
基于Reformer模型的文本情感分析
2022-04-21 07:24黄海燕乔伟涛
计算机工程与设计 2022年4期
王 珊,黄海燕,乔伟涛
(华东理工大学 信息科学与工程学院,上海 200237)
0 引 言
传统的文本情感分析[1]大多采用机器学习和情感词典的方法。随着深度学习的不断发展,越来越多深度学习技术被用于情感分析任务中,目前,已经提出卷积神经网络(convolutional neural networks,CNN)、长短时记忆法(long short-term memory,LSTM)、双向长短时记忆法(bi-directional LSTM,Bi-LSTM)等多种神经网络模型及改进方法来解决此类问题[2-5]。但这些方法还存在着训练时间长、复杂度大的问题。在已有工作的基础上,本文提出了基于Reformer模型的文本情感分析方法,该模型在Transformer模型的基础上,引入局部敏感哈希注意力和可逆残差网络,既能克服传统CNN、RNN网络梯度爆炸或梯度消失的问题,同时简化了情感分析模型结构,提高了文本训练的速度。
1 相关工作
近年来,互联网+的快速发展使评论文本情感分析在基于用户的大数据分析中占有一定的比重,相对于传统机器学习方法的不灵活性等特点,深度学习的方法可以更加高效、准确地判断文本所蕴含的情感信息,因此通过深度学习的方法获取文本情感信息是目前较为热门的一个研究领域,并取得了良好的研究成功。例如,曹宇等利用Word2vec对文本进行向量化处理,然后利用双向门控循环单元进行训练并取得了较好的效果[6]。殷昊等利用多组LSTM对经过欠采样处理的多组数据分别进行训练,最后将各组训练结果融合进行文本情感分析,很好实现了不均衡数据集的情感分析[7]。王丽亚等利用CNN网络和CNN-BGRU网络针对字符级文本分别进行特征学习,最后引入Attention机制(注意力机制)对文本情感进行分类[8]。
利用CNN和RNN以及两者结合进行文本情感分析已经取得了良好的效果,但仍存在一定的问题,利用使用RNN进行文本情感分析存在长期依赖的问题并且难以并行计算,CNN则不能直接处理序列较长的文本样本。因此谷歌团队抛弃了具有解码-编码(encoder-decoder)结构的神经网络模型必须结合CNN或RNN的固有概念,将输入序列中任意两个词语之间的距离缩小为常量,提出了完全由注意力机制构成的Transformer模型[9],并在自然语言处理领域得到了广泛利用并取得了较好成绩。例如,陈珂等利用Transformer模型对文本进行训练得到文本语义、位置特征,然后根据情感词典提取包含文本情感特征的词语并利用自注意力机制进行训练获得文本情感特征,最后将两种不同训练方法得到的文本特征进行融合并进行情感分类[10]。王明申等利用词级权重模型获得不同词语的权重,然后将得到的权重与 Transformer 模型相结合进行文本情感分析[11]。尽管利用Transformer模型进行文本情感分析已经取得了较好的成绩,但Transformer模型仍存在复杂度高、训练时间长的问题。因此,优化Transformer模型结构,降低模型复杂度,对提高文本情感分析准确率,加快训练时间具有重要意义。
2 Reformer模型
Reformer模型是Nikita Kitaev等在Transformer模型的基础上提出的一种变体,它克服了Transformer模型处理长文本时占用内存大,训练速度慢的问题[12]。同Transformer模型结构类似,Reformer模型也采用由注意力机制和前馈网络组成Encoder-Decoder(解码-编码)结构,其总体结构如图1所示。与Transformer模型相比Reformer模型主要进行了3点改变:局部敏感哈希注意力机制(locality sensitive hashing attention,LSH Attention)取代点乘注意力(dot-product attention),可逆残差(reversible residual layers)代替标准残差(standard residuals)以及采用分块的前馈网络[12]。

