
多尺度Transformer激光雷达点云3D物体检测
2022-04-21 05:16:54孙刘杰王文举张煜森
计算机工程与应用 2022年8期
孙刘杰,赵 进,王文举,张煜森
上海理工大学 出版印刷与艺术设计学院,上海 200093
近些年来,深度学习技术[1]的发展日新月异,在其飞速发展的同时,也带动如自动驾驶[2]、智能机器人[3]、智能物流[4]等领域的创新进步。尤其是自动驾驶领域由于准确性和实时性要求,准确快速的3D场景感知是重中之重,而3D物体检测[5]对于3D场景感知是至关重要的,但3D物体检测技术受限于数据集、传感器等因素影响,使得此项技术难度大,非常具有挑战性。
由于激光雷达具有精确的长度测量,可提供准确的深度信息,所以激光雷达[6]是自动驾驶最常用的传感器,激光雷达传感器分为二维和三维两种。蔡泽宇等人[7]设计一个具有上下行程的云台,通过二维激光雷达的上下运动,对周围环境物体的轮廓进行检测,达到三维激光的功能。但这样做由于需要上下运动,检测速度相对慢很多。而三维激光雷达扫描周边场景快速生成三维点云,三维点云数据保留了三维空间中原始的几何信息,不进行任何离散化处理,更容易得到物体姿态和形状,因此三维点云是很多3D物体检测[8]任务的首选数据。F-PointNet[9]基于2D RGB图像检测结果,快速定位物体在点云数据中的空间位置,然后利用能够直接从点云数据学习特征的PointNet[10]以及PointNet++[11],回归物体的3D包围盒。Shi等人[12]觉得F-PointNet严重依赖2D检测性能,且存在遮挡问题容易导致漏检,故提出两阶段PointRCNN[12],首次利用点云数据丰富的3D信息,第一阶段基于每个前景点生成一个鲁棒的初始3D包围盒;第二阶段融合深度、坐标、反射强度、局部特征等多种信息优化3D包围盒参数,从而实现3D物体检测。Shi等人[13]认为数据集中标注的3D包围盒隐含了每个三维目标内部分布的点,这有利于学习更多有效信息,有助于提高3D物体检测性能,而之前的方法都忽略这些,故提出Part-A2net[13]在部分感知阶段充分利用数据集标注信息,预测高质量初步3D包围盒和准确的物体内部位置;然后在部分聚合阶段对包围盒重新估计置信度,并通过物体内部部件位置的空间关系来优化包围盒位置。
考虑到点云数据的不规则性和稀疏性,很多研究者[14-16]对点云进行预处理(如将点云去掉高度或深度转换为二维的鸟瞰图或前视图像),然后再利用成熟的图像检测技术得到位置、朝向、类别等2D信息,最后再估计高度、深度信息从而实现三维物体的识别与检测。RT3D[14]将稀疏点云转成稠密的深度图,在深度图中生成初步3D包围盒,进一步从整个点云中提取出感兴趣目标并优化3D包围盒参数,完成3D物体检测;虽然深度图的像素点灰度值反映深度,也可直接反映物体可见表面的几何形状,但存在较为严重的遮挡问题。Range-RCNN[15]为避免尺度变化和遮挡问题,提出RV-PV-BEV(range view to point view to bird eye view)模块,将特征从Range view转移到鸟瞰图。VoxelNet[16]将不规则点云转换规则的体素网格表征,然后使用3D卷积进行3D物体检测。虽然这些方法提高了检测速度,但在数据预处理过程中不可避免地丢失信息从而影响检测精度。
受Transformer[17]在如机器翻译[18]、语音识别[19]等NLP[20]领域成功启发,近期许多研究者将Transformer应用于计算机视觉任务,如2D图像的分类ViT[21],物体检测DETR[22]、ACT[23],分割VisTR[24];3D点云的分类分割PT[25]、PCT[26],3D物体检测Pointformer[27]。得益于其高效的自注意力机制,Transformer在计算机视觉任务各个领域取得种种突破。然而,现有的3D视觉处理方法Transformer由于每层输入嵌入都是等尺度的,没有跨尺度特征,使其不具备在不同尺度的特征之间建立注意能力,这样对于近密远疏的点云数据以及尺寸不同的物体是不合理的。
