
基于多尺度条件生成对抗网络的图像去模糊
2022-04-21 07:24王晨卿刘云鹏蒋晓瑜闫兴鹏
计算机工程与设计 2022年4期
王晨卿,荆 涛,刘云鹏,陈 颂,蒋晓瑜,闫兴鹏
(陆军装甲兵学院 信息通信系,北京 100072)
0 引 言
图像去模糊技术是图像处理和计算机视觉领域内的研究热点。在相机拍摄过程中,由于相机抖动旋转、目标物体相对位移或镜头失焦等因素的影响,会导致所拍摄图像产生模糊。传统的去模糊算法首先根据先验约束[1-4]估计模糊核,然后再通过反卷积复原图像,其缺点在于泛化能力差且计算过程复杂。近年来,卷积神经网络(convolutional neural network,CNN)被应用到图像去模糊领域,并以其固有的多尺度特征提取能力取得了良好效果[5,6]。Nah等[7]以分层网络级联作为多尺度特征表达方式的CNN能以由粗到细的策略逐步地恢复出清晰图像,然而这种方式会导致模型的参数量和计算时间增加。Kupyn等[8]使用生成对抗网络以端到端方式进行去模糊处理并提升了运行速度,然而由于其扁平化的网络结构导致了处理效果不佳。
针对现有的去模糊方法中效果不佳和处理速度慢等问题,本文提出一种端到端方式的多尺度条件生成对抗网络模型,用以高效地处理复杂场景下的非均匀模糊问题。首先构造了一种多尺度残差模块,增强网络的多尺度特征提取能力,同时减少网络参数量,并以多尺度残差块为主体构造生成器网络;添加全局和局部跳跃连接的结构,以提高网络的学习效率和多尺度特征的自适应表达能力。其次引入PatchGAN[9]鉴别器网络结构提升局部图像特征提取和表征,并加速网络收敛。
1 相关工作
1.1 条件生成对抗网络
传统的生成对抗网络模型如图1(a)所示,生成对抗网络(generative adversarial network,GAN)由一个生成器G(Generator)和一个鉴别器D(Discriminator)组成,训练的过程就是两者进行动态地“零和博弈”。网络训练时输入随机噪声z到生成器G,G通过不断地学习真实数据x的分布,使生成的数据G(z)尽量接近于真实数据x的分布。而鉴别器D的任务是把真实数据x与生成数据G(z)尽量区分开。模型最终的目的是鉴别器D无法区分生成数据G(z)的真假。传统GAN的损失函数可以表示为
Ez~Pz[log(1-D(G(z)))]
(1)
