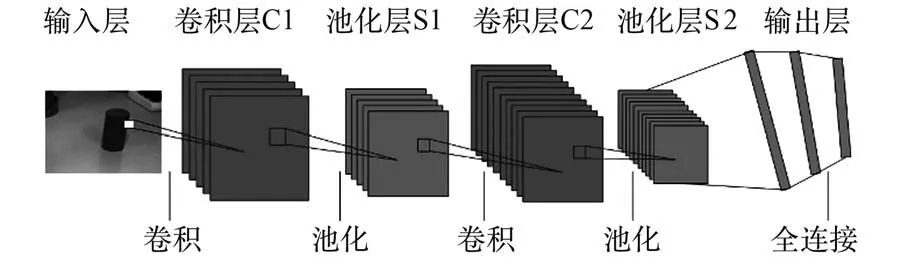
图8 卷积神经网络结构Fig.8 Structure of CNN
输入信息经过多层卷积池化操作形成特征图。 将特征图按照行展开连接成向量,传入全连接层。 全连接层为一个BP(Back Propagation)反向传播神经网络,通过梯度下降和反向传播算法进行训练。
4.2 门控循环单元GRU
门控循环单元GRU(Gate Recurrent Unit)是以序列数据为输入的递归网络。 GRU 能挖掘数据中的时序信息以及语义信息,在解决语音识别、行为检测、机器翻译等涉及时序的问题上发挥了重要作用。
如图9 所示,GRU 由重置门和更新门组成,重置门决定新输入信息与记忆信息结合的方式,更新门决定了当前时间步对记忆信息的保存量,其更新方式如式(3)~(6)所示:

图9 门控循环单元结构Fig.9 Structure of GRU


4.3 视触觉信息融合CNN⁃GRU 模型结构
针对视觉触觉信息融合问题,本文设计了如图10 所示双输入神经网络。 由于视触信息不同的特性,将视觉信息和触觉信息分别送入神经网络进行特征提取,提取得到的特征向量进行拼接后再送入全连接层进行训练。 在参考经典神经网络的基础上对比分析得到网络参数,如表1 所示。

