
地铁沿线老旧房屋结构安全预警模型*
2022-04-26 01:55段在鹏邱少辉俞思雅张一洋
中国安全生产科学技术 2022年3期
段在鹏,李 帆,邱少辉,俞思雅,张一洋
(1.福州大学 环境与安全工程学院,福建 福州 350108;2.中铝瑞闽股份有限公司,福建 福州 350108)
0 引言
城市快速发展过程中遗留大批隐患房屋,目前房屋排查完全采用人工排查手段,排查成本高、效率低。
截至2020年底,中国各个城市地铁线路总里程已经达5 180.6 km[1],但地铁线路规划建设不可避免地会下穿城市建筑群,从而对地上建筑产生影响。国内学者针对地铁施工对周边房屋的影响做了大量研究:钱春宇等[2]研究地铁盾构施工和运营振动对城墙和钟楼的影响;崇金玲[3]研究地铁运营产生的振动对古建筑结构性能的影响。在现代建筑方面,宋波等[4]监测地铁通过时建筑物的振动加速度,研究地铁运行对邻近砖混结构建筑物的影响;于凯文等[5]系统研究地铁运营对沿线不同基础型式建筑物的振动影响规律。
国内外对建筑结构安全分析的研究大多集中在计算机模拟和无损探测方面:Guo等[6]通过建立力学仿真模型研究客运滑道的安全性;Bernardi等[7]提出基于CFD技术模拟和热力有限元模型的结构安全评估方法;Isaac等[8]通过对比标准区间分析和参数化区间分析发现,标准区间分析方法在某些情况下会得出具有误导性的结论;Daou等[9]通过数字模拟建模验证码头结构的安全性。