基于以上分析,本文提出一种基于多尺度点云Transformer的3D物体检测方法(MSPT-RCNN)来提高3D物体检测精度。该框架由两个阶段组成,第一阶段(RPN)为更好学习点云局部几何信息,并在不同尺度信息间建立注意,获得点与点之间的相关性,设计基于坐标的多尺度邻域嵌入模块,该模块首先逐点提取特征,然后使用最远点采样对点云降采样,最后利用欧几里德距离对降采样后的每个点在原始点云中进行KNN[28]搜索,最后计算局部邻域几何特征;跳跃连接偏移注意力模块首先得到不同层次的语义信息,最大平均池化后得到全局语义特征;然后基于采样后的前景点聚合局部邻域几何信息和全局语义特征由近到远生成初始3D包围盒;第二阶段(RCNN)为优化包围盒的位置、尺寸、朝向和置信度,将RPN阶段得到的初始包围盒内的点进行坐标转换,然后通过MLP得到感兴趣区域的局部特征,并将学习到的局部特征结合点云深度信息、反射强度、RPN阶段的单点特征、感兴趣区域内点云的多尺度局部几何信息以及全局语义特征优化3D包围盒的信息。与其他方法相比,此方法充分考虑局部点之间的关联性,并通过注意力机制充分利用有效特征,对较小、较远物体检测效果显著。
1 相关理论基础
1.1 Transformer
由于Transformer在自然语言处理领域的强大表征能力并取得很好的效果,研究人员提出将Transformer扩展到计算机视觉任务。相比于卷积网络、递归网络等网络类型,基于Transformer的模型在各种视觉任务上表现出较强竞争性,甚至拥有更好的性能。
如图1所示,Transformer是一种由编码模块和解码模块组成的深度神经网络,它主要基于自注意力机制,具有几个相同结构的编码器/解码器,每个编码器由自注意力机制和前馈神经网络组成,而每个解码器由自注意力机制、编码解码器注意力和前馈神经网络组成。
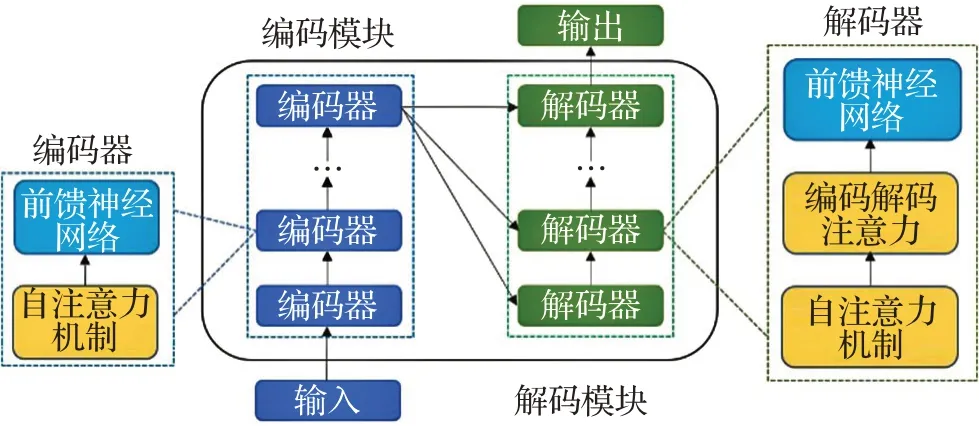
图1 Transformer框架Fig.1 Transformer framework
在编码模块,编码器的自注意力机制首先将输入向量转换成三个不同的向量,即查询向量Q、关键向量K、值向量V,然后由不同输入得到的向量被打包成三个不同的矩阵,之后不同输入向量之间的注意力函数通过以下四步计算:

第一步为了确定对当前位置数据进行编码时对其他位置数据的关注程度,计算两个不同向量之间的分数S。第二步将分数S标准化为Sn,使其具有更稳定的梯度,以便更好地训练。第三步将使用softmax函数将分数Sn转换为概率P。第四步获得权重加权矩阵,每个值向量V乘以概率P,具有较大概率的向量将被随后层更多关注。这个过程可用公式(5)统一表示为:
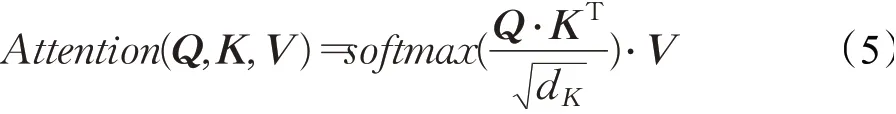
然后将权重加权矩阵输入前馈神经网络(由两个线性层和ReLU激活函数组成,应用于每个编码器和解码器中自注意力层之后),可由公式(6)表示:

其中,W1和W2是两个线性变换层参数矩阵,σ表示ReLU函数,X是注意力层的输入。
解码模块中的编码解码注意力层与编码模块中的自注意力机制几乎相同,只是键矩阵K和值矩阵V是从编码器模块中导出,查询矩阵Q从前一层中导出。
与只关注局部特征的CNN相比,Transformer能够捕捉长距离特征,这意味着Transformer可以轻松导出全局信息。与必须按序列计算隐藏状态的RNN相比,Transformer效率更高,因为自注意力层和全连接层的输出可以并行计算,也更容易加速。
1.2 基于基于点云的3D物体检测
PointNet[10]首创点云学习,PointNet++[11]利用球型对点云数据进行局部分组,再用多层PointNet[10]来捕获局部结构信息。PointRCNN[12]是两阶段3D物体检测方法,以原始点云为输入,利用PointNet++[11]提取点云特征后,对点云特征进行处理,生成多个较为粗糙的初始3D包围盒,最后进行点云区域池化,回归物体准确的3D包围盒和分类置信度。