表1 CNN⁃GRU 各层网络参数Table 1 Parameters of layers of CNN⁃GRU
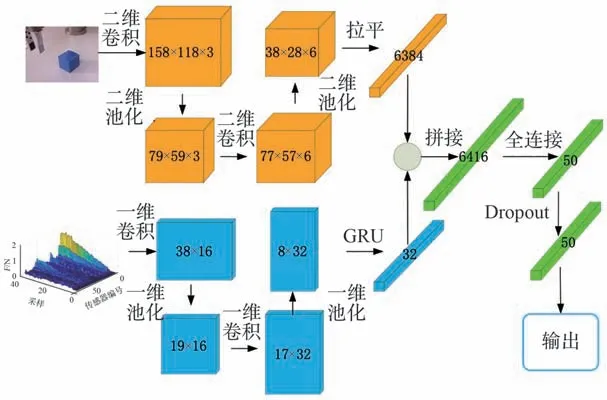
图10 视触觉融合网络模型Fig.10 Network model of visual and tactile fusion
1)视觉特征提取。 视觉数据为160× 120 像素3 通道RGB 图像,使用多核多通道卷积操作进行特征提取。
第一层网络采用3 个3× 3 卷积核对3 通道进行卷积,卷积结果输入激活函数,得到158×118×3 的特征值矩阵。 采用步长为2,大小为2× 2 的最大池化,对特征进行下采样为79×59× 3 的特征值矩阵。
第二层网络采用6 个3× 3 卷积核对第一层网络输出的特征值矩阵进行卷积,卷积结果输入激活函数,得到77× 57× 6 的特征值矩阵。采用步长为2,大小为2× 2 的最大池化,对特征进行下采样为38× 28× 6 的特征值矩阵。
将卷积形成的38×28×6 特征矩阵拉平为一列6384 的特征向量。
2)触觉特征提取。 触觉数据由72 个触觉阵列传感器,以20 Hz 频率采样,按时间序列排列得到,数据大小为40× 72,采用一维卷积与门控循环单元相结合的方式进行特征提取。 CNN 网络能够提取数据中的空间信息,GRU 具有长期记忆功能,能够有效分析数据的时间变化关系,两者结合能有效提取触觉信息的特征。
第一层网络采用16 个大小为3 的卷积核对触觉数据沿时间方向进行一维卷积,卷积结果输入激活函数,得到38× 16 的特征值矩阵。采用步长为2、大小为2 的最大池化,按时间方向对特征进行下采样为19× 16 的特征值矩阵。
第二层网络采用32 个大小为3 的卷积核对第一层网络输出的特征值矩阵进行一维卷积,卷积结果输入激活函数,得到17× 32 的特征值矩阵。 采用步长为2、大小为2 的最大池化,按时间方向对特征进行下采样为8× 32 的特征值矩阵。
第三层网络采用神经元数为32 的GRU 门控循环单元对第二层网络输出的特征值矩阵进行时序特征提取,形成大小为32 的特征向量。
3)特征融合分类。 视触觉信息融合为特征层面的融合,对提取完的视觉特征和触觉特征进行拼接,分类网络采用全连接网络实现。
在全连接层之前进行,将提取完的视觉特征和触觉特征按列方向进行拼接[] ,形成一维视触特征向量。
第一层全连接层神经元个数为50,激活函数为。 引 入Dropout 层 防 止 过 拟 合, 参 数为0.5。
输出层神经元个数为物品类别数14,激活函数为,实现物品类别的输出。
5 算法验证
5.1 实验物品选择
根据实验目的,对比分析单一视觉、触觉、视触融合网络对复杂光线、单一视角下相似目标识别情况。 选取具有对照价值的14 种物体,分别为:(a)软泡沫蓝色扁方块;(b)硬泡沫蓝色扁方块;(c)铁制蓝色扁方块;(d)软泡沫蓝色圆柱;(e)蓝色硬纸盒;(f)硬海绵红色方块;(g)塑料红色圆柱;(h)硬海绵红色圆柱;(i)塑料蓝色高方块;(j)软泡沫蓝色高方块;(k)木制红色方块;(l)硬海绵球;(m)充气球;(n)卷纸。 如图11 所示,材质为软泡沫、硬海绵、塑料等软硬不同材质;颜色为红色、蓝色;形状为圆柱、扁方块、高方块、球体。 其中存在多组对照,如表2 所示。

图11 14 种物体Fig.11 14 kinds of objects

表2 样本对照组Table 2 Sample control groups
5.2 视触觉数据集组建
视觉采样对复杂光线条件下、不同角度、不同遮挡情况下的实验物品进行拍摄,如图12 所示。每个物品采集图像200 张,分辨率为160× 120,删除其中物品占比过小或失真严重的图像。 使用镜像和翻转等重采样操作对样本量进行扩充,最终形成样本量为7960 的视觉数据集。