无损探测在结构安全评价方面得到一定应用:Stefan等[10]利用超声波探测和概率分析对大桥结构安全性进行评估;常银生等[11]以南京地铁3号线为例,提出利用房屋结构信息和抵抗不均匀沉降能力等情况初步判断房屋的安全性能;张飞[12]以厦门1号线为背景提出对地铁沿线老旧房屋进行安全现状评价的具体方法;蒋智勇等[13]提出在地铁施工前对老旧房屋安全性能鉴定和测试的方法。近年来,利用计算学习进行房屋性能评估的方法逐渐盛行:Zhang等[14]提出用于震后结构安全性评估的机器学习框架;Lee等[15]利用深度神经网络(DNN)实现对老旧房屋采暖能耗的预测,均取得较好的效果。
鉴于此,本文基于房屋基本数据(建筑年份、结构类型、基础类型、地理位置等),利用4种不同机器学习算法分别对某市地铁沿线老旧房屋的安全状况进行预测,采用不同指标比较不同分类器的性能,验证利用机器学习预测房屋安全性的可行性。
1 数据收集
1.1 预警指标
本文实验选取某市地铁1号线与2号线沿线老旧房屋作为预测对象,每栋房屋属性见表1,共收集11个指标。
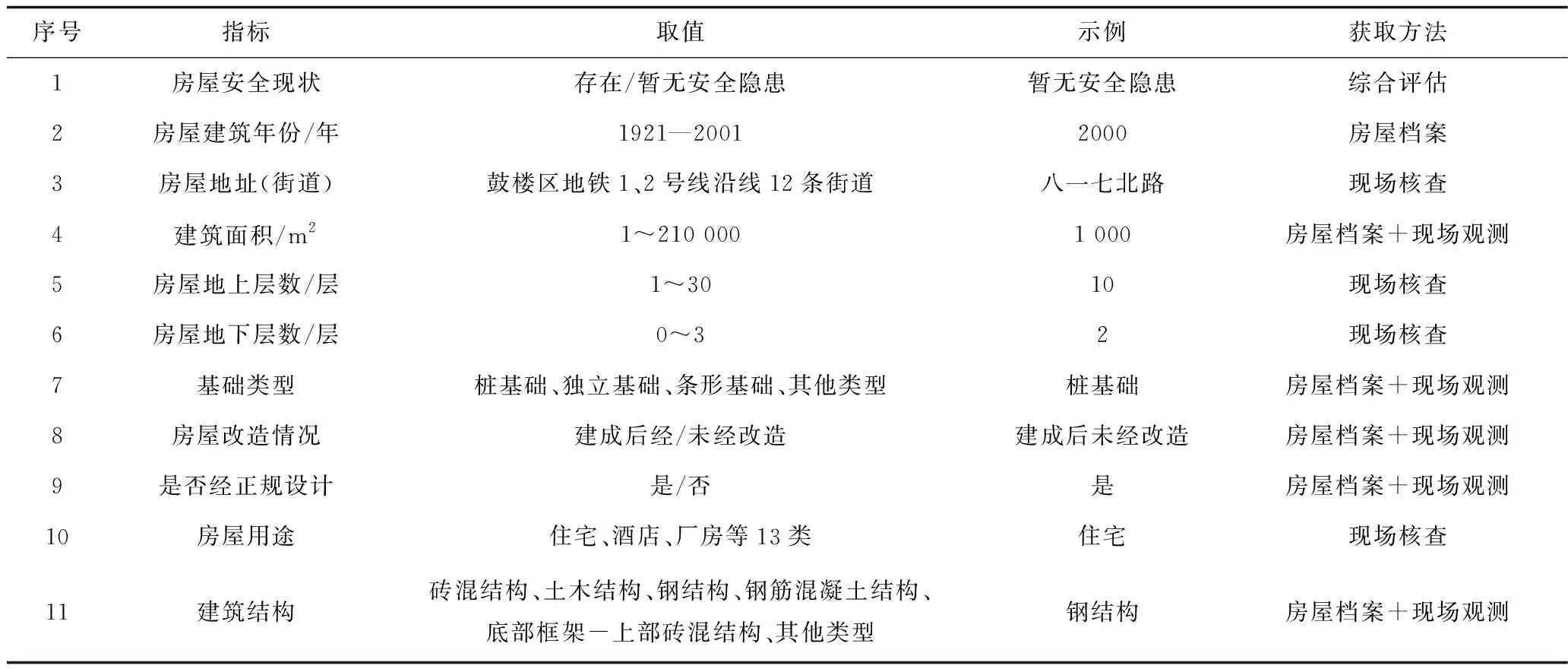
表1 实验数据属性Table 1 Introduction to experimental data attributes
房屋安全现状分为存在安全隐患和暂无安全隐患2级,由技术人员现场从房屋基础、外观、结构等方面进行辨识,具体分级标准见表2。

表2 房屋安全现状分级标准Table 2 Classification standard of building safety status
1.2 数据采集
研究区域卫星图像如图1所示。该区域地铁线路穿过市中心,沿线街道存在大量老旧房屋,各类用途房屋占比情况见表3。
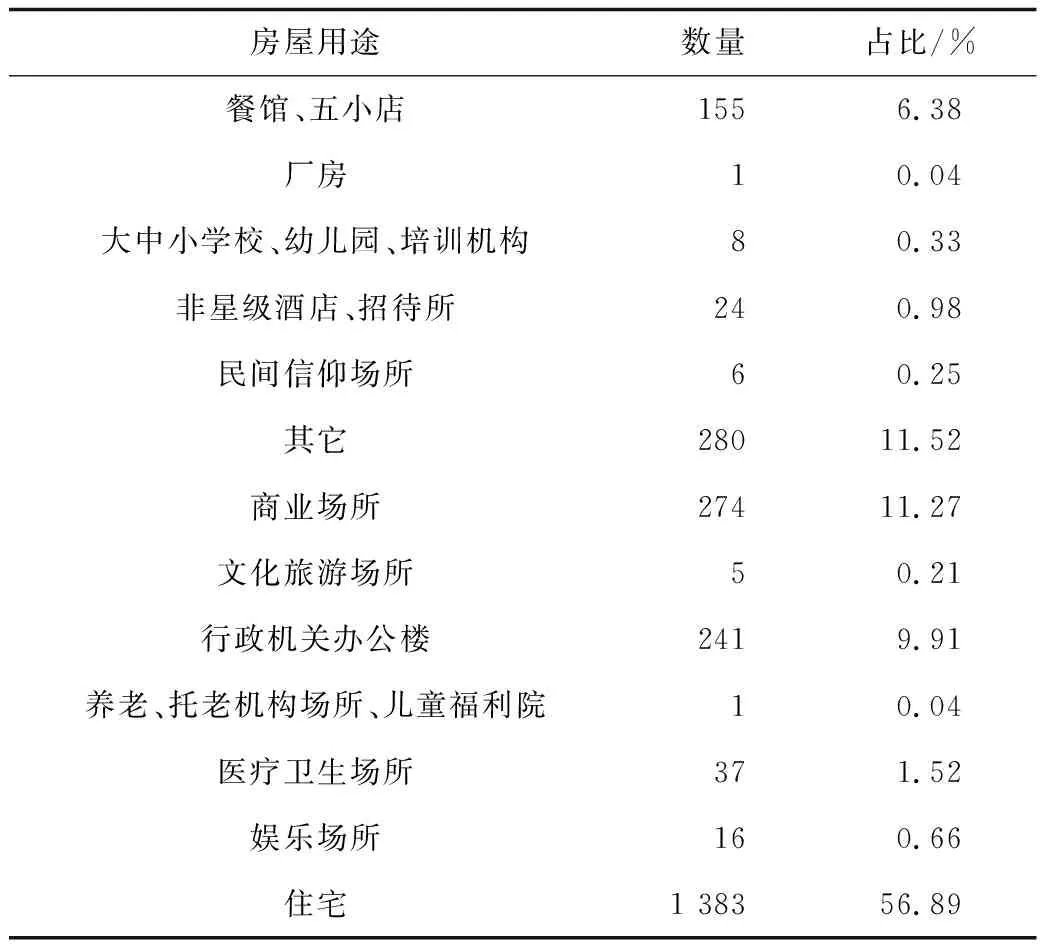
表3 房屋用途统计表Table 3 Statistical table of building usages
房屋数据各指标相关性热力图如图2所示。由图2可知,与房屋安全性(安全现状)相关性最高的指标为房屋改造情况,相关系数绝对值达0.7;其次为房屋结构类型、基础类型和设计情况,相关系数绝对值均大于0.1。
1.3 数据整理
1)缺失值和离群值。收集到的数据数量充足且完整性较高,含有缺失值和异常值的样本量很少,因此本文通过人工筛选的方式对这部分样本进行剔除。