如图2所示,PointRCNN[12]第一阶段对原始点云数据降采样为16 384个点后,以PointNet++[11]为主干网络提取特征并将点分类(即将点云分割为前景、背景),然后利用点云特征通过PGM(proposal generation module)模块基于每一个前景点自下而上的生成初始3D包围盒和对应的物体分类置信度。
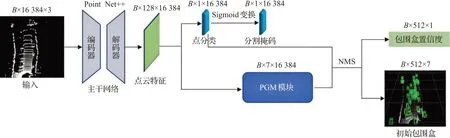
图2 PointRCNN第一阶段网络框架和相应数据流程图Fig.2 PointRCNN stage-1 framework and corresponding data flow chart
如图3所示,PointRCNN[12]第二阶段为了优化第一阶段生成的初始3D包围盒,区域池化点云坐标、深度信息、全局语义特征和前、背景分割信息,结合感兴趣区域(ROI)局部点云特征,通过编码器得到高级语义特征,分别使用分类头和回归头,细化物体包围盒的尺寸、位置、朝向和置信度,并通过NMS(非极大值抑制)使得一个物体最终只保留一个包围盒。
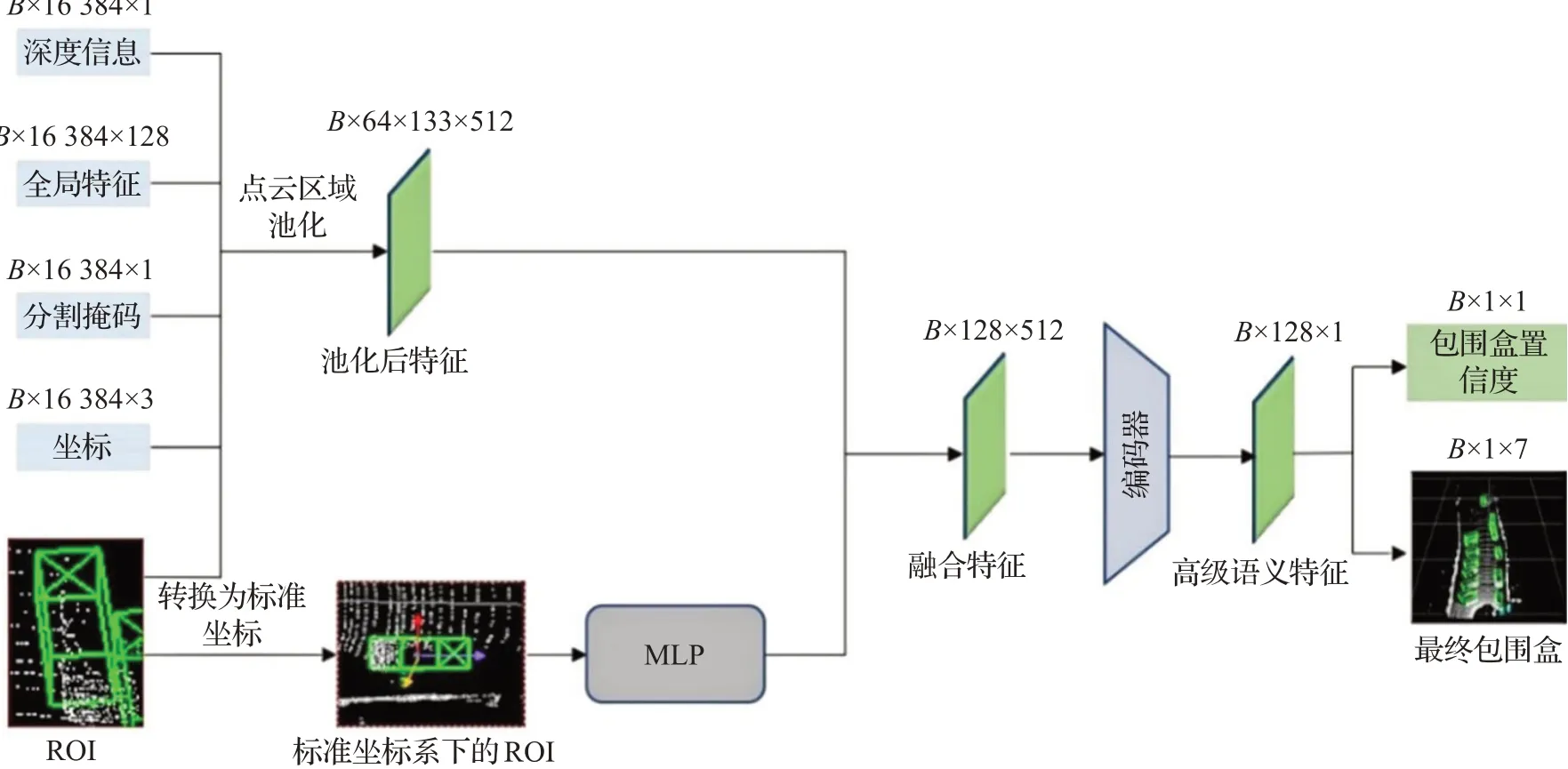
图3 PointRCNN第二阶段网络框架和相应数据流程图Fig.3 PointRCNN stage-2 framework and corresponding data flow chart
2 方法
现有先进的点云3D物体检测方法可以分为一阶段方法和两阶段方法。一阶段的方法通常更快,但直接预测物体的包围盒而不进行细化,精度方面相对会低;而两阶段方法会在第一阶段生成初始包围盒,并在第二阶段进一步优化包围盒和置信度。因此,本文提出了从不规则点云中检测3D物体的两阶段检测方法MSPTRCNN,整体结构框架如图4所示,由第一阶段(RPN)和第二阶段(RCNN)组成。
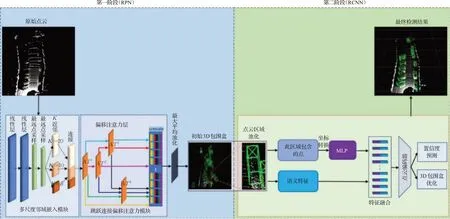
图4 MSPT-RCNN结构框架Fig.4 MSPT-RCNN structure framework
2.1 RPN
RPN主要用来生成候选框;如STD[29]的RPN阶段基于每个点添加一个球形anchor从而生成准确的初始包围盒,但由于大量点云数据为建筑、数目等其他物体,这样会造成大量冗余计算;PointRCNN[12]未使用anchor,基于每一个前景点生成一个初始包围盒,但这样对于一个物体生成的初始包围盒过多,也会造成多余计算;故提出基于采样后点云的前景点由近到远生成初始3D包围盒。
2.1.1多尺度Transformer主干网络
目前大多方法使用PointNet++[11]、DGCNN[30]或者VoxelNet[16]学习点云特征。但Transformer通过注意力机制高效提取有用信息,因此设计一种新型Transformer框架,利用点云坐标作为Transformer顺序嵌入需求,通过多尺度邻域嵌入模块和跳跃连接偏移注意力模块,进行多尺度邻域几何信息和多层次语义信息学习。
(1)邻域嵌入模块
在点云数据中,一个点的语义内容很少。注意力机制虽能有效获取全局语义特征,但是它可能会忽略局部几何信息,这些局部几何信息对于具有几何形状的物体是至关重要的。PointNet++[11]以关键点为球心,提取一定半径范围内点云数据的局部几何信息,但极有可能包含多个物体的点云,导致学习错误的信息;DGCNN[30]使用K近邻搜索可以有效提取物体的几何信息,但不同物体尺寸有所差异,使用固定K近邻搜索不合适。
如图5(a)所示,邻域嵌入模块包括两个LBR(Linear、BatchNorm、ReLU)层和两个SG(sampling and grouping)层。LBR层为单个点嵌入,然后使用两个SG层,每个SG层首先对点云降采样,然后通过K-NN搜索降采样后每个点的邻域几何特征。
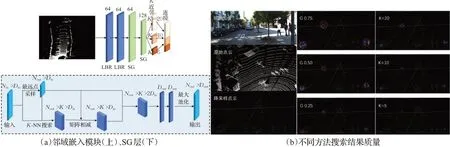
图5 邻域嵌入模块框架和搜索结果质量Fig.5 Neighborhood embedding module framework and search result quality
