
改进相位补偿结合谐波重构的语音增强方法
2022-04-21 08:01马建芬张朝霞
计算机工程与设计 2022年4期
崔 磊,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
语音增强的目的就是从含噪语音中去除背景噪声。但是多数语音增强方法仅关注幅度谱的优化,却忽视了相位信息对于语音的重要性。已有学者对相位信息的优化[1-5]进行了研究,其中最具代表性的就是Anthony P.Stark等提出的相位谱补偿函数,它将含噪语音幅度谱与优化过的相位谱重新结合来产生增强语音。但是这种方法有一个较大缺陷就是其补偿因子是一个固定值无法适应非平稳噪声的变化情况,这会对相位优化产生一定的影响。此外多数语音增强方法在降噪过程中由于语音的谐波结构遭到破坏会出现一定程度的语音失真。
针对传统相位改进方法中补偿因子无法改变以及降噪过程中出现的语音失真等问题,提出改进相位补偿结合谐波重构的语音增强方法。该方法利用先验信噪比来动态调整补偿因子。因目前大多数使用的先验信噪比估计算法[6-8]如直接判决算法、两步噪声消除算法、改进型直接判决算法等都存在一定的缺陷[9],而这些缺陷会导致先验信噪比的估计值较真实值存在较大误差,为解决这一问题本文采用深度学习模型[10,11]来估计先验信噪比。在此基础上针对在降噪过程中出现的语音失真采用谐波重构的方式对语音的谐波结构进行恢复,最终实现语音增强。通过实验对比,进一步探讨本文方法的性能。
1 传统相位谱补偿函数
假定x(t)表示纯净语音,z(t)表示噪声,x(t)和z(t)相互独立,t表示离散时间变量,则含噪语音y(t)可表示为
y(t)=x(t)+z(t)
(1)
对式(1)两边同时做短时傅里叶变换即可得含噪语音频谱Y(n,k),纯净语音频谱X(n,k),噪声频谱Z(n,k),Y(n,k)的极坐标形式表示如下
Y(n,k)=|Y(n,k)|exp(j∠Y(n,k))
(2)
其中,|Y(n,k)|表示含噪语音第n帧第k个频点的幅度信息,∠Y(n,k)表示含噪语音第n帧第k个频点的相位信息。
虽然相位信息可以有效提升语音质量,但是由于相位谱的高度非结构化特性,很难对相位进行直接估计,鉴于此Paliwal等提出了相位谱补偿方法,该方法可以利用噪声特性对含噪语音相位信息进行优化,相位谱补偿函数如下
(3)
其中,λ为补偿因子,φ(k)为如下所示判决函数
(4)

Y∧(n,k)=Y(n,k)+Λ(n,k)
(5)
其中,Y∧(n,k)表示补偿后的第n帧第k个频点的含噪语音频谱,对Y∧(n,k)取相位即可得到补偿后的相位谱
∠Y∧(n,k)=arg[Y∧(n,k)]
(6)
将补偿后的相位谱与含噪语音幅度谱结合即可得到增强语音频谱S∧(n,k)