其中,x,z分别为输入的真实数据和随机噪声,Pr和Pz分别表示真实数据分布和随机噪声分布,E[*]表示数学期望。对抗过程中交替更新生成器G和鉴别器D,直到二者达到纳什均衡,即D(G(z))=0.5。
然而传统的GAN作为一种无监督学习模型,不需要预先假设数据分布模型,其生成过程过于自由,因此对于较复杂的数据或高分辨率的图像信息,传统的GAN变得不在生成器和鉴别器中引入约束条件y,为生成特定条件下的数据提供方向上的指导,y可以是标签或图像可控。针对这种情况,CGAN[10]被提出并广泛应用于图像翻译、图像修复和超分辨率重建等领域,其通过在生成器和鉴别器中引入约束条件y,为生成特定条件下的数据提供方向上的指导,其中y可以是标签或图像等任意辅助信息。因此将传统的GAN由无监督学习方式转变为监督学习,更有利于生成符合条件的数据。CGAN的模型框架如图1(b)所示,其目标函数可以表示为
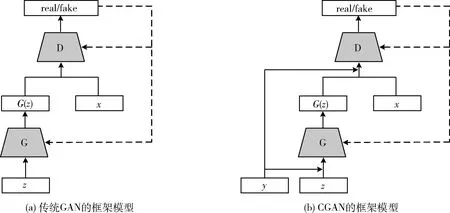
图1 生成对抗网络的基本框架
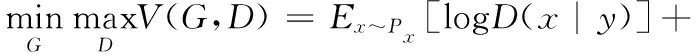
Ez~Pz[log(1-D(G(z|y)))]
(2)
1.2 多尺度特征表达方式
在计算机视觉处理任务中,表达多尺度特征需要用不同大小的感受野来提取不同尺度下的特征信息。而CNN因其固有的特征提取能力,能够以堆叠卷积层的方式由粗到细地提取到图像的多尺度特征。通过增加CNN网络层的深度和宽度来提取更加丰富和抽象化的图像特征信息,该种策略已经被广泛应用并且取得了良好的效果,如AlexNet[11]和VGGNet[12]等。然而,通过简单地堆叠网络层或者以多层网络级联的方式进行多尺度特征提取,不仅会造成运行时间和内存的增加以及模型的过拟合,同时,冗余的网络层会导致传输过程中的特征丢失。
为了有效地增强CNN的多尺度特征提取能力,ResNet[13]通过学习残差的方式解决了深层CNN中的网络退化问题,因此可以使用深层残差网络来提高多尺度特征提取能力。GoogLeNet[14]通过并行使用多个不同内核大小的卷积层提取到不同尺度的图像特征,而后进行级联拼接实现多尺度特征的融合。DenseNet[15]在任意两个网络层之间添加跳跃连接,使当前层的特征信息能够传递给后续所有的网络层,实现了多尺度特征的复用,然而其能力受到计算量的约束。Res2Net[16]基于ResNet中的bottleneck模块,将中间的3×3卷积层改进为分级连接的较小卷积块,增加了网络层的感受野范围;并通过将特征通道数均分为L组,在更为精细的层次上提升了多尺度表达能力,同时减小了参数量。相关网络的模型结构如图2所示。