首先,为将语义相近的点嵌入到空间中更靠近的位置,暂不考虑点与点之间的相关性,使用单点嵌入。具体来说,用共享神经网络将点云数据P的三维坐标(即Dp=3)嵌入到一个De维的空间Fe∈RN×De中,该网络包括两层LBR,每层LBR输出维度为64维。
然后使用两个连接的SG层来逐渐扩大几何特征聚合过程中的感受野,在点云采样期间,SG层利用欧几里德距离进行K-NN搜索,聚合每个点邻域几何特征。具体地说,SG层将具有N个点和相应特征F的点云P作为输入,通过最远点采样(FPS)算法将P下采样到PS,对于每个采样点PS∈P,利用K-NN搜索得到PS在P中的NS个K近邻KNN(p,P),然后计算输出的邻域特征FS(P)。
如图5(b)所示,最左侧一列,自上而下分别是RGB图像、原始点云和降采样后点云,其中RGB图像中的物体在点云数据中的对应位置用方框和箭头显示出来,红色框表示car,黄色框表示cyclist,蓝色框表示pedestrian;中间一列(红色表示采样点PS,蓝色点表示与采样点属于同一物体的点,黄色点表示和采样点不属于同一物体的点)的G0.75、G0.50、G0.25分别表示以采样点为圆心,以半径0.75 m、0.50 m、0.25 m进行球型分组搜索结果的质量图;最右侧一列(红色表示采样点PS,蓝色点表示与采样点属于同一物体的点,黄色点表示和采样点不属于同一物体的点)的K=20、K=10、K=5分别表示以20个、10个、5个邻近点进行K-NN搜索结果的质量图。从图中可以看出,由于球型分组搜索粗糙地处理一定半径范围内的局部点云,忽略了局部点与点之间的几何关系,所以球型分组搜索结果相比于K-NN搜索结果黄色点多很多,这说明球型分组搜索质量比K-NN搜索质量差。然后因为自动驾驶场景中行人、车辆、自行车等物体尺寸存在较大差异,以单尺度K近邻对场景中不同尺寸物体的搜索适应性较差,如K=20对于尺寸较大的车辆物体来说较为合适,但对于自行车或者行人这种尺寸较小的物体,搜索结果存在一定的误差,这样学习到的特征存在一定的误导信息;同理,K=10对于密集行人或扫描点较少的自行车,也不合适;当K=5时,即使对于小尺寸的物体也没有错误的搜索,提供准确的几何信息,但此时的感受野较小,则只能得到较小的局部特征,不利于不同尺寸物体的分类识别。
通过以上分析,本文设计多尺度K近邻搜索,来学习点云数据中不同尺寸物体包含的多尺度几何信息,这样既可以获得不同尺度的局部几何信息,更普适于不同尺度的物体,又可以提供不同大小的感受野,有利于不同尺寸物体的分类识别。具体做法是使用相同的关键点,搜索不同数值的K近邻,最后将不同尺度的邻域几何特征连接起来,得到多尺度几何信息,作为跳跃连接偏移注意力模块的输入。其计算过程可由如下公式表示:
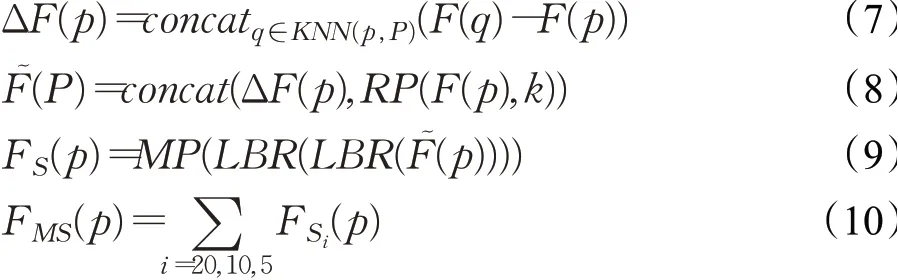
其中,F(P)是点P的输入特征,MP为最大池化,RP(F(P),k)是重复k次向量F(P)形成的矩阵,FS(P)是采样点的单一尺度邻域几何特征,FMS(P)为采样点的多尺度邻域几何特征。
(2)跳跃连接偏移注意力模块
注意力机制[31]是一种计算数据序列中不同项目之间语义相似度的机制。图卷积网络[32]证明了使用拉普拉斯矩阵L(度矩阵与邻接矩阵之间的偏移量,即L=D-E,其中E为图的邻接矩阵,D为图的对角度矩阵,对角度矩阵D是由邻接矩阵E的每一列元素加起来得到N个数,然后把它们放在对角线上,其他地方都是零,组成一个N×N的矩阵)替换邻接矩阵E的巨大优势。从这个方面思考,可以将点云看作一个以“浮动”的邻接矩阵作为注意力特征图的图形,然后将注意力特征图的每一列的和缩放为1,则对角度矩阵为单位矩阵。这样偏移注意力[26]的优化过程可以近似理解为一个拉普拉斯过程。更具体地说:
由多尺度邻域嵌入模块输出的多尺度邻域几何特征FMS(P),作为跳跃连接偏移注意力模块的输入,然后进行线性变换,如下:
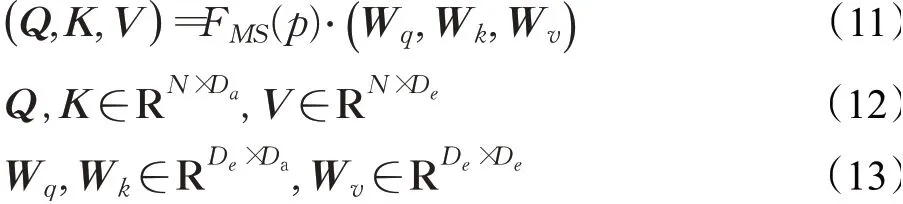
其中,W q、W k和W v是共享可学习线性变换层的权重矩阵,Da是Q和K的维度。为了提高计算效率,将Da设置为De/4。
如图6所示,首先使用Q和K矩阵通过矩阵点乘来计算注意力权重:
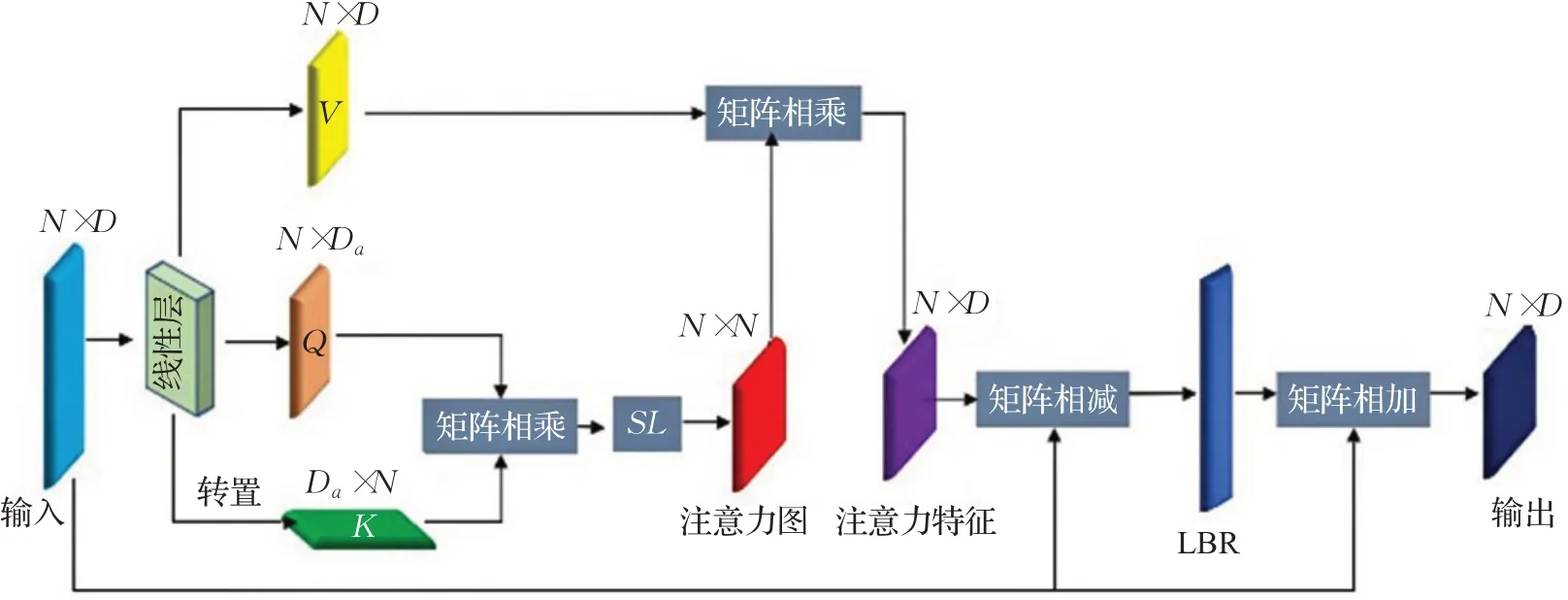
图6 偏移注意力层框架Fig.6 Offset-attention layer framework

然后对这些权重进行归一化(在图6中用SL表示)得到A=(α)i,j,此处在第一个维度上使用softmax算子,在第二个维度上使用L1-norm来规范化注意力图。
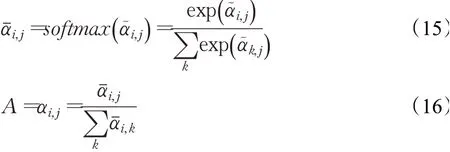
偏移注意层的输出特征Fsa,使用相应的注意权重、值向量计算得到:

最后,自注意特征Fsa和输入特征FMS(P)进一步通过偏移注意层获得输出特征FOA:
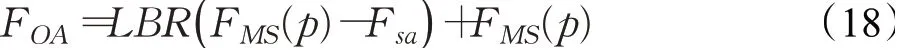
而多尺度邻域几何特征和自注意特征之间的偏移量即FMS(p)-Fsa根据公式(11)~(17)可得公式(19)类似于拉普拉斯矩阵。
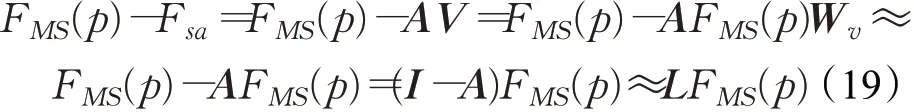
其中,A是注意力矩阵,I是单位矩阵,L是拉普拉斯矩阵。
在公式(19)中,W v因为是线性层的权重矩阵,可以被忽略,每一列的和缩放为1的注意力矩阵A相当于拉普拉斯矩阵L中的邻接矩阵E,而对角度矩阵D由于注意力矩阵A每列和为1等于单位矩阵。这样,偏移注意层对多尺度邻域几何特征和自注意特征之间偏移量的计算过程,可近似理解为拉普拉斯矩阵的计算过程,则偏移注意力的优化过程可以近似理解为一个拉普拉斯过程。
相比于Transformer中的自注意力,偏移注意力的查询向量Q、关键向量K和值向量V矩阵由共享的线性变换矩阵和输入特征F MS(P)确定,与输入的顺序无关。并且softmax和加权和都是与置换无关的算法。因此,整个注意的过程是排列不变的,这使得偏移注意力非常适合于无序不规则点云数据特征的学习。
并且偏移注意力的优化过程可以近似理解为一个拉普拉斯过程,而自注意力的优化过程可以近似理解为邻接矩阵的优化,文献[32]证明了使用拉普拉斯矩阵L替换邻接矩阵E的巨大优势。故本文采用偏移注意力[26]。
如图7所示,跳跃连接偏移注意力模块是由四个偏移注意层构成,AT j分别表示第j个偏移注意层。跳跃连接偏移注意力模块通过以下三步计算最终输出全局语义特征FG:
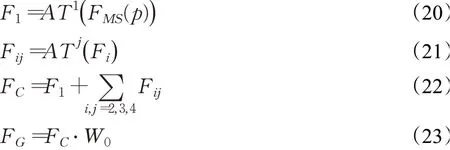
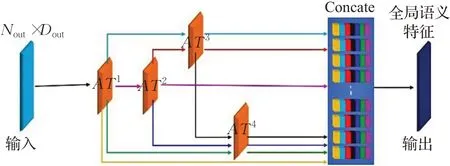
图7 跳跃连接偏移注意力模块框架Fig.7 Jump connection offset-attention module framework
其中,F MS(P)为输入特征,AT j表示第j个偏移注意层,每层都具有与其输入相同的输出维度,F1表示第一偏移注意层的输出,Fi,j表示输入特征Fi经过第j个偏移注意层计算后得到的输出,W0表示线性层的权重。
2.1.2初始3D包围盒生成
为提取一个有效的表示点云全局特征向量,本文选择在输出特征后连接两个池化:在学习到的特征表示上进行最大池化(MP)和平均池化(AP)。然后附加一个包围盒回归头,基于采样后前景点聚合多尺度邻域几何特征,由近到远生成初始3D包围盒。
3D包围盒在Lidar坐标系中表示为(x,y,z,h,w,l,θ),其中(x,y,z)是对象中心位置,(h,w,l)是物体大小,θ是鸟瞰图中物体的朝向。则初始3D包围盒可以表示为:
图8 给出了各个算法的同步误差性能与信标节点和普通接收节点同步过程中消息总数的关系[12].从图中可以看出,对于每种算法,随着消息总数的增加,算法的同步误差都在减小,但是不同算法的误差下降幅度是不一样的.CB-Sync算法在消息总数小于20时,较其他算法有较好的同步性能;在消息总数大于25时,CB-Sync算法与其他算法的同步误差性能接近.换言之,CB-Sync较CCS-Sync,DA-Sync,D-Sync算法可以以更少的能量消耗得到更高的同步精度.

2.2 RCNN