S∧(n,k)=|Y(n,k)|exp(j∠Y∧(n,k))
(7)
传统的相位谱补偿函数中λ是一个固定值,一般取3.74。但是由于λ的固定性它无法反应噪声的实时变化情况,现实生活中大多数噪声都是非平稳噪声,简单的通过一个经验值无法很好的根据噪声的变化情况来确定该对相位谱进行何种补偿。
分析语谱图,图1(a)中的Clean是纯净语音,图1(b)中的Mixture是含噪语音,图1(c)中的PSC是使用传统相位谱补偿方法结合含噪语音幅度谱得到的增强语音。从语谱图中可以看出传统的相位谱补偿方法可以在一定程度上抑制噪声,但是整体效果并不理想而且失真现象较为严重,这一定程度上是由于结合了含噪语音幅度谱导致的,但是也能反应出传统相位谱补偿方法对于语音质量提高的局限性。
2 相位改进结合谐波重构的语音增强方法
相位改进结合谐波重构的语音增强方法主要分为3部分,第一部分是对相位谱补偿函数进行改进,第二部分是通过深度学习模型估计先验信噪比,第三部分是对增强后的语音进行谐波重构。
2.1 改进的相位谱补偿函数
传统相位谱补偿方法的关键在于补偿函数Λ(n,k),而补偿因子λ又是补偿函数中较为关键的一环。传统相位谱补偿方法中补偿因子是一个固定值,这会带来一个问题就是不能很好地根据噪声能量的变化情况对补偿因子做出动态调整,因此传统相位谱补偿方法会存在一定的不足。针对传统相位谱补偿方法中出现的问题,本文提出一种改进的相位谱补偿方法,该方法利用含噪语音先验信噪比这一参数对补偿因子进行优化,先验信噪比可以很好反应纯净语音和噪声的能量变化情况。将含噪语音先验信噪比与相位谱补偿函数相结合可以很好地通过信噪比变化情况动态调整相位谱补偿函数,所提出的改进的相位谱补偿函数中补偿因子如下
(8)
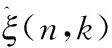
此外,补偿因子λnew中c的取值也会影响到增强语音的质量,经多次实验取c=7.5。将式(8)带入式(3)中得到新的相位谱补偿函数
(9)
结合式(9)和式(6)可以得到新的相位谱
∠Y∧new(n,k)=arg[Y∧new(n,k)]=
arg[Y(n,k)+Λnew(n,k)]
(10)
2.2 先验信噪比估计
传统的先验信噪比估计算法大多存在一定的不足,而改进的相位谱补偿方法对于相位谱的优化主要依赖于对先验信噪比的准确估计,为了更好地解决这一问题本文将采用Deep XI深度学习模型,其中Deep代表深度学习而XI代表先验信噪比。Deep XI模型是一种结合了残差网络[12]和时域卷积网络[13]可以有效针对先验信噪比估计的深度学习框架。Deep XI模型对于先验信噪比的估计主要包括两个阶段,第一阶段是从含噪语音幅度谱中估计先验信噪比的映射值,第二阶段是通过映射得到的先验信噪比计算先验信噪比估计值。Deep XI模型估计先验信噪比的语音增强方法实验框架如图2所示,它包括训练和增强两个部分,本文主要对训练部分的网络配置、特征提取、代价函数以及增强部分的语音合成进行简要介绍。

