
结合多尺度与可变形卷积的自监督图像特征点提取网络
2022-04-25 11:49:46张少鹏周大可
计算机测量与控制 2022年4期
张少鹏,周大可,2,杨 欣,2
(1.南京航空航天大学 自动化学院,南京 210000; 2.江苏省物联网与控制技术重点实验室,南京 210000)
0 引言
图像特征点检测任务是计算机视觉领域的底层任务,对许多更高层的任务,比如车辆检测[1]、视觉SLAM[2]起到至关重要的支撑作用,更高的特征点检测精度能显著提升这些高层任务的性能。在早期研究中,特征检测任务主要通过手工设计特征提取策略和特征点描述策略来寻找特征点,比如SIFT[3]、SURF[4]、AKAZE[5]、ORB[6]等。随着深度学习的兴起,卷积神经网络在计算机视觉领域开始广泛应用,如何利用深度学习进行特征点检测、描述和匹配也成为了研究的热点。根据深度学习在这些研究中起到的作用,可以将其分为三类:使用传统算法检测的特征点作为监督信息进行训练的方法,采用自监督特征描述网络+手工筛选特征点的方法,和采用自监督方式同时训练特征点检测和描述网络的方法。
受采用人工提取策略的特征检测器启发,Verdie等[7]将特征点检测问题视为回归问题,利用SIFT特征点来监督网络训练;Yi等人[8]把特征点检测视为分类问题,预测每个像素点是特征点的概率,同样利用SIFT特征点监督训练,取得了不错的效果。但这类方法采用SIFT等传统策略提取的特征进行监督,导致特征点检测网络的上限被选用作为监督的人工设计检测器所限制,无法取得更优的效果。
卷积神经网络具有优异的图像特征提取能力,因此,一些研究者提出不训练特征检测网络,采用自监督的方式直接训练卷积神经网络提取输入图像每个像素局部区域的描述向量,然后人工设计筛选策略,选出潜在特征点[9-12]。Dusmanu等人[13]等首先提出了这种方法,通过比较像素点和周围特征向量在通道域和空间域的差异来筛选特征。Tian等人[14]等改进了筛选策略,以特征向量的方差大小和特征向量与周围像素的差异来挑选特征点。然而,这种方法在选取策略上还存在一定缺陷,虽然在光照变化下表现出了良好的性能,但在视角变化大时性能下降明显。
由于手工设计策略筛选特征点的方式仍存在对视角变化较敏感、难以达到全局最优等问题,许多研究选择训练卷积神经网络同时完成特征点的检测和描述。DeTone等人[15]先训练网络提取三角形、四边形等简单图形中的角点,训练完成后再在真实图像上进行训练,使用输入图像多次进行单应矩阵扰动后提取的特征点作为伪真值标签。Ono等人[16]将输入图像施加单应变换,以两张图像提取的特征点差异作为监督,同时加入空间变换网络,让网络提取的描述子具备空间不变性。Christina等人[17]巧妙地将图像降采样与预测特征点位置相结合,同时输出特征点位置和描述向量。Barroso-Laguna等人[18]采用人工设计的滤波器组预处理图像,再输入网络进行预测。