图12 视觉数据采集Fig.12 Visual data collection
触觉采样一次完整抓取过程分为恒速抓紧、保持、恒速释放3 个阶段。 每种物品进行20 次抓取,经过处理及滑动窗口采样,最终形成样本量为3025 个的触觉数据集。
对于触觉数据和视觉数据,由于其触觉数据与视觉数据之间无一一对应的强匹配关系,所以采取在同一类物品内部弱匹配方式。 如图13 所示,对于某一物品的每个视觉样本,随机抽取该物品触觉数据集的2 个触觉样本,组成2 组视觉触觉样本对,最终形成15 920 组视觉触觉对,组成视觉触觉数据集。
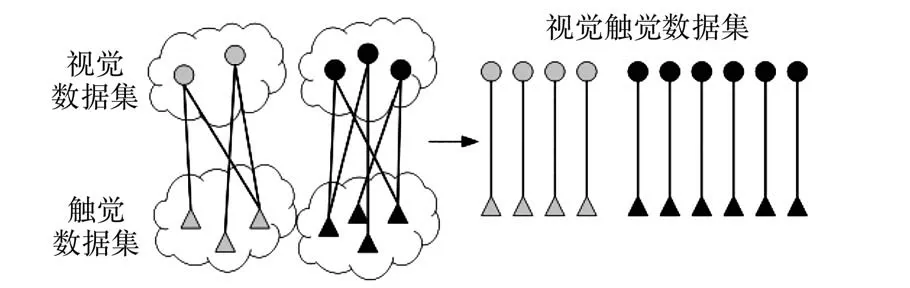
图13 视觉触觉融合Fig.13 Visual tactile fusion
5.3 算法比对
为了验证本文设计的视触觉融合神经网络在物体识别方面的优势,设置一定的传统分类网络、单独视觉触觉神经网络进行对照。
实验基于Python 下的tensorflow、keras 库搭建神经网络算法,基于sklearn 库搭建K 邻近算法(K⁃Nearest Neighbor, KNN) 和 支 持 向 量 机(Support Vector Machines, SVM)算法。 将视觉、触觉、视触觉数据集分别按照1 ∶1 ∶4的比例划分测试集、验证集和训练集,并打乱样本顺序。KNN⁃V、SVM⁃V 和CNN⁃V 网络使用视觉数据集进行训练;KNN⁃T、SVM⁃T 和GRU⁃T 网络使用触觉数据集进行训练;KNN⁃VT、SVM⁃VT、CNN⁃GRU和CNN⁃LSTM 网络采用视觉触觉数据集进行训练。
训练环境:CPU 为Intel Core I7 6900K 8 核,运行内存RAM 为64 G,GPU 为2 个NVIDIA TI⁃TAN Xp CPLLECTORS EDITION,显卡内存12 G。
使用训练集和验证集对模型参数进行训练,使用测试集计算模型分类准确率,记录100次连续分类所需总时间,计算预测平均时间。训练过程观察模型的准确率与误差曲线,对模型的初始权值、学习率参数进行调整,获取最优识别模型。
图14 为视触融合CNN⁃GRU 网络训练过程的准确率和误差曲线。 训练过程学习率初始值为0.001,训练轮数为100。 最终训练样本准确率为97.5%、 误 差 为 0.104, 测 试 样 本 准 确 率 为97.8%、误差为0.131。 该结果表明CNN⁃GRU 网络能够有效利用视触觉特征,对单一视角下相似物体做出准确识别,符合空间机械臂目标识别系统的应用要求。
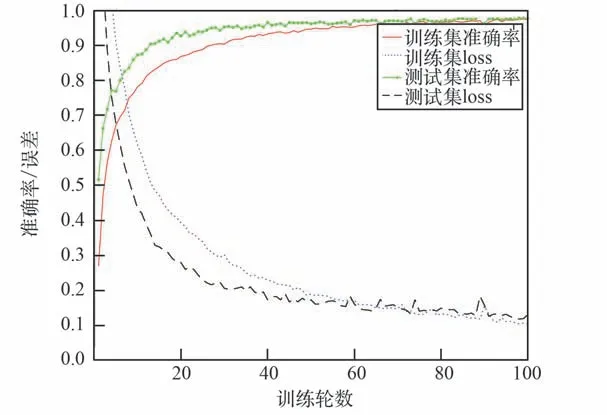
图14 CNN⁃GRU 网络模型训练曲线Fig.14 The training curve of CNN⁃GRU network model
对比表3 中各算法的准确率和预测时间,在同一传感器数据下,采用CNN 和GRU 网络的分类方式比传统KNN 和SVM 算法取得了更高的准确率,且预测平均时间大幅度下降。 同时CNN⁃GRU 网络比CNN⁃LSTM 准确率高6.3%,表明CNN 和GRU 网络能更有效地提取不同目标物视觉数据与触觉数据的特征。 针对同一类分类算法,使用视觉触觉融合方式的分类网络,比单一视觉或触觉的分类网络,准确率均有明显的提升。表明目标物视觉数据与触觉数据能够有效互补,弥补单一传感器下难以分辨的特征信息。