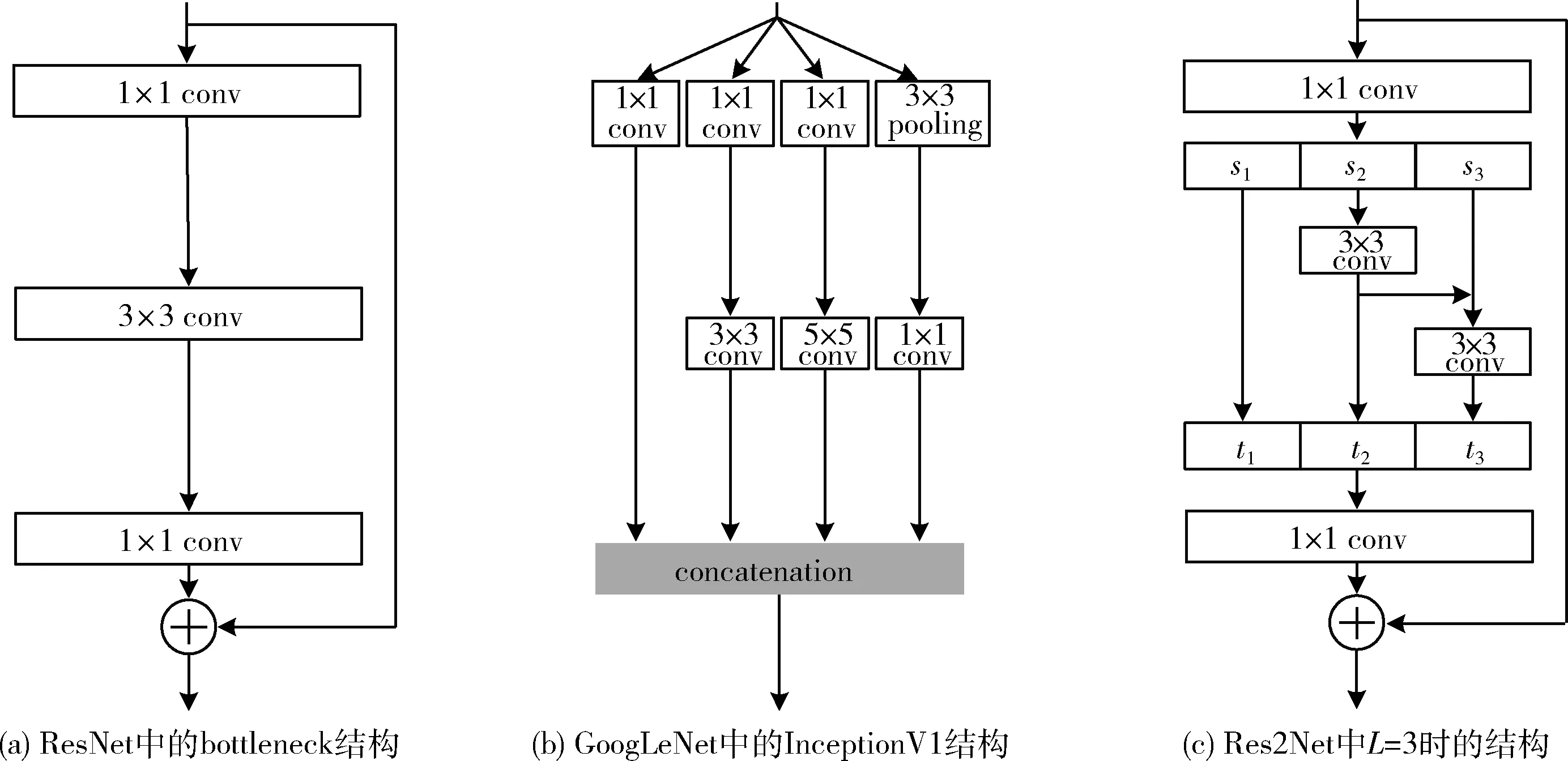
图2 多尺度网络模型的结构对比
2 本文方法
2.1 多尺度残差模块
为更好地还原清晰图像的边缘结构和纹理细节,提升网络的去模糊效果,本文提出一种有效的多尺度残差模块MSR2B(multi-scale Res2Net block),以充分提取不同比例的特征信息。MSR2B的结构如图3所示,以输入特征分组数L=4为例进行说明。该模块由PartA和PartB两部分组成,其中PartA基于Res2Net模型的分级残差连接方式,PartB并行使用了两组不同内核大小的卷积核,最后通过拼接操作(concatenation operation)融合特征图。PartA和PartB能够以不同的策略提取到多尺度特征,将两者结合产生了更好的效果。

图3 多尺度残差模块MSR2B的结构(特征通道分组L=4时)

(3)
在PartB中,构造了一个并行的双分支结构,其中包含两个不同内核大小的卷积层:3×3卷积和5×5卷积。将ti(2≤i≤L)处的特征图经过拼接(concat)后经双分支卷积处理,以自适应地提取不同尺度的图像特征。PartB的功能可以表示为
(4)
(5)
(6)
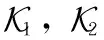
Cn=Cn-1+Wout
(7)
在MSR2B中删除了传统残差网络中的批归一化(batch normalization,BN)层,因为BN层占用了过多的计算内存,并且在去模糊任务中添加BN层会弱化图像本身的细节信息并带来伪影和棋盘效应,并且增加了模型复杂度,限制了网络的泛化能力[17]。MSR2B通过在单个块内进行分级连接和并行卷积再融合的残差网络结构不仅可以增强多尺度特征的提取能力,而且相比于传统的bottleneck模块带来的计算复杂度也可以忽略。
2.2 网络结构