Shen等人[19]改进了LF-Net的网络结构以融合多尺度特征。在特征检测的过程中,重复纹理处提取的特征点常常会导致误匹配,所以需要针对性的处理重复纹理处提取的特征点。Revaud等人[20]在网络中额外添加了评估描述子可信度的输出层,该层会在纹理重复度高的像素点位置输出一个较低的可信度,从而避免提取到这些特征点。然而,在特征点的提取过程中,卷积神经网络每一层的尺度变化较大,且只能以固定尺寸的卷积核对输入的特征图进行卷积,缺乏多尺度信息的融合;同时,图像局部的纹理形状并不规则,导致卷积层提取时可能引入无关信息、破坏局部纹理的完整性。所以如何融合多尺度的图像特征信息、更好地描述图像局部特征成为提高特征点提取网络性能的关键。
综上所述,本文针对以上问题,采用自监督的方式训练卷积神经网络,引入多尺度卷积,在同一个卷积层内融合多个不同感受野的卷积核,从而获得有丰富信息的多尺度特征,引入卷积注意力机制和坐标注意力机制与多尺度卷积核结合,使网络能够重点关注某一尺度特征图;引入可变形卷积,使网络输出的描述子可以灵活描述像素点周围的区域,最终获得了效果更佳的特征点检测网络。
1 方法
本文网络采取L2-Net[21]作为基础网络,不同于L2-Net的输入为32*32的图像块,本文输入为整张图像,输出每个像素的描述向量、该像素是特征点的概率、该像素描述向量的可信度。在基础网络中加入多尺度卷积和卷积注意力模块,在网络最后额外增加两层单应约束的可变形卷积层和坐标注意力模块,网络整体结构如图1所示,输入图像经过共享特征融合模块后,从左到右依次输出特征点置信度响应图、特征点描述子、特征点局部区域重复度响应图。在训练时,本文预测两幅图像的特征点,并用光流预测的方法得到对应的特征匹配,并以此进行自监督训练。

图1 整体网络框架示意图
1.1 共享特征融合模块
本文首先通过一个共享的特征提取模块来提取后续三个输出模块需要的深度特征。为了获取足够丰富的特征信息,本文采用了多尺度卷积模块,该模块的输出通道与输入通道之间的关系如图2所示,不同颜色的方块代表不同空洞率的卷积,这部分输出特征通道由输入特征通道与该空洞率的卷积核卷积得到。首先通过四层3*3卷积层对图像进行预处理,再通过多尺度卷积层进行卷积,获得多尺度融合特征。但是,在网络中进行降采样会丢失信息,造成精度下降,因此,本文使用增加卷积空洞率的方式来代替降采样。
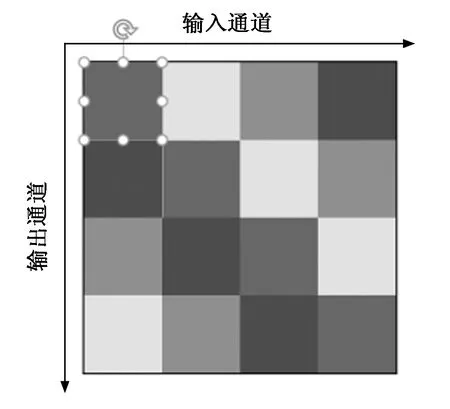
图2 多尺度卷积层
PSConv[22]是Li,Yao等人提出的一种在同一层内提取多尺度特征的卷积层,其对输入的特征图采用不同空洞率的空洞卷积进行特征提取,空洞率沿着输入和输出通道的轴周期性地变化。卷积核的空洞率和卷积的感受野大小息息相关,空洞率越大,感受野越大。对于一个空洞率为d,卷积核尺寸为K的空洞卷积层,它的单层等效感受野R的大小为:
R=(d-1)×(K-1)+K
(1)
低空洞率的卷积更关注图像局部的信息,高空洞率的卷积能关注到更全局的图像信息。这种多尺度卷积设计使得网络能够在更细粒度范围内聚合不同尺度的特征图,有助于提取对尺度变化更鲁棒的特征点。
为提取到尺度不变的特征点,本文在多尺度卷积的基础上加入了卷积注意力机制(CBAM, convolutional block attention module)。CBAM模块的结构如图3所示,通过依次应用通道和空间注意力来识别重要的特征区域。通过在多尺度卷积层后加入CBAM模块,网络能够在输入图像的场景尺度发生变化时提取到尺度相近的特征,有利于最后提取到尺度相对鲁棒的特征点。
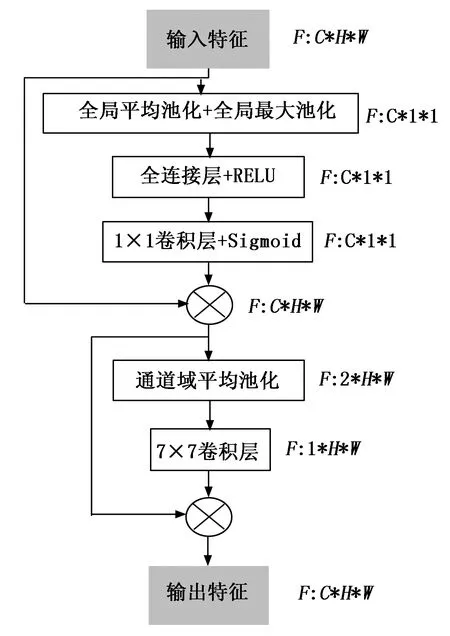
图3 卷积注意力模块
1.2 归一化变换点对的单应约束可变形卷积层
可变形卷积是由Zhu等人[23]提出的一种卷积操作,设卷积核大小为3,空洞率为1的传统卷积采样点为:
R={(-1,-1) (-1,1) … (1,-1) (1,1)}
(2)
R是以(0,0)为中心的周围9个点,则在每个卷积中心点p0输出的特征图y(p0)与输入特征图x(p0)的关系为:
(3)
其中:w(p)代表卷积核在点p处的权重,x(p)代表输入特征图在点p处的像素值。
而可变形卷积额外添加了两个卷积层用来预测采样点的偏移量Δpn和采样点的重要程度Δmn,其卷积公式为:
(4)
通过预测偏移量,可变形卷积层可以采样到不规则的感兴趣区域轮廓,不必受限于规整的采样区域,能够增强网络输出的描述子的描述能力。
经典的可变形卷积核每个采样点都能在x,y两个方向自由偏移,因此每个采样点的自由度为2,一个卷积核的偏移量的自由度是2·k2,k为卷积核大小。假设k=3,则卷积核有9个采样点,输入图像大小为B×C×H×W,输出的预测偏移量大小应为B×18×H×W。然而,在特征点检测任务中,完整的2·k2自由度并不是必要的。在早期研究中,为了给网络提供空间不变性,研究者给网络添加了某些几何约束。Jaderberg等人[24]通过空间变换网络(STN)预测一个二维仿射变换参数用于对齐输入图像,在LF-Net[16]中,作者利用STN结构来变换输入图像,然后提取图像的描述子。这些研究直接估计输入图像的二维仿射变换,这种预测方法无法自适应调整局部的变换参数,同时仿射变换也无法完全描述二维射影图像间的几何关系。Luo[25]等人提出利用二维单应矩阵来约束可变形卷积的变化范围。定义一张图像上像素点的齐次坐标为(x,y,w)T,它属于射影空间IP2,射影映射是一种满足下列条件的可逆映射h:x1,x2,x3共线当且仅当h(x1),h(x2),h(x3)也共线[26]。射影映射组成的群称为射影变换群或单应变换群,存在一个非奇异矩阵H∈R3×3满足:h(x)=Hx。


