
基于自注意力的多模态LSTM的动作预测
2022-04-21 07:24莫晨,邵洁
计算机工程与设计 2022年4期
莫 晨,邵 洁
(上海电力大学 电子与信息工程学院,上海 200090)
0 引 言
基于视觉的动作识别一直是计算机视觉领域研究的难点与热点之一。在实际应用中,人们希望监控系统在风险行为发生之前就能发出预警信号,而非对于已经完成的动作进行识别,这就要求系统具备动作预测的能力。动作预测是指对输入视频流的特征进行分析和处理,旨在尽可能早地识别视频中包含的动作。动作预测与传统动作识别的主要区别就是识别目标的完整性。后者的识别对象是剪切好的视频中一段完整动作,动作结构完整。而前者是在仅观测到输入视频的一部分,就要及时地预测出视频中动作的类别,无法获取动作完整的时序结构。
Gao等[1]提出一个编码器-解码器的框架,该框架借助LSTM单元可以很好处理历史信息,并且回归未来帧的特征,利用特征完成分类。Antonino Furnari等[2]提出了rol-ling-unrolling LSTM模型用于运动序列的分析。然而,当观察时间缩短时,上述算法在性能不够稳定、不同预测时间的结果相差很大。
动作预测的效果极大程度上依赖特征对于非完整的动作片段的描述能力。特征越强,算法的效果就越好。然而目前大多数的工作[1,2]直接提取卷积层之后的特征用于后续的处理,而非考虑进一步地编码所得到的视频特征。所以本算法应用自注意力机制以及位置编码来进一步挖掘动作特征序列的语义。本文提出一个基于自注意力机制的多模态LSTM模型用于解决预测视频中人的动作问题。
1 模型框架
整体模型包含了3个分支网络,3个子网络分别用于处理3种不同的视频特征:RGB视频图像、光流、基于目标的标注信息(如图1所示)。每个子网络包括了3个组成部分,分别是,特征提取部分(RGB和Flow分支的特征提取网络为bn-inception,而Obj分支的特征提取网络为Faster R-CNN),包含自注意力机制模块和位置编码模块的编码器,以及LSTM结构。在提取好特征后,特征序列会输入到编码器进一步编码。编码器的输出序列即为LSTM结构的输入。LSTM结构会根据不同预测的时间,加载特征序列的历史信息产生动作类别预测的分布。最后,本算法采取了多模型融合策略(modality attention network[2]),综合考虑3个子网络的输出,分配相应的权重,权重与对应模态的动作种类分布张量对应相乘得到整个模型最后输出。