本文的生成器网络以MSR2B残差模块为主体结构,如图4所示。生成器网络包含一个步长为1,卷积核尺寸为7×7的常规卷积层。两个步长为2,卷积核尺寸为3×3的跨步卷积层,可以对图像进行下采样并扩展通道数量。然后堆叠了9个多尺度残差块MSR2B用以充分提取多尺度图像特征。最后包含了两个步长为2、卷积核尺寸分别为3×3的转置卷积层和一个步长为1、卷积核尺寸为7×7的常规卷积层,用来对图像进行上采样并恢复特征通道数量。除最后一层卷积外的常规卷积和转置卷积后都跟随ReLU激活函数以增强网络的非线性表征能力,最后一层卷积后添加tanh激活函数。
为了进一步增强网络的特征学习能力,在生成器网络中添加了全局跳跃连接和局部跳跃连接。局部跳跃连接的作用表现在:一方面为了防止特征信息随着网络深度的增加而逐渐丢失,另一方面为了充分利用各个MSR2B模块的不同输出特征,因此将各个MSR2B的输出都发送至网络末端进行特征融合,并在残差网络末端添加一个1×1大小的瓶颈卷积,其作用是自适应地提取多尺度特征并解决特征融合带来的冗余信息,同时减小网络的计算复杂度。其次通过添加全局跳跃连接,可以提高网络对图像特征信息的复用,并降低模糊图像到生成图像之间端到端学习的复杂度。
GAN常用的鉴别器大多为二分类器,是将图像经过多个卷积层和全连接层后得到的标量值直接作为判别的结果输出,是对整张图像的真实性做出的判断。本文采用PatchGAN鉴别器网络,通过假设一张图像内的多个图像块(patch)之间的像素是互相独立的,然后对每个图像块进行鉴别,并取所有图像块的鉴别结果的平均值作为输出结果。相比于传统的二分类器,PatchGAN更加关注图像中的局部高频信息,能够表达更为精确的整体差异;并且由于PatchGAN是对小尺寸的图像块而非整张图像进行处理,加速了训练过程中的网络收敛。如图4所示,本文中的鉴别网络包含5个卷积层,前4层卷积大小依次为4×4×64、4×4×128、4×4×256和4×4×512,且步长均为2,其后连接BN层和斜率α=0.2的LeakyReLU激活函数层。最后一层卷积大小为4×4×1,步长为1,其后连接Sigmod激活函数层。本文中鉴别器的输入为来自生成器的输出图像和对应的清晰图像(约束条件y),且每个patch的大小均为70pixel×70pixel。
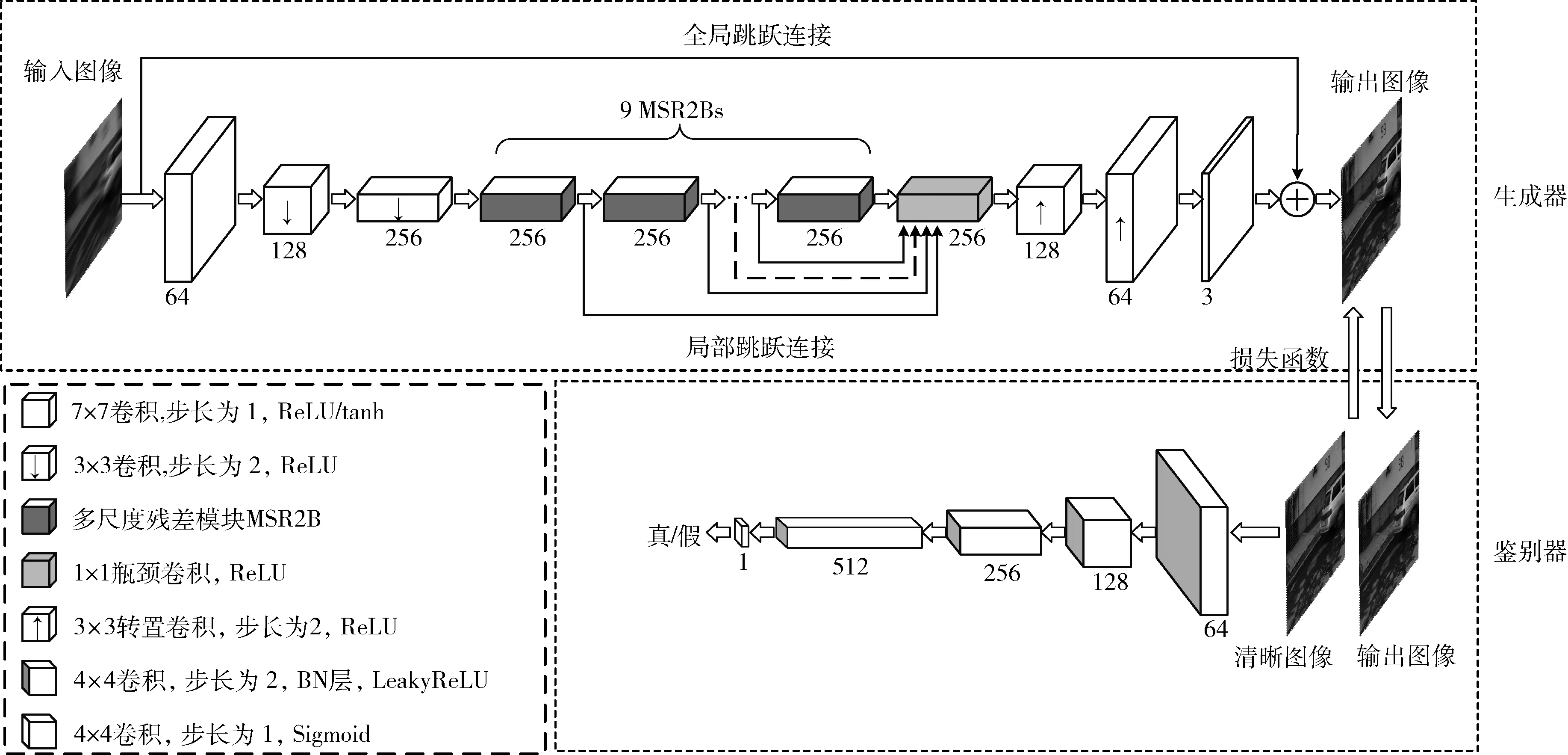
图4 本文去模糊条件生成对抗网络的结构
2.3 损失函数
本文采用的损失函数由对抗损失和内容损失两部分组成。总的损失函数表示为
Ltotal=Ladv+λLpers
(8)