在第一阶段得到物体粗糙的初始3D包围盒后,这样的包围盒尺寸、位置、方向都不够精确,不能准确表示物体的信息,所以本文第二阶段,基于RPN生成的初始3D包围盒,通过更具体的局部特征优化其尺寸、位置和方向。考虑到第一阶段包围盒不够准确,为避免信息遗漏,根据第一阶段的初始3D包围盒的位置,将初始3D包围盒稍稍扩大得到一个新的3D包围盒,然后提取新包围盒内的点以及这些点对应特征,用来优化包围盒。
2.2.1点云区域池化与坐标转换
为尽量避免信息遗漏和利用初始3D包围盒的上下文附加信息,将第一阶段得到的每个初始3D包围盒boxi=(x i,yi,zi,hi,w i,li,θi)稍微扩大得到新的3D包围盒,其中η是包围盒扩大尺寸的一个常数值,设置η=1.0 m。
对于每一个点p=(x(p),y(p),z(p)),通过坐标位置确定点p是否在扩大后新包围盒内,如果在,则这个点以及其特征将被保留用于优化包围盒boxi。与包围盒内点相关特征,包括:点坐标信息F(x,y,z)、逐点特征FP、多尺度邻域几何信息FMS(P)、激光反射强度Fr(p)、点云深度信息Fd(p)和局部空间点特征FP~。其中点坐标信息通过包围盒重心坐标直接影响包围盒的位置信息;逐点特征可以用于前背景点的分割,将不属于物体的背景点剔除,从而通过精确的前景点的特征优化包围盒信息;多尺度邻域几何特征为同一场景中包含的人、自行车、车辆等多种刚性物体提供丰富的几何信息,这有利于细化包围盒边缘;由于不同物体之间材料不同,它们的反射率也截然不同,从而可以通过激光反射反射强度实现不同物体的分类,对包围盒置信度优化有很大帮助。
为利用RPN阶段高召回的初始3D包围盒和能够鲁棒学习包围盒周围的局部空间点的特征,将属于每个包围盒的所有点转换为相应3D包围盒的标准坐标系[12],通过刚性转换,同一物体的绝对坐标虽然完全不同,但相对坐标通常更鲁棒一些。如图8所示,一个3D包围盒的标准坐标系表示:(1)包围盒中心是坐标原点;(2)X0轴和Z0轴平行于地面,X0方向为包围盒朝向,另一个Z0轴垂直于X0;(3)Y0轴垂直于地面。通过适当旋转、平移,将每个包围盒的所有点P坐标转换为标准坐标P~,最后通过MLP学习局部空间点的特征FP~,通过感兴趣区域内的点云数据的坐标转换,可以更鲁棒地提取感兴趣区域空间内点的特征(局部空间点特征),这些特征直接表征该物体的信息,对于单个物体而言,更有利于表示该物体包围盒尺寸、位置以及置信度的优化。
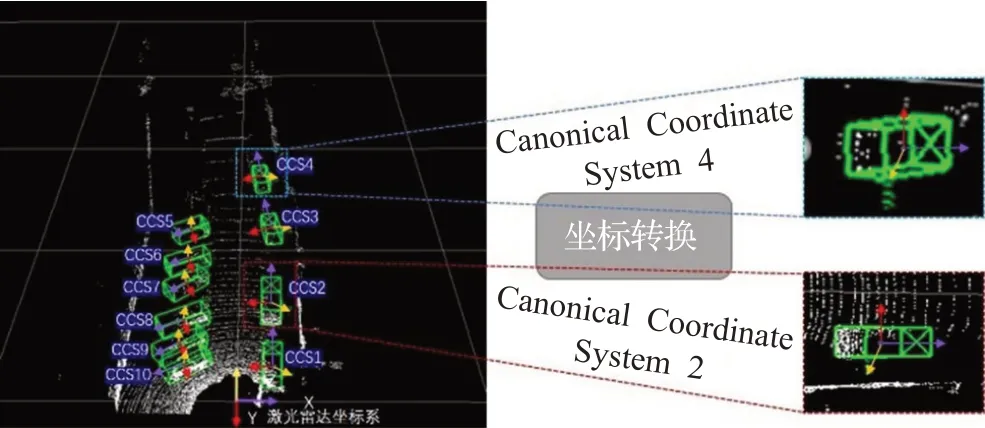
图8 坐标转换(CCS表示标准坐标系)Fig.8 Coordinate transformation(CCS denotes canonical coordinate system)
2.2.2特征融合
RCNN阶段融合新包围盒坐标转换后的局部空间点的特征以及它们的全局语义特征,用于进一步优化初始包围盒和置信度。虽然坐标转换能够实现鲁棒的局部空间特征学习,但同时会完全丢失每个点的深度信息,为此,将激光雷达点的深度信息即在坐标转换后,再引入到点P的特征中去,这样既可鲁棒提取特征,又不会因失去深度信息而影响包围盒尺寸和位置预测。
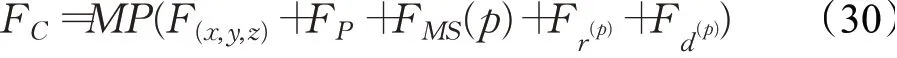
然后输入到几个全连接层,将FC编码到与局部空间点的特征FP~相同的维度。然后,将FC和FP~融合:

最后将FR输入到点云编码器网络,获得一个区分性高级语义特征向量,用于后续的分类置信度预测和包围盒优化。
对于RCNN阶段的分类头,如果带有ground-truth的包围盒最大3D IoU大于0.6,则该包围盒被视为正包围盒;如果包围盒最大3D IoU小于0.45,则该包围盒被视为负包围盒。以3D IoU 0.55作为包围盒回归头训练的最小阈值。最后,利用鸟瞰图阈值为0.01的定向NMS来移除重叠的边界框,只保留一个得分最高的包围盒作为检测对象的三维边界框。
3 实验与结果