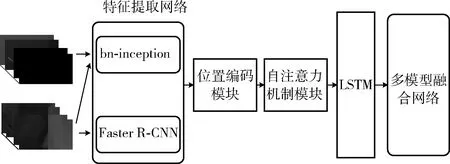
图1 总体架构设计
1.1 多特征提取网络
构建一个动作预测算法,首先就应该考虑什么样的特征适合于建模动作。本算法考虑了3种具有丰富语义的高层特征。其中,RGB视频图片用于建模空间信息,光流图片用于建模时序信息,与目标相关的特征(Obj特征)用于检测视频中的人与何物互动,即查清视频中目标的类别。
RGB图片和光流图片输入到bn-inception网络里分别提取RGB特征和光流特征。去除bn-inception原网络结构最后的分类层,并且从中间层Global pooling layer的输出提取为相应的RGB特征和光流特征。特征向量的维数为1024维,这样的特征向量与机器翻译任务中采用词嵌入算法得到的词向量很相似。视频里不同帧取出来的图片特征相当于文本里的词,且都是时序信息,这为在计算机视觉领域应用基于自注意力机制的Transformer[3]提供了基础。
Faster R-CNN[4,5]用于与目标相关的特征的提取。提取该特征,目的是弄清楚视频中目标的种类,而非目标的位置。所以,该特征向量略去了目标边界框的坐标信息。特征向量是一个H维的向量,向量中的每一个元素是视频里的每帧中包含的目标类别的置信度分数的累加,其中H表示数据集里目标的类别总数。
1.2 位置编码模块
机器无法从打乱顺序的视频中判断出动作的类别,所以片段中动作的先后顺序对于动作预测十分重要。这也就要求,对于提取好的特征序列,必须要加入表明它们在原视频先后位置的记号。本模型添加了一个独立的基于三角函数位置编码模块,目的是使自注意力模块能够充分地学习到序列的位置信息。
(1)
(2)
其中,在位置编码向量的偶数元素位置,使用正弦函数编码,而在奇数元素位置,则使用余弦函数进行编码。2i和2i+1分别代表了位置编码向量里元素的位置索引。
1.3 自注意力机制模块
如图2所示,每个模态的特征都会经过位置编码模块和自注意力机制模块的处理,位置编码模块和自注意力机制模块嵌入到3种模态特征的分支网络中。特征序列X(RGB)、X(Flow)、X(Obj)分别与相应的位置编码矩阵Pe相加后,输入到自注意力机制模块进一步处理,输出得到具有丰富语义的高维特征Y(RGB)、Y(Flow)、Y(Obj)。
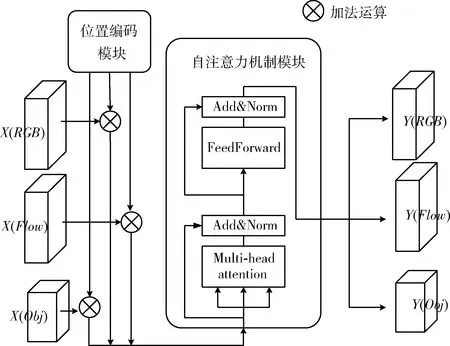
图2 位置编码模块和自注意力机制模块
