
结合门循环单元和生成对抗网络的图像文字去除
2022-04-24 09:53王超群全卫泽侯诗玉张晓鹏严冬明
中国图象图形学报 2022年4期
王超群,全卫泽,侯诗玉,张晓鹏,严冬明*
1.中国科学院大学人工智能技术学院,北京 100049;2.中国科学院自动化研究所模式识别国家重点实验室,北京 100190;3.清华大学水沙科学水利水电工程国家重点实验室,北京 100084
0 引 言
文字信息在日常生活中无处不在,它在传递有价值信息的同时,也会造成私人信息泄漏,例如拍摄照片或收集数据时,不可避免地会在图像中出现一些个人信息(证件号码、电话号码等)(刘静和王化喆,2015),而图像文字去除技术则能通过去除图像中的敏感信息,起到保护隐私的作用。同时,该技术还广泛应用于图像视频编辑(季丽琴和王加俊,2008)和文字翻译等任务。
图1展示了两组自然场景下的图像文字去除示例。当前,图像文字去除面临的困难与挑战主要有:1)图像文字去除方法需要感知到笔画级的位置信息,这比边框级的文字检测方法更复杂;2)去除文字后,原始的文字区域应填充与背景视觉一致的内容;3)非文字区域应尽可能保持原始图像中的样子。

图1 文字去除示例Fig.1 Text removal example((a)input images;(b)output images;(c)text area masks;(d)stroke-level masks)
Tursun等人(2019)通过添加文字区域二值掩膜作为辅助信息使模型更加关注文字区域,与现有的图像文字去除方法相比取得了明显改进,但是这种文字区域二值掩膜信息会覆盖文字笔画之间、文字和文字之间存在的大量无需去除的背景信息,这意味着实际去除的区域比真正需要去除的区域大,加大了去除文字后恢复文字区域的难度。显然,如果能够提取出精确的笔画级二值掩膜,就可以尽可能地保留输入图像的原始内容,继而得到质量更高的去除文字后的图像。
本文的创新点如下:1)首次将门循环单元(gate recurrent unit,GRU)(Chung等,2014)引入到图像文字去除任务中,通过对笔画级二值掩膜的提取,在文字去除阶段能更好地利用文字笔画之间、文字和文字之间的有用信息,从而提升模型的性能。2)通过将普通卷积替换成逆残差模块,使模型在性能略微损失的情况下,模型的计算量大幅降低,实现了高质量和高效的图像文字去除。3)设计了亮度损失函数和文字损失函数,进一步提升了结果的视觉真实感。
1 相关工作
早期的图像文字去除方法主要基于颜色直方图或者阈值。Khodadadi和Behrad(2012)基于颜色直方图估计候选块中的背景和文字颜色,然后基于匹配修复算法,能高效地重构文字区域中的图像内容。Modha和Dave(2012)通过结合形态学的方法定位出文字区域,然后用图像修复算法,对文字进行去除。Wagh和Patil(2015)通过对笔画特征的提取找到文字区域,然后使用最邻近匹配算法,对文字去除后的区域进行填充,但进行文字区域填充需要反复迭代,因此算法的效率不高。除了上述静态图像文字去除,也有一些工作研究去除视频帧的字幕和标题。Lee等人(2003)利用不同帧之间的文字和背景差异,在连续帧对时序的光流信息进行恢复,在当前帧对空间信息进行恢复,以此替换文字区域的像素达到去除文字的目的,实现了视频序列中文字的自动检测和去除。Mosleh等人(2013)通过对笔画宽度变换得到的连通成分进行无监督聚类,找到每帧中的文字位置,然后通过图像修复算法对文字区域进行修复。早期的这些方法着重于对图像数字化文字的去除,而这种文字的模式较为单一。相比之下,在真实的场景文字图像中,因为环境、光照等各种因素,造成文字模式十分复杂,这些方法通常无法很好地去除真实场景中的文字。