图1 Reformer模型结构
2.1 局部敏感哈希注意力机制
注意力机制是文本情感分析中常用的一种方法,它可以根据不同词语所在的位置赋予其不同权重,从而更好实现分类效果。传统Transformer模型中主要采用放缩点积注意力机制[9]。对于放缩点积注意力机制,其表达式为
(1)
其中,Q(query)是向量化的输入文本,K(key)和V(value)则是输入文本中单个词语的词向量。通过式(1)可以看出,当输入文本的长度为L时,放缩点积注意力机制的复杂度为Ο(L2)。为了降低注意力机制的复杂度,Reformer模型引入局部敏感哈希算法,舍弃Q值并将注意力权重替换为K的函数,构建了局部敏感哈希注意力机制。
局部敏感哈希(locality sensitive hashing,LSH)是Indyk提出的一种改进哈希算法,其主要思想是,设计一种哈希函数对高维空间中任意两点进行计算,当两点间隔很近时,则这两个点大概率有相同的哈希值,反之,当两点间隔很远时,它们哈希值相同的概率会很小[13]。根据两点之间相似度计算方式的不同,LSH算法有许多不同的hash算法。在Reformer模型中,采用的hash算法是基于向量之间夹角计算相似度的随机投影法[14]。该方法首先将向量投影到一个单位球的球面上,然后应用一系列的旋转操作,最后找到每个旋转向量所属的切片。这样一来就需要找到最近邻的值,这就需要局部敏感哈希,它能够快速在高维空间中找到最近邻的点。假设空间中存在3个点A,B,C,其中A,B两点距离很近,A,B与C距离很远,则这3个点投影到一个单位圆上,并随机旋转3次,其变换过程如图2所示,其中旋转正角度时为逆时针,反之为顺时针。
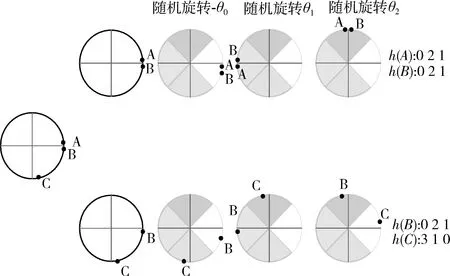
图2 哈希变换过程
因此,在注意力机制中引入局部敏感哈希后,LSH Attention的计算过程如图3所示。

图3 LSH Attention工作流程
如图3所示,局部敏感哈希注意力机制的工作流程为:
(1)对输入序列进行处理,令Q=K;
(2)利用哈希函数,将Q和K中的序列分为不同的哈希桶(图3中,不同背景表示不同的哈希桶);
(3)根据哈希桶的不同对序列进行重新排序,同个哈希桶中,按照原本位置进行排序;
(4)对步骤(3)得到的新序列,进行分块;
(5)对分块后序列进行并行化处理,利用注意力机制对每个qi(qi∈Q)对同一哈希桶中当前位置及之前位置序列进行训练。
2.2 可逆残差网络
虽然在注意力机制中引入局部敏感哈希算法解决了Transformer模型复杂度高的问题,但模型仍然存在内存占用大的问题。将Transformer模型的内部进行展开,其结构如图4所示。通过图4可以看出,Transformer模型的每个注意力层和前馈层都被包装成一个残差块的形式,因此,在模型训练过程中,需要存储每一层激活函数的输入来计算反向传播期间的梯度,导致大量的内存消耗。因此,在Reformer模型中,采用可逆残差网络对反向传播中激活函数的输入重新计算,从而减少内存的占用。以编码器为例,引入可逆残差网络后,其结构如图5所示。

图4 Transformer模型内部结构

图5 Reformer模型解码器内部结构
假设注意力机制和前馈网络分别用Att,FFN表示,则通过图5可以看出,正向传播时
y1=x1+Att(x2)
y2=x2+FFN(y1)
(2)
反向传播时
x1=y1-Att(x2)
x2=y2-FFN(y1)
(3)
因此,引入可逆残差网络后,训练过程中只需要在第一层编码器或解码器存储激活一次,极大节约了内存的占用。
2.3 前馈网络分块化
对于前馈神经网络,当其隐含层非常大时,其内存占用也是非常大的。但是在Transformer模型中,由于前馈网络的输入是独立的,因此,可以对其进行分块划分,每次只对一个模块进行计算,从而极大降低了内存的使用,其计算公式如下所示
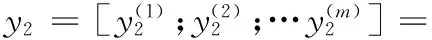
(4)
其中,m为分的块数。
3 基于Reformer模型的文本情感分析模型
本文提出的基于Reformer的情感分析模型如图6所示,主要包括文本预处理、文本词向量转化及分类3个部分,其中v1v2v3v4…vn为文本预处理后得到的词语,w1w2w3w4…wn为文本向量化后得到的词语向量,n为词语个数。当评论文本输入时,首先通过文本预处理层对输入数据进行分词、去停用词,再利用文本词向量转化层将输入文本映射成对应的词向量,得到W=[w1,w2,…,wn]T,其中wn为文本中第n个词语的词向量,然后经过Reformer模型的编码层,获得文本的情感特征,最后将获得的文本情感特征输入全连接层进行文本情感倾向计算。