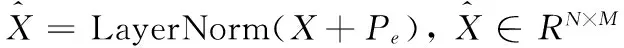
(3)
Y=FeedForward(LayerNorm(Om))+Om
(4)
(5)
Multi-head(Q,K,V)=Concat(head1,…,headh)Wo

(6)
FeedForward(x)=max(0,xWs+b1)Wt+b2
(7)
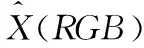
1.4 LSTM
在完成特征序列的编码后,由单个LSTM层具体实施动作预测,加载过去观察到的视频帧的特征序列Y,并且产生不同的预测时间的动作种类分布Oa,t。LSTM的输入输出关系如图3所示(虚线框内的模型省略位置编码模块以及自注意力机制模块),对于一个视频片段,在动作开始前,往前取样14帧图片,时间间隔为0.25 s。这14帧图片构成一个基本的训练样本,其中Ft代表了样本中的第t帧。训练样本构成了视频的观察片段,观察片段包含两个时间,一个是观察时间,一个是预测时间。如图3所示,观察时间为[F1,F7]之间的时间间隔,即LSTM层的输入序列为[F1,F7]的特征序列Yt,那么预测时间即为从F7到动作开始时刻的时间间隔。
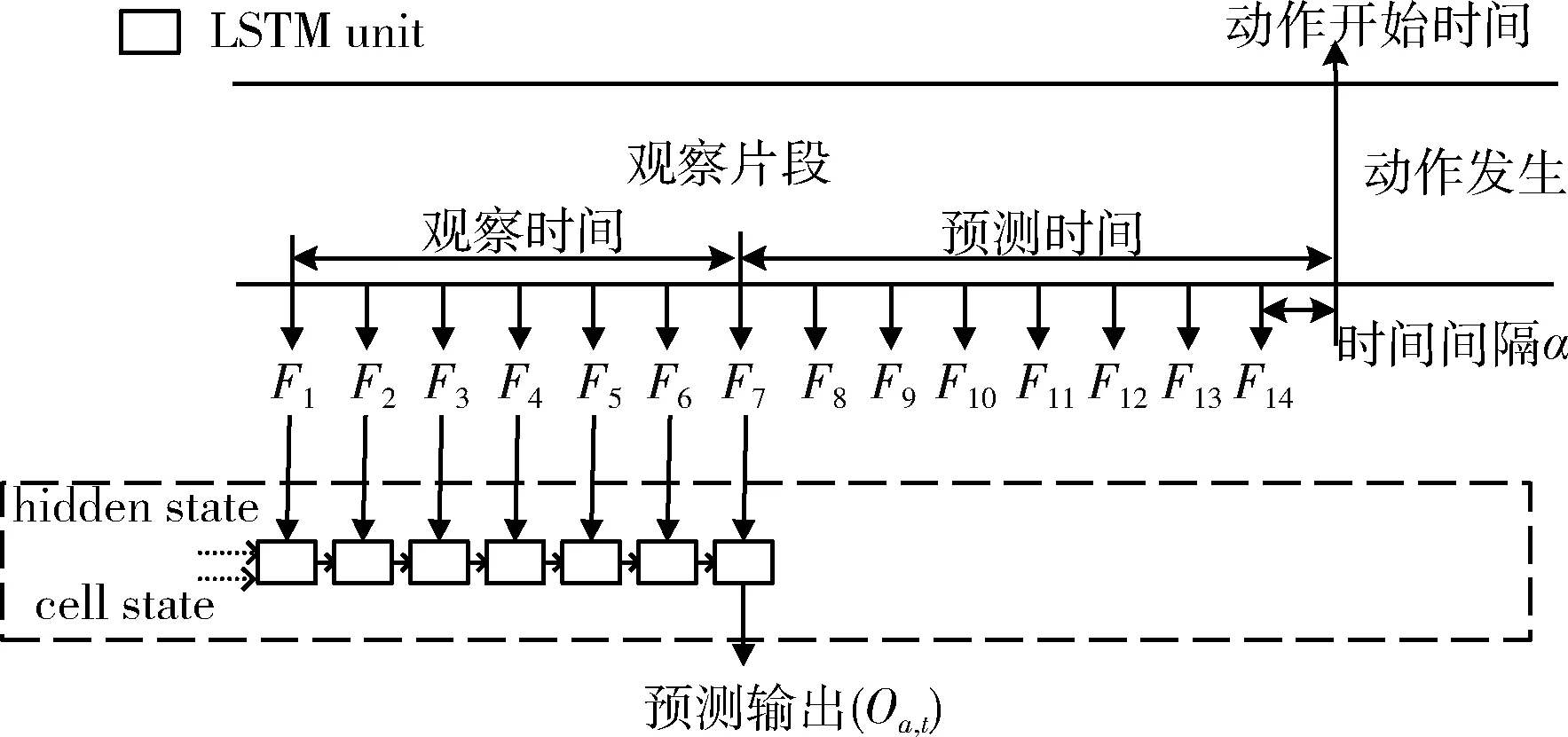
图3 采样策略及LSTM输入输出关系
LSTM有两个中间状态hidden stateht和cell statect,且这两个中间状态的初始化值设定为0,即图3的最左侧的虚线箭头输入置为0。而ht和ct(t≥1)的值均是由LSTM的上一个时间步的输入(即代表视频帧的特征向量),和上一个时间步的ht-1和ct-1所计算出来,并继续往后传递,具体如式(8)所示
(Oa,t,ht,ct)=LSTM(Yt,ht-1,ct-1),t∈[1,N]
(8)
这两个中间状态即为模型加载过去观察的历史信息来预测未来动作,并以LSTM的输入序列的最后一帧特征向量Yt的输出Oa,t作为该次预测时间下的预测输出。以图3为例,此时LSTM的输入序列为[F1,F7],模型在总结F1到F6的信息后,输入F7到对将要发生的动作的预测(本次时间步LSTM层的输出),此时预测时间为2 s。因此,当t越小时,LSTM网络观测到帧数也越少,相应的预测时间也越长。在实验中,为了便于与其它的算法比较,α=0.25 s,t=14 s。本文所提出的算法一共可以产生8个预测时间的结果,Ta∈{0.25 s,0.5 s,0.75 s,1.0 s,1.25 s,1.5 s,1.75 s,2.0 s}。