2)变量处理。对年份、建筑面积、地上及地下楼层数等连续型变量进行标准化处理,采用Standard Scaler[16]对训练集和测试集进行标准化。对于离散型变量,本文采用独热编码(One-Hot Encoding)[17]的方式进行处理。
2 数据采样
本文实验共收集房龄大于20 a的老旧房屋数据2 431条,其中暂无安全隐患数据与存在安全隐患数据的比例为2 407∶24,“暂无安全隐患”数据量远大于“存在安全隐患”数据量,属极端不平衡数据。
在数据层面,样本不均衡性解决办法主要包括过采样和欠采样(下采样)2种,欠采样方法在样本正负例比例过大时失去作用,目前对这种数据集效果较好的处理方法为数据过采样技术(SMOTE)[18-19],在诸如医疗等非均衡样本机器学习领域得到广泛应用[20-21],并取得很好的效果。
研究数据属极端不平衡数据,若采用欠采样,则易造成数据浪费,故本文采用过采样思路中的SMOTE模型进行研究。SMOTE通过插值法生成新样本,使得输入数据集达到平衡。过采样前后训练集中正负类样本数量统计见表4。
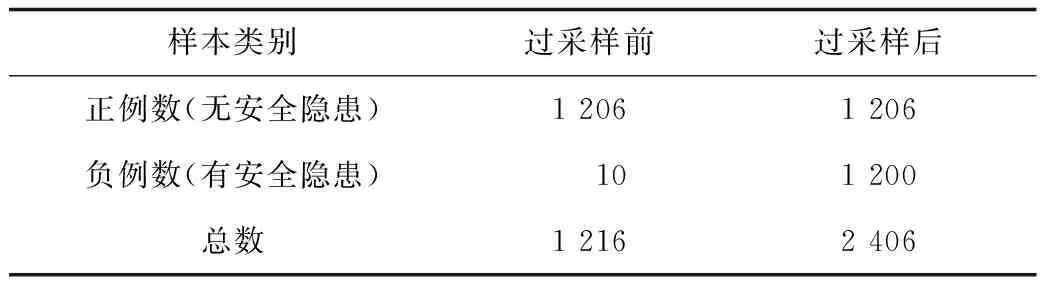