借鉴深度学习方法在计算机视觉任务中的巨大成功,基于卷积神经网络(convolutional neural network,CNN)(Lawrence等,1997)的方法使文字去除任务有了很大改进。Nakamura等人(2017)最先提出使用CNN从自然场景图像中去除文字,他们使用滑动窗口的方法将图像分成若干小块,并使用U-Net网络(Ronneberger等,2015)去除文字。该方法的文字去除过程在各个图像块上进行,然后将处理后的图像块合并在一起,这种基于图像块的处理机制会导致图像的结构一致性降低,并且限制了图像的处理速度。随后的研究又将生成对抗网络(generative adversarial network,GAN)(Goodfellow等,2019)引入到场景文字去除任务中,将GAN和U-Net形状的网络结构结合起来使用(Zhang等,2019;Liu等,2020),并通过风格损失、内容损失和总变分损失(Liu等,2018)等损失函数使文字去除效果取得更进一步提升,但是该方法使用的训练数据是通过文字合成(Gupta等,2016)技术得到的,这使得模型在真实场景下的泛化能力不足,对背景复杂的情况处理效果不佳,并且这种方法因为缺乏对文字区域信息的获取,所以无法对指定的部分文字区域进行去除。而通过引入文字区域二值掩膜,作为网络的附加输入(Tursun等,2019,2020),使得用户能够选择他们需要去除的文字区域。但他们使用的文字区域掩膜不够精细,忽略了文字笔画之间、文字和文字之间大量可利用的背景信息,这意味着模型处理区域明显大于实际文字所占区域,导致在文字区域较大或者文字笔画分散的情况下,出现文字去除不干净的现象。
直觉上,如果能够提取出准确的文字笔画,则意味着可以尽可能地保留输入图像的原始内容,继而可以获得更好的结果。但是,这样的精确区域很难获得,鲜有相关研究工作集中于区分文字笔画和非笔画区域。随着循环神经网络(recurrent neural network,RNN)(Mikolov等,2010)的发展,Qian等人(2018)利用长短期记忆网络(long short term memory,LSTM)(Shi等,2015)获得注意力图,将模型的注意力集中在雨水上,进而为雨水的去除起到很好的辅助作用。与文字去除有所不同,该方法针对全局图像进行雨水去除,而图像的文字去除方法则只针对文字区域。因此,受循环神经网络得到图像目标区域注意力图的思想启发,本文提出了基于门循环单元的图像文字去除方法,目的在于获得笔画级的精细文字掩膜,从而有效地指导模型更好地去除文字。
2 基本模型介绍
2.1 生成对抗网络
生成对抗网络由生成器网络(generator,G)和鉴别器网络(discriminator,D)两部分构成。生成器G的目的是尽可能学习真实的数据分布,使生成的图像尽可能地像真实数据,而鉴别器D的作用是计算输入数据来自真实数据而不是生成数据的概率,也就是使真实图像尽可能判别为真,生成数据尽可能判别为假,这样就使得生成器和鉴别器之间构成了一种动态博弈的过程,鉴别器能促使生成器生成更为真实的结果,而生成器会增强鉴别器的鉴别能力,两者相互对抗和优化,直到两者达到纳什平衡状态。在本文中,给定带文字的图像It和对应的没有文字的真实图像Igt,通过优化使生成器尽可能生成真实的没有文字的图像Iout。其中,需要解决的优化问题为

