
基于SDN网络环境感知的智能路由算法
2022-04-21 05:13赵季红张梦雪乔琳琳张文娟卢立伟
计算机工程与应用 2022年8期
赵季红,张梦雪,乔琳琳,张文娟,卢立伟
1.西安邮电大学 通信与信息工程学院,西安 710121
2.西安交通大学 电子信息工程学院,西安 710049
随着通信网络技术的发展,网络中接入的通信设备越来越多[1-3],因此网络环境信息也越来越丰富和多样,网络环境中包含着大量与用户紧密相关的各种信息,比如包括用户的兴趣爱好、移动属性和身份信息等等[4-6],如何有效地分析并利用这些网络中的环境信息来提高网络的性能,让网络更加智能地服务于人们将会成为网络研究的热点。
研究关于如何提高网络性能的传统软件定义网络(software defined network,SDN)路由算法已有很多[7]。但是面对复杂多样的网络环境,传统的SDN路由算法在提高网络性能的同时并未分析和结合网络中的环境信息,比如文献[8]提出了一种基于遗传算法的自适应SDN路由算法(adaptive SDN routing algorithm based on genetic algorithm,ASRAGA),该算法通过对交叉和编译操作进行条件约束,来降低网络开销和优化网络性能;文献[9]提出了一种基于SDN缓存和流转发算法的端到端的延迟最小化联合规则,制定了一个受流守恒和缓存容量等约束的端到端延迟最小化问题,并用K-最短路径(K-shorted path,KSP)算法、Kuhn-Munkres算法和拉格朗日对偶法依次求解;文献[10]提出一种基于分段路由的SDN路由算法,通过对路径值的综合评价制定策略,用以节省路径代价和缓解网络拥塞;文献[11]提出一种基于优先级的SDN动态多路径(priority-based dynamic multi-path routing,PDMR)路由算法,以此提高资源的利用率和满足严格的QOS要求;文献[12]提出一种遗传蚁群(genetic ant colony,GAC)路由算法,该算法结合了遗传算法和蚁群算法的优点,充分利用正反馈缩短搜索时间从而快速找到最优路径。
关于结合网络环境信息的路由算法的研究也有一些,比如文献[13]中提出了一种SFQ(social features based quota)路由算法,该算法利用节点的社交属性来确定每个节点的配额,在该方法中,与目标节点拥有更多共同属性的节点获得更多的数据复制配额;文献[14]提出一种SSR(social similiry-based