(1)对抗损失。传统的GAN在训练过程中存在着模式崩塌和不易收敛等问题,Arjovsky等指出这些问题是由于传统的GAN采用JS散度(jensen shannon divergence)和KL散度(kullback leibler divergence)作为优化策略而导致的,并提出WGAN网络,使用Wasserstein距离衡量真实样本分布与生成样本分布之间的距离替代传统策略来优化网络[18]。然而WGAN会通过剪切权重的方式来强制满足Lipschitz约束,从而导致梯度消失或梯度爆炸等问题。为进一步解决此问题,WGAN-GP使用了梯度惩罚的方式替代权重剪切,并且获得了更好的性能[19]。WGAN-GP的损失函数表示为
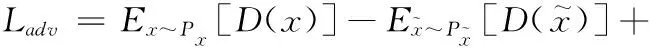
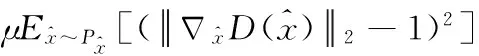
(9)

(2)内容损失。为了更好地恢复模糊图像的细节特征,本文使用感知损失Lpers[20]替代传统的L1或L2损失函数来定义网络训练的内容损失,用以改善生成图像和清晰图像之间的内容一致性。Lpers定义为清晰图像经过卷积后得到的特征矩阵与生成图像经过卷积后的特征矩阵之间的欧式距离,可以表示为
(10)
其中,R、G(B)分别表示清晰图像和生成图像,φi,j表示在ImageNet数据集上预训练的VGG19网络中第i个池化层前的第j个卷积层输出的特征图,wi,j和hi,j表示特征图的维度,由于较低层的特征图相对于深层的特征图着重于表达图像的纹理特征,故这里选择i=j=3。感知损失函数Lpers有助于网络生成真实性更强的图像。
3 实验结果与分析
3.1 数据集
GOPRO数据集由Nah等[7]提出,通过使用GoPro4 Hero Black高速相机以240 fps的帧率拍摄多个场景的视频,并对视频中的连续帧求平均来生成模糊图像,这些模糊图像较好地模拟了复杂相机抖动、散焦和物体相对位移等真实的非均匀模糊场景。GOPRO数据集中包括3214个清晰-模糊图像对,选取其中2103对作为训练集,另外1111对作为测试集。
Köhler数据集是Köhler等[21]通过记录和回放6D相机的运动轨迹得到的。Köhler数据集作为评价非均匀去模糊算法的标准数据集,其中包含了4张清晰图像,且每张清晰图像分别对应了12张不同模糊核的模糊图像,但由于该数据集内容较小,只能用作测试集使用。
3.2 训练细节