(1)
式中,E表示计算期望值,Igt服从数据真实分布Pd(Igt),It服从输入的初始分布Pd(It)。
2.2 门循环单元
RNN是功能强大的模型,具有记忆性和参数共享的特点,并且在字符预测和机器翻译等硬序列问题方面表现出色(van den Oord等,2016)。同时,RNN在建模灰度图像和纹理方面也能得到非常好的结果,但是无法很好地处理远距离依赖问题,而GRU能很好地解决长期记忆和反向传播中的梯度等问题,且较LSTM参数量更少(Wang等,2017;Dey和Salem,2017),其结构如图2所示(Chung等,2014),其中更新门ut表示前一时刻的特征信息在当前时刻的重要程度,更新门的值越大,说明前一时刻的特征信息越重要;重置门rt用于控制忽略前一时刻的特征信息的程度,重置门的值越小,说明忽略得越多。

图2 GRU结构示意图Fig.2 The structure of the gate recurrent unit
3 基于GRU的图像文字去除模型
图3为本文提出的图像文字去除模型的整体结构。首先将带文字的图像It和对应文字区域的二值掩膜Mr作为输入,利用笔画级二值掩膜生成模块得到笔画级的文字掩膜Mt,然后将得到的Mt、It和Mr组合成5通道的数据作为文字去除模块的输入,通过文字去除模块对文字区域进行去除和修复后,输出为不带文字的图像Iout,同时,使用鉴别器区分真假,以提升输出结果的真实感,整个过程是端到端的。
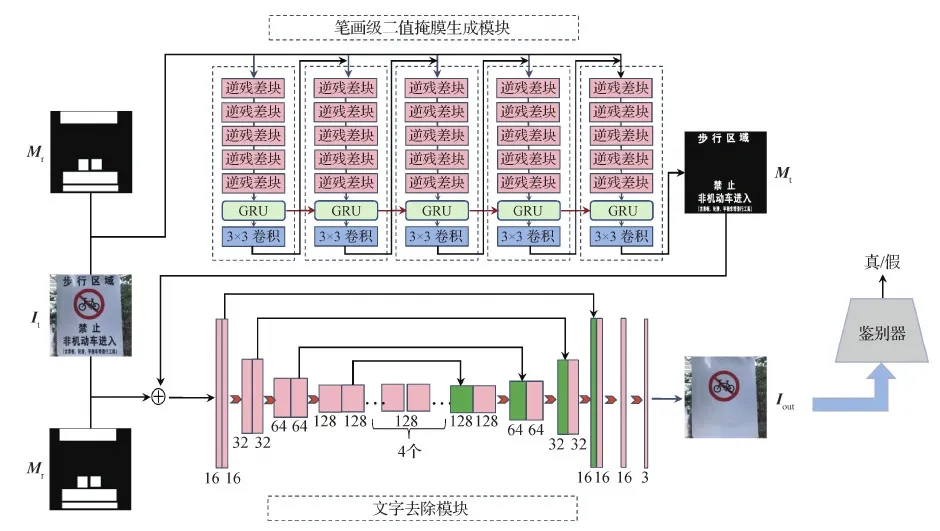
图3 GRU图像文字去除模型结构图Fig.3 Image text removal network based on gate recurrent unit
3.1 笔画级二值掩膜生成模块
现有的图像文字去除模型,输入分为两种,1)只输入带文字的图像It;2)输入带文字的图像It和对应文字区域的二值掩膜Mr。方式1)中不需要额外的文字区域的标记,所以数据集获取比较容易,但是得到的模型难以处理文字背景复杂的情况,同时模型无法满足部分文字去除的需求;方式2)中因为有了文字区域掩膜的加入,模型会更关注文字区域,所以去除的效果会更好,并且能对指定区域的文字进行去除,但是需要额外的文字区域掩膜数据,所以数据集的构造会更加困难,同时因为文字区域往往不能很精准地将文字笔画分割出来,导致文字笔画之间的大量信息无法利用,因此,本文提出了一种基于GRU的笔画级文字掩膜生成模块,能高效地根据带文字的图像It和对应文字区域的二值掩膜Mr,生成笔画级二值掩膜Mt。
如图3上半部分所示,由GRU组成的网络用于生成笔画级的二值掩膜Mt。每个子模块由5个逆残差层对输入的图像和前一个子模块生成的掩膜进行特征提取,然后使用GRU和1层卷积操作生成当前模块的笔画级掩膜Mt。
本文使用的GRU由更新门ut和重置门rt组成,门与门之间沿着时间维度的相互关系定义为