1.5 多模型融合网络
得到3种模态的特征的动作预测结果Oa后,需要采取多模型融合策略得到最终的预测输出。受文献[7,8]工作的启发,本文算法选择Modality attention network。该融合网络比经典的融合方法(如late fusion)效果要好。late fusion原理可见式(9),即找到一组合适的参数Ki,与对应模态的预测结果Oa,i线性组合后得到最终的输出。late fusion往往采取交叉验证的方法确立适合的参数Ki。交叉验证在数据集规模较大时,会因为训练时间很长而变得繁琐。不同模态的特征对动作预测结果的影响力是不同的,Modality attention network针对每种模态特征找到合适的融合权重,能有效避免late fusion由于交叉验证带来的缺点,且对最终的融合效果也能更好地改善
(9)
Modality attention network的主要原理就是为不同模态的特征计算出一组注意力分数σ,注意力分数σ表明了每种模态特征对最终预测结果的重要程度。Modality attention network(NMATT)由3个可以学习参数的线性层和ReLu激活函数组成。该模态特征的注意力分数σm由该模态子网络的LSTM结构的两个中间状态ht和ct合并(concatenation)张量输入到NMATT里计算得到。具体如式(10)所示,其中m代表相应模态,即RGB特征、Flow特征和Obj特征。⊕是张量间的concatenation运算。注意力分数σ的个数与模型所考虑的特征总数L保持一致
σm=NMATT(ht,m⊕ct,m)
(10)
融合权重θm由注意力分数σm经Softmax函数归一化后得到,具体如式(11)所示
(11)
整体模型最终的预测结果由相应模态的融合权重θi与该模态分支网络的预测输出乘积的线性组合。具体如式(12)所示
(12)
2 实 验
2.1 实验细节
在EPIC-Kitchens[8]和EGTEA Gaze+[9]两个数据集评估本算法。为了便于与其它算法对比性能,按照文献[2]的设定分割EPIC-Kitchens数据集。EPIC-Kitchens的训练集包含了23 493个样本,测试集包含了4979个样本。EGTEA Gaze+的官方训练集包含了8299个样本,测试集包含了2022个样本。算法的表现由Top-5准确率指标衡量。