(5)
1.3 坐标注意力机制
通过观察特征点的分布,我们认为检测特征点不仅需要图像的局部信息,还需要网络能聚合更大范围内的图像空间信息。CBAM注意力模块通过全局池化来引入位置信息,但这种方式只考虑了局部范围的信息。因此,本文采用坐标注意力机制[28]来捕获更大范围内的特征依赖关系。
如图4所示,从上层网络得到特征F∈RC×H×W,C,H,W分别是输入特征图的通道数、高和宽。对输入特征分别进行X和Y方向的一维全局平均池化操作得到,然后将其拼接在一起并依次通过一个1×1卷积核映射、一个RELU非线性激活层,再将两个方向的特征分离并分别通过一个1×1卷积核映射再与原输入特征做哈达玛积,这样每个注意力图都具备了沿着不同方向捕获输入特征图远距离依赖关系的能力。通过在编码器中加入坐标注意力机制可以获得可训练的空间权重,指导网络不局限于特征图的局部特征,提取到更丰富的特征,同时也能够加速训练收敛。
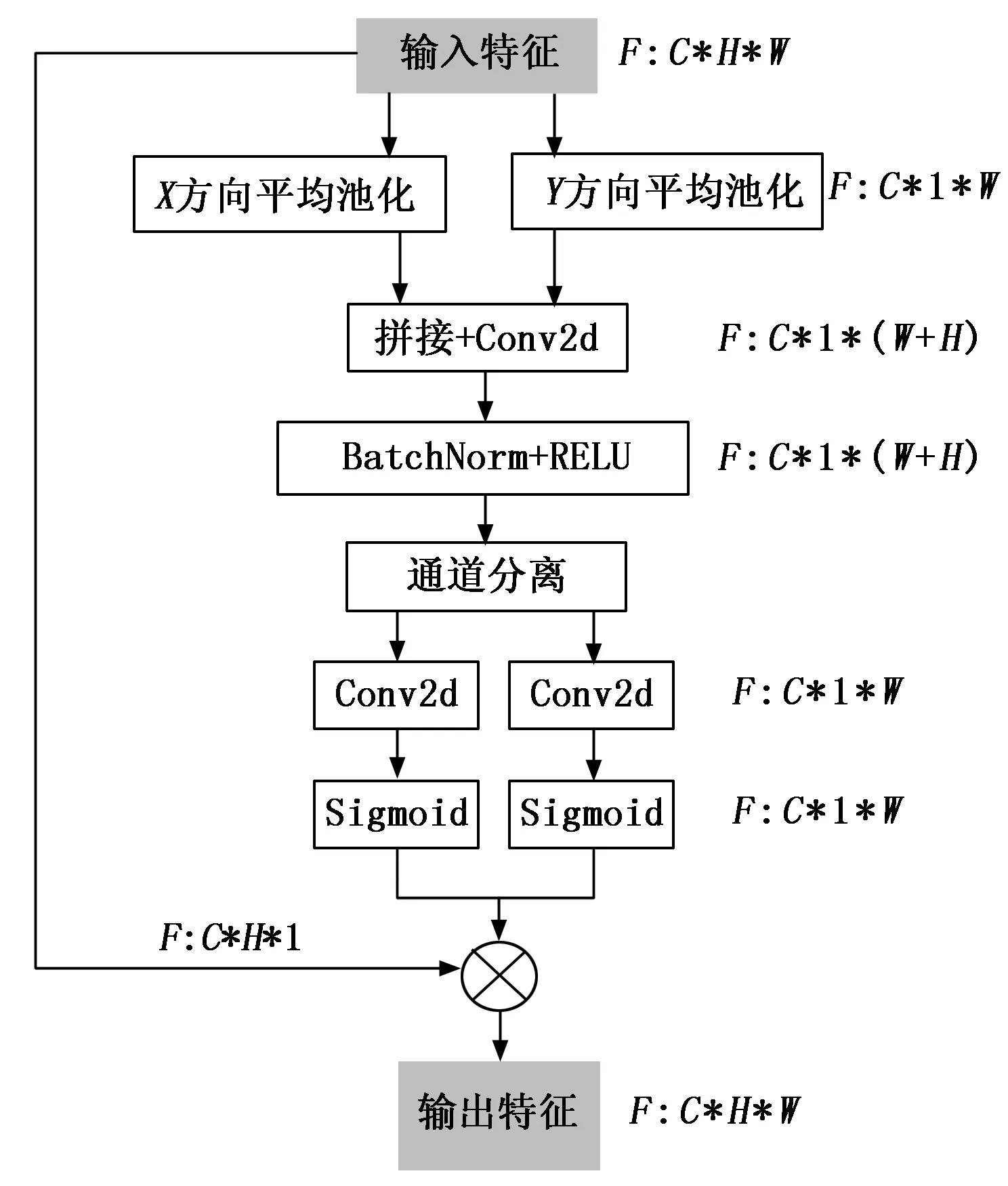
图4 坐标注意力模块
1.4 损失函数
通过自监督方式训练特征点检测网络实质上是通过合成新视图的方式获取真值。与Revaud等[20]提出的方法类似,本文的损失函数设置为:
Ltotal=λdetLdet+λdescLdesc
(6)
其中:Ldet用于训练特征点检测网络,Ldesc用于训练描述子生成网络。Ldet由余弦相似度损失Lcosim和差异度损失Lpeaky构成。令S[p]为网络预测的输入图像上点p是特征点的可能性,I,I′分别是输入图像和合成的新视图,P是每个像素点周围区域,则余弦相似度损失为:
(7)
为保证选出的特征点在S上的局部区域内有显著的大小差异,本文采用差异度损失:
(8)
综上,检测子损失为:
Ldet=Lcosim(I,I′)+0.5(Lpeaky(I)+Lpeaky(I′))
(9)
描述子损失Ldesc用于衡量两幅图像中同一个特征点生成的描述子是否相似,使用可微分的平均精度损失(AP)[29]:
LAP(q)=1-AP(q)
(10)
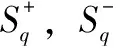
与网络预测的描述子可信度结合,最终的描述子损失函数为:
LAPκ(i,j)=1-[AP(i,j)Rij+κ(1-Rij)]
(11)
其中:R是网络输出的各像素点描述子可信度,κ是超参数。
2 实验结果与分析
2.1 实验设置
2.1.1 数据集
使用图像检索数据集Achen[30]和Random Web Image数据集作为训练数据,Hpatches[31]数据集作为测试数据集,以便与现有工作进行比较。Aachen数据集包含6 697张参考图像,1 015张明暗不同的查询图像以及对应的位置信息。原始图像大小为1 600×1 063像素,为降低网络计算量,将输入图像的大小设置为640×480像素。在选定图像对后,通过SFM和稠密光流预测,可以获得对应的位姿变换和两张图像上逐像素对应坐标,在训练中,网络预测获得图像对的特征点后,通过光流可以获得特征点在另一张图像上的位置,可以据此进行自监督训练。