本文使用KITTI[33]数据集进行实验。本文提出的MSPT-RCNN在KITTI[33]数据集上与PointRCNN[12]、PointPillar[34]、STD[29]、TANet[35]进行比较。STD[29]对每个点添加一个球形anchor,用每个点的语义得分来移除冗余锚点从而实现高的召回率,然后应将初始包围盒内部的点特征由稀疏表示转化为紧凑表示,在点池化模块结合基于点和体素的方法的优点,实现3D物体的有效预测。之前的研究方法将原始点云栅格化为正方体的体素,PointPillars[34]将原始点云栅格化为长方体的体素,然后学习这些长方体的特征,再将学习到的特征分散回一个二维的伪图像,最后再用检测头利用2D CNN得到的特征预测物体的包围盒和分类。TANet[35]针对行人等较难检测物体的检测精度不高问题提出三重注意力(TA)模块,通过联合考虑channel-wise、point-wise和voxelwise的注意在行人检测上取得很好的效果。
此外,本文还进行了消融实验,选择PointRCNN[12]作为消融实验的基线,以验证所提方法的有效性。
3.1 实验环境
为验证本文提出的MSPT-RCNN在3D物体检测中的有效性,仿真实验在Python3.7、CUDA10.0环境下使用KITTI[29]数据集进行训练和测试,所使用计算机和配置环境的硬件参数为处理器Inter®CoreTMi7-10700K。显卡芯片NVIDIA GeForce RTX 2070 SUPER,显卡芯片内存容量为12 GB。
3.2 实验结果分析
本文选择PointRCNN[12]作为消融研究的基线,为保证对比绝对公平,所有的实验数据和参数设置保持不变。PCT-PointRCNN表示使用PCT[26]提取特征的网络,PCT-RCNN表示在PCT-PointRCNN基础上将特征提取主干网络的偏移注意力模块替换为跳跃连接偏移注意力,MSPT-RCNN表示在PCT-RCNN基础上使用多尺度邻域嵌入模块和RCNN阶段融入感兴趣区域内点的多尺度邻域几何信息。
如表1所示,替换PointRCNN[12]特征提取主干网络后,最终检测精度均有提升,mAP也提升了1.2个百分点。PCT-RCNN通过跳跃连接偏移注意力,获取不同层次有效语义特征,检测结果mAP相对于PCT-PointRCNN提升0.67个百分点。MSPT-RCNN利用两个SG层逐步扩大感受野,通过多尺度邻域嵌入模块,有效学习点云的局部几何信息,检测结果mAP相对于PCT-RCNN提升0.29个百分点,相对于基线PointRCNN[11]提升2.16个百分点,尤其在行人和自行车物体的检测精度提升幅度较大。由于引入Transformer、偏移注意力和多尺度KNN搜索方法,实验证明检测精度提升2.16个百分点的同时,运算成本和测试运行时间逐步有所增加。
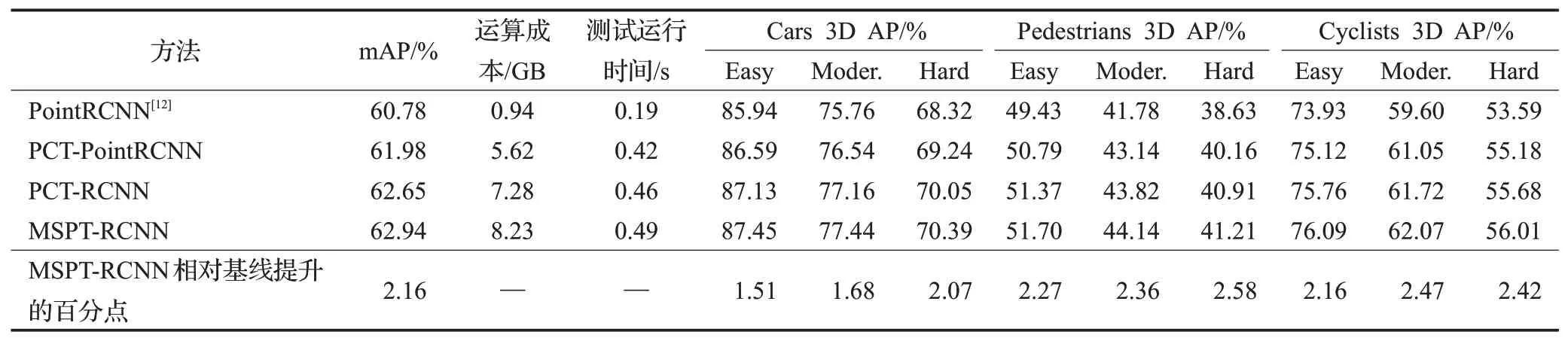
表1 消融实验结果(Cars IoU=0.7 Pedestrians,Cyclists IoU=0.5,batchsize=1)Table 1 Results of ablation experiment(Cars IoU=0.7 Pedestrians,Cyclists IoU=0.5 batchsize=1)
如表2所示(√表示引入该特征,×表示不引入该特征),点坐标信息F(x,y,z)、逐点特征FP、多尺度邻域几何特征F MS(P)、激光反射强度Fr(p)、深度信息Fd(p)、局部空间点特征FP~对最终的检测精度均有提升作用,提升效果如表中mAP精度所示。
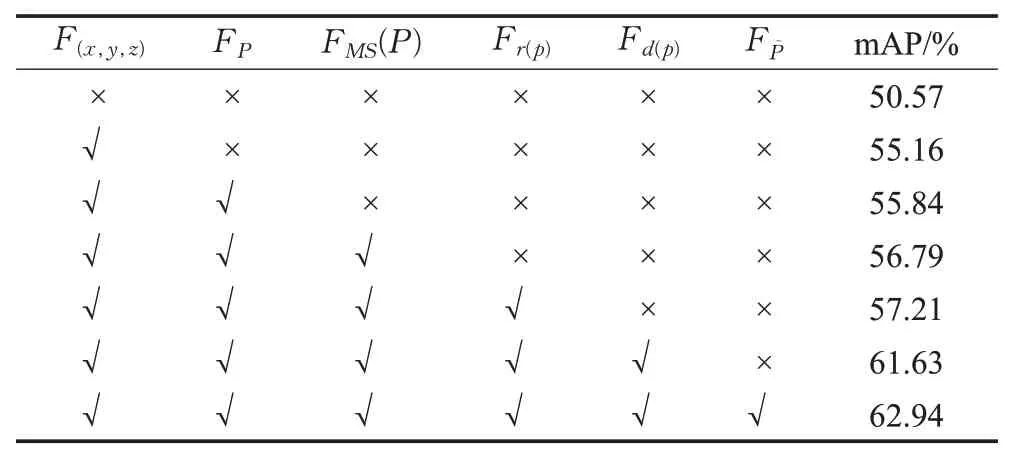
表2 特征多样性作用消融实验Table 2 Characteristic diversity effect ablation experiment
其中点坐标信息和深度信息对包围盒的位置、尺寸直接相关,故提升较大,多尺度邻域几何特征也引入单个物体的几何信息,对检测结果也有不小的提升。
图9为消融实验检测结果可视化图(图中红色方框表示误检漏检物体,并且在图片右上角数字表示误检漏检数量)。由可视化图也可以看出消融实验,误检漏检数量逐次减少,证明本文方法对3D物体检测均有提升效果。
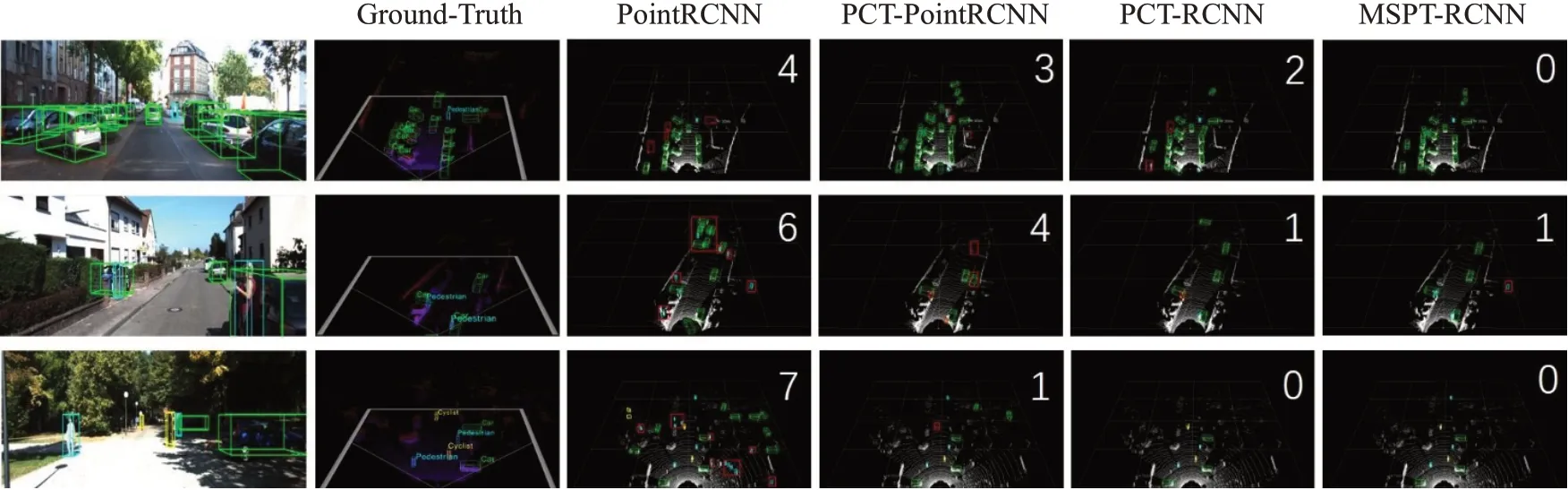
图9 消融实验检测结果可视化Fig.9 Visualization of ablation experiment detection results
