
DenseNet生成对抗网络低照度图像增强方法
2022-04-21 05:21王照乾孔韦韦滕金保田乔鑫
计算机工程与应用 2022年8期
王照乾,孔韦韦,滕金保,田乔鑫
1.西安邮电大学,西安 710121
2.陕西省网络数据分析与智能处理重点实验室,西安 710121
在图像采集过程中,所在场景的光照条件往往是影响图像质量的重要因素之一,在现代社会生产生活中,人们采集图像变得更为方便和快捷,由于光照条件不足产生的低照度图像识别度不高,导致缺乏可用性,并对后续的图像处理、目标识别、语义分割等任务造成了困难。
早期对低照度图像增强的主流方法如Pizer等[1]提出的基于直方图增强法(histogram equalization,HE),该方法通过调整图像直方图分布达到增强图像亮度和对比度的目的,具有简单快速的优点,但存在图像失真等问题。随后,Land[2]提出了Retinex理论:人类眼睛视觉感受到的亮度和对色彩的感知与周围环境光照强度无关,而是由物体自身实际反射率来决定。依据此理论出现了单尺度Retinex(single scale R,SSR)方法[3]和多尺度Retinex(multi-scale Retinex with color restoration,MSRCR)[4]方法来对低照度图像增强,此类方法虽然达到了对低照度图像增强的目的,但依旧存在颜色失真、边缘模糊等现实问题。
另外,还有一些基于Retinex理论的传统方法,如Fu等[5]提出的一种基于融合的低照度图像增强方法;Guo等[6]提出的基于照度区域估计的方法;Ying等[7]提出的基于融合的方法;Ren等[8]提出的结合图像去噪的低照度图像增强方法,这些方法虽然一定程度上达到了增强图像照度的效果,但同样存在颜色失真和纹理模糊等问题,无法获得高质量的图像。
目前,深度学习技术迅速发展,并且在计算机视觉方面有着广泛的应用和优良的效果,深度学习模型可以利用大量数据来完成对深度模型的训练,比如输入大量不同照度的图像,利用自动编码器或卷积神经网络进行训练,从而达到对低照度图像增强的效果。其中,Lore等[9]首次提出一种利用自动编码器实现低照度图像增强的方法,由于该模型采用的是处理图像降噪任务的深度编码器改进后的模型,计算能力有限,所以该模型一般只适用于处理小尺寸的图像。随后,Tao等[10]利用卷积神经网络(convlutional neural network,CNN)和残差学习对Lore的方法进行改进,取得了不错的效果。此外,Li等[11]提出的LightenNet运用四层卷积CNN模型对图像照度进行增强;马红强等[12]也采用CNN模型对低照度图像进行增强,但其特色在于对图像的RGB到HIS进行颜色空间转换,更有助于达到增强图像照度的目的。总体看来现有的深度学习模型在一定程度上弥补了传统方法存在的缺点和不足,但也存在着较大的提升空间。
随着生成对抗网络(GAN)[13]的提出,研究人员将GAN应用到了计算机视觉领域,并取得了较好的效果[14]。为了提升对低照度图像增强的处理效果并得到高质量的图像,本文利用对抗网络训练特点和学习能力,提出了一种基于DenseNet[15]生成对抗网络的低照度图像增强方法。此方法运用DenseNet作为框架搭建生成器网络,其优势在于具有非常好的抗过拟合性能,尤其适合于训练数据相对匮乏的任务,另外本文使用PatchGAN作为判别器来监督生成器网络,提升生成器生成高质量图像的能力。
