
利用时变经验模态分解的主干道短时交通量预测
2022-04-21 12:42赵磊娜王延鹏邵毅明李淑庆温欣雨
重庆交通大学学报(自然科学版) 2022年3期
赵磊娜,王延鹏,邵毅明,李淑庆,温欣雨
(1. 重庆交通大学 数学与统计学院,重庆 400074; 2. 重庆交通大学 交通运输学院,重庆 400074)
0 引 言
短时交通量预测是智能交通系统中的关键技术之一,其预测精度对智能交通系统性能起决定性作用[1]。目前,常用的短时交通量预测方法大致分为:数据驱动模型和混合/融合预测模型,其中数据驱动模型分为参数模型与非参数模型[1-2]。参数模型包含:差分自回归移动平均模型(ARIMA)、季节性差分自回归移动平均模型(SARIMA)[3-6]、卡尔曼滤波模型[7-8]和历史平均模型[9]等;非参数模型包含:深度学习模型[10-14]、支持向量机(SVM)[15-16]和最小二乘支持向量机[17]等。M.SABRY等[18]利用1990—2002年的街道年、月、周平均日交通量数据集拟合了ARIMA预测模型,预测了埃及某条公路的交通量;S.V.KUMAR等[19]以印度金奈市某条3车道的主干道为例,基于SARIMA模型进行了短时交通量预测;I.OKUTANI等[20]使用卡尔曼滤波模型进行交通量预测时,引入了预测路段和相邻路段之间的影响关系,提高了模型的预测准确率;G. N. POLSON等[21]和T. PAMULA[22]分别研究了深度学习体系结构预测短时交通量。然而数据驱动模型在实际应用中存在一定局限。例如:时间序列模型很难解释数据的非线性;卡尔曼滤波模型中的参数选取需要靠经验;深度学习模型在使用时容易出现过拟合或欠拟合现象。基于数据驱动模型的预测精度很难满足实际应用需求,因此众多学者致力于混合/融合预测模型研究。
混合/融合预测模型是将不同的数据与模型按一定特征规律进行组合,联合不同数据及模型的优势,从而达到提高短时交通量预测精度的目的。TNAG Jingjun等[23]、赵阳阳等[24]、TIAN Xiujuan等[25]分别将经验模态和集合经验模态分解并与预测模型相结合,进行了交通量与客流量预测,然而这两种数据分解方法存在端点效应问题,很难将数据特性解释清楚。部分学者认为交通量数据具有一定的时间依赖性,并采用去趋势方法结合预测模型进行预测。FENG Shuo等[26]、LI Li等[27]、LI Zhiheng等[28]、DAI Xingyu等[29]、YANG Bailin等[30]分别利用去趋势波动分析法分析了交通量的时间特性,对提升交通量预测精度产生了积极影响,但该方法不适合用于解释数据中暗含的统计特性;ZHANG Weibin等[30]和N. N. L. DO等[31]分别考虑了交通量的时空特性,挖掘交通量与时间和空间相关性,优化了预测模型,但没有充分考虑交通量数据自身的特征。随着大数据不断发展,部分学者将大数据分析与数据融合方法应用于短时交通量预测的研究中。LI Li等[33]、GUO Fangce等[34]、LYU Yisheng等[35]分别构建了基于大数据和数据融合方法的预测模型,在一定程度上提高了预测精度,但该类方法需要大量的数据样本且效率较低。综上所述,现阶段短时交通量预测模型还存在部分问题需进一步改善:缺乏合理方法与模型解释短时交通量数据存在的非线性与非平稳性;预测精度还未满足智能交通系统需求,需进一步优化提高。
基于数据分解的混合模型属于混合/融合预测模型,该类模型逐渐成为研究热点[36],模型中的数据分解方法能很好地解释数据非平稳与非线性特性,从而提高预测精度。因此,笔者采用时变滤波经验模态分解(TVF-EMD)方法[37],结合LSSVM模型进行短时交通量预测。与传统数据分解方法相比,该方法运用时变滤波技术,可准确描述数据的时变特性,改善模态混合现象发生,增强处理数据非平稳性与非线性能力,优化交通量数据分解效果,有助于提高短时交通量预测精度。
1 基本理论
1.1 时变滤波经验模态分解
传统数据分解方法(例如经验模态分解与集合经验分解)存在一定缺陷,经常会出现分解过度或分解不彻底的情况。数据过度分解,会造成原始数据特征被破坏,影响数据分解效果;分解不彻底,会造成特征混合现象,无法解释清楚数据特性。时变滤波经验模态分解方法(TVF-EMD)能改善传统数据分解方法中存在的弊端[37]。该方法通过收敛准则,自适应确定分解层数,用局部窄带信号代替固有模态函数(IMF),局部窄带信号不仅与IMF性质相似,还可提供一个有物理意义的希尔伯特谱。该方法筛选过程由时变滤波来完成,对于给定任意多分量信号x(t),可表示为一个双分量信号,如式(1):
x(t)=A(t)ejφ(t)=a1ejφ1(t)+a2ejφ2(t)
(1)
故只需考虑双分量信号的分解过程,对双分量信号进行时变滤波经验模态分解的基本步骤如下:
1)利用希尔伯特变换计算输入信号x(t)的瞬时幅值A(t)及瞬时频率φ′(t),如式(2)、式(3):
(2)
(3)