图2 Deep XI估计先验信噪比实验框架
2.2.1 网络配置
Deep XI模型的搭建参考了文献[10,11],模型首先是一个大小为256维的全连接层,该全连接层包含归一化层以及整流线性单元(ReLU)激活函数。全连接层后面跟40层残差结构,每层残差结构包含3个一维因果膨胀卷积层,每个卷积层通过层归一化和ReLU激活函数进行预激活,其中第一层卷积核为1,输出大小为64维,膨胀率为1;第二层卷积核为3,输出大小为64维,膨胀率随残差块指数增加2的幂次,若超过最大膨胀率,则再次循环;第三层卷积核为1,输出为256维,膨胀率为1。最后一个残差结构后面跟一个带有sigmoid单元的全连接层作为输出层,用来获得模型的输出。模型训练过程中使用的梯度下降参数优化算法为Adam,初始学习率为0.001。
2.2.2 特征提取
将纯净语音和噪声逐帧相加得到含噪语音,提取分帧后的含噪语音幅度谱|Y(n,k)|作为网络的输入。
2.2.3 代价函数
Deep XI模型使用的代价函数为sigmoid交叉熵函数,具体定义为
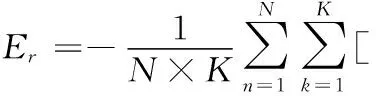
(1-ξ(n,k))ln(1-ξp(n,k))]
(11)
其中,N表示总帧数,K表示每一帧包含的样本点数,ξp(n,k)如下式所示
(12)

(13)
其中,λz(k)代表噪声方差,λx(k)代表纯净语音方差。
2.2.4 语音合成

(14)
将含噪语音频谱Y(n,k)与维纳滤波增益函数G(n,k)相乘,即可得到增强语音频谱S(n,k),公式如下
S(n,k)=Y(n,k)×G(n,k)
(15)

(16)
其中,|S(n,k)|表示增强语音频谱S(n,k)的幅度谱,最后通过傅里叶逆变换得到时域上的增强语音。
2.3 谐波重构
目前通过单声道语音增强方法得到的增强语音中都会存在一定的语音失真,这是因为语音的浊音中包含了与语音相关的大部分信息,而浊音的功率是随着频率的增加而减小,由于浊音的功率小,它的组成部分会被视为噪声而被抑制,特别是在高频下这种情况尤为严重[14],为了解决这一问题,本文采用谐波重构的方法,而谐波重构的目的就是为了将被抑制的谐波分量重新恢复。

(17)
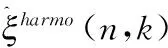
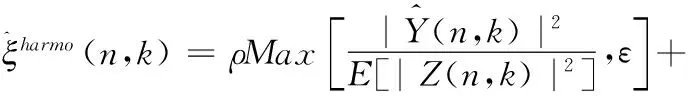

(18)