表4 过采样前后训练集正负样本数量统计Table 4 Statistics on positive and negative samples numbers of training set before and after oversampling
3 分析模型
3.1 模型参数
本文所有程序均基于Python3.7环境,各分类器主要参数如下,未标明参数均采用默认值。
1)KNN,Bayes 2个分类器的参数均采用默认值。
2)Logistic:max_iter=2 000。
3)SVM:惩罚系数C:2;内核类型kernel:‘linear’;分类策略decision_function_shape:‘ovo’。
3.2 模型构建
实验数据离散变量多且存在大量相似数据,本文采用One-Hot Encode+KFOLD+SMOTE的方式对数据进行加工,算法流程如图3所示。
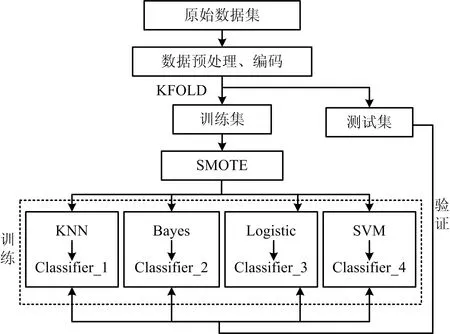
图3 算法流程示意Fig.3 Schematic diagram of algorithm flow chart
4 实验结果分析
实验数据集共2 431条数据,训练集与测试集划分比例为1∶1。为避免随机性,实验2次训练所用数据不存在交叉,即将第1次实验的测试集作为第2次训练的训练集,2次实验结果的混淆矩阵如图4所示。