2)确定A(t)的最大值tmax与最小值tmin。
3)对A(t)的极值点分别进行插值,所得曲线分别为β1(t)、β2(t)。
4)根据式(4)计算出瞬时均值a1(t)和瞬时包络a2(t)。
(4)
5)令式(5):
(5)
(6)
6)根据调整后的截止频率重构信号,如式(7):
(7)
将h(t)的极值点作为节点,将h(t)分成n段,每段步长为m,其中n被称为B样条函数的阶数。用式(8)进行B样条插值逼近,逼近结果记为m(t),代表局部均值曲线。
(8)
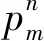
7)因局部窄带信号定义与瞬时带宽密切相关,在此基础之上,TVF-EMD制定了判断瞬时窄带信号的相对准则。
ξ为带宽阈值,若θ(t)≤ξ,则信号可认为是窄带信号。加权平均瞬时频率φavg(t)与瞬时带宽BL的计算如式(9)~式(11):
(9)
(10)
(11)
经过上述步骤分解过后,原信号由如式(12)表达。
x(t)=∑cj(t)
(12)
式中:cj(t)为分解后的子序列。
1.2 最小二乘支持向量机
最小二乘支持向量机(LSSVM)是对支持向量机(SVM)模型的一种改进,将标准SVM模型中的不等式约束条件改为等式约束条件,将误差平方项作为训练的损失函数,使得凸二次规划问题转化为解线性方程组[38]。
设D=(xi,yi),i=1, 2,…,n为样本集,xi∈Rm为输入;yi∈R为对应的输出。假定训练部分{(x1,y1), (x2,y2),…, (xn-m,yn-m)}为n-m个数据集组成,m为xi的维度,具体数值选取可通过训练部分输出值的均方根误差最小化原则来确定[39];对应的输出为yi=x(i+m)。
LSSVM回归函数可表示如式(13):
f(x)=ωTφ(x)+b
(13)
式中:φ(·)为非线性函数;ω为权向量;b为偏置量。
LSSVM回归优化目标函数如式(14):
(14)
式中:ei为误差变量;μ和ξ分别为可变参数。
为求解上述优化问题,构建Lagrange函数,如式(15):
(15)
式中:αi为Lagrange乘子。
由此可得式(16):
(16)
式中:惩罚系数γ=ζ/μ。
消除ei和ω后,原优化问题变为式(17):
(17)
式中:Ωij=φ(xi)Tφ(xj)=K(xi,xj);l=[1,…,1]T;Y=[y1,…,yN]T。
通过式(16)求出α和b,那么LSSVM回归函数可改写如式(18):
(18)
式中:K(x,xi)为需要符合Mercer条件的核函数。
核函数包括径向基核函数(RBF)、Sigmoid核函数和多项式核函数等。RBF核函数也称为高斯核函数,该函数需要设置的参数较少,非线性学习能力强,是最有效的核函数之一。故笔者选择的核函数为RBF核函数[40],如式(19):
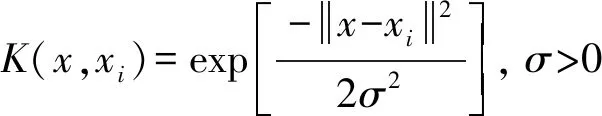
(19)
2 混合预测模型
笔者采用TVF-EMD方法处理具有非平稳性与非线性的短时交通量数据。短时交通量数据经过TVF-EMD分解后,得到多个具有不同特性的窄带子序列。该窄带信号与EMD分解后的本征模态方程(IMF)性质相似,可进一步开展建模分析。针对分解后的子序列,分别建立核函数为RBF的LSSVM模型。其中:基于子序列展现出不同的尺度波动性,选取最合适的核函数参数σ和惩罚系数γ,进而获得预测值。TVF-EMD-LSSVM混合模型具体流程如图1。