2.1.2 训练细节
使用的训练平台为英伟达RTX 2080,整体算法采用pytorch框架实现。输入图像大小为640×480像素,采用随机水平翻转、亮度调整、对比度调整、小幅度射影变换扰动来实现数据增强,采用Adam作为优化算法,学习率设置为0.001,batch大小为4,共训练20个epoch,权值衰减为0.000 5。
2.1.3 评估指标
本文使用评估特征点检测精度最常用的几个指标,包括匹配分数(MS,matching score),即正确匹配在两图像共视特征点中的占比,它能反映提取的特征点质量;
(12)
其中:N是测试集样本数量,Minlier,Numco分别是正确匹配数量和图像中共视特征点数量。
平均匹配精度(MMA,mean matching accuracy),即正确匹配特征点与所有可能匹配之比,MMA越高,说明特征点的匹配正确率越高,反映了特征点描述子的区分能力。
(13)
其中:Mtotal是两幅图像的特征点采用暴力匹配得到的所有可能匹配数量。
特征点重复度(Rep,keypoint repeatability),即所有可能匹配与两图共视特征点数量之比,它能反映网络对某个纹理区域的特征提取能力。
(14)
单应矩阵估计精度(HA,homography accuracy):使用检测特征点估计的单应矩阵与两图单应矩阵真值之间的差距,由于特征点匹配常用于三维重建、导航等需要求解变换矩阵的场景,因此该指标也很重要。
(15)
2.2 实验结果
2.2.1 对比实验
我们在HPatches数据集上比较了本文方法和7种主要方法,如R2D2[20]、D2Net[13],SIFT[3]等,各对比方法的结果数据来自原论文。表1给出了在3像素误差阈值下8种方法的实验结果,其中,各对比方法的结果数据来自原论文。由于部分用于对比的方法在论文中缺乏相关指标的实验结果数据,且代码未开源,因此,表1中有部分数据缺失。结果表明,本文方法在大部分指标上的评估结果优于其他7种方法。相较于其他方法,本文采用的方法在重复度指标上较次优方法提升了约1%,对于同一个纹理区域,本文方法能提取出的有效特征点更多,特征提取能力更佳;匹配分数上较次优方法提升了约1.3%,说明采用本文方法提取的特征点提取质量更好;平均匹配精度提高了约0.4%,说明采用本文方法提取的特征点在匹配时误匹配更少,网络提取的描述子能更好地区分不同特征点。虽然单应矩阵估计精度未取得最优效果,但仍能达到较优秀的精度。

表1 在HPatches数据集上结果比较