图6 基于Reformer模型的文本情感分析模型
Reformer模型完全继承了Transformer 模型可以充分提取文本语义特征的能力,同时通过引入局部敏感哈希注意力机制,可逆残差等改进办法,使模型可以更快处理长文本,提高了文本情感分析的效率。
3.1 文本预处理
分词是中文文本处理的一个必要步骤,与英文文本不同,中文的字与字之间不存在空格符进行分割,因此需要预先进行文本分词处理。本文主要采用分词工具jieba来实现文本中词语的划分。除分词外,去停用词也是中文文本预处理必不可少的步骤。在文本中,经常存在一些对其所蕴含的情感倾向不存在影响的词语或字,这些字或词即被称为停用词,因为这些词和字不会对情感分析产生影响,因此在信息检索中,为节省存储空间和提高搜索效率,在处理文本数据过程中会自动过滤掉这些停用词。本文在去停用词过程中采用的是自然语言处理领域常用的“哈工大停用词表”。
3.2 文本词向量转化
由于机器不能直接识别纯文本输入,需要对文本进行向量化操作,将文本转化为机器可以识别的数值形式。因此,本文采用Word2Vec的CBOW模型将文本预处理后得到的单词转化为向量形式,假设词向量维度设置为j,则单词vi经过训练后,得到词向量
wi=[wi1,wi2,wi3…wij]
(5)
假设输入文本S经过文本预处理后长度为n,则该文本向量化后可以表示为,W∈Rn×j,其中W=[w1,w2,…,wn]T。
3.3 分 类
在Reformer模型中,解码器是生成式模型,主要用于自然语言的生成,因此,在本文中情感分析任务中,仅采用编码器结构。在Reformer模型的Encoder模型中,注意力机制采用由多个局部敏感哈希注意力机制组成的多头注意力(multi-head attention layer),当输入为x时,多头注意力层通过h个不同的线性变换输入进行投影,最后将不同的注意力机制结果拼接起来,因此,当经过预处理和向量化的文本输入Reformer模型的多头注意力层时,得到输出为
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
(6)
其中,WO为多头注意力层的权重矩阵,head1,head2,…,headh为局部敏感哈希注意力机制的输出,其表达式为
headi=Attention(Qi,Ki,Vi)
(7)
Attention(Qi,Ki,Vi)=

(8)
(9)
(10)

前馈神经网络是解码器子层的第二层,通过该层可以得到句子的特征向量,由于Reformer模型采用的是分块化前馈神经网络,因此,当输入文本时,首先将文本划分成m个模块,然后依次对各个模块进行计算,最后,将各模块计算结果进行拼接,得到前馈网络层输出,其计算公式为
C=Concat(chunk1,chunk2,…chunkm)=
Concat(max(0,Z1W1+b1)W2+b2,
max(0,Z2W1+b1)W2+b2,…,
max(0,ZmW1+b1)W2+b2)
(11)
其中,m为前馈神经网络输入所分的块数,W1,W2为前馈网络的权重,b1,b2为前馈网络的偏置。
本文使用的编码器是由6个编码模块组成,因此,最后,采用Softmax函数对输入进行计算,进而实现文本分类,计算方法为
y=Softmax(WH+B)
(12)
其中,W为权重系数矩阵,B为相对应的偏置。
4 实验设计与结果分析
本文利用Reformer神经网络对评论文本所蕴含的情感倾向进行判断分类。首先word2vec算法将利用jieba分词后的文本转化为词向量形式,然后输入Reformer模型进行训练,最后由Softmax分类器进行计算和情感分类。实验的环境见表1。