3.3 消融实验
在本节中,本文提出的方法MSPT-RCNN与Point-RCNN[12]、PointPillar[34]、STD[29]和TANet[35]四种方法进行了比较。表3显示了不同方法下检测精度的比较(加粗字体表示该列最高精度),图10为不同方法的检测结果可视化图(图中红色方框表示误检漏检物体,并且在图片右上角数字表示误检漏检数量),由可视化图可以看出本文方法误检漏检数最少。
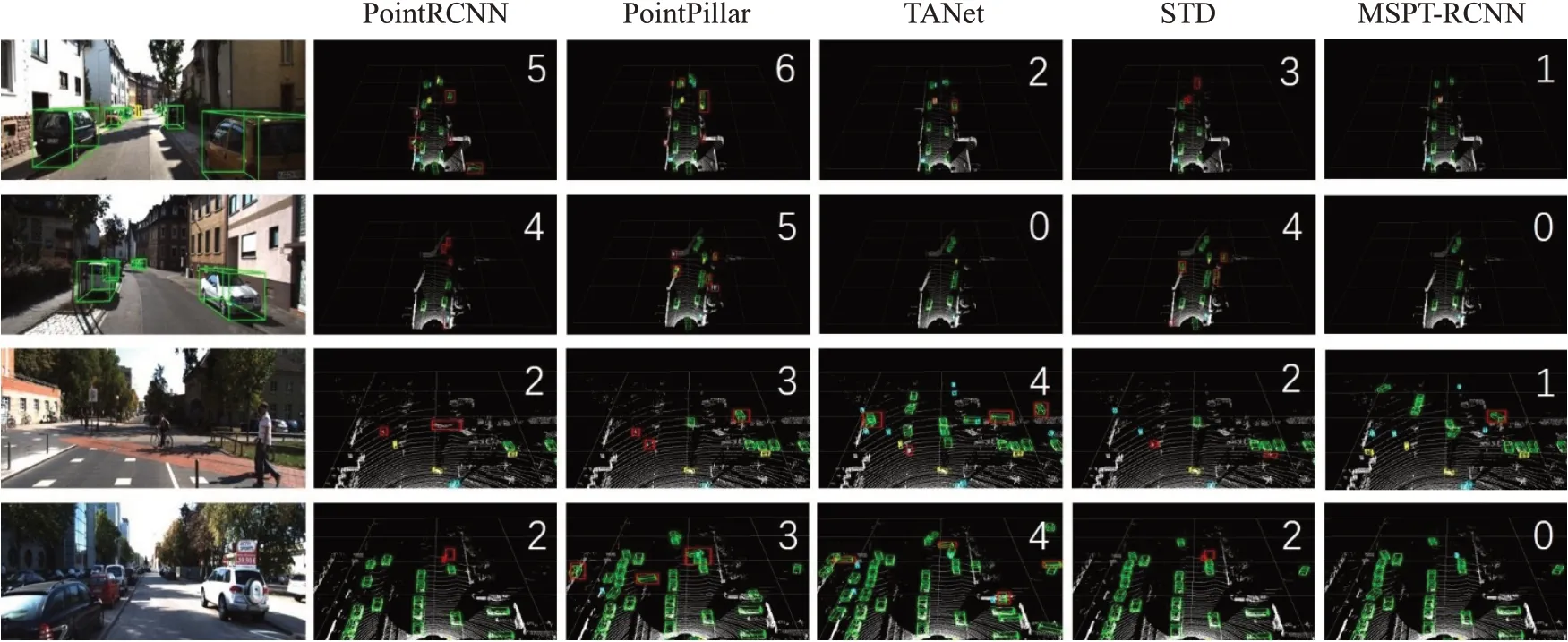
图10 不同方法下的检测结果可视化Fig.10 Visualization of detection results under different methods
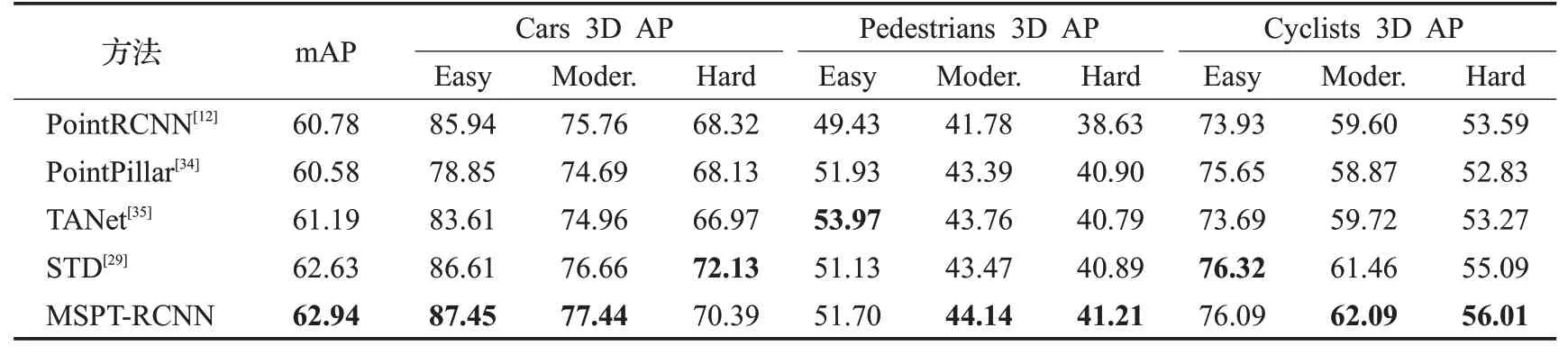
表3 不同方法检测结果(Cars IoU=0.7 Pedestrians,Cyclists IoU=0.5)Table 3 Detection results of different methods(Cars IoU=0.7 Pedestrians,Cyclists IoU=0.5) %
PointRCNN[12]模型mAP精度比本文方法低1.87个百分点,PointRCNN[12]先逐点提取特征,虽使用PointNet++[11]通过球形分组考虑局部特征,但这样的局部特征不够细致,导致小物体检测精度较低。PointPillar[34]将点云转换为稀疏伪图像,利用2D CNN提取伪图像特征。将三维空间数据转为二维图像,大大提高推理速度,但纬度的降低,导致精度普遍偏低。TANet[35]针对较难检测物体(如行人)通过三重注意力模块增强目标的重要信息,提高定位精度,但对于容易检测的车辆效果不够好。STD[29]通过语义信息基于每一个点生成一个人为设置的球形anchor,再通过nms得到少量初始包围盒,接下来是点云池化层采用VFE得到每一个包围盒的特征,最后IoU分支和包围盒预测分支结合优化初始包围盒。但由于激光雷达传感器的固定角度扫描,远处物体的点通常比近处物体少得多,STD[29]针对行人设置半径为1 m的球形anchor,对于较远处的行人,根据少量的点易造成误检漏检。
本文方法MSPT-RCNN通过多尺度邻域嵌入模块,有效学习点云数据中的多尺度几何信息,通过跳跃连接偏移注意力模块,能够提取不同层次的有效信息。实验结果表明,MSPT-RCNN检测精度相较于PointRCNN[12]有较大提升,尤其是较难检测行人方面,提升高达2.58个百分点。相较于PointPillar[34]、STD[29]和TANet[35],本文方法MSPT-RCNN综合指标mAP最高,充分说明本文方法对点云3D物体检测的有效性。
4 结语
本文提出一种基于多尺度点云Transformer的3D物体检测方法(MSPT-RCNN),将Transformer应用于自动驾驶真实场景3D物体检测,以点云为输入,设计多尺度邻域嵌入模块和跳跃连接注意力模块,有效学习点云数据中的多尺度几何信息,提取不同层次的有效语义信息。
实验结果表明,相较于基线方法PointRCNN[12],综合指标mAP提高了2.16个百分点,有效提高了3D物体检测效果,在行人和自行车检测上提升甚至高于2个百分点。相较于其他方法,MSPT-RCNN综合指标mAP最高,充分证明本文方法通过点云数据检测3D物体的有效性,对其他点云3D物体检测也具有一定的研究参考价值。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
自动化学报(2018年7期)2018-08-20 02:59:04
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
周口师范学院学报(2016年5期)2016-10-17 06:36:47
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:48