(2)
式中,Xt是由逆残差层提取的特征,Ht是经过GRU之后的输出特征,符号⊙代表逐元素相乘,*代表卷积操作,σ为sigmoid激活函数,在得到GRU的输出特征Ht之后,对其进行一次卷积操作,就可以得到一个笔画级的文字掩膜特征图Ot。在每个子模块结束后,将当前阶段得到的笔画级二值掩膜特征图和输入的图像进行连接组合,然后输入到下一个阶段的GRU子模块中。
在训练阶段,通过对每个子模块中得到的笔画级二值掩膜特征图计算L2损失,得到损失函数Lm,该损失函数的定义为
(3)
式中,{O}为所有GRU模块的笔画级二值掩膜特征图的集合,M为笔画级二值掩膜的ground-truth。M可以通过将带文字的图像It和对应的没有文字的图像Igt处理后得到。N为循环GRU子模块的个数,N越大,最后得到的笔画级二值掩膜Mt(最后一个Ot即为Mt)越准确,但是计算量也会更大,在本文中N取值为5。λ为每个GRU模块的损失权重,越早产生的损失值贡献越小,在本文中取值为0.7。
3.2 基于GAN的图像文字去除
3.2.1 文字去除模块
文字去除模块将带文字的图像It和对应文字区域的二值掩膜Mr以及生成的笔画级二值掩膜Mt三者一起组合成5通道的数据作为输入,输出为去除文字后的图像。输入和输出图像的尺寸均为256 × 256像素。
文字去除模块的网络结构如图3下半部分所示。本文使用的文字去除模块是一种编解码(Badrinarayanan等,2017)的网络结构。在编码阶段,首先经过两个卷积层,得到大小为256 × 256像素、通道数为16的特征图,其中使用的卷积核大小为3 × 3,步长为1,接着使用3组下采样,每组包含一个步长为2和一个步长为1的卷积层,每次下采样后,特征图的高度和宽度减半,通道数加倍。中间部分使用4个步长为1的卷积层,目的是为了加深网络,提取深层次的特征。在解码阶段,使用3组上采样,每组包含一个步长为2的反卷积操作和一个步长为1的卷积操作。同时,为了加强模型对纹理细节和结构的恢复,以及为了避免模糊结果的产生,使用了跳跃连接,将编码器的浅层特征信息输入到解码器的对应层,使浅层特征得以更好地利用,从而保证模型恢复出更多的细节特征。最后使用一个步长为1、卷积核大小为3 × 3的卷积层,得到最终的无文字图像。
本文将文字去除模块中的所有卷积操作都用逆残差块(Sandler等,2018)代替,目的在于减少模型的参数量和计算量,使最终得到的模型能够很好地去除图像中的文字。其中,逆残差块的结构如图4所示,先用一个卷积核为1 × 1的点卷积操作,扩大输入特征图的维度,防止通过激活函数后因为维度过低丢失过多的信息,然后使用卷积核为3 × 3的深度卷积(Howard等,2017)对特征进行提取,最后使用一个1 × 1的点卷积,压缩特征的通道数。其中,在步长数为1时,因为输入和输出维度相同,所以能使用残差结构,使模型在较深时依然能很好地训练。

图4 逆残差块结构示意图Fig.4 The architecture of the inverted residual blocks
需要注意的是,本文在文字去除模块中的所有激活函数均使用ReLU6。同时,本文没有使用批归一化层,因为批归一化层会破坏颜色一致性,降低模型的效果(Yu等,2018)。
文字去除模块使用的损失函数由文字损失函数LT、图像亮度损失函数LY和生成器对抗损失函数Lg3部分组成。
文字损失函数LT是为了尽可能地在去除文字的同时,保留非文字区域的信息,所以将更多的注意力放在文字区域。具体地,对文字区域和非文字区域使用逐像素的L1损失函数。具体为
(4)
(5)
LT=10Lt+Lnt
(6)
式中,1和Mt具有相同形状,但是值都为1。
同时,研究表明(Xu等,2012;Dong等,2016),人眼对图像的亮度变化更为敏感,因此,将输出图像Iout和Igt从RGB空间映射到YCrCb颜色空间,然后将亮度通道分离出来得到Yout和Ygt,对两者使用L1损失函数,得到亮度损失函数LY。具体为
(7)
对于生成器的对抗损失函数,使用经典的生成器对抗损失函数(Goodfellow等,2019),即
LDsn=E[ReLU(1-Dsn(Igt,Mr,Mt))]+
E[ReLU(1+Dsn(Iout,Mr,Mt))]
(8)
式中,Dsn表示频谱归一化鉴别器。
综上,文字区域掩膜和带文字的图像首先通过由5个GRU组成的笔画级二值掩膜生成模块得到笔画级掩膜,然后该掩膜作为辅助信息进入到文字去除模块,进行图像的文字去除,这两个模块整体上构成了生成器部分。整个过程是端到端训练的。随着训练次数的增加,笔画级二值掩膜生成模块得到的笔画级掩膜会越来越精确,进而提升了文字去除的效果。整个生成器损失函数由笔画级二值掩膜生成模块的损失函数和文字去除模块的损失函数构成,即
LG=Lm+LT+LY+Lg
(9)
3.2.2 鉴别器网络
为了尽可能将生成器生成的图像分类为假图像,将真实数据分类为真图像,一些基于GAN的方法引入了两种类型的鉴别器,分别为全局鉴别器和局部鉴别器。全局鉴别器能很好地鉴别出整个图像是否存在不一致,而局部鉴别器则专注于指定区域是否存在不一致,这种策略通常需要局部区域是规则的矩形,而在本文的任务中,文字区域是任意形状的,因此使用SN-PatchGAN(Yu等,2019)作为本文的鉴别器网络,其结构如图5所示。该鉴别器使用6个卷积核大小为5 × 5、步长为2的卷积层获取高维特征。然后对高维特征的每个特征元素都进行鉴别,同时因为输出特征的每个神经元的感受野都能覆盖全图,所以无需另外使用全局鉴别器,具体的鉴别器损失函数为