1 相关理论
1.1 生成对抗网络
生成对抗网络(GAN)是由生成器网络G和判别器网络D二者相互博弈组成。生成器的任务是把输入的噪声数据经过生成网络得到生成数据,判别器的任务是负责辨别真实的数据和生成的数据,生成器不断更新网络权值以生成更加接近真实数据的生成数据,从而使判别器无法判别生成数据的真假。判别器同时也在不断更新网络权值以达到最精准的判别效果。生成器与判别器二者间不断博弈对抗,最终达到一个动态平衡的状态,此时生成器的生成效果最佳。这里给出GAN的数学模型:
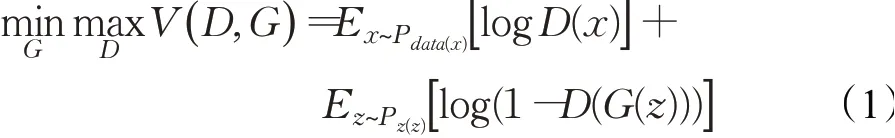
其中,V表示生成器D和判别器G的最终优化目标,E表示数学期望,x~Pdata(x)表示数据来源于真实数据,z~PZ(Z)表示z为服从(一般为高斯分布)的随机噪声,G(z)表示随机噪声z通过生成器G得到的生成数据,D(x)和D(G(z))表示判别器对真实数据和生成数据进行判别。
1.2 DenseNet理论
目前,计算机视觉领域采用CNN已成为主流方法,例如GoogleNet、VGGNet、Inception等模型,而残差网络(RestNet)[16]的出现更是把CNN带到了一个新的高度,构建RestNet模型的核心是通过建立前一层和后一层间的“短路连接”(shortcuts,skip connection),这种结构的优势在于加速了训练过程中梯度的反向传播,从而可以满足更深的CNN网络训练。DenseNet的思路与RestNet基本一致,其二者的结构区别如图1所示。
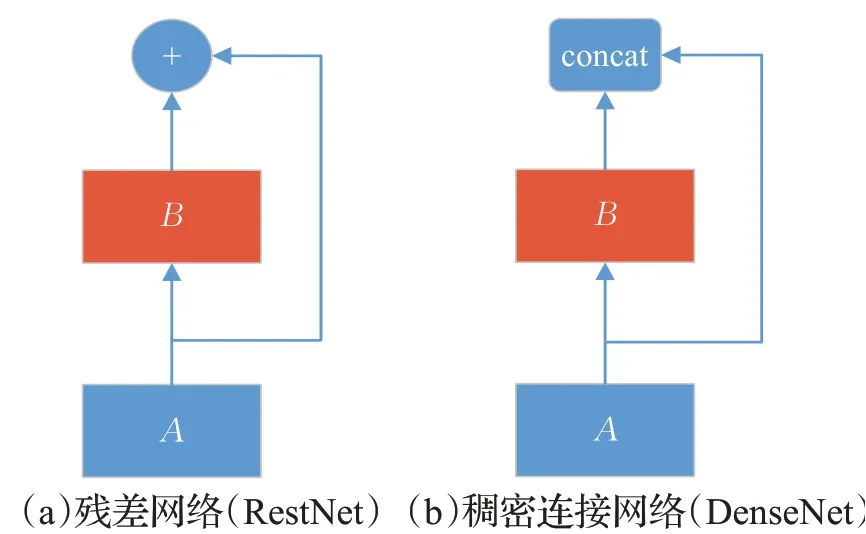
图1 残差网络与稠密连接网络Fig.1 RestNet and DenseNet
在RestNet中,A层与B层之间加入了一个高速通道——“短路连接”,A层的输入可以跳过B层,和B层输出做一次加法,这样做的优势在于:梯度在反向传播时,最上层的梯度可以直接跳过中间层B,传至最下层A,从而避免最下层A的梯度过小。
然而,在DenseNet中,A层输出和B层输出并非相加,而是在通道维度上连接,这样做的目的是使A层输出直接和B层后面所有层连接在了一起,其优势在于特征重用以及方便梯度传递,可以让DenseNet在参数、样本和计算成本更少的任务中获得比RestNet更具有优势的性能。
1.3 PatchGAN理论
通常情况下,GAN模型的判别器网络是一个二分类判别器,判别器对输入的数据做判别,判断是真实数据还是生成数据。PatchGAN又称马尔科夫判别器,与传统判别器的输出结果有所不同,PatchGAN最后输出一个N×N的矩阵,然后通过计算矩阵的均值作为判断真假的输出,这和原始的二分类判别器输出一个代表真或假的矢量有着根本区别。其中,输出矩阵的每一个输出是模型对应原图像中的一个感受野,对应原图像的一部分区域。
2 本文方法