routing)算法,节点在缓冲区记录相遇的社会重要性,当两个节点接触时,采用动态扭曲算法来计算两个节点的社会重要序列相似度,最后与目的节点社会重要序列相似度最大的节点作为下一跳中继节点;文献[15]提出一种社区感知转发算法,该算法利用节点在不同周期的接触方式的相似性划分社区,通过训练隐藏半马尔可夫(hidden semi-Markov model,HSMM)来计算节点在社区之间转移概率,并把转移概率最大的节点作为下一跳中继节点;文献[16]提出一种基于用户兴趣选择合作节点的传输机制,在通信过程中,该算法计算节点之间偏好的匹配度,选择匹配度最高的节点作为中继节点传输数据。文献[13-16]中的算法都只考虑了一种网络环境因素,没有考虑更多的网络环境因素,而网络中还有很多其他的环境因素,因此不能够找到更合适的中继节点。合适中继节点的选择在提高数据转发效率和网络性能方面起着至关重要的作用,而且这些算法也没有结合SDN,SDN将转发与控制进行分离,不仅能够动态地掌握全局网络视图,还可以实现逻辑集中式和可编程控制,在网络开发和网络管理方面带来便利[17]。
针对以上情况,提出一种基于SDN网络环境感知的智能路由算法(intelligent routing algorithm for SDN network environment awareness,SNEA-IR)。该算法的主要贡献有:(1)根据人们活动的周期性,在时间上划分周期和时期。(2)融合网络环境中的社交属性因素和移动属性因素来计算节点与目标节点的相遇可能性,并利用BP神经网络根据所得到的相遇可能性预测下一个时期的相遇可能性。(3)通过不断地寻找更合适的中继节点完成寻路过程。(4)最后通过仿真结果验证所提算法能有效提高数据传输率,减少延迟和传输跳数。
1 系统模型
如图1描述了载体节点下一跳中继节点的选择以及这两个节点之间数据的发送过程。本文的应用场景是在一个城市中,节点是携带移动设备的人。定义城市中每个区都部署有一个SDN控制器,每个SDN控制器内都部署有SNEA-IR算法和BP神经网络。根据节点活动的周期性,在时间上划分周期和时期,每个时期又分为状态收集阶段、状态发送阶段和数据发送阶段。
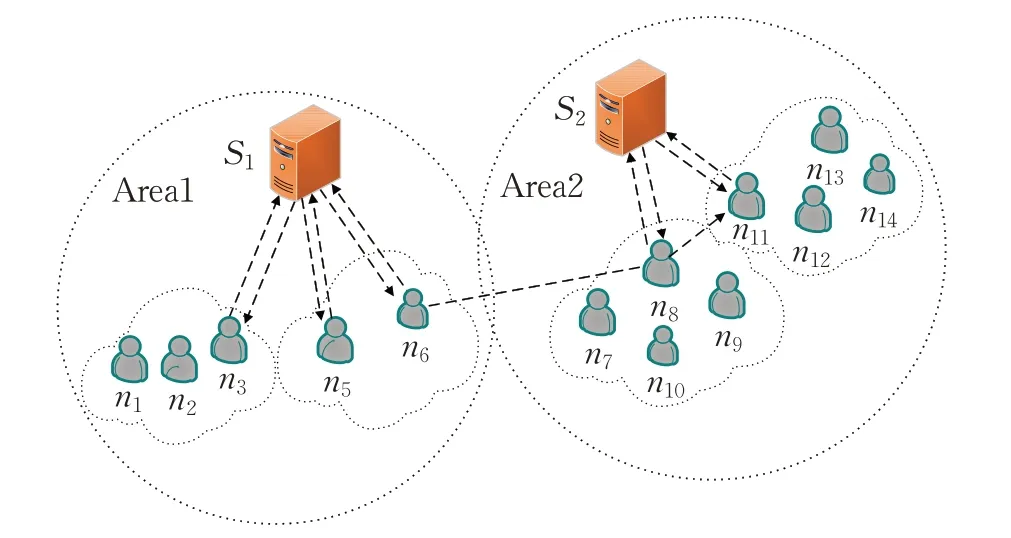
图1 系统模型Fig.1 System model