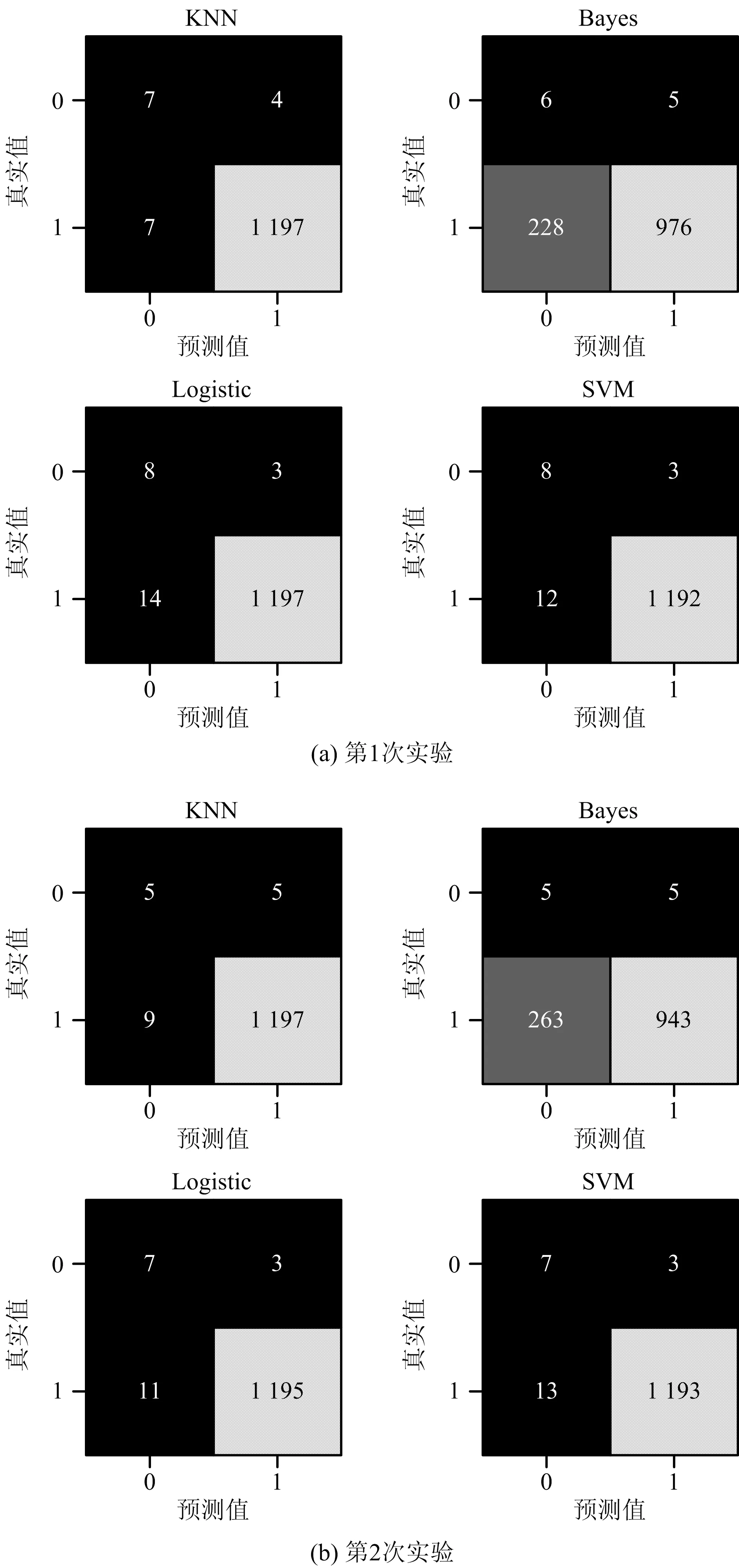
图4 实验结果混淆矩阵Fig.4 Confusion matrix of experimental results
从2次实验的混淆矩阵可知,综合负例检出率和正例误判率,Bayes模型在4个模型中表现最差;逻辑回归模型和SVM模型的表现比较出色,负例检出率均大于70%,正例误判率较低,但无法进一步做出比较。
根据2次实验结果生成的PR曲线,整条曲线反应在不同判别阈值情况下模型的预测能力(用AP值量化)如图5所示。由图5可知,KNN和Bayes模型2次实验的PR曲线非常接近,但效果均不佳;从AP值来看,逻辑回归和SVM的差距并不明显,但逻辑回归有部分阈值的Precision值和Recall值大于其他3个模型,即通过优化判定阈值,逻辑回归效果较好。
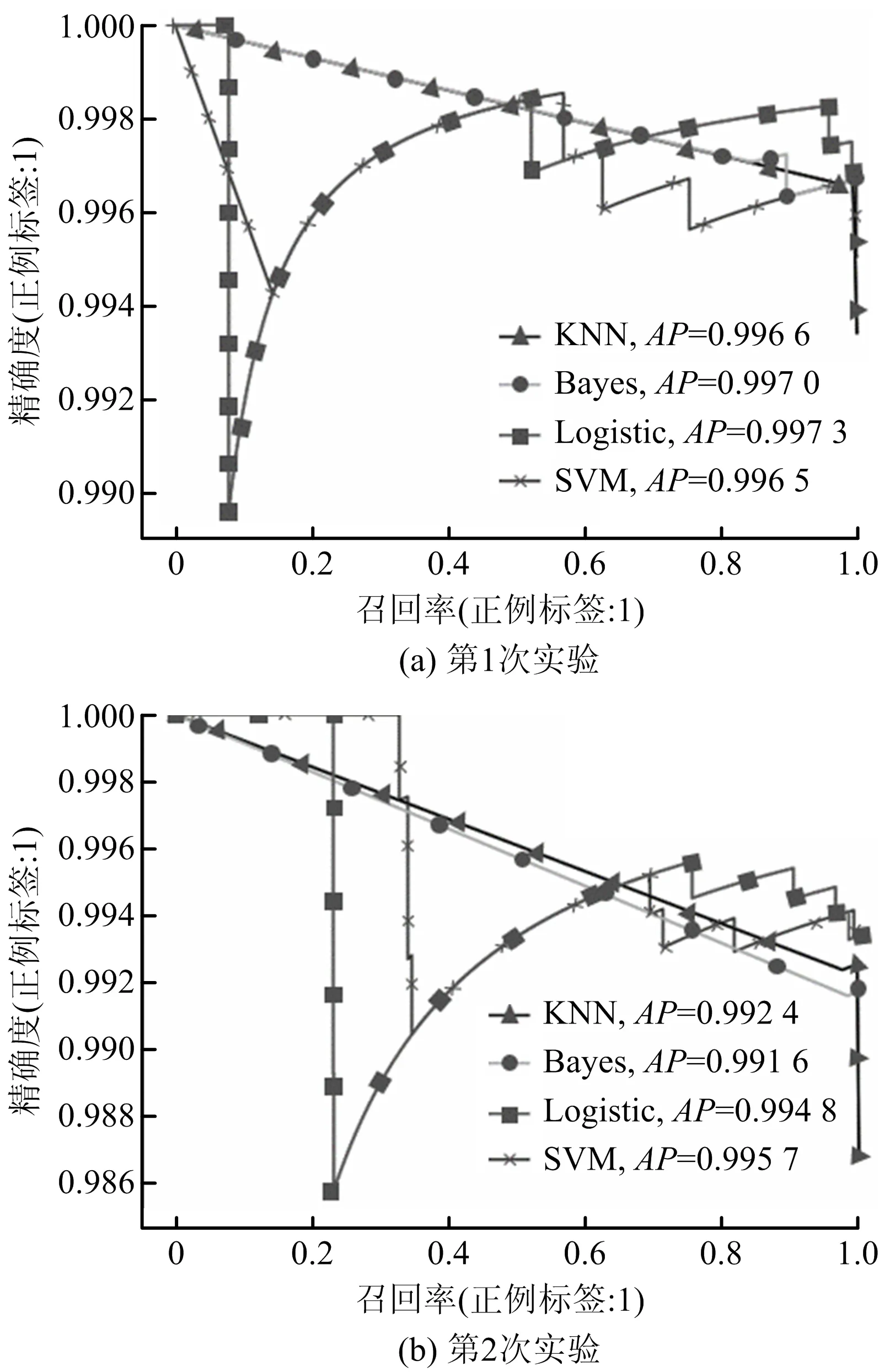
图5 PR曲线Fig.5 Precision-Recall (PR) curves
根据2次实验结果生成的ROC曲线如图6所示。ROC曲线表示选取不同判定阈值时,真正率(TPR=TP/(TP+FN))随假正率(FPR=FP/(FP+TN))的变化情况。ROC曲线越向上远离Chance线,分类器性能越好。