本文所提出的基于DenseNet生成对抗网络,避免了采用传统CNN模型作为生成对抗网络的框架,而是结合优势更加明显的DenseNet作为框架来搭建生成器网络,有效地解决了梯度消失等问题,具有参数量和计算量小、抗过拟合、泛化能力更强等优势,并且使用PatchGAN作为判别器代替传统的二分类判别器,使得训练的模型更加注重图像细节,提高了图像质量,加快了网络收敛速度。本文方法的网络结构如图2所示。
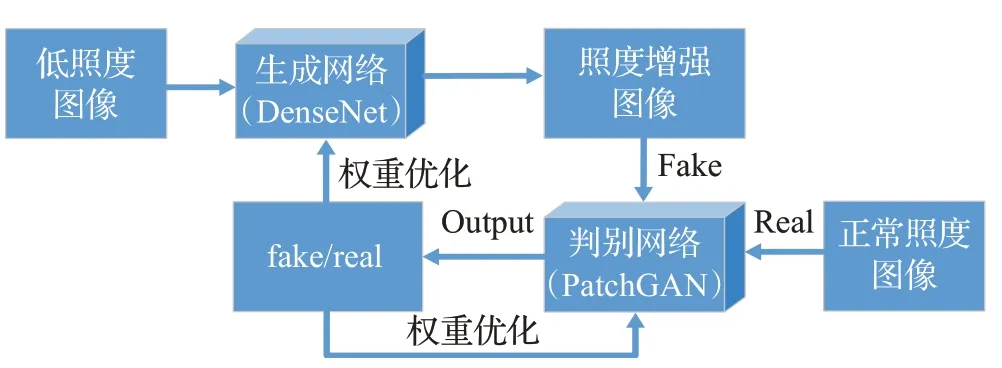
图2 DenseNet生成对抗网络低照度图像增强模型Fig.2 Low illumination image enhancement model based on DenseNet GAN
2.1 生成器网络结构
本文以DenseNet为框架搭建生成器网络,建立低照度图像与真实的正常照度图像间的映射关系,利用反向传播来训练生成器网络获得最优的权重值,从而让生成器对低照度图像的增强效果达到最佳。本文生成器的网络结构和该网络中的DenseNet结构如图3、图4所示。

图3 本文的生成器网络结构Fig.3 Generator network structure of this paper
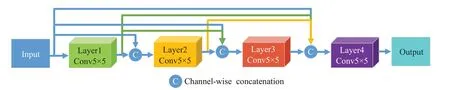
图4 生成器网络中的DenseNet Fig.4 DenseNet in generator network
(1)上采样层,由4个4×4大小的卷积核组成,对输入图像进行特征提取,卷积核个数分别为1 024,512,256,128,每层间经过卷积后采用BatchNorm对数据进行标准化处理,使用ReLu作为激活函数,对输入数据进行上采样传入DenseNet。上采样特征提取公式为:

其中,X代表输入的低照度图像,GLi代表第L层输出的第i组特征图,“*”代表卷积操作,GLi代表第L层的第i组卷积核,i=1,2,3,4。
(2)在设计DenseNet结构时,根据本任务小样本空间的特点,为了防止层数过深,导致参数量过多产生过拟合,本文设计的DenseNet为四层,Layer1,Layer2,Layer3均采用5×5卷积核,通道个数为128,每层之间经过卷积后采用BatchNorm对数据进行标准化处理,使用ReLu作为激活函数,最后一层Layer4采用5×5卷积核,通道个数为3,经过卷积后使用Tanh作为激活函数,整个DenseNet中有3个concatenation用来将不同尺寸的特征图调整为统一的通道数进行连接。
(3)DenseNet的映射函数为:
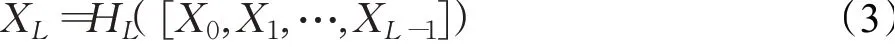
其中,[]表示将第X0层到XL-1层的所有输出的特征图按通道数大小组合在一起,HL表示使用BatchNorm+Relu+conv进行非线性变化。
2.2 判别器网络结构
本文在设计判别器网络时参考Isola等[14]提出的PatchGAN判别器来替换传统的二分类判别器,该判别器输出N×N矩阵,经过矩阵均值计算来判断该图像是真实图像或生成图像。相比传统的二分类判别器,使用PatchGAN判别器的优势在于其输出是一个矩阵,最终结果为矩阵均值,充分考虑到了图像不同区域的影响,从而提升了图像质量,更加注重了图像细节;此外,对小尺寸图像块的计算大大加快了网络的收敛速度。本文设计了4层全卷积层的CNN模型,除最后一层卷积层外,其余3层每层之间经过卷积后使用BatchNorm对数据进行标准化处理,并采用LeakReLu作为激活函数,其具体结构如图5所示。

