
图像均衡化与FaceNet算法相结合的方法研究
2022-04-24 09:58:50王欣汪宁于晓昀公安部第一研究所
警察技术 2022年2期
王欣 汪宁 于晓昀 公安部第一研究所
引言
迄今为止,计算机人脸识别的准确性依然受到光照条件等因素的影响,特别在公安实战环境下,由于受到光照以及摄像头角度等因素影响,获取的线索照片一般比较模糊,质量不高,降低了识别率,影响了实战应用效果[1]。因此,本文提出了图像均衡化与FaceNet算法相结合的方法,用于提升光线不足、过曝等图像的识别准确率。
一、研究现状
人脸识别的研究始于20世纪60年代,人脸识别因其便捷、高效、易普及的优点成为最受关注的研究问题之一[2]。
人脸识别的方法主要分为四类,分别是神经网络方法、稀疏表示方法、子空间方法、基于三维形变模型的方法[3]。
稀疏矩阵标识方法,其中稀疏标识在一个含有大量训练样本的空间,样本可以由空间的同类样本线性表示,并可通过将噪声考虑在内,增加算法的鲁棒性。
子空间方法是通过寻找映射矩阵,将原始高维样本映射至低维空间,同时样本结构保持不变。但子空间算法常常会发生“小样本问题”。
因为人脸是三维结构,所以采用三维形变模型可以更好的表示人脸,但三维形变模型理论不是很完善,还有很多问题需要研究。
近年来,基于深度学习的人脸识别方法受到了广泛研究。使用深度学习进修人脸识别的早期,研究人员倾向于使用多个深度卷积神经网络提取人脸特征,再进行融合。而基于深度学习的人脸识别方法的趋势是使用单个网络,多网融合特征逐渐被VGGNet、GoogleNet和ResNet这三种深度人脸识别的代表性网络架构所取代。其中,GoogleNet通过增加网络结构的稀疏性来解决网络参数过多的问题,大大减少了计算量。FaceNet使用Inception模块实现了轻量级的深度人脸识别模型,可以在前端设备上实时运行。
通常,图像质量受采集环境、采集设备和采集距离等因素影响,如何提升低质量图像识别精度是一个值得关注的问题。
二、图像均衡化与FaceNet算法相结合的方法研究
(一)FaceNet算法
传统的基于深度卷积神经网络(CNN)的方法,一般利用CNN的Siamese网络来提取人脸特征,然后利用SVM等方法进行分类。
FaceNet则利用DNN直接学习到从原始图片到欧氏距离空间的映射,从而使得在欧式空间里的距离的度量直接关联着相似度,并且引入Triplet损失函数,增强模型学习能力。
FaceNet算法的本质是通过CNN学习图像到128维欧几里得空间的映射,该映射将图像映射为128维的特征向量,通过使用特征向量之间距离的倒数来表征图像之间的相似度,对于相同个体的不同图片,其特征向量之间的距离较小,对于不同个体的图像,其特征向量之间的距离较大。最后基于特征向量之间的相似度来解决图像的识别、验证和聚类等问题。
(二)图像均衡化
图像均衡化技术可以在图像增强、光照补偿等多个领域取得很好的效果[3]。该项技术能够将一个灰度级别分布不均匀的图像,通过变换得到一个均匀分布。
直方图是图像中像素强度分布的图形表达方式,它统计了每一个强度值所具有的像素个数,是一种常用的灰度变换方法,主要用于增强动态范围偏小的图像对比度。
直方图均衡化是一种简单有效的图像增强技术,通过改变图像的直方图来改变图像汇总个像素的灰度,通过拉伸像素强度分布范围来增强图像对比度。
(三)图像均衡化与FaceNet算法相结合
为了提高别准确率,本文把输入的图片先进行图像均衡化处理,提高图像的对比度,然后再进行边缘检测提取,最终通过FaceNet模型进行识别与比对,用于提升识别的准确率。
具体流程如下:
(1)输入图片
(2)图像均衡化处理
本文采用直方图均衡化技术进行图像预处理。