实验中使用PyTorch深度学习框架,在装有Intel i7-6900K CPU和单块Nvidia Titan X GPU的工作站上进行网络模型的训练。训练中采用自适应估计矩阵(adaptive moment estimation,Adam)算法进行优化,其中首次估计的指数衰减率β1=0.5,第二次估计的指数衰减率β2=0.999,参数ε=10-8。交替更新生成网络和鉴别网络,即每更新1次生成器需要对鉴别器进行5次优化更新,经过300个epoch后模型收敛,前200个epoch的初始学习率设置为1×10-4,在后100个epoch的学习率线性衰减至1×10-7。感知损失函数的权重因子设置为λ=100,实验过程中将batchsize设为2。并将随机裁剪得到的256×256像素大小的图像数据作为训练输入。
为准确评估图像的去模糊效果,并评价本文所提出的去模糊多尺度生成对抗网络方法的有效性,采用峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为客观评价标准。PSNR反映了对应像素点之间的差异程度,评价结果以dB(分贝)为单位表示,其值越高表明图像越清晰;SSIM从亮度、对比度和结构3个方面来衡量图像的相似度,取值范围是[0,1],其值越接近于1表明图像质量越高。
3.3 多尺度残差模块的有效性分析
首先分析了MSR2B模块中特征通道分组数L的大小对于网络性能的影响。由于在本文的生成网络中,MSR2B模块的输入和输出特征通道数均为256,为了使模块内的通道数能够均分,设计了L=1,L=2和L=4这3种参数下的多尺度残差模块MSR2B,并在GOPRO数据集下进行训练,保持了相同的实验参数。客观评价结果见表1,可以看出随着L的增大,网络层获取的感受野范围越来越大,提取到的多尺度特征越来越精细,PSNR和SSIM也随之增大,并在L=4时表现出最佳性能。图5所示为不同尺度L下的网络去模糊效果,结果表明,随着特征分组的增加,网络的去模糊性能随之提升,可以恢复出更多的细节纹理和图形结构信息。尽管可以通过继续增大块内特征通道分组数L来提高特征提取能力,但是随着L的增加,图像的特征会被已有的感受野完全覆盖,模块的性能提升将会受限且复杂度会随之增大,为了平衡网络的计算复杂度和性能,本文最终选择使用L=4时的MSR2B作为多尺度残差模块的基准结构。

表1 不同尺度下MSR2B的性能比较