图5 本文的判别器网络结构Fig.5 Network structure of discriminator in this paper
2.3 损失函数
本文生成器网络和判别器网络训练过程中均使用均方误差损失函数(mean square error,MSE)。对于生成器网络,MSE用于计算生成照度增强后的图像与正常照度图像之间的误差。MSE对于判别器网络,目的是计算经判别器网络处理后的图像与正常照度图像之间的损失,MSE值越小,说明生成器生成的照度增强后的图像越接近真实图像。反之,与真实图像差距越大。生成器和判别器的损失函数计算公式分别为:
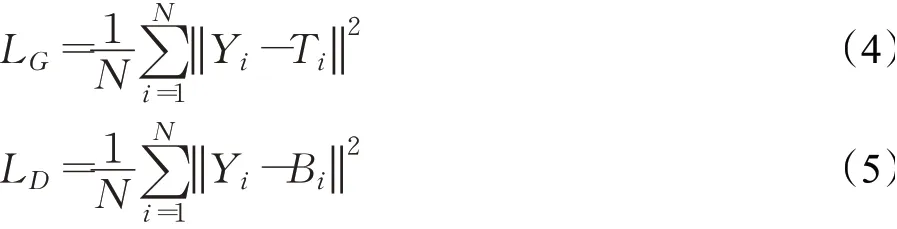
其中,LG代表生成器网络的损失,L D代表判别器网络的损失,N代表训练样本数目,Y i代表第i组真实的正常照度图像值,Ti代表生成器生成的第i组输出,Bi代表判别器的第i组输出。
3 实验与结果分析
为了验证本文方法的有效性,本章分别从实验数据集、实验设置以及结果分析等方面进行了论述。仿真实验首先将低照度图像传入生成器网络,生成照度增强的图像,然后将生成器生成的图像和正常照度的图像传入PatchGAN判别器,并计算损失值,同时对生成器网络和判别器网络进行权重优化,最后训练模型达到稳定状态,得到较好的照度增强效果。
为了客观评价本文方法对低照度图像的增强性能,将选取的低照度图像数据集应用于本文方法和几种现有的主流方法,同时对它们在照度增强方面的处理效果进行对比。选取的现有主流方法有:HE[1]、基于相机模型的Ying[7]、Ma[12]、MSRCR[4]、Guo[6]、Lore[9]、Li[11],采用的客观评价指标有峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似度(structural similarity,SSIM)、处理时间等三项指标。
3.1 实验数据
本文实验采用的图像数据集由Cai等[17]提供的多曝光度图像数据集,利用调整相机的曝光值调节拍摄的曝光度,从而采集不同照度的图像,其中包含589个精心挑选的高分辨率多曝光序列和4 413幅图像,数据集中每一张低照度图像都有与其对应的真实的正常照度图像,场景包含了室内外、人像、物品等。本文实验从中选取580幅图像作为训练集,以及60幅图像作为测试集。同时,为了增加训练图像的多样性,随机对图像进行水平或竖直方向的翻转。
3.2 实验设置
本文实验使用Tensorflow深度学习开源框架,采用CPU配置为Intel Core i5-10300H,GPU配置为NVIDIA GeForce GTX 1660ti,在Win10+16 GB内存的PC平台上对本文方法模型进行训练。训练期间学习率为固定参数0.000 2,迭代次数为6 000,batch-size为64,优化器选用Adam优化器,设置动量参数一阶矩估计的指数衰减率为0.5,设置二阶矩估计的指数衰减率为0.999。
3.3 主观评价