① 映射函数应该是一个累积分布函数(cdf)。对于直方图H(i),它的累积分布H(i)是:
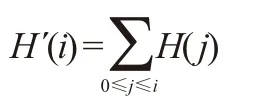
② 要使用其作为映射函数,须对最大值为255(或者用图像的最大强度值)的累积分布H(i)进行归一化。
③ 最后,通过映射过程来获得均衡化后像素的强度值:
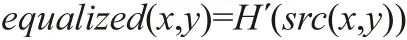
(3)检测对齐
检测对齐采用基于深度学习的MTCNN算法。该算法利用检测任务和分类任务来辅助关键点检测。其总体框架包含三个阶段:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),这三个阶段的输入为不同大小的图片,用于检测不同大小的人脸[4]。
P-Net的输入是一个12×12×3的RGB图像,在训练的时候,该网络要判断该图像中是否存在人脸,并且给出人脸框的回归和关键点定位。
为了去除大量的非人脸框,R-Net输入是P-Net生成的边界框,输出是人脸框的回归和人脸关键点定位。
进一步将R-Net的所得到的区域进行缩放,输入ONet。O-Net输入大小为48×48×3的图像,输出包含P个边界框的坐标信息,score以及关键点位置。
(4)采用FaceNet算法计算
具体流程如下:
① 采用CNN结构提取特征;
② 特征归一化(使其特征的 | |f(x) | |2 = 1 ,所有图像的特征都会被映射到一个超球面上);
③ 再接入一个Embedding层(嵌入函数),嵌入过程可以表达为一个函数,即把图像x通过函数f(x)映射到d维欧式空间;
④ 此外,对嵌入函数f(x)的值,即值阈,做了限制。使得x的映射f(x)在一个超球面上;
⑤ 使用Triplet损失函数(优化函数)进行特征优化。
(5)输出结果
本文采用Inception ResNet v1神经网络结构,基于数据集CASIA-WebFace,进行模型训练。选取了LFW数据集和网络爬取的图片,经过粗略的人工筛选,去除不符合要求的图片,并对所有图片进行了Gamma变换,降低亮度,模拟暗处拍出的图片,组成了一个5000余张的测试集,进行测试。
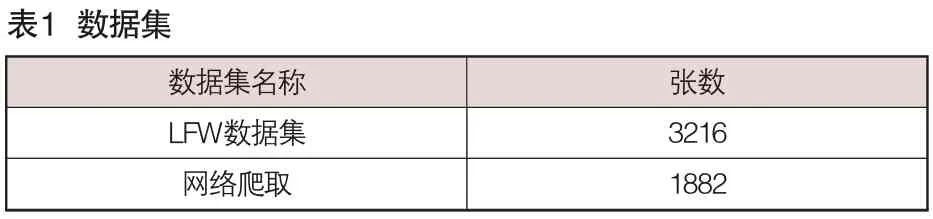
?
测试效果示例如图1所示,其中图片左侧为原图,中间为对原图Gamma处理后的图像,右侧为对中间图像进行直方图均衡化处理后的图片。

结果如图2所示,通过直方图均衡化预处理后,对相对较暗的图片,识别的准确率有了明显的提升。
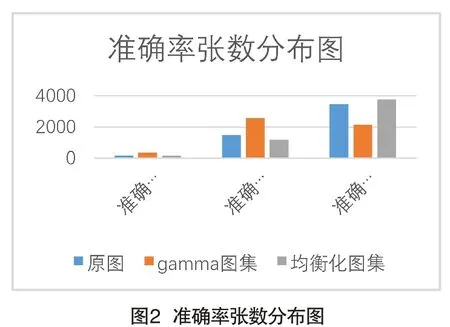


?
三、应用展望
本研究提出的方法可作为人员身份核实的一个步骤应用于分析研判、比对等业务中。如在公安分析研判业务中,利用该算法将图像进行比对,基于比对结果进行分析,如通行分析、聚集分析等,并可进行预警反馈。
四、结语
本文提出了一种基于图像均衡化和FaceNet人脸识别算法相结合的方法,针对于提升光线不足、过曝等图像的人脸识别准确率。通过实验证明本文提出的方法对人脸识别准确率有明显提升。
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
保定学院学报(2022年2期)2022-04-07 02:26:50
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
中国卫生(2015年1期)2015-11-16 01:06:02
计算机工程(2015年8期)2015-07-03 12:20:21
物探化探计算技术(2015年2期)2015-02-28 17:42:49