两个数据集的视频是由可穿戴摄像机所拍摄的,视频的帧率有所不同。把原始视频的帧率统一转换到30 fps,并且保持原始视频的时间长度不变。提取EGTEA Gaze+视频的光流图片使用了TVL1算法。在EPIC-Kitchens数据集中,作者已经提供了提取好的每帧的光流数据。为了避免过拟合,特征提取与预测网络的训练将分别进行。对于RGB特征和光流特征,使用bn-inception网络进行提取。具体地,先在两个数据集上的行为识别任务上训练TSN[10]网络,TSN网络的主要结构是bn-inception,一共有两支,分为空间流和时间流。训练完毕后,会得到空间分支和时间分支的模型权重,即预训练模型。把预训练好的模型分别导入到bn-inception网络里,从Global pooling layer的输出提取对应的RGB特征和光流特征。这两个特征向量的维度都是1024维。Obj特征的向量维度为352维,因为EPIC-Kitchens数据集里目标的类别数是352。由于EGTEA Gaze+数据集缺少与目标检测相关的标注信息,所以在该数据集的实验中未加入Obj特征训练。在Multi-head attention模块,head的数量设定为8,RGB分支网络的维度设定为1024,Obj分支网络的维度设为352,模型的维度需要和其特征向量的维度保持一致。
2.2 实验结果及其分析
表1和表2列举了State-of-the-art的动作预测算法在两个数据集上不同预测时间取得的Top-5准确率结果。如表1所示,在EPIC-Kitchens数据集上,当预测时间Ta为0.25 s时本算法表现略低于RU[2],其余预测时间均取得最佳效果。如表2所示,在EGTEA Gaze+数据集上,本算法在所有的预测时间上都超过了其它算法。RU[2]算法是对比算法中取得了次优效果的方法,在表1和表2的最后一栏列举了本算法实验结果对于取得次优结果的RU算法的改善情况。由实验结果可知,对比算法在预测时间Ta变短时,模型效果都会越好。这表明这些算法在较长的预测时间的预测上的表现不如较短的预测时间。本算法随着预测时间Ta的改变,在EPIC-Kitchens数据集的最终结果平均稳定在38%附近,在EGTEA Gaze+数据集的最终结果平均稳定在77%附近。这主要是由于自注意力机制地有效应用,模型能够更好地学习到所提取的视频特征的全局信息,并且使得模型在所有的预测时间上取得的结果保持稳定,没有较大的波动。