为了直观地展示本文方法对低照度图像增强的效果,本实验从真实数据集中选取三幅低照度图像,使用本文方法和其他方法对低照度图像亮度进行增强,不同方法的增强效果如图6~图8所示。
在图6~图8中,经过不同方法的增强处理后,从视觉效果方面可以直观看出,经HE、MSRCR处理后,图像虽然能够达到改善照度的目的,但处理后的图像出现了色彩偏差、颜色失真的问题。特别是MSRCR在面对复杂场景图像时,处理效果整体偏暗。

图6 不同方法对低照度图像scenery的增强效果对比Fig.6 Contrast of different methods for scene enhancement of low illumination image
经Guo方法和Ying方法处理后的图像在色彩还原方面要明显优于前两种方法,其中Guo方法虽然对图像整体处理效果不错,但对比正常照度图片,Guo方法增强后的图像饱和度较高,图像整体效果不够自然,且在细节恢复上存在差距。与本文方法相比较,Ying方法增强后的图像,从视觉效果方面看图像色温偏白色,并且对图像中偏暗的区域亮度增强效果欠佳。

图7 不同方法对低照度图像child的增强效果对比Fig.7 Contrast of different methods for child enhancement of low illumination image
基于融合的Lore方法,虽然对低照度图像在照度上达到了一定的增强效果,但与真实图像相比在亮度恢复方面还是与本文方法存在一定差距。经Ma方法增强后的图像,与本文方法最大的差距是在图像纹理方面,Ma方法增强结果较为模糊。基于CNN的Li方法模型过于单一简单化,所以对图像的亮度增强能力有限,增强后的图像亮度偏低。
而本文方法的增强效果在视觉直观方面,不仅使照度增强后的图像在亮度方面与正常照度的图像亮度非常接近,而且较好地做到了对图像细节信息的保留和色彩还原,增强后的图像更加自然,视觉效果更好。
3.4 客观评价
除了直观展示对低照度图像增强的效果外,为了能进一步说明本文方法对低照度图像增强效果的优势,实验同时计算和记录了各种方法的PSNR、SSIM、处理时间三项指标值对实验中的方法进行定量评价。
PSNR[18]是一种衡量图像失真或噪声水平的客观标准指标,PSNR值越小说明两幅图像之间越趋于劣化,图像照度增强效果也越差,反之PSNR值越大说明图像受噪声影响较小,失真也越小,图像照度增强效果也越好,计算公式为:
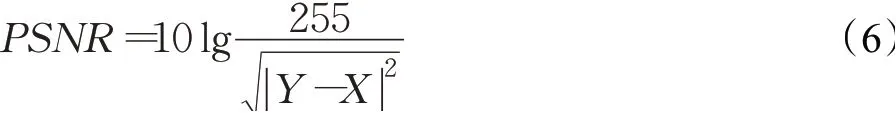
其中,Y代表正常照度图像,X代表低照度图像。
SSIM[19]是一种衡量两幅图相似度的指标,也是常用的图像质量评价标准,SSIM值的范围从0到1,其值越接近1说明两幅图像越是接近,失真越小,图像照度增强效果质量越好,计算公式为:
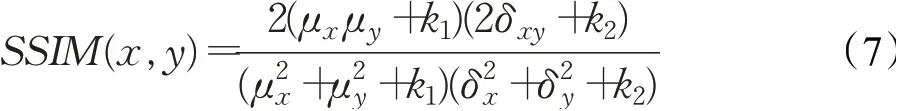

实验最后,不同方法对图6~图8照度增强效果的客观评价指标对比结果如表1所示,其中MSRCR方法一味追求图像亮度增强效果,而牺牲了模型的准确性,所以其PSNR值和SSIM值均较低。而Ma方法中加入了对图像RGB到HIS的颜色空间转换,所以其PSNR值和SSIM值表现较好。