为了更好地展示本文方法在不同情况下的性能,图5展示了不同方法在光照、视角变化情况下MMA指标随像素误差阈值变化的图像,最左侧图像为两种变化下MMA指标的平均值。由于图5中部分方法仅有HPatches数据集下MMA这一指标的实验数据,因此这部分方法未在表1中列出。如图5所示,当像素误差阈值上升到2px时,本文方法的MMA指标综合上看已取得了最优效果,随着阈值限制的放宽,在不同特定条件下的效果也取得了最优效果。综合不同曲线,本文方法在大多数情况下取得了最优的匹配精度。

图5 HPatches数据集下部分方法平均匹配精度(MMA)随像素误差阈值变化曲线
图6是在HPatches数据集中分别选取光照、视角变化较大的两个场景进行特征点匹配测试,上行为光照变化,下行为视角变化,像素误差阈值为3px,每张图像提取4 000个特征点,提取图像对的特征点后,通过数据集提供的图像对之间的变换矩阵将一幅图像中的特征点投影到另一幅图像中,并取投影位置周围3个像素范围内的特征点进行特征匹配,最后输出匹配结果。从图6可以看出,在光照条件变化大的情况下,本文方法提取的特征比传统的SIFT、ORB等特征有更多的正确匹配特征点对,说明匹配效果更好,相比D2-Net、R2D2等采用深度学习的方法,本文的方法更少在图像的低信息区域提取特征;在视角变化时,相较于其他方法,本文方法提取的特征分布更加均匀,定位也更精确。在曲线的前半段可以看出,仅需稍微放宽像素误差阈值的限制,本文方法获得的精度提升最大,更容易达到最优效果。

图6 不同方法在光照条件、视角变化下进行特征点提取、匹配的结果
2.2.2 消融试验
本文采用L2-Net作为基准网络,在此基础上加入了多尺度卷积层、可变形卷积层和卷积注意力、坐标注意力模块,为进一步探究各模块对实验结果的影响,分别去除注意力机制、CBAM+多尺度卷积模块、CA+可变形卷积模块,将得到的评估指标进行比较,结果如表2所示。实验结果表明,增加注意力机制和不同的卷积模块均会带来一定的精度提升,可变形卷积模块能有效提升。
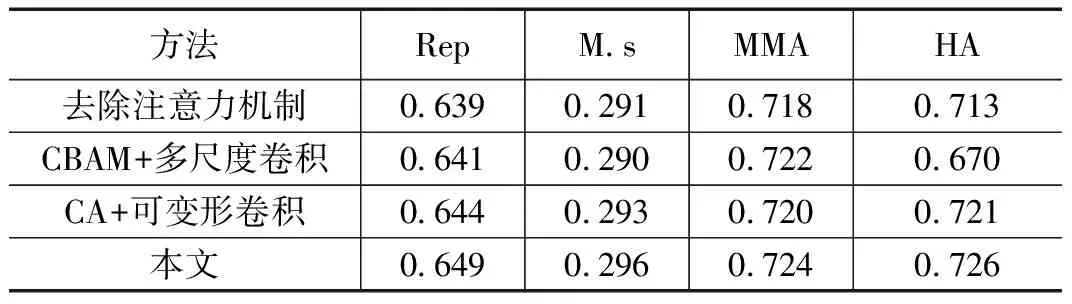
表2 HPatches数据集上消融实验结果比较
3 结束语
为改进特征点检测及描述算法的性能,本文提出了一种端到端的自监督特征点提取网络。在L2-NET网络基础上,通过加入多尺度卷积和可变形卷积,优化可变形卷积的单应约束求解步骤,并引入卷积模块注意力和坐标注意力机制,提升网络对特征点的检测能力。实验结果表明,本文方法实现了更高的特征点检测精度,同时对光照、视角变化有更强的鲁棒性,在各类场景中均有较高的应用价值。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
太空探索(2016年5期)2016-07-12 15:17:55
CHIP新电脑(2016年3期)2016-03-10 14:22:03
时代英语·高三(2014年5期)2014-08-26 17:01:17
