
基于异构集成模型的个人信用评估研究
2022-04-19 00:47:24张承钿何浩龙许建龙
计算机仿真 2022年3期
张承钿,何浩龙*,许建龙
(1. 汕头大学计算机系,广东 汕头 515000;2. 汕头大学智能制造技术教育部重点实验室,广东 汕头 515000)
1 引言
传统的以信用卡信息为基础的个人信用评估方法已不能满足银行金融产业发展的需要,由于个人信用评估数据集存在非均衡性,数据集中信用良好的客户远远大于信用较差的客户,利用传统的机器学习分类算法很难得到令人满意的分类结果,因此个人信用分类问题的研究重点之一在于解决数据的非均衡性[1]。
国内外许多学者针对非均衡数据分类问题进行了大量的研究,并提出了各种解决方法。文献[2]提出利用聚类算法对多数类样本进行欠采样抽取,获取与少数类样本数量相同的多数类样本构成新的数据集。文献[3]提出一种基于迭代提升欠采样的集成学习方法,通过多次采样并迭代不断修正抽样概率,最后从中选择最好的分类器。彭敏等[4]提出一种基于SVM聚类的欠采样方法,通过对多数类样本进行层次的欠采样,可以在不影响多数类样本的基础上提高少数类样本的分类效果。Napierala K等[5]提出一种基于类标签的方法,通过标注少数类样本权重,最后提高分类准确率。以上这些研究表明,有效的非均衡数据处理方法可以提高分类的准确率。
在个人信用评估方面,已经有许多研究人员使用统计学、机器学习的方法来构建个人信用评估模型[6]。常用的机器学习方法有逻辑回归(Logistic Regression,LR),支持向量机(Support Vector Machine,SVM),决策树(Decision Trees,DT)等。
基于以上的分析,本文提出一种基于异构集成模型(Heterogeneous Ensemble Model,HEM)算法用来提高个人信用风险评估的准确率[7]。模型首先采用重复随机欠采样的方法将训练集中的少数类样本与等量多数类样本划分成多个训练集,划分后每个训练集都是多数类和少数类别相等的数据集。接着将每个训练集输入到各个不同参数的XGBoost模型中进行训练,利用XGBoost模型中生成的提升树叶子结点得到新的特征向量。然后将新生成的特征和原来的训练集合并生成新的训练集,输入到各个参数不同的LR模型中训练生成不同的基分类器。接着输入测试集,让每个LR基分类器进行分类预测并对结果进行集成,最终得到该异构集成模型的预测结果。
2 不平衡数据集处理
个人信用评估数据集存在好坏客户数据不均衡问题,由于数据集中的多数类样本数量远远大于少数类样本,导致在训练时,分类结果往往偏向于多数类样本而容易忽略少数类样本,造成预测结果存在误差[8]。解决数据不平衡问题的方法主要有过采样、欠采样和混合采样。
2.1 EasyEnsemble欠采样方法
EasyEnsemble采样方法通过欠采样抽取将数据集中的多数类样本随机划分成与少数类样本相等的若干个子集,每个子集分别与少数类合并生成新的数据子集。这样使得每个数据子集都是类别均衡的数据集,并且集成后总的数据集信息量并没有减少[9]。
2.2 产生训练子集
首先确定数据集中少数类样本总数t,采用欠采样方法从总的训练集D={(x1,y1),(x2,y2),…,(xm,ym)}中随机采样t个多数类样本(采样每个子集时使用不放回采样),将这些少数类样本和随机采样的多数类样本组成多个新的训练子集D1,D2,…,Dn。
每个训练子集虽然都是由欠采样抽样生成的,但是总的数据集却没有丢失重要信息,因此可以采用这种方法解决数据不均衡问题[10]。
3 异构集成模型
异构集成模型(HEM)算法是Bagging算法的一种扩展,其基本思想是通过对原始数据集多次抽样,输入不同参数在这些子集上训练出不同的基分类器,最后融合这些基分类器,按简单平均方法输出分类结果。由于不同模型的基分类器之间存在一定的差异性,各自生成的分类决策边界不同,因此,在基分类器融合后可以得到更加清晰地边界。从模型的整体角度看,融合更加清晰地边界有利于减少模型的分类错误,从而得到更好的预测结果。