其中,ρ(0≤ρ≤1)是权重因子,ε是偏置值取0.8,E[|Z(n,k)|2]代表噪声的功率谱。因为维纳滤波增益函数G(n,k)的取值范围也是0到1,而且增益函数G(n,k)是由先验信噪比计算得到的,可以较好地反应噪声能量的变化情况,因此本文使用增益函数G(n,k)来代替权重因子ρ。则式(18)可以改写为如下形式

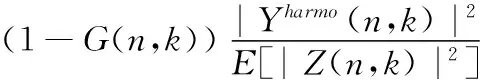
(19)
其中,维纳滤波增益函数G(n,k)是通过第一步基于相位改进的语音增强方法计算得到的,此外权重因子ρ的取值越小计算得到的先验信噪比估计值越精确,如果直接使用增益函数G(n,k),当信噪比值较高也就是在非噪声段的时候增益函数G(n,k)的取值会逼近1,这会影响到最终求得的先验信噪比估计值的精确度,因此对式(19)进行改进得到最终的先验信噪比求解公式
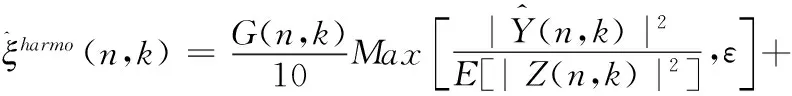
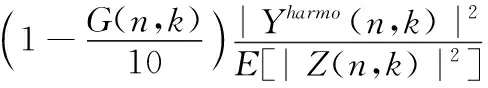
(20)
将增益函数G(n,k)的取值范围缩小至0到0.1之间,这样就可以保证不管信噪比是如何取值,最终得到先验信噪比估计值的精确度都不会有较大幅度的波动。
(21)
得到增强语音频谱后通过傅里叶逆变换即可得到最终的增强语音。
3 实验和结果分析
3.1 实验配置
实验中训练集和测试集的纯净语音均来自TIMIT语料库,其中TIMIT语料库中的训练集共有4620条纯净语音,测试集中共有1680条纯净语音,一共有6300条纯净语音。训练集和测试集的噪声均来自NOISEX-92语料库,NOISEX-92语料库中共有15种噪声。在4种信噪比(-5 dB,0 dB,5 dB,10 dB)条件下,通过将TIMIT语料库训练集中选取的3000条纯净语音与NOISEX-92语料库中选取的4种噪声(Pink,F16,Volvo,Factory1)相结合,可以得到包含48 000(3000×4×4)条含噪语音的训练集,将其中的2400条含噪语音设置为交叉验证集。为了使实验更符合真实情况,在上述4种信噪比条件下,选取在训练集中不匹配的噪声类型,即NOISEX-92语料库中的3种噪声(Factory2,White,Babble),同时选取TIMIT语料库中测试集的400条纯净语音结合得到一个包含4800(400×3×4)条含噪语音的测试集。实验中所有的纯净语音和噪声的采样率均为16 KHz。对信号分帧,加窗,其中帧长为32 ms(512个采样点),帧移为16 ms(256个采样点),并对分帧后的信号进行短时傅里叶变换,可将信号从时域转换到频域。
3.2 评价方法