图1 预测流程Fig. 1 Forecasting procedure
步骤如下:
第1步:为针对短时交通流数据中的非平稳性,采用TVF-EMD方法将原始数据分解为一系列具有不同特性的子序列{cj(1),…,cj(n)},j=1, …,M+1,如式(12)。相比原始数据而言,子序列更为规则、平稳;
第2步:将实验数据分为两个部分,包括训练部分和测试部分,其中训练部分是为了建立模型,测试部分是为了开展模型性能评估;

3 案例应用与结果分析
3.1 数据说明
短时交通量数据来源于重庆市主城区某主干道的路口,数据统计间隔为5 min,连续7 d共2 016个交通量数据。运用相邻补齐法对错误数据与丢失数据进行修复[41];其次用前2/3的数据对模型进行训练,剩余1/3的数据进行测试,交叉口进口道原始交通量序列如图2。

图2 短时交通量时间序列Fig. 2 Short-time traffic volume time series
3.2 数据特性分析
在预测问题研究中,数据特性的准确分析对预测模型选择至关重要。合适的预测模型不仅可提供满意的预测精度、改善结果可靠性,还能降低错误预测所带来的负面影响。故笔者采用均值、方差、最大值等指标对短时交通量数据特性进行定性与定量分析,如表1。

表1 数值特性Table 1 Numerical characteristics
表1中:进口短时交通量最大值为246,最小值为0,数据均值、方差较大,波动性较大,非平稳性与周期性较强;偏度不为0、峰度不为3,反映出数据具有一定的非高斯性。
3.3 评价准则
为更好地分析与评价TVF-EMD-LSSVM模型的预测效果,笔者选取的评价指标为:平均绝对误差(MAE)、平均相对百分比误差(MRPE)、均方根误差(RMSE)、均方根相对误差(RMSRE)和均等系数(EC),其计算如式(20)~式(24):
(20)
(21)
(22)
(23)
(24)