3.1 XGBoost方法
XGBoost是由陈天奇博士提出的极端梯度提升树类算法,它是在GDBT(Gradient Boosting)算法的基础上提出的支持多线程并行计算模型,通过迭代和减少残差的方向生成新的树,组成一个准确率高的强学习器。
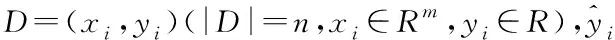
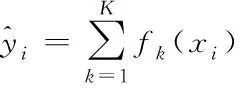
(1)
式(1)中,xi表示第i个特征向量,fk表示第k个子决策树模型。为了学习到模型函数,模型引入的目标函数为

(2)
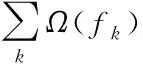
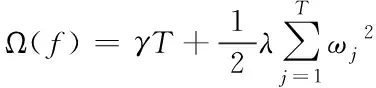
(3)
式(3)中,γ为树惩罚正则项,具有前剪枝的作用,抑制结点向下的分裂;λ为叶子权重惩罚正则项,在计算分割点增益时可以起到平滑的作用;T为树总的叶子结点个数;ωj为第j个叶子结点的权值。通过对式(2)目标函数L的二阶泰勒公式展开,其中一阶导数部分为

(4)
泰勒二阶导数部分为
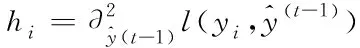
(5)
综合以上分析,模型采用二阶泰勒公式替换,带入正则化惩罚项系数,得到XGBoost模型最终的目标函数为
(6)
式(6)中,Ij表示树中第j个叶子结点的样本集合,目标函数L值越小表示生成的树结点越稳定。在生成树的类型确定后,利用贪心生成树方法遍历所有输入特征的切分点,将树结点分裂前后的目标函数值相减,其中相减后增益最大的结点是生成树最佳的切分点,对应生成叶子结点特征为最佳特征。
3.2 XGBoost特征与LR融合模型
原始训练数据集经过欠采样抽样分组处理,分成多个训练子集后,每个训练子集为均衡训练数据集。接下来利用XGBoost训练得到新的数据特征,将训练子集输入到XGBoost模型中进行学习并且每个子集输入不同的参数,得到k棵树,每棵树上有n1,n2,…,nk个叶子结点。每个预测样本在每棵树中都会落在一个叶子结点上面,那么以落在每棵树上的叶子结点作为该样本的特征值,就得到一个n1+n2+…+nk维的稀疏矩阵,其中有k个值为1,其余值为0。
经过XGBoost特征转换后,再将得到这些新特征与之前原始特征进行融合,组成新的特征输入到LR中进行训练。在原有特征基础上增加组合特征,通过扩展数据的维度用来间接提高模型的学习能力,在此基础上建立的LR模型可以有效提高LR模型的预测准确率。
3.3 异构集成模型
基于机器学习中的异构集成分析,提高传统的XGBoost算法的泛化能力,本文提出一种异构集成模型(HEM),该模型结合集成算法思想和XGBoost低偏差特性,该流程如图1所示。

图1 HEM模型流程
该方法的包括四个部分,具体方法如下:
1)模型首先使用EasyEnsemble方法,将不均衡的个人信用数据集划分成若干个样本均衡的训练子集;同时设置XGBoost模型的参数范围,组合多份不同参数集用于训练;
2)将处理后的训练集中训练多个XGBoost模型,在原始特征空间进行特征转换,产生不同的新特征;
3)将XGBoost模型得到的分类结果作为新的特征,与原始特征进行融合,组成新的数据集输入到LR1,LR2,…,LRm中进行学习。为减少融合过程中过拟合的风险,在第一层分类结果中加入了随机噪声,公式如下
XTi=X+Θ(Ti)
(7)
式(7)中X为原始特征向量,XTi为融合后的故障特征向量。Ti为子模型的预测结果;Θ(·)表示引入随机噪声。
4)最后输入测试数据集对每个子模型得到的预测结果进行融合,按ωj,j∈[1,n],通过堆叠方式,构建综合决策层,权值ωj的计算如式(8)所示。
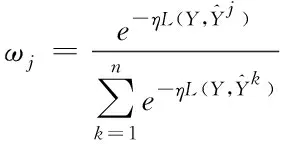