由图6可知,KNN分类器在不同测试集上的波动性较大,性能不够稳定,Bayes分类器2次实验结果均不理想,逻辑回归和SVM分类器在2次实验中ROC曲线均十分稳定,且逻辑回归分类器的表现要略优于SVM分类器。
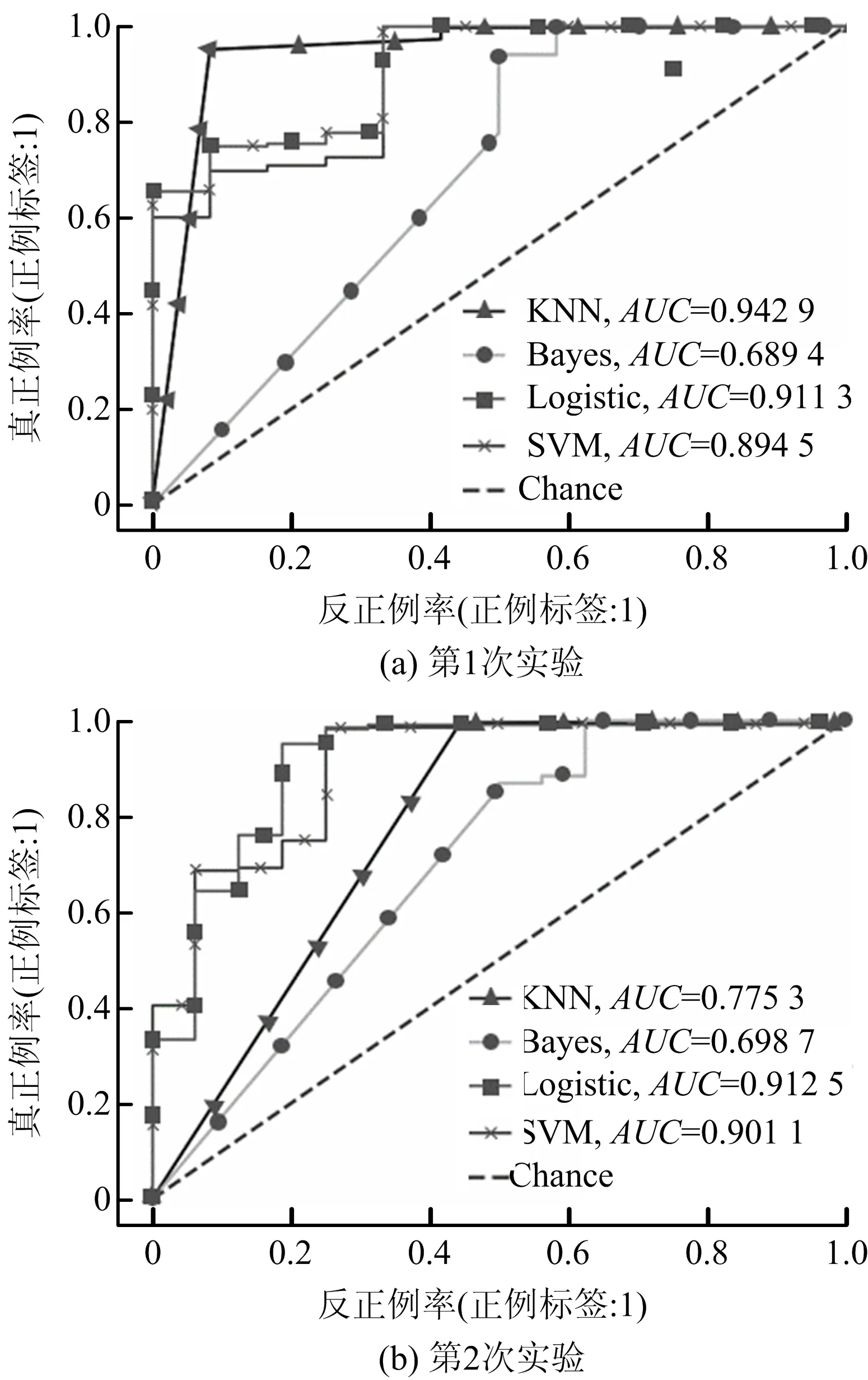
图6 ROC曲线Fig.6 Receiver Operating Characteristic (ROC) curves
各分类器2次实验表现的定量评价指标汇总见表5。由表5可知,无论是从准确率、精确率、召回率这类2级指标,还是F1_score3级指标来看,逻辑回归模型比其他3种分类器表现更为突出,其准确率(Accuracy)高达99.02%,查准率(Precision)达到75.63%,验证逻辑回归模型分类器的有效性。
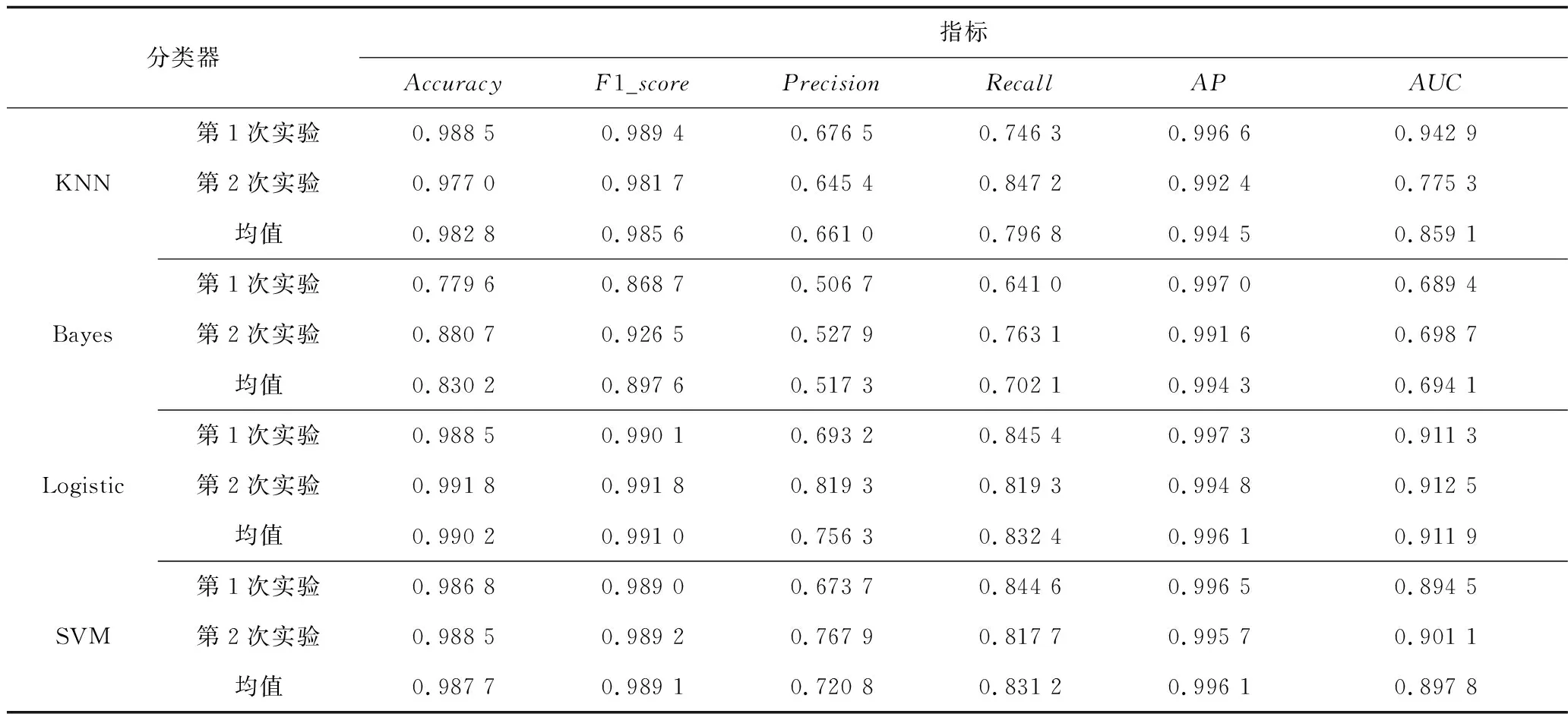
表5 评价指标汇总Table 5 Summary of evaluation indexes
5 结论
1)通过对11个房屋指标进行统计分析发现,城市中存在很多经不合理设计、结构老化、违规改造的老旧房屋,其中违规建造导致的上下楼体结构不一致、地基滑移,违规改造造成的楼体结构损坏更易影响楼体的结构安全。
2)通过模型拟合结果可知,在使用的10个指标中,房屋是否经过改造和是否经过正规设计、基础、结构指标与房屋是否有安全隐患有较强的相关性,因此在城市房屋安全隐患整治过程中,应尤其注重对于违规建造和改造的房屋的排查。
3)KNN、Bayes、Logistic、SVM 4个分类器对于正例样本均能达到较好的分类性能,但Bayes分类器的错误分类最多,表现最差。在房屋安全性负例样本预测中,KNN和Bayes分类器效果相近,检出率约为50%,基于逻辑回归和SVM的分类器表现较好,达70%左右的检出率。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
中学生数理化·高一版(2021年2期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
现代装饰(2020年12期)2021-01-18
文苑(2020年10期)2020-11-22
电子技术与软件工程(2019年18期)2019-11-18
金桥(2018年2期)2018-12-06
领导决策信息(2018年16期)2018-09-27
电子技术与软件工程(2017年14期)2017-09-08
数学学习与研究(2017年3期)2017-03-09