中继节点的选择以及载体节点与中继节点之间数据的发送具体过程如下:在状态收集阶段,载体节点通过相遇收集其他节点的状态信息,在这里假设源节点了解目标节点的状态信息。在状态发送阶段,载体节点把收集到的状态信息和目标节点的状态信息发送给SDN控制器,SDN控制器计算节点与目标节点之间当前时期的相遇可能性,然后利用BP神经网络根据节点与目标节点的以往周期和当前时期的相遇可能性预测下一时期的相遇可能性,SDN控制器选择出与目标节点下一时期相遇可能性最大的节点作为载体节点的中继节点,并将中继节点的ID发送给载体节点。在数据发送阶段,载体节点根据中继节点ID将数据和目标节点的状态信息发送给中继节点。
每个中继节点都重复这三个阶段直到将数据发送给目标节点为止。
1.1 周期和时期的划分
在日常生活中,人们的活动具有周期性的趋势,在节点的移动中,把每一周作为一个周期(历史参数),把每一周划分为很多时期(当前参数)。周期和时期划分模型如图2所示,假定是节点与目标节点当前的相遇可能性,那么是节点与目标节点的历史相遇可能性是节点与目标节点的下一时期的相遇可能性。
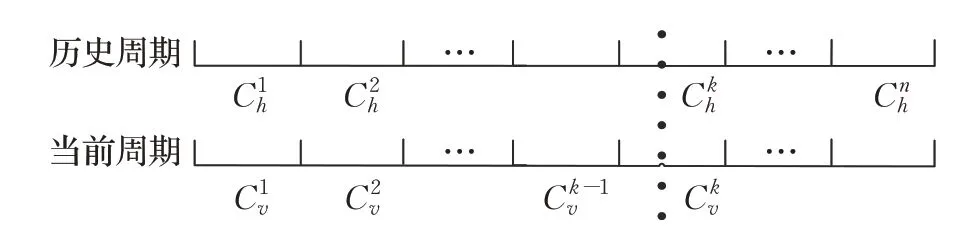
图2 周期和时期划分Fig.2 Periods division
1.2 状态表的建立和收集
定义每个节点都有一个状态表,里面包含自己的社交属性信息和移动属性信息。用Statez=(Md z,αz,Listz)表示载体节点z的状态表,Md z代表z的移动属性信息,αz里面包含z的社交属性特征向量,Listz是z与其他节点相遇建立的状态序列,当z与其他节点相遇时,就会把与之相遇的节点的状态表添加到自己的Listz里面。Listz表示如下:
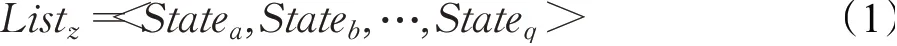
Statea、Stateb、Stateq分别表示与n1相遇的节点a、节点b和节点q的状态表。αz=(A z,B z,…,Y z),其中A z,B z,…,Y z分别代表z不同属性的特征子向量,例如A z=(a1,a2,a3,a4)是兴趣子向量,a1、a2、a3、a4代表不同的兴趣可以分别表示为篮球、看电影、学习和听音乐。如果z的兴趣只喜欢打篮球那么A z=(1,0,0,0)。
1.3 社交属性相似度的计算
节点z和目标节点d之间的兴趣子向量的相似度可以表示为:
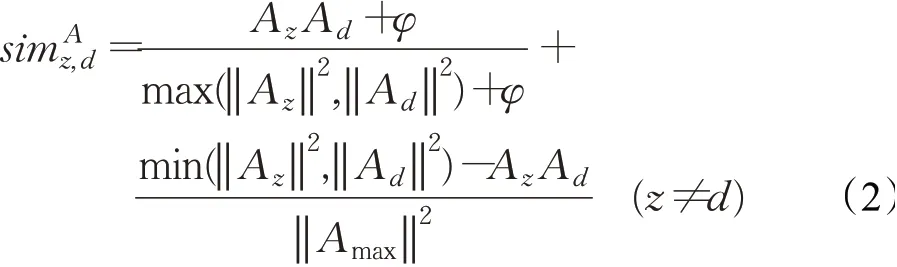
z和d之间的社交属性相似度可以表示为:
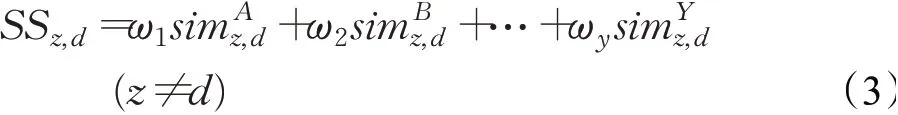
ω1,ω2,…,ωy是z和d的不同属性子向量的权重值,利用改进的熵值评价方法计算节点之间不同子向量的权重值,给出权重矩阵G如下:
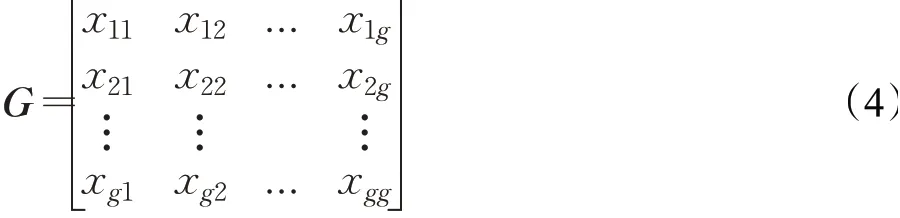
其中,x ij表示第i个节点的第j个子向量,即节点i的第j个社交属性值,将节点i的第j个社交属性的贡献值可以量化为:

定义Qj为所有节点第j个属性值的总贡献值,所有节点的第j个社交属性的总贡献值可以量化为:

Qj的取值范围为[0,1]。当所有节点第j个社交属性的贡献值趋于相等时,Qj等于1。
因此可以利用贡献值的差异来确定社交属性子向量的权值,定义ci为每个节点第j个社交属性的贡献一致性程度,即ci=1-Qj。
因此可以根据对应的贡献水平来确定子向量的权重,第j个社交属性子向量相似度的权值ωj可以表示为:

调整后的权重值可以表示为:

1.4 移动属性相似度的计算
通常情况下,两个节点的移动属性越相似,这两个节点之间相遇的可能性就越高,成功转发消息的概率也就越高。根据这一理论,所提算法可以将节点的移动属性用时间点和通信区域的位置(t1,l1),(t2,l2),…,(tu,lu)来表示,其中t为时间点,l为通信域。
定义u表示节点z与其他节点之间信息传输的次数,用CL(z,R)来表示节点z的移动属性,那么CL(z,R)可以用下面公式来表示:
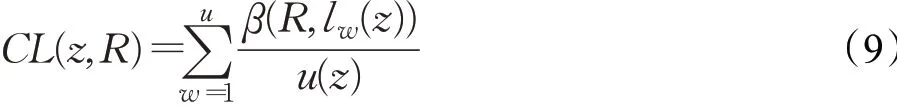
其中,R为移动社交网络中通信区域的位置集,这就意味着,只有当节点z与通信区域R中的其他节点相接触时,β(R,lw(z))的值为1。节点z和节点d之间的移动相似度可以表示为:
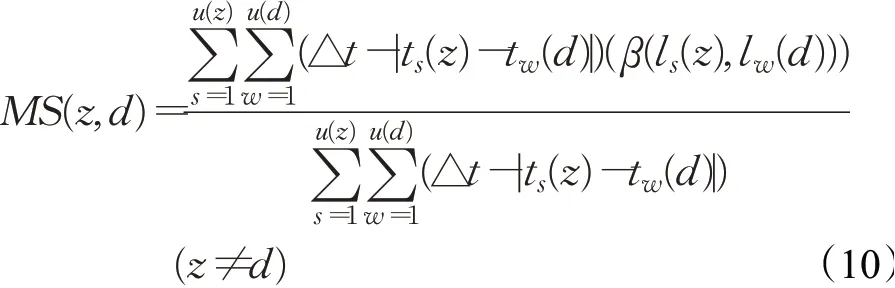
考虑到时间因素,定义△t为时间精度,它反映了同一时间内同一地理位置所有节点所占的比例。
定义SRz,d为节点z和目标节点d之间的相遇可能性,SRz,d的表示如下:
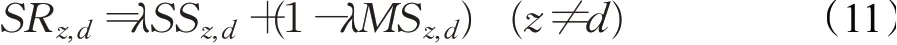
1.5 BP神经网络预测模型
如图3是BP神经网络预测模型,将BP神经网络部署在SDN控制器中,该BP神经网络的当前输入为节点与目标节点的当前时期的相遇可能性SRv,历史输入为节点与目标节点的历史相遇可能性SRh,输出为预测的节点与目标节点下一时期的相遇可能性SRp。
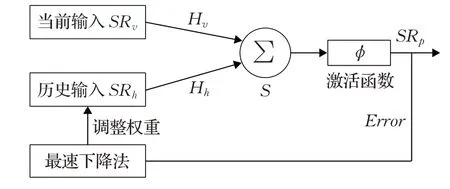
图3 BP神经网络预测模型Fig.3 BP neural network prediction model
H v和H h分别为当前输入和历史输入的权重。
φ是激活函数,S是求和函数,S可以表示为:

SRp可以表示为:
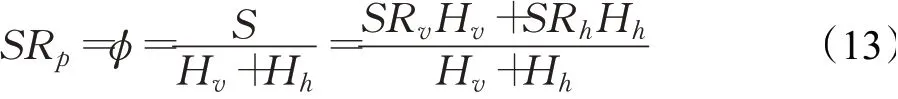
Error是该BP神经网络预测模型的最小误差值,该BP神经网络预测模型采用最速下降法来求Error,Error可以表示为:
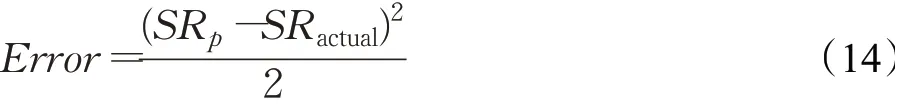
其中SRatual是节点与目标节点实际的相遇可能性。
2 路由算法设计
本章主要描述了路由算法的设计过程。该算法数据转发的关键在于在与载体节点相遇的节点集中找到最合适的中继节点,合适的中继节点的选择不仅可以提高数据转发的效率还可以提高整个网络的性能。在前面分析中,提出了一种基于SDN网络环境感知的智能路由算法(SNEA-IR),整个路由策略如算法1所示。
算法1 SNEA-IR路由策略

SDN控制器内部署BP神经网络,并且定义在SDN控制器中有一个SAT表用于存放节点与目标节点当前时期的相遇可能性。在SDN控制器中计算节点与目标节点当前时期的相遇可能性,并利用BP神经网络对节点与目标节点下一时期的相遇可能性进行预测,然后选出下一时期与目标节点相遇可能性最大的节点作为下一跳中继节点,具体过程如子算法1所示。
子算法1中继节点的选择

在BP神经网络中,使用最速下降法,通过反向传播不断逐层地调整权值和阈值,使得网络的误差平方和最小。BP神经网络中节点与目标节点下一时期相遇可能性的预测如子算法2所示。
子算法2相遇可能性的预测

3 仿真与性能分析
3.1 实验环境配置
本实验使用IGEN[18]工具生成物理网络拓扑,并通过Matlab进行仿真分析,在仿真过程中,源节点随机生成数据包,并随机选择其目的节点,具体参数如表1所示。在实验中,为了使模拟更加接近于人们的真实运动轨迹以及运动轨迹范围内人们的聚集密度,设置通信区域的面积大小为3 000 m×3 000 m,并划分为9个面积相等的区域,每个区域的面积为1 000 m×1 000 m,设置整个通信区域中总体模拟节点数量为600个。把每一周按小时划分为168个时期,在仿真实验中,状态收集时长太短会影响载体节点寻找合适中继节点的精准性,状态收集时间太长则会增加整个数据发送过程的时延,只有当状态收集时长为35 min时,数据的传输效率最高,因此将状态收集时长设置为35 min。根据多次的仿真经验,设置状态发送阶段时长范围为0~15 min,数据发送阶段的时长范围为0~10 min,总的模拟时间为15 d。结合现实生活中人和车辆的正常移动速度,设置每个节点的移动速度为1~6 m/s。