图5 鉴别器模型Fig.5 The architecture of the discriminator
LDsn=E[ReLU(1-Dsn(Igt,Mr,Mt))]+
E[ReLU(1+Dsn(Iout,Mr,Mt))]
(10)
4 实验结果与分析
4.1 实验设置
实验使用的硬件环境为Intel(R)Xeon(R)E5-2690 v4 2.60 GHz CPU,NVIDIA TITAN RTX(24 GB显存)GPU,256 GB内存;软件环境中操作系统为Ubuntu 16.04.6 LTS,深度学习框架为Tensorflow 1.13.1,CUDA为V10.0。输入图像的尺寸为256 × 256像素,初始学习率为0.000 1,批处理大小为4,网络训练使用的优化器为Adam(Kingma和Ba,2014),优化器的两个参数分别为β1=0.5、β2=0.9。
4.2 数据集
对于图像文字去除任务,需要成对的带文字的图像和没有文字的干净图像训练深度模型。然而,在自然场景中很难同时获得这种成对的数据。现有方法(Tursun等,2019;Zhang等,2019)都是通过在没有文字的图像上使用文字合成方法获取大量训练数据。这种合成的训练数据,虽然能模拟真实场景中的文字,但是始终和真实环境下带文字的图像是有差异的,因此本文构建了一个真实的数据集。具体地,从ICDAR2017 MLT(International Conference on Document Analysis and Recognition)数据集(Nayef等,2017)中收集了5 070幅真实环境中带文字的图像,这些图像采集自各种各样的场景,并且包含多种语言文字,同时又从日常的生活环境中,拍摄了1 970张照片,然后用Photoshop软件将搜集的带文字的真实图像去除掉文字得到Igt,获得7 040组真实的训练数据,与此同时为了增加数据集的多样性,使用文字合成的方法合成了4 000组高真实感的数据,最终,本文使用的训练集数据共11 040组。对于测试集,另外准备了1 080组真实数据和1 000组合成数据。
上述每组数据对应的文字区域二值掩膜Mr是通过人工标注得到的,对应的笔画级二值掩膜Mt则是用带文字的图像It和去掉文字的图像Igt通过计算得到,具体计算为
(11)
式中,Mt、It和Igt分别为各自对应的图像中的每个像素点的值,在本实验中阈值δ为27,gray为灰度化操作,abs为取绝对值运算。
4.3 与现有方法比较
为验证本文方法的性能,与现有的文字去除算法STE(scene text eraser)(Nakamura等,2017)、EnsNet(ensconce network)(Zhang等,2019)、MTR(mask-based text removal network)(Tursun等,2019)、EraseNet (erase network)(Liu等,2020)和MTR++(Tursun等,2020)进行对比。其中EnsNet和EraseNet使用官方提供的源代码进行训练和测试,STE、MTR和MTR++算法严格按照其原文所述进行复现。为了保证公平,所有模型都训练到收敛。本文方法与对比方法在真实数据集和合成数据集上的测试结果如图6所示。
从图6可以看出:1)STE、EnsNet和EraseNet方法在模型推理测试阶段没有使用文字区域的二值掩膜,所以模型无法准确地知道需要去除的文字的区域,得到的结果会有明显的文字轮廓和文字笔画的残留,而本文方法能将文字去除得很干净。2)MTR方法虽然使用了文字区域二值掩膜,但是这种掩膜覆盖的区域较大,所以会出现明显的过平滑现象,导致在视觉感受上和周围背景不一致。MTR++方法没有考虑浅层掩膜特征对后续阶段的影响,导致生成的笔画级二值化掩膜不够精细。而本文方法则利用不同阶段的掩膜特征信息得到更为精准的笔画级二值化掩膜,所以能更好地利用文字笔画之间、文字和文字之间的有用信息,从而在图像的细节恢复上取得很好的效果,如图6的第3和4行所示,本文方法能很好地还原出背景图像的结构。这些结果表明,本文方法在文字区域的二值掩膜的基础上,通过检测笔画级的二值掩膜,能在引导模型去除文字区域内容的同时,更好地保留非文字区域的信息,从而得到细节更丰富、图像结构更为合理的结果。3)STE、EnsNet和EraseNet方法因为没有文字区域掩膜的引导,无法做到对指定文字区域的去除,而部分文字去除是诸如图像编辑等应用所需要的功能。图7展示了MTR、MTR++和本文方法对部分文字去除的效果的比较,其中绿色框中的文字是需要去除的部分。可以看到本文方法能很好地去除被选中部分的文字,未被选中的文字则能很好地保留。