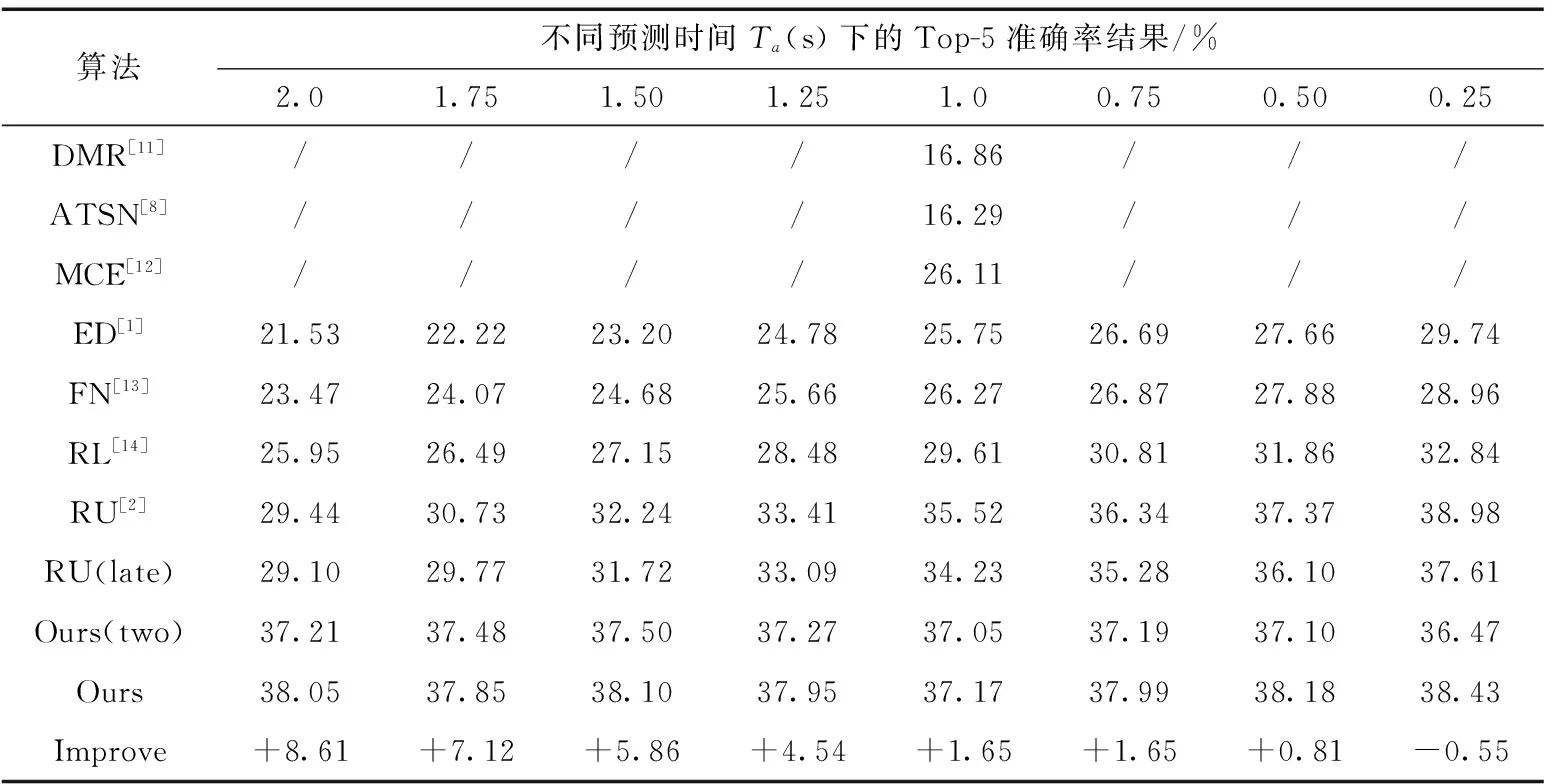
表1 EPIC-Kitchens数据集的动作预测结果

表2 EGTEA Gaze+数据集的动作预测结果
在EPIC-Kitchens数据集上的预测精度结果不足40%。通常来说,动作复杂度越高,相似动作之间就越容易混淆,所取得分类精度就越低[15]。动作复杂度是指相同动词与不同的名词之间组合的数量。两个数据集的动作标注的标签由动词加名词的组合构成。EPIC-Kitchens数据集包含了125个动词,352个名词,有2513个独特的动作类别。然而EGTEA Gaze+数据集仅有19个动词,51个名词,106个独特的动作。EPIC-Kitchens的动作片段的标注约为EGTEA Gaze+数据集的3倍。所以,EPIC-Kitchens数据集的规模比EGTEA Gaze+数据集要大,它的动作复杂度也要更加复杂。这意味着EPIC-Kitchens有更多相似的动作且更容易混淆。动作中包含的样本越多,动作种类的姿态多样性就越丰富,可能会使得模型更难学习。
为了探究模型中LSTM结构的选择,本文算法设立了一个双层结构的LSTM,3个模态特征(RGB, Flow, Obj),并采用Modality attention network融合的基线算法作为对照,模型记为Ours(two)。RU算法的双LSTM结构是基于编码器-解码器结构,编码器与解码器都由LSTM实现。主要原理是解码器使用编码器内部特征进行初始化,并在训练样本最后一帧特征上迭代来预测将来的动作。由表1的结果对比可知,本算法的单LSTM结构比起这种双层LSTM结构,更适合于预测任务。表1还给出了late fusion和Modality attention network多模型融合网络的对比结果,其中RU(late)为采用late fusion的RU算法,而RU算法则使用Modality attention network。由结果可知,在动作预测任务上,该融合网络要比传统的late fusion方法效果更好。