表1 实验平台设置
4.1 数据来源

表2 语料库基本信息

表3 语料库数据样例
4.2 评价指标
本文使用准确率Acc和训练时长Time作为分类的评价指标,针对同一语料库,Acc越大,代表模型预测越准确,Time越小,代表训练速度越快
(13)
其中,TP、TN、FP、FN分别为情感分类中几种分类结果,其具体分类见表4。

表4 文本分类混淆矩阵
4.3 实验参数设置
表5是实验所用一些参数的具体说明,其中词向量的维度vocab_dim设为100维,局部敏感哈希注意力机制的哈希桶数 buck设为10。优化算法使用自适应矩估计算法Adam来调整参数的学习率,并利用Dropout机制来避免过拟合现象的出现。

表5 实验参数
4.4 实验结果与分析
本文将Reformer模型与CNN、LSTM等模型进行对比,实验结果见表6。通过表6可以看出,相对于CNN、LSTM等模型,本文提出的利用Reformer模型进行文本情感分析不仅可以取得更高的准确率,在时间上也明显优于其它几种神经网络模型。本文提出的基于Reformer的情感分析模型在3种数据集上准确率达到92.21%、98.38%、99.94%,相对于与其它深度学习模型在对应数据集上的最高准确率分别提高了2.92%、3.27%、3.83%,从时间角度来说,本文提出的基于Reformer的情感分析模型相对于其它模型在这3种数据集上最快速度来说,分别提高了52.43%、55.36%、41.52%,可以看出本文提出的模型结构在3种数据集上的实验结果,较本文其它几种对比模型有较大幅度的提升。同时,本文所采用的3种数据集在大小、文本长度及是否为平衡数据集上都存在区别,由此也可以看出,在应用上,本文提出的基于Reformer的情感分析模型有较好的普遍适用性。
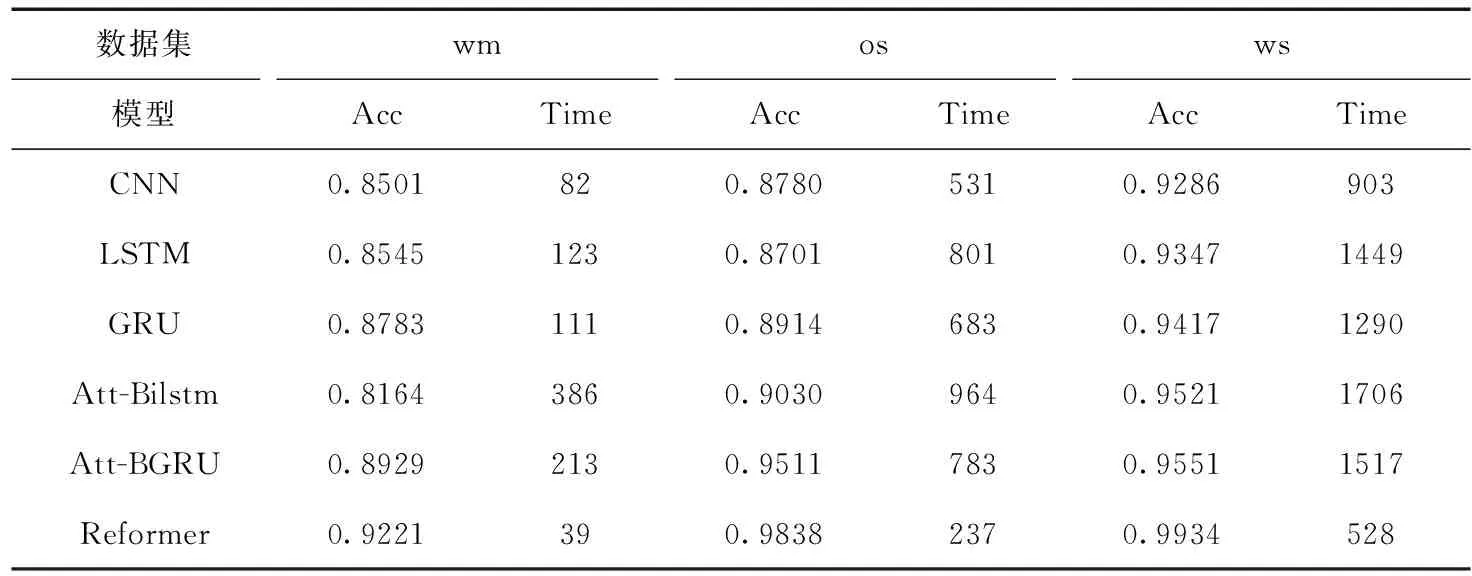
表6 Reformer模型与传统神经网络实验结果
以os数据集为例,绘制实验对比曲线图,如图7所示。通过图7可以看出,Reformer模型第一个Epoch的准确率就达到了90%以上,同时,当第4个Epoch结束,模型情感分类准确率增长速度变慢,逐渐接近收敛,验证Reformer模型的收敛速度明显快于其它几组实验对比模型。