选取节点最重要的5个社交属性特征作为节点的社交属性子向量,这5个子向量分别是身份、家庭住址、工作地址、兴趣和每个节点自身特征,每个社交属性子向量里面包括4个特征关键词。由于节点的活动具有周期性,节点之间下一时期的相遇可能性与它们的历史相遇可能性具有更强的相关性,因此在BP神经网络中设置历史相遇可能性的权重值为0.6,当前相遇可能性的权重值为0.4。经过多次迭代,当学习率为0.3时BP神经网络的训练达到最优,所以将学习率设置为0.3。结合通信区域的总体模拟节点数量和实验时间,每个载体节点在实验时间范围内可能遇到的其他节点的数量在0~600个,因此设置每个载体节点的训练样本为0~600个,根据移动设备在无线网络和非无线网络下实际的数据平均发送速率,将数据源的数据发送速率设置为6 Mbit/s。
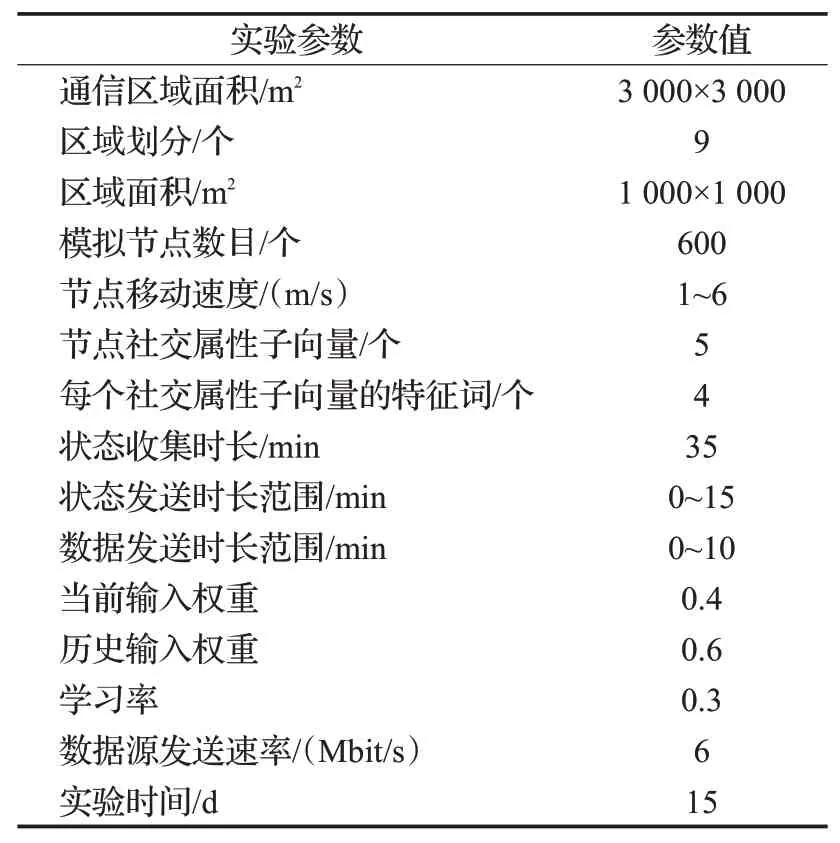
表1 实验配置参数Table 1 Experimental configuration parameters
3.2 性能分析
本节将所提算法SNEA-IR与SFQ[13]算法和SSR[14]算法进行了对比,SFQ算法利用节点的社交属性来确定每个节点的配额,在该算法中与目标节点拥有更多公共属性的节点获得更多的数据复制配额。在SSR算法中节点在缓冲区记录相遇的社会重要性,当两个节点接触时,采用动态扭曲算法来计算两个节点的社会重要序列相似度。最后将数据包转发到与目的节点社会行为最相似的中继节点。本节从数据传输率、数据传输跳数和数据传输时延三个方面来评估算法的性能,并验证所提算法的有效性。
(1)数据传输速率变化比较
图4是数据传输速率的比较,从图中可以看出在第1天三个算法的数据传输率相差不大,随着时间的增加,三种算法的传输率都有所增加,但最终都趋于稳定。在第15天,SNEA-IR算法的数据传输率达到73%,SSR算法55%,SFQ算法33%。SNEA-IR算法的数据传输率要远高于其他两种算法是因为SNEA-IR算法根据节点与目标节点以往周期和当前时期的相遇可能性来预测下一时期的相遇可能性,提高了中继节点寻找的精准性,并且随着时间的增加,载体节点接触到的其他节点越来越多,BP神经网络的训练样本也越来越多,BP神经网络预测结果与实际结果的误差会降低到一定的范围,端到端之间的数据传输就会更加高效和稳定。
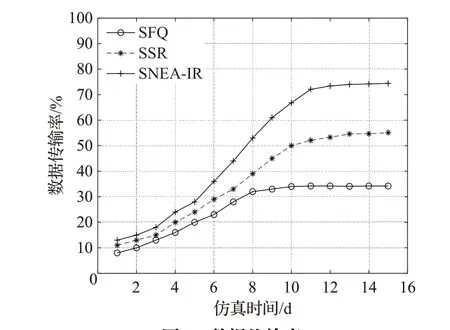
图4 数据传输率Fig.4 Data transfer rate
(2)数据传输跳数比较