图5 不同尺度下MSR2B的去模糊效果对比
其次验证了基准模块MSR2B(L=4)的数量k对于网络去模糊性能的影响。如图6所示,从图中可以看出,一开始随着MSR2B模块的增加,网络的去模糊效果快速提升,然而继续增加MSR2B模块的数量会导致网络的参数量增大并且性能提升的效率不明显。因此为了平衡网络的计算复杂度和去模糊性能,最终选择使用MSR2B模块的数量为k=9。
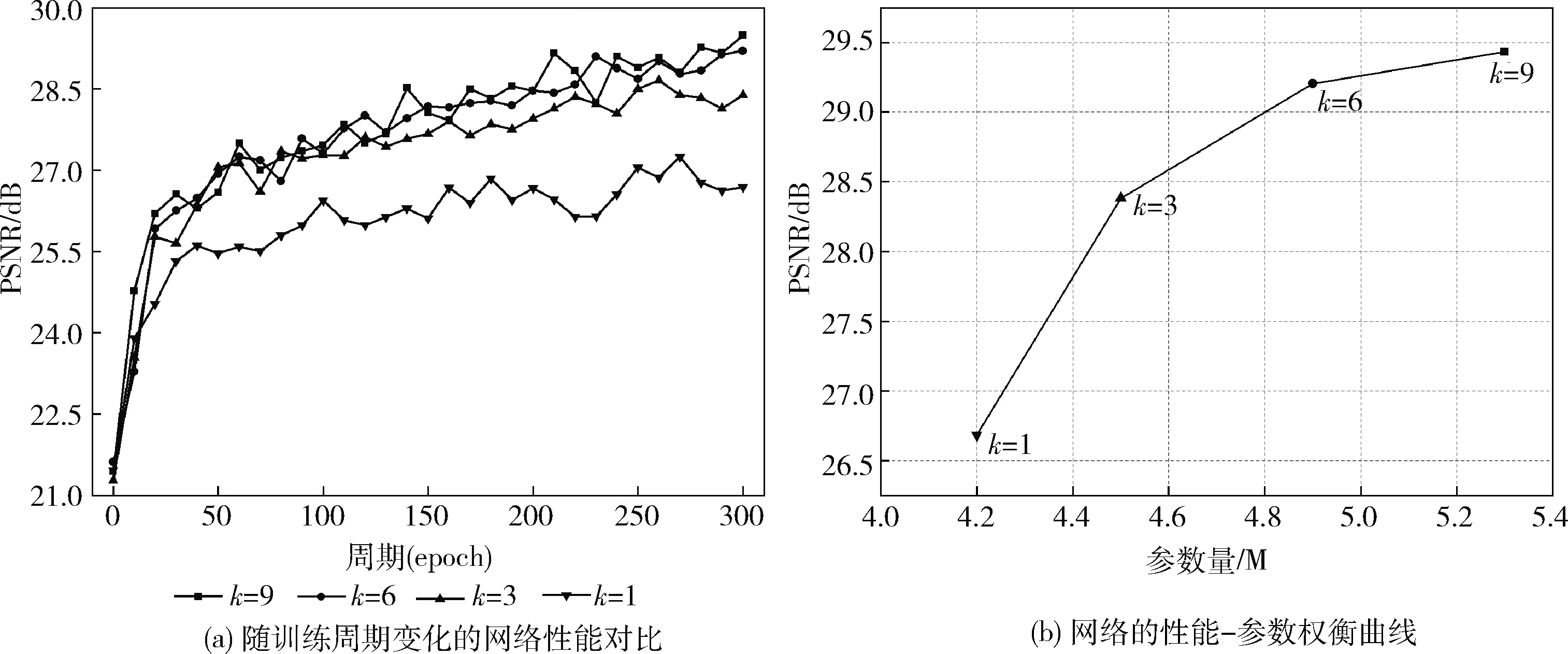
图6 不同数量的MSR2B对网络性能的影响
最后为了验证本文提出的多尺度残差模块MSR2B的有效性,将该模块与残差模块ResNet和Res2 Net在生成网络中的特征提取能力进行了比较。在本文的生成器主干网络结构中,分别使用经典的ResNet残差模块和Res2Net(L=4)残差模块替换掉MSR2B(L=4)基准残差模块,并且为了公平比较,在保持其它实验参数固定的条件下进行了训练。以这3种模块为主干特征提取结构的条件生成对抗网络在GOPRO数据集上的测试结果见表2,视觉效果对比如图7所示,从中可以得出,本文提出的多尺度残差模块MSR2B在图像去模糊任务中非常有效。从客观评价结果上看,MSR2B模块相较于传统的ResNet模块提升较大,在测试集上的平均PSNR和SSIM分别提高了1.02 dB和0.01;相较于Res2Net(L=4)模块也有进一步地提高,在测试集上的平均PSNR和SSIM分别提高了0.26 dB和0.002。从视觉效果对比上看,使用ResNet模块的去模糊网络可以从严重模糊中恢复出图形结构,但是字符仍然不够清晰,人眼无法识别出图中的有效信息;使用Res2Net(L=4)模块的网络由于增强了多尺度特征提取能力,因此能恢复出较清晰的图像,但部分字符仍存在扭曲失真;MSR2B模块网络的多尺度特征表达能力进一步提升,恢复出了更丰富的图像纹理和细节信息,字符的边缘结构更加清晰。
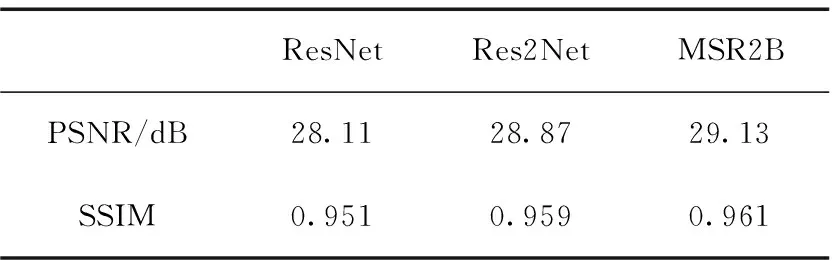
表2 不同残差模块之间的性能比较

图7 不同残差模块的去模糊效果对比
3.4 与其它方法对比