MAE、MRPE、RMSE、RMSRE越小,预测误差越小,EC越接近于1,说明预测值与实际值之间拟合度越好,演化趋势越相似。
3.4 案例应用
运用TVF-EMD对短时交通量数据进行信号分解处理,得到10个子序列,如图3。分别对10个子序列建立最小二乘支持向量机(LSSVM)模型进行预测。确定非线性回归函数。
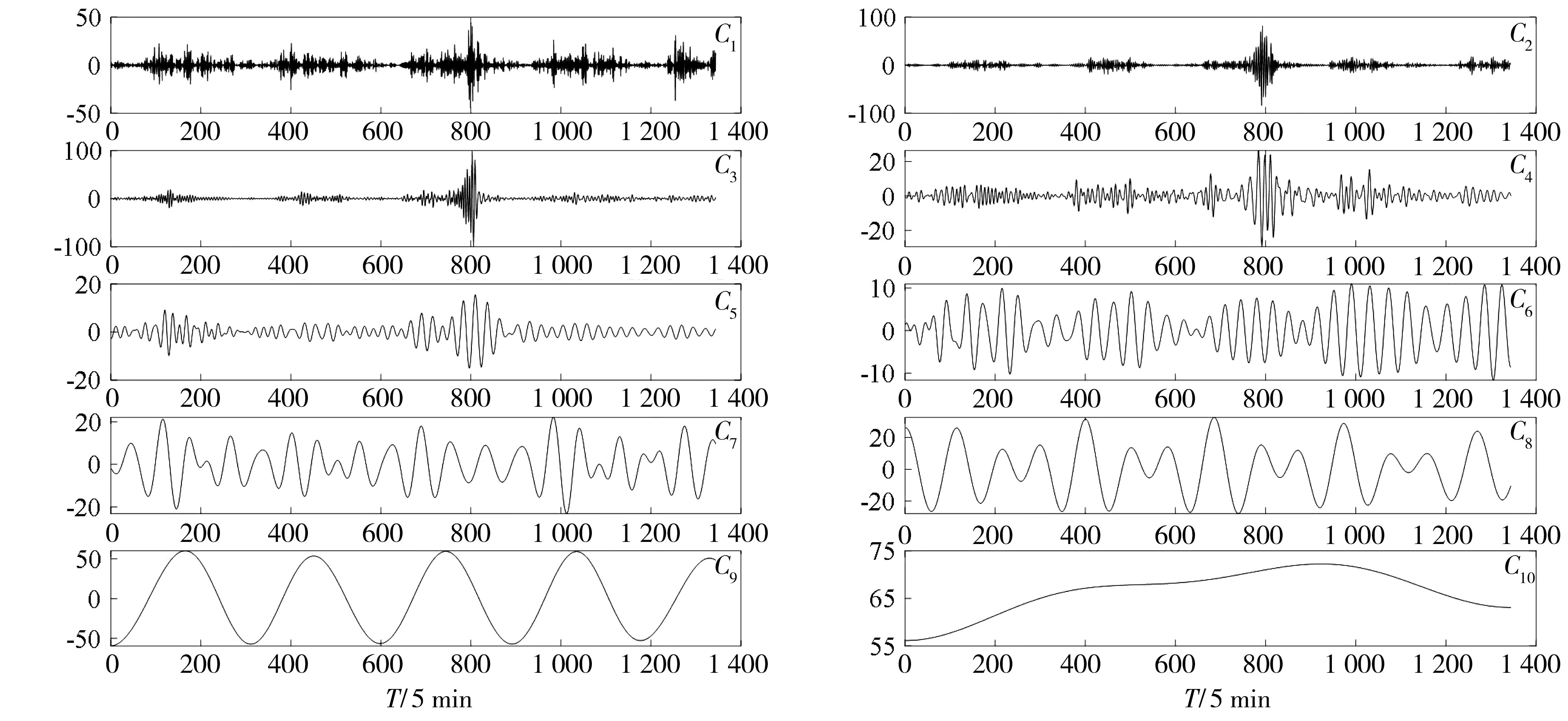
图3 TVF-EMD分解结果Fig. 3 TVF-EMD decomposition results
文中选择径向基核函数为最小二乘支持向量机模型的核函数,故非线性回归函数可改写如式(25):
(25)
LSSVM模型每次更新训练集后,上述参数需要重新计算,计算量大并且较为复杂。因此,笔者以c1序列为例重点分析最后一次计算得到的相关参数信息。
第1步:构建训练集,将数据前2/3的部分(1 344个)用于模型训练,即k=1 344。
第2步:确定维度g,构建输入输出。训练集输入、输出的构建形式如式(26)。根据已有研究成果,维度g在2~18范围内选取不同的值对输入数据进行试算,当训练集输出结果的均方根误差最小时,对应g的取值即为最佳维度[38]。经过试算,c1=17。

(26)
第3步:确定惩罚系数γ与核函数参数υ的值。利用网格搜索法,以误差最小为目标,得出惩罚系数γ=2.334×109与核函数参数υ=22 688。
第4步:求解α、u。确定了惩罚系数γ与核函数参数υ后,通过MATLAB软件,求出u=-57.746以及α值。将计算所得参数代入回归函数中求出预测值,并更新训练集。
第5步:重复上述步骤,得出最终的预测值。同理,对子序列c2~c10进行预测,得出最终的预测结果。
为证明新建模型TVF-EMD-LSSVM的优势,笔者选取3种模型进行对比[42-43],分别为ARIMA、LSSVM和EMD-LSSVM。ARIMA模型属于数据驱动模型中的参数模型,具有结构简单,计算方便的特点,常用于预测具有线性特征的数据;LSSVM模型属于数据驱动模型中的非参数模型,具有相对较低的计算复杂度和较高的泛化性能,预测含有非线性和非平稳性成分的短时交通量数据具有一定优势,被广泛应用于交通信息预测领域;EMD-LSSVM模型是常用的混合预测模型,在以往研究中进行了多次应用。上述3种模型是数据驱动模型以及混合预测模型中具有一定代表性的模型。这3种不同模型的评价指标结果如表2,预测结果如图4。