为了验证编码器模块的有效性,在模型中去除编码器(模型A)以及保留编码器(模型B),验证模型A和模型B在EPIC-Kitchens数据集上的表现。如表3所示,表3的前3行是去除了编码器后在3个模态特征的分支网络的Top-5准确率,而后3行是保留编码器的原模型在3个模态特征的分支网络的Top-5准确率。显然编码器显著地改善了模型的预测表现,特别是对于长预测时间下的预测(比如Ta=2.0s,Ta=1.75s)。较长时间的预测与较短时间的预测之间的区别在于输入到模型的视频序列的时间长度,当输入到模型的帧数越少时,预测时间就越长。所以基于自注意力机制的编码器有效地编码序列上下文的信息,重建高层特征序列来提高预测动作的能力。
表4比较了不同特征组合的融合结果,目的是探究3种模态的特征的相关性。结合表3的B模型在RGB, Flow, Obj这3个单特征上的表现可知,所提出的算法两两特征融合均能改善单个分支特征上的表现,这表明该算法能有效利用3种从视频提取出来的特征。如表4所示,3种模态的特征里,RGB特征比起光流特征以及Obj特征在动作预测任务中更加有用,而Obj特征取得了次优的结果。RGB特征和光流特征在叠加Obj特征后均可带来明显提升,这表明Obj特征对于视频动作推理的重要性,设计该类算法需要加以考虑视频中目标的影响。RGB,Flow,Obj特征三者融合可以带来最佳的结果。
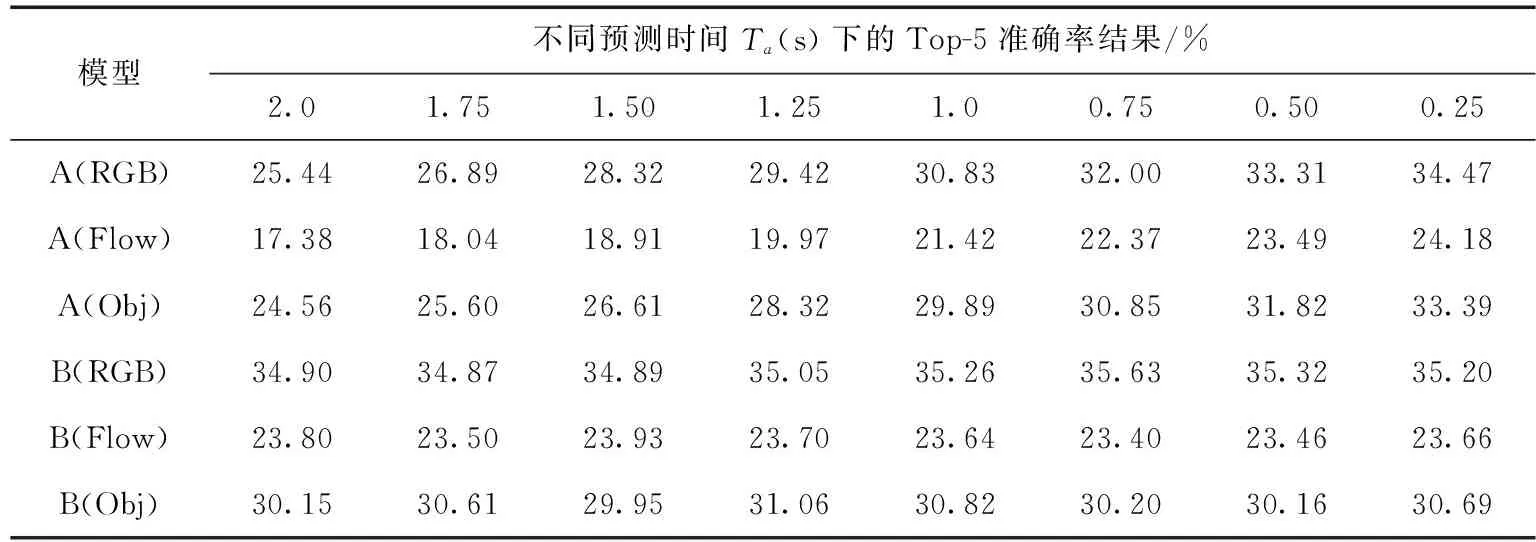
表3 缺少编码器的模型(A)与完整模型(B)结果对比
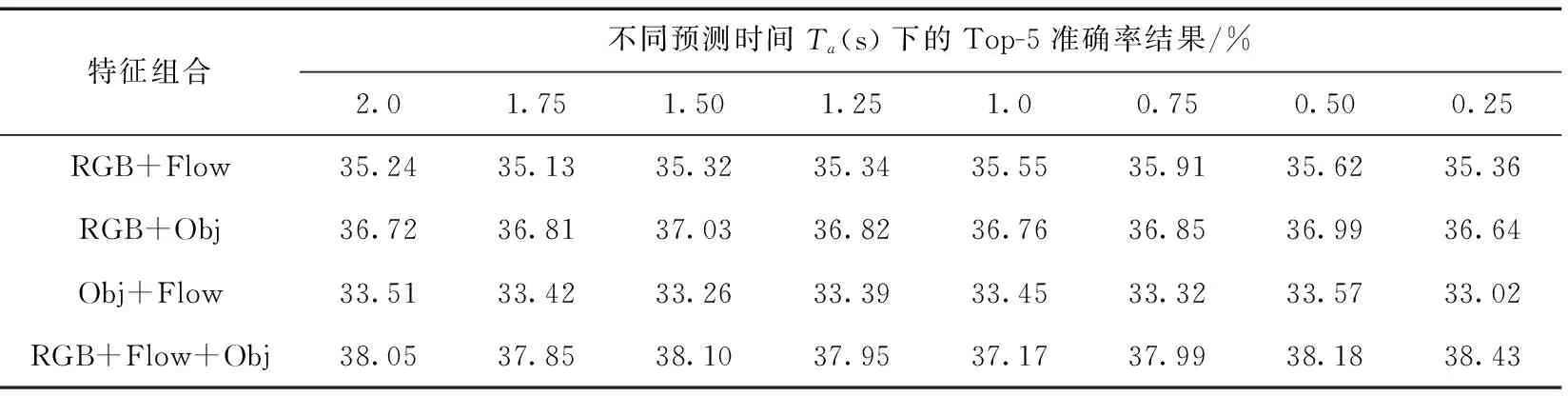
表4 不同特征组合的融合结果
3 结束语
本文为改进现有的动作预测算法中在不同预测时间上不稳定的问题,提出了基于自注意机制的多模态LSTM网络。受到机器翻译任务的Transformer模型的启发,借鉴词向量的表示方法来表示视频图片的特征,在计算机视觉领域应用了自注意力机制编码视频特征序列,并且验证了自注意力机制可有效帮助模型学习视频动作的特征。使用位置编码技术可以充分利用序列的位置信息,使预测具有可靠性。RGB特征比起光流特征以及Obj特征在动作预测任务中更加有用,而Obj特征取得了次优的结果。在两个基准数据集上的实验结果表明,本文所提出的模型是鲁棒的,并且取得了最好的结果。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
网络安全与数据管理(2022年1期)2022-08-29
昆明医科大学学报(2022年3期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
探测与控制学报(2015年4期)2015-12-15