将本文的多尺度生成对抗网络与其它先进的方法在GOPRO和Köhler评估数据集上的结果进行对比,对比的方法包括:Pan等[4]提出的通过去除图像边缘的离群值来估计模糊核的传统盲去模糊方法;Sun等[22]使用CNN估计模糊核,并结合反卷积恢复图像的过渡方法;Nah等[7]使用基于分层级联网络的多尺度CNN,以端到端的方式进行去模糊的方法;以及Kupyn等[8]基于图像翻译思想而提出的条件生成对抗网络,采用深层残差网络进行不同尺度的特征提取,并以端到端的方式进行盲图像去模糊的方法。实验结果通过其发布的带有默认参数的官方代码实现或直接从其论文中得出。
表3中显示了不同方法在GOPRO和Köhler评估数据集上的客观评价结果,其中本文的去模糊方法在两个数据集上均达到了最佳PSNR和SSIM值。其中在GOPRO数据集上,相比于Nah等的多尺度级联网络,PSNR提高了0.2 dB,SSIM提高了0.05;相比于Kupyn等的方法在运行时间上减少了24%。在Köhler数据集上PSNR和SSIM相比于Kupyn等的生成对抗网络,分别提高了2.0%和2.5%。图8显示了本文和其它方法在GOPRO数据集上的去模糊视觉结果对比,从中可以看出,Nah等和Kupyn等的方法都取得了不错的去模糊效果,但是仍未能很好地恢复图像的纹理和细节特征,如图中标识牌的颜色、窗户的框架轮廓和广告牌上的文字等,本文方法则可以对其进行较好地恢复;在Köhler数据集上的视觉效果对比如图9所示,本文方法相比于Nah的方法能更为清晰地恢复图像,相比于Kupyn等的方法减少了图像中的伪影,并且显示出了良好的泛化能力。综上所述,本文方法可以更清晰、更真实地还原图像的边缘结构和纹理信息,同时处理速度更优。

表3 不同方法在测试集上的客观评价结果

图8 在GOPRO数据集上的视觉效果对比

图9 在Köhler数据集上的视觉效果对比
4 结束语
本文提出一种基于多尺度条件生成对抗网络的端到端图像去模糊方法,用以解决现有的方法中去模糊效果不佳和处理速度慢等问题。在生成器网络中,本文提出一种多尺度残差模块MSR2B作为主干特征提取结构,该模块通过扩展模块内部的精细感受野范围来表达多尺度特征;并进一步添加全局和局部的跳跃连接,来融合多尺度信息并提升网络的自适应特征表达能力。通过PatchGAN判别网络来表征和提取局部细节特征,并加速网络收敛。实验结果表明,本文提出的方法相比于以分层级联和加深深度作为多尺度策略的方法,去模糊效果更好并且运行速度更快。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