图6 不同方法的测试结果Fig.6 Test results of different methods((a)input;(b)STE;(c)EnsNet;(d)MTR;(e)EraseNet;(f)MTR++;(g)ours;(h)ground truth)

图7 部分文字去除结果Fig.7 Examples of partial text removal on real scenes ((a)input;(b)MTR;(c)MTR++;(d)ours)
与EnsNet使用的评价指标一致,本文使用两类评价指标对结果进行定量评价。第1类评价指标是用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)衡量去除文字后的结果与真实值之间的差异。第2类评价指标是用准确率(P)、召回率(R)和F值(F)衡量模型去除文字的能力。
具体地,本文使用目前最先进的文字检测算法CRAFT(character region awareness for text detection)(Baek等,2019)检测结果图像中的文字,并用DetEval(Wolf和Jolion,2006)方法计算出R、P、F的值。R、P、F的值越低,表示文字去除模型的性能越好。然而,这种方法没有考虑图像整体的视觉感受,即如果图像内容完全擦除,文字检测结果将是最好的,但这是不合理的,所以需要结合PSNR和SSIM评价图像的质量。PSNR和SSIM的值越大,代表模型性能越好。表1和表2分别展示不同模型在两个测试集上各评价指标的测试结果的均值。可以看出,本文方法在图像质量指标和文字检测指标上均表现最好,证明本文的图像文字去除方法较其他方法表现更好。

表1 真实数据集的测试结果对比Table 1 Comparison of test results on real dataset
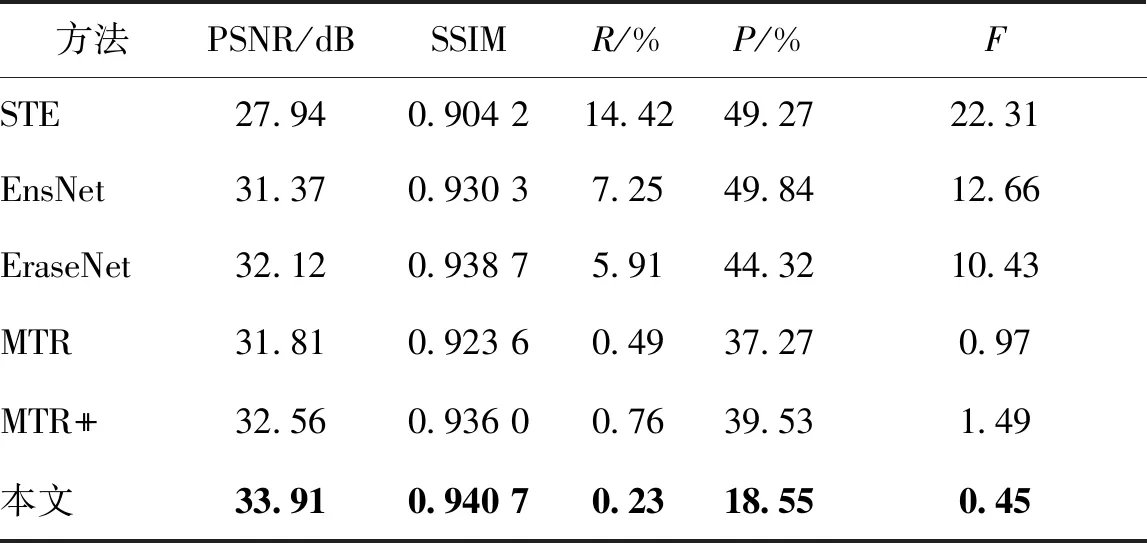
表2 合成数据集的测试结果对比Table 2 Comparison of test results on synthetic dataset
4.4 消融实验
为了分析每个因素对模型效果的影响,进行了多组消融实验。
为了比较笔画级二值掩膜对图像文字去除效果的影响,在保持输入数据和其他训练参数不变的条件下,进行了两组实验:1)使用生成器和鉴别器网络对图像文字进行去除,用TE_GD表示;2)在TE_GD方法的基础上,加上笔画级二值掩膜检测模块,用TE_GDM表示。图8和表3展示了在真实数据的测试集和合成数据的测试集下的文字去除结果。从图8可以看出,TE_GD在文字区域较大的情况下,出现了颜色混乱和过平滑的现象,对非文字区域的细节保留的不理想,而TE_GDM的结果明显优于TE_GD。从表3可以看出,添加了笔画级二值掩膜后的各项评价指标均有所提升。