表2 不同方法预测精度对比分析Table 2 Comparative analysis of prediction accuracy ofdifferent methods

图4 不同预测方法预测结果Fig. 4 The prediction results of different prediction methods
3.5 预测结果分析
1)由图4和表1可看出:TVF-EMD-LSSVM模型的拟合效果非常好;5个评价指标分别为MAE=0.654,MRPE=1.303%,RMSE=1.118,RMSRE=2.118%,EC=0.993 3。这与EMD-LSSVM模型相比,5项指标分别相差5.462、10.630%、7.510、15.123%、0.045 4。评价结果表明:TVF-EMD-LSSVM模型采用时变滤波技术,能形象描述数据的时变特性,同时可解决EMD-LSSVM模型存在的模态混合问题,处理数据中的非平稳性和非线性成分能力更强,使得其分解结果更适合用来预测,大大提高了预测精度。
2)TVF-EMD-LSSVM模型与EMD-LSSVM预测精度高于LSSVM模型。LSSVM模型的评价结果为:MAE=9.840,MRPE=20.250%,RMSE=14.709,RMSRE=33.675%,EC=0.911 2。与TVF-EMD-LSSVM模型相比,5项指标分别相差9.186、18.947%、13.591、31.557%、0.082 1;与EMD-LSSVM模型相比,5项指标分别相差3.724、8.317%、6.081、16.434%、0.036 7。因为短时交通量数据具有较强的非平稳特征,TVF-EMD-LSSVM模型与EMD-LSSVM模型能降低数据中非平稳性对预测精度的干扰,故TVF-EMD-LSSVM模型与EMD-LSSVM模型预测精度高于LSSVM模型。
3)ARIMA模型的5个评价指标结果分别为:MAE=10.244,MRPE=20.988%,RMSE=14.730,RMSRE=32.955%,EC=0.911。与TVF-EMD-LSSVM模型相比,5项指标分别相差9.590、19.685%、13.612、30.837%、0.082 3。因案例所用数据具有非线性,ARIMA模型不善于预测具有非线性的交通数据,所以预测精度不高。
4 结 论
1)短时交通流数据具有较强的非平稳和非线性特性。相比ARIMA模型而言,LSSVM模型具有较高的预测精度。不同于ARIMA模型仅能描述数据中的线性特性,LSSVM模型能较好的解释数据中的非线性特性,因而数据具有显著的非线性特性。此外,比较LSSVM模型和TVF-EMD- LSSVM模型,进一步验证了数据含有明显的非平稳特性。
2)相比原始的EMD数据处理方法而言,TVF-EMD的分解结果更适应于短时交通流预测,预测精度更高。TVF-EMD-LSSVM模型数据处理方法采用低通滤波器提取数据特征,并重新建立了停止准则,改善了EMD分解方法应对具有强非平稳性和非线性交通量数据时存在的模态混叠及端点效应问题,提高了数据分解的质量。
3)对于具有非线性与非平稳性特性的短时交通量数据而言,TVF-EMD-LSSVM模型精度明显好于传统单一预测模型。不同于单一模型往往只能解释数据某种或某一类特性,TVF-EMD-LSSVM模型能同时解释短时交通量数据中的非线性与非平稳性,因而具有较好的预测可靠性。
4)TVF-EMD-LSSVM模型为短时交通量预测提供了一种新的预测方法,在理论层面上设计较为完整,同时在实际应用中预测精度较高。然而,上述方法仅能提供确定性的预测结果,无法考虑短时交通流数据中不确定性因素的影响。为此,有必要开展短时交通流概率预测研究,进而为后续风险评估提供理论指导。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
茶道(2022年3期)2022-04-27
汽车工程师(2021年12期)2022-01-17
中学生数理化·高一版(2021年11期)2021-09-05
成长·读写月刊(2018年8期)2018-08-30
CHIP新电脑(2017年6期)2017-06-19
筑路机械与施工机械化(2016年3期)2016-03-22
水运管理(2015年6期)2015-07-01
商业文化(2014年7期)2014-10-21
现代电子技术(2014年20期)2014-10-14