语音增强性能评价指标采用语音质量感知评价(perce-ptual evaluation of speech quality,PESQ)和语音可懂度评价(short-time objective intelligibility,STOI)。语音质量感知评价代表人在听语音时的舒适程度,语音可懂度评价代表人对于语音的可理解程度,其中PESQ得分在-0.5~4.5之间,得分越高代表增强语音的质量越好。STOI得分在0~1之间,得分越高代表语音的可懂度越好。
3.3 评价结果
为了验证本文所提出的改进相位补偿结合谐波重构的方法可以进一步提高语音增强性能,将本文所提方法与3种对比方法进行比较,含噪语音表示为Mixture,3种对比方法分别为不对相位进行处理的Deep XI语音增强方法简称为Method_A,该方法通过Deep XI模型直接估计先验信噪比,并将估计得到的先验信噪比用于维纳滤波增益函数并对含噪语音进行增强;传统的相位谱补偿方法简称为Method_B;sigmoid型相位谱补偿方法[15]简称为Method_C;本文提出的改进相位补偿结合谐波重构的语音增强方法简称为Method_D。其中传统的相位谱补偿方法和sigmoid型相位谱补偿方法结合的增强语音幅度谱均是通过Deep XI模型获取到先验信噪比估计值后构建维纳滤波增益函数,将维纳滤波增益函数与含噪语音幅度谱相乘得到的。
表1列出了在3种噪声(Factory2,White,Babble)以及每种噪声对应的4种信噪比(-5 dB,0 dB,5 dB,10 dB)下,本文所提方法与3种对比方法的PESQ得分情况。从表1中可以看出在Factory2噪声下Method_D比Method_A的PESQ得分提升了13%,比Method_B提升了9%,比Method_C提升了4%;在White噪声下Method_D比Method_A提升了11%,比Method_B提升了8%,比Method_C提升了3%;同样在Babble噪声下Method_D比Method_A提升了11%,比Method_B提升了8%,比Method_C提升了4%。从数据中分析可知所提方法在不同的噪声环境,不同的信噪比情况下均取得了较其它3种对比方法更好的PESQ得分,这是因为本文所提方法不仅仅只针对含噪语音幅度谱进行处理,容易被忽视的相位信息在本文中也得到了相应的处理,同时得益于Deep XI模型强大的学习能力能够更准确地估计先验信噪比,本文所提方法对相位的优化要好于对比方法。
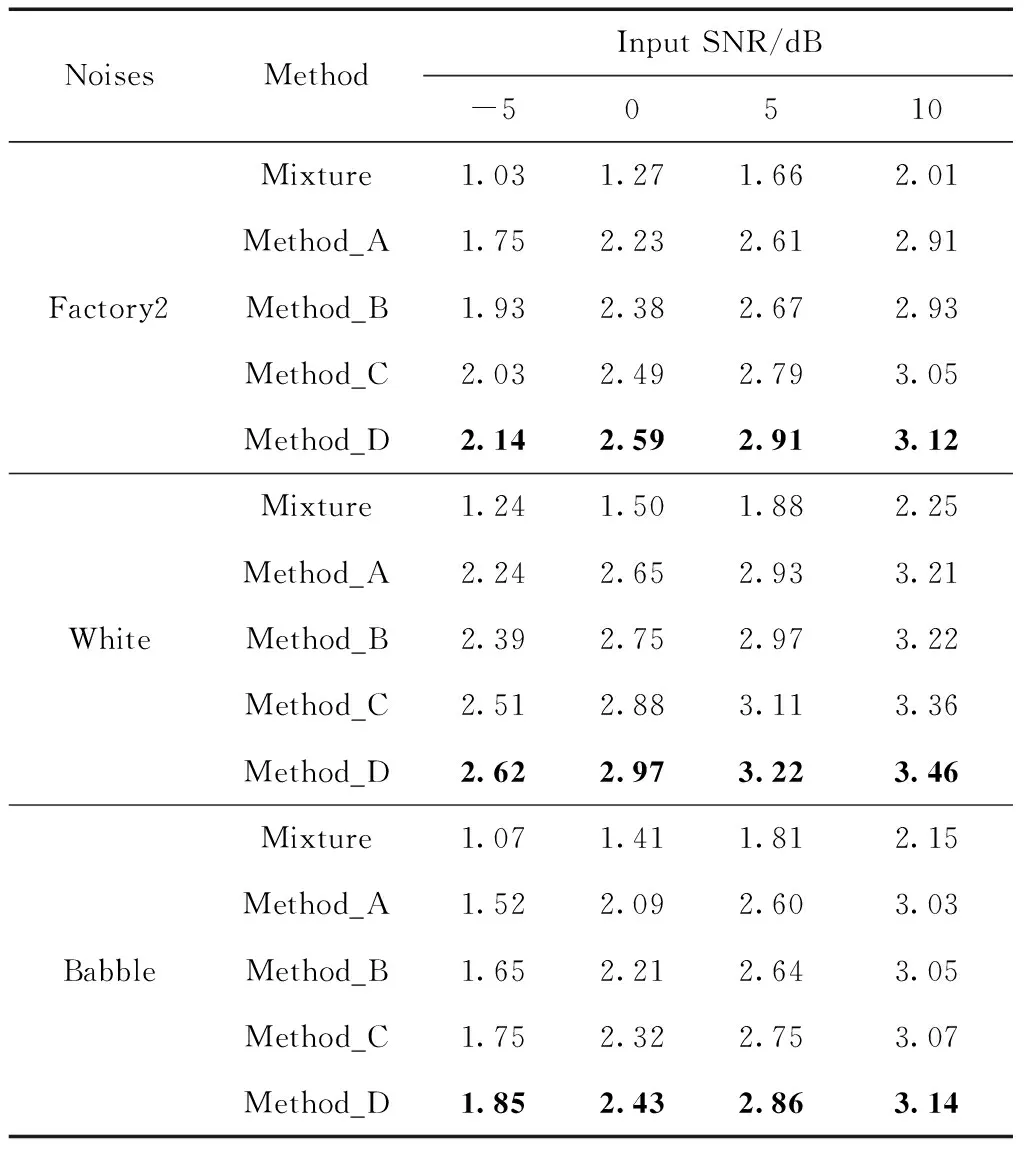
表1 4种方法在不同噪声不同信噪比情况下的PESQ得分
表2给出了本文所提方法与3种对比方法的STOI得分情况,分析表2数据可知Method_A,Method_B和Method_C的STOI得分相差不大,在某些情况下数据甚至相等,这是因为在幅度谱保持一致的情况下,增强相位信息并不会对可懂度的提升有较大影响,相位信息更多的是在影响语音的质量,但是Method_D不仅考虑对相位进行改进,同时对增强后的语音进行谐波重构,尽可能地恢复在增强过程中被抑制的谐波分量,有效减少了语音失真,对语音可懂度的提升有一定帮助。