图5是三种算法数据传输跳数的比较,从图中可以看出,SNEA-IR算法在刚开始时数据传输跳数低于SFQ算法和SSR算法,随着时间的推移,SNEA-IR算法数据传输跳数的增长速率也远远低于SFQ和SSR两种算法。在实验结束时,SNEA-IR算法的传输跳数比SFQ算法少26跳,比SSR算法少18跳。因为在节点相似度的计算上SFQ算法和SSR算法只考虑了单一的网络环境因素,而SNEA-IR算法考虑了社交属性因素和移动属性两种网络环境因素。因此SFQ算法和SSR算法相比SNEA-IR算法不能找到更合适的下一跳中继节点,所以它们的传输跳数较多。
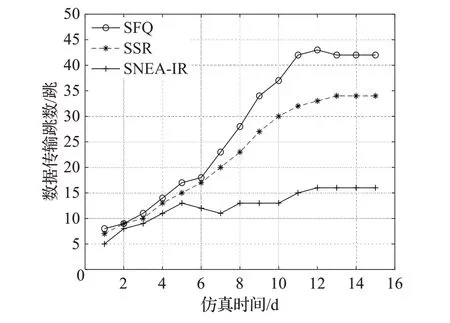
图5 数据传输跳数Fig.5 Number of data transfer hops
(3)传输时延变化比较
图6说明了这三种算法的传输时延,三种算法的传输时延都随着仿真时间的增加逐渐降低,并最终趋于稳定。在实验结束时,SNEA-IR算法的时延比SFQ算法低332 s,比SSR算法低251 s。由于SFQ算法和SSR算法相比于SNEA-IR算法在传输跳数上更多,所以它们的传输时延也更大。
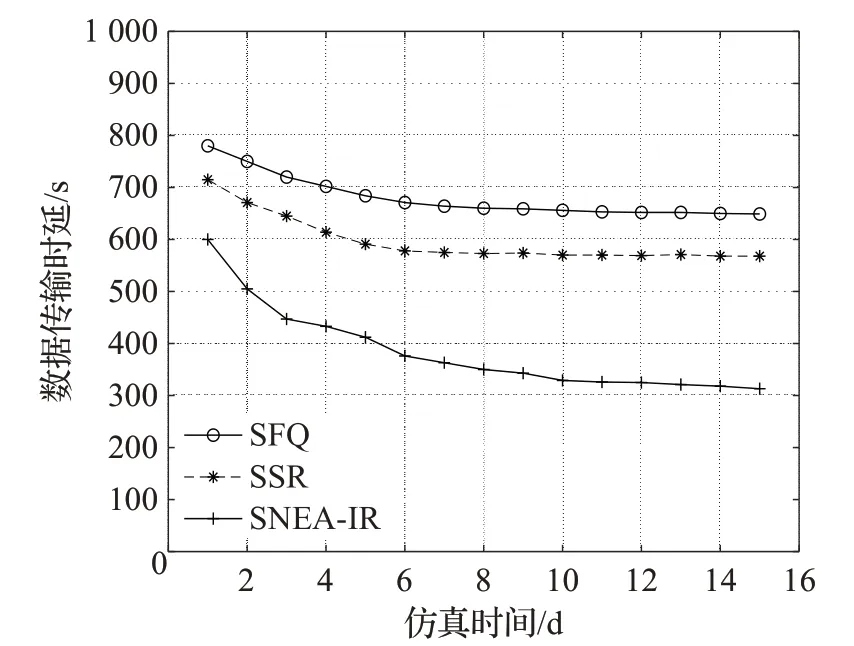
图6 传输时延Fig.6 Transmission delay
4 结束语
本文提出了一种基于SDN网络环境感知的智能路由算法,该算法相比传统SDN路由算法融合网络环境中节点的社交属性和移动属性两种因素,并且该算法考虑了节点与目标节点的以往周期和当前时期的两种相遇可能性与节点未来时期相遇可能性之间关联,并进行了预测。该算法与文中所提其他结合网络环境因素的路由算法相比该算法能够找到更加合适的中继节点,并且提高了数据传输率,降低了端到端时延和传输跳数。该算法在考虑网络环境中的因素时考虑了社交属性和移动属性两个因素,而网络环境中还有其他因素,下一步工作是继续寻找并添加其他网络环境因素来进一步优化算法,使算法性能再有所提升。
猜你喜欢
现代电力(2022年2期)2022-05-23
铁道通信信号(2020年9期)2020-02-06
无线电通信技术(2019年1期)2019-12-24
电子制作(2019年19期)2019-11-23
太原科技大学学报(2019年6期)2019-11-18
太原学院学报(自然科学版)(2019年3期)2019-09-23
太原科技大学学报(2019年3期)2019-08-05
电子制作(2019年24期)2019-02-23
科技与创新(2018年1期)2018-12-23
中国科技纵横(2016年14期)2016-10-10