图7 模型实验对比曲线图
为了进一步验证Reformer模型的有效性,本文将Reformer模型与Transformer模型及其变体进行比较,实验结果见表7,其中,LAT为Linear-Attention Transformer。“—”为未进行实验。通过表7,可以看出相对于Transformer等模型,Reformer模型在文本情感分析任务上有更好的效果。
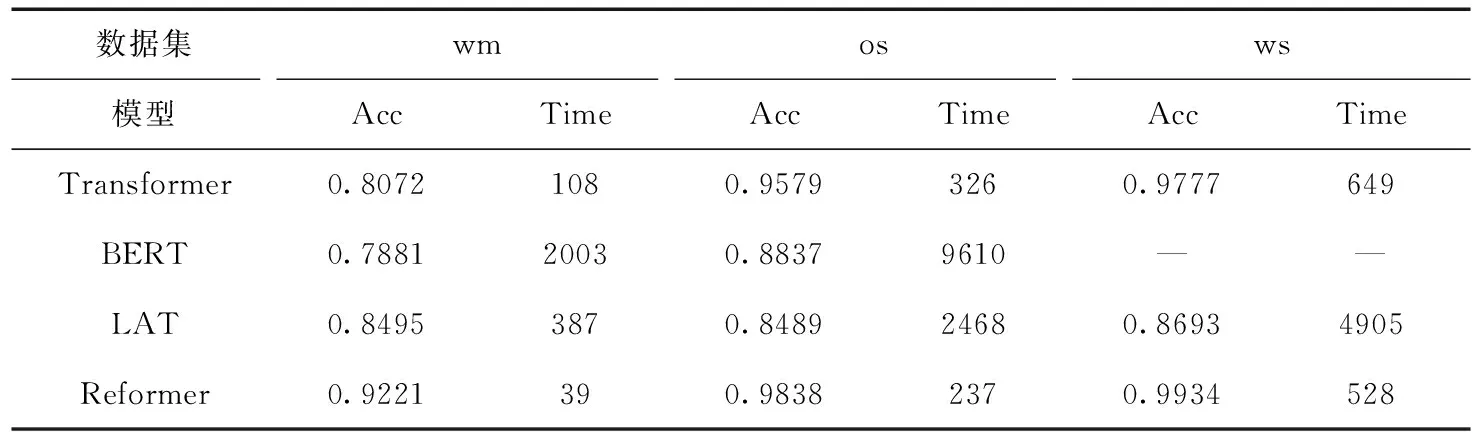
表7 Reformer模型与Transformer模型及其变体实验结果
5 结束语
针对传统情感分析训练时间长、准确率低的问题,本文提出了一种利用Reformer神经网络模型解决中文文本情感倾向分析的有效方法。该方法利用Reformer模型对输入的向量化的文本进行训练及分类。实验结果表明了使用该方法处理中文评论情感分析问题是可行的,相比CNN、LSTM、Transformer等模型能够更好实现中文文本情感的分类。在下一步的工作中,将继续对算法进行更加深入的研究,优化模型的结构,以期达到更好的情感分析结果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电脑爱好者(2020年20期)2020-10-22
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