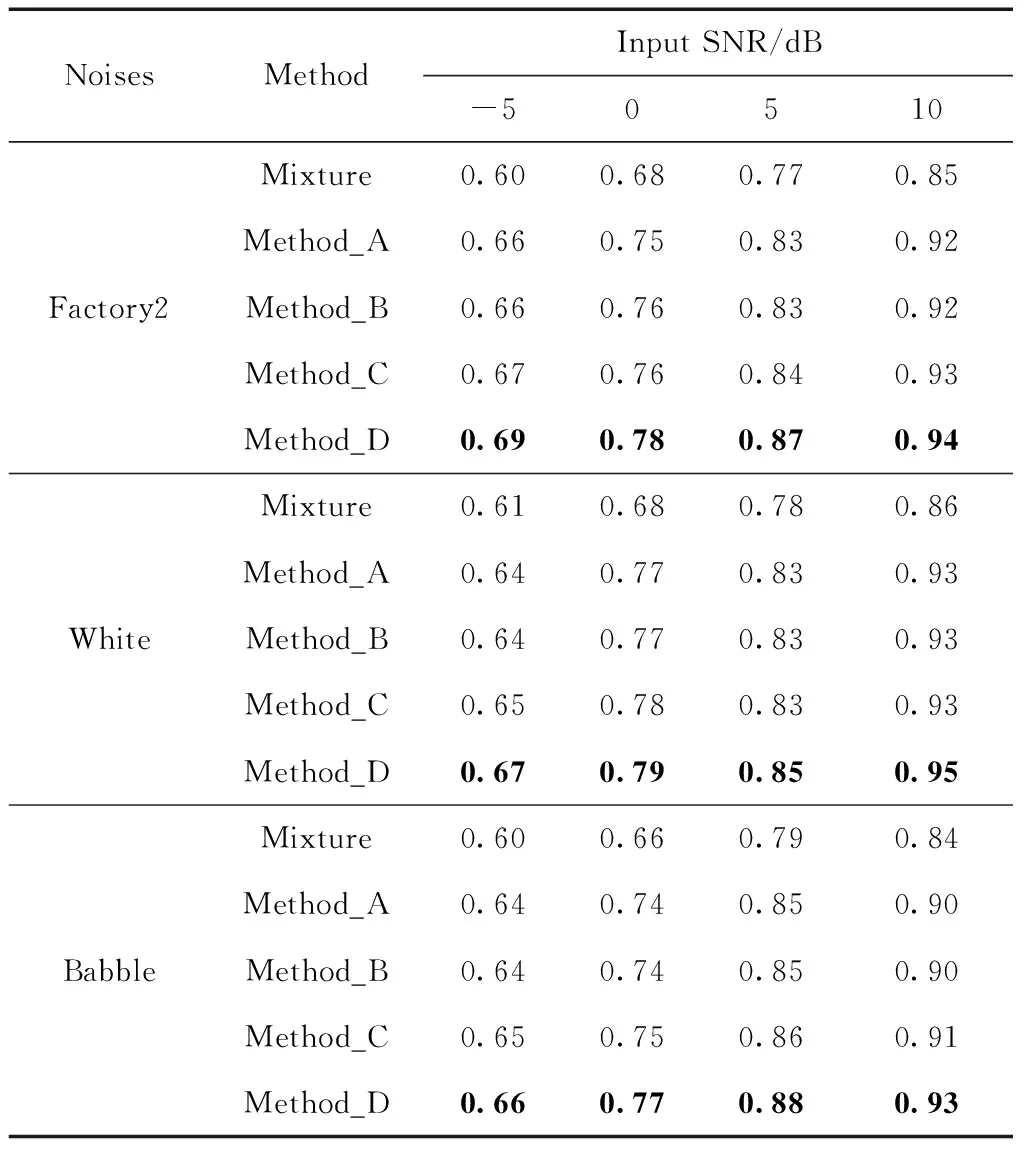
表2 4种方法在不同噪声不同信噪比情况下的STOI得分
图3以柱状图的形式更直观地展示了Method_A,Method_B,Method_C和Method_D的PESQ均值。从图3中可以明显看出,Method_D与3种对比方法相比取得了明显的提升。结合表1数据可知这种提升在低信噪比下尤为明显,当信噪比较高时由于相位信息对语音质量的影响较小,对相位的改进不会带来明显的语音质量的提升,但是本文提出的方法在高信噪比下也取得了不错的增强效果。

图3 各方法PESQ均值
图4表示TIMIT语料库中的一条纯净语音Clean,SNR=5dB的含噪语音Mixture,以及Method_A,Method_B,Method_C和Method_D这4种不同方法得到的增强语音的语谱图。从图4的语谱图中可以看出,相比图4(a)中的纯净语音,图4(c)、图4(d)、图4(e)中的增强语音虽然残留噪声较少,但是语音的谐波结构较图4(a)有一定差距,同时可以看到图4(f)中增强语音的谐波结构较3种对比方法更接近于图4(a)。这表明所提方法确实可以更好地恢复谐波结构进而提高增强语音的可懂度。

图4 不同增强方法语谱图对比
4 结束语
本文提出一种改进相位补偿结合谐波重构的语音增强方法。实验结果表明,所提出的语音增强方法相比于不对相位进行处理的方法以及其它对于传统相位谱补偿函数进行改进的方法在语音质量和可懂度方面有明显提升。同时本文所提方法具有普适性,可与任何幅度谱估计方法相结合,最终得到的增强语音在质量和可懂度方面均会优于单独使用幅度谱估计方法得到的增强语音。
但是本文所提方法也存在一定不足,先验信噪比估计精确度的提升是通过深度学习模型以大量的训练时间为代价。未来将继续寻找一种轻量级模型,在不降低精确度的前提下缩短训练时间。
猜你喜欢
中国卫生统计(2022年2期)2022-05-28
现代仪器与医疗(2022年1期)2022-04-19
文化创新比较研究(2020年13期)2021-01-14
矿山测量(2020年2期)2020-05-17
天津外国语大学学报(2020年1期)2020-03-25
北京航空航天大学学报(2019年9期)2019-10-26
雷达学报(2017年3期)2018-01-19
岁月(2016年5期)2016-08-13
探测与控制学报(2015年4期)2015-12-15
雷达与对抗(2015年3期)2015-12-09