图8 消融实验结果对比Fig.8 Comparison of ablation experiment results((a)input;(b)TE_GD;(c)TE_GDM)

表3 笔画级二值掩膜有效性实验结果Table 3 Validation of binary stroke mask of real dataset
为了评估逆残差块的有效性,在保持同样网络配置的情况下,将卷积方式替换为普通的卷积进行训练,用TE_Conv表示。表4展示了TE_Conv和本文使用的逆残差块的方案在模型的参数量和浮点运算次数(floating point of operations,FLOPs)上的差异,同时从图像质量的角度对比了两者在真实数据的测试集下图像质量指标PSNR和SSIM的差异。可以看出,两者在图像质量上的差异很小,但是使用逆残差块方案的FLOPs降低了72.0%,证明了该方案的有效性。

表4 逆残差块结果对比Table 4 Comparison of test results of inverted residual block
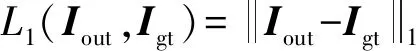
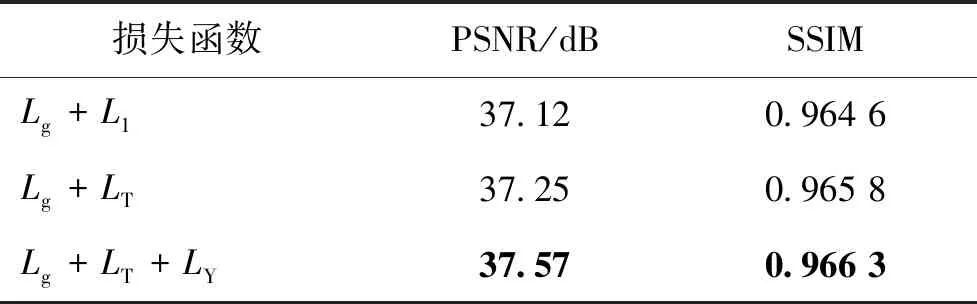
表5 不同损失函数结果对比Table 5 Comparison of results of different loss functions
5 结 论
本文提出了一种基于门循环单元的图像文字去除模型,以带文字的图像和文字区域二值掩膜为输入,通过端到端的方式,得到去除文字后的图像。首先,本文构造了笔画级二值掩膜生成网络,通过叠加的逆残差块和门循环单元获得更为精细的笔画级掩膜,以此帮助基于生成对抗网络的文字去除模块,能将注意力更好地集中在文字笔画区域。其次,采用逆残差替代普通的卷积,进一步优化了模型的大小,从而达到了模型去除文字的效果和模型性能之间的平衡。最后,通过对比试验,验证了本文网络设计以及损失函数的有效性。相比现有的方法,本文能高质量和高效率地实现图像文字去除。
本文方法仍然存在局限性,针对艺术体的文字和带有光影轮廓的文字,本文方法的效果还有待提升。如图9所示,当输入图像的文字存在轮廓以及字体为夸张的艺术字体时,本文的文字笔画检测网络难以准确地提取出笔画级二值掩膜,文字去除的效果欠佳。在未来的工作中,计划通过在数据集中加入更多复杂字体和带光影轮廓的数据,并设计更有效的文字去除模型,以进一步提高图像文字的去除效果。

图9 局限性示例Fig.9 Limitation examples
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
初中生世界·九年级(2018年12期)2018-12-22
小天使·二年级语数英综合(2018年10期)2018-10-15
中国新通信(2017年9期)2017-05-27
读者(2015年9期)2015-05-04
时代英语·高三(2014年5期)2014-08-26
初中生世界·八年级(2014年2期)2014-03-15
意林(2011年10期)2011-05-14