表3 各个算法的分类准确度和预测平均时间Table 3 Classification accuracy and average prediction time of each algorithm
本 文 提 出 的CNN⁃GRU 网 络, 准 确 率 为97.8%, 比 单 一 视 觉 CNN⁃V 网 络 识 别 提 升16.3%,比单一触觉GRU⁃T 网络提升15.8%,比视触觉融合CNN⁃LSTM 网络提升6.3%,同时预测时间更短,在该分类问题下拥有良好的性能。
对比CNN⁃V 视觉神经网络、GRU⁃T 触觉神经网络和CNN⁃GRU 视触融合神经网络的混淆矩阵如图15~17 所示,分析视触觉网络对物体的特征提取与识别状况。 在CNN⁃V 视觉神经网络下,网络有14%的几率将木制红色方块识别为塑料红色圆柱,将软泡蓝色高方块识别为塑料蓝色高方块,有16%的几率将硬泡沫蓝色扁方块识别为铁制蓝色扁方块。 而在GRU⁃T 触觉神经网络下,这3 种情况的误识别率均为0,能够做出有效区分。可知视觉网络的误识别主要发生在同色且外观相似物体之间,与物体的材质、软硬等属性几乎无关,触觉信息能对此缺陷做出有效弥补。

图15 CNN⁃V 网络识别结果的混淆矩阵Fig.15 Confusion matrix of recognition results of CNN⁃V
GRU⁃T 触觉神经网络在木制红色方块与蓝色硬纸盒之间发生了严重的误识别,错误率超过50%,同时也存在17%的几率将软泡沫蓝色高方块识别为硬海绵红色方块,11%的几率将塑料蓝色高方块识别为木制红色方块。 在视觉神经网络下,这3 种情况的误识别率也均为0%,能够做出有效区分。 CNN⁃V 触觉网络的误识别主要发生在形状、硬度相似的物体之间,与物体的颜色无关,视觉信息能有效弥补触觉网络对该特征的不足。

图16 GRU⁃T 网络识别结果的混淆矩阵Fig.16 Confusion matrix of recognition results of GRU⁃T

图17 CNN⁃GRU 网络识别结果的混淆矩阵Fig.17 Confusion matrix of recognition results of CNN⁃GRU
CNN⁃GRU 视触觉融合神经网络对所有物体均有较高的识别准确率,对于一半的物体准确率超过99%,误差主要产生于木制红色方块、硬海绵红色方块这类颜色、形状、软硬度都较接近的物体之间。
总体而言,面向空间机械臂的视触觉融合目标识别系统能够自主采集有效视觉触觉数据。 同时基于CNN⁃GRU 网络能有效地对视觉和触觉特征进行提取和融合,解决空间作业过程中视觉传感器视角单一、光线条件复杂导致的相似目标识别较差的问题,明显提高识别准确率和速度。
6 结论
1)基于ROS 系统设计点云定位、路径规划、机械臂控制和灵巧手控制模块,实现了对目标物视觉触觉信息的自主采集。
2)提出了基于CNN⁃GRU 网络的视触觉融合模型。 该模型通过卷积神经网络提取视觉特征,通过门控循环单元提取触觉特征,将特征向量拼接后送入全连接网络进行目标识别。
3)组建14 种分类样本数据集,进行算法验证。 实验表明,该系统能够有效利用视触觉信息的时空分布特性,解决空间作业过程中单一视觉传感器识别较差的问题,准确率为97.8%,比单一视觉CNN⁃V 网络和触觉GRU⁃T 网络识别分别提升16.3%和15.8%。 同时,相较于传统KNN 和SVM 网络,CNN⁃GRU 网络在预测速度和准确性方面都有极大的提升。 后续可继续补充真实空间机械臂作业场景样本及实验,并且优化模型参数,以达到未来更好地应用于实际空间机械臂作业的目的。
猜你喜欢
小学生学习指导(低年级)(2022年9期)2022-10-08 03:12:02
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
海外星云(2021年6期)2021-10-14 07:20:42
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:28
科普童话·学霸日记(2020年4期)2020-05-06 09:13:19
电子制作(2019年11期)2019-07-04 00:34:38
特别健康(2018年3期)2018-07-04 00:40:20
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
工业设计(2016年4期)2016-05-04 04:00:20
中外健康文摘B版(2014年8期)2014-06-27 06:33:03