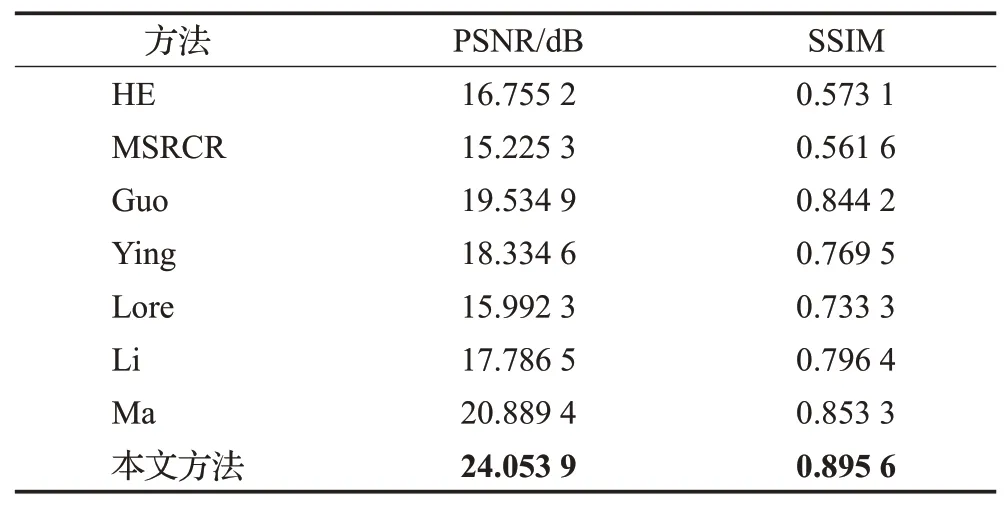
表1 不同处理结果的客观对比Table 1 Objective comparison of different treatment results
从表1中可以明显看出,本文方法模型在PSNR值和SSIM值这两项指标方面,都要优于其他方法,这也表明本文的基于DenseNet生成对抗网络模型在低照度图像增强任务中具有较明显的优势。
3.5 计算效率
除了从主观视觉效果和客观指标两方面对几种方法的增强效果进行比较外,每种方法的运行时间,也是衡量一个方法模型计算效率的一项重要指标,运行时间越短说明模型的算法复杂度越小。实验选取图6~图8用来测试几种方法的处理时间并进行比较,每种方法分别对每幅图像运行三次,并记录三次运行时间,取平均值作为最终结果,实验结果如表2所示。需要说明的是,所有方法均采用在同一PC平台上进行运算,其中本文方法和Li、Ma使用PYTHON语言编写,基于GPU进行运算。MSRCR使用MATLAB语言编写,基于CPU进行运算。HE、Guo、Ying、Lore使用PYTHON语言编写,基于CPU进行运算。

表2 不同方法的运行时间Table 2 Running time of different methods s
从表2中不难看出,本文方法和Li、Ma三种借助GPU运行的方法,其处理时间要快于其他基于CPU运行的方法。本文方法模型的运行时间在所有方法中处于次优,需要指出的是,由于Li的模型结构较为简单,且借助GPU进行运算,所以在第三项指标处理时间上要优于本文方法。最终综合表1、表2三项指标的对比结果不难得出结论,本文所提出的基于DenseNet生成对抗网络对低照度图像增强的方法,相比其他现有的主流方法在客观评价方面有着较为突出的优势。
4 结语
为了解决低照度图像亮度增强的问题,本文提出了一种基于DenseNet生成对抗网络的低照度图像增强方法,方法改进了传统的以CNN作为生成器网络的结构,采用DenseNet作为框架搭建生成器网络,方便信息量快速传递,解决了因网络层数过深导致的梯度消失等问题。同时,改进了传统对抗网络采用二分类判别器作为判别网络,而是选用PatchGAN作为判别器网络,不仅可以加速训练网络,还能提升生成网络对低照度图像的增强效果。最后通过实验,直观地比较了本文方法与其他经典主流方法对低照度图像的增强效果,并且通过对PSNR、SSIM、处理时间三项评价指标的客观比较和分析,最终证明了本文所提出的方法对低照度图像具有更佳的增强能力。如何进一步优化网络结构,降低模型算法复杂度将成为下一步的工作重点。
猜你喜欢
航天返回与遥感(2022年2期)2022-05-12
北京航空航天大学学报(2021年9期)2021-11-02
燃气涡轮试验与研究(2021年6期)2021-08-01
辽东学院学报(自然科学版)(2021年1期)2021-03-12
海洋信息技术与应用(2020年4期)2021-01-18
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年3期)2017-11-23
照明工程学报(2017年3期)2017-07-10