(8)
式(8)中,η为常值,得到最终的预测结果。
4 实验与分析
4.1 数据集描述
为了验证本文提出的异构集成模型算法的有效性,利用UCI数据库中的德国个人信用数据集对模型进行实验验证。该数据集一共包含了1000个客户的基本信息,其中包括了700个信用良好客户与300个违约客户,每一客户的信息有20个特征,包括10个离散特征和10个连续特征。
该UCI数据集被广泛用于评估个人信用模型的验证中,具有可靠的参考性。
4.2 数据预处理和特征工程
在本数据集中,由于存在年龄、信用卡额度和信用卡使用期限等不同的量纲,对比实验中SVM是基于距离度量的分类方法,它对于数据之间的数量级别不同非常敏感,数据之间差别较大容易导致较大的分类结果误差。为了消除这个影响,本实验在进行模型训练前使用均值方差标准化方法对年龄、信用卡额度和信用卡使用期数据进行标准化处理。
本实验采用均值方差标准化方法处理,将原始数据的均值和标准差进行标准化处理,其转换函数为
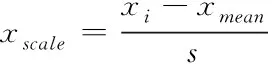
(9)
式(9)中,xmean是数据样本的平均值,S是数据样本之间的标准差。这样标准化处理后的数据不一定在0-1之间,但是所有数据标准化后符合标准正态分布,这种方法可以有效防止出现极端数据值的情况,也使得本实验更加规范。
4.3 模型评价指标
评价分类器性能有很多指标,通常来说精确率越高,分类效果越好,但是在数据样本分布不均衡的情况下,精确率越高并不一定意味着是一个性能好的模型。例如预测客户信用好坏,由于信用良好的客户远远大于信用违约客户数量,在极大概率下都是信用好的客户,所以随便一个模型预测是信用好的客户,它精确率都可以达到99%以上,因此使用精确率来评价一个算法模型的性能来说是不够的。
本文使用AUC值来评价模型的性能。ROC(Receiver Operating Characteristic)曲线是以假正率为横轴和真正率纵轴的曲线,AUC是ROC曲线下方的面积,一个好的分类模型的曲线应该尽可能靠近ROC曲线左上角。ROC曲线在数据不平衡条件下仍能很好展现模型实际情况,为了量化ROC的好坏,用ROC曲线与X轴围成的面积即AUC值来判断分类器性能。
4.4 实验设计
首先为了验证EasyEnsemble方法在处理非均衡数据时的有效性,实验用原始数据集、SMOTE过采样算法和EasyEnsemble欠采样算法进行数据处理,分别用LR、DT、SVM、XGBoost和HEM的基分类器算法(XGBoost-LR)进行实验对比分析。经过参数调优,本实验中XGBoost模型的学习率为0.03,生成树最大深度为7,特征采样比例为0.8,模型迭代次数为100次。
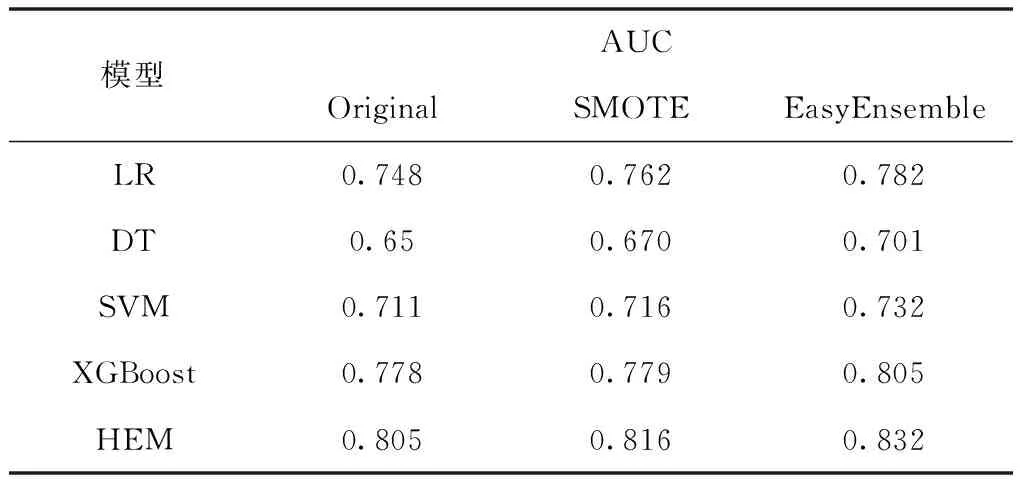
表1 不同算法处理后基分类器AUC值
表1为使用不同不平衡数据算法处理后基分类器分类的AUC值。从实验结果可以看出,训练子集经过EasyEnsemble处理后的AUC值比原始数据集和SMOTE算法处理的AUC值分别提升约3%和2%,说明EasyEnasemble欠采样方法处理后的数据对提升基分类器的分类准确率效果更好。
为了验证本文提出的HEM算法模型的有效性,实验以AUC为评价指标,并与当前常用的机器学习算法进行对比分析。经过参数调优,本实验中HEM模型使用40个子模型,每个子模型中的XGBoost学习率扰动范围为0.01~0.03,树最大深度扰动为6~8,特征采样比扰动为0.7~0.8,迭代次数扰动为100~200次。
实验结果如表2所示,其中对比实验的LR、DT、SVM和XGBoost集成模型包括了40个子模型,每个子模型输入不同的数据子集和参数训练,最后进行融合集成。表2中Fold1、Fold2、Fold3、Fold4、Fold5分别是各个集成模型进行五次交叉验证的结果,其中Avg为这些结果的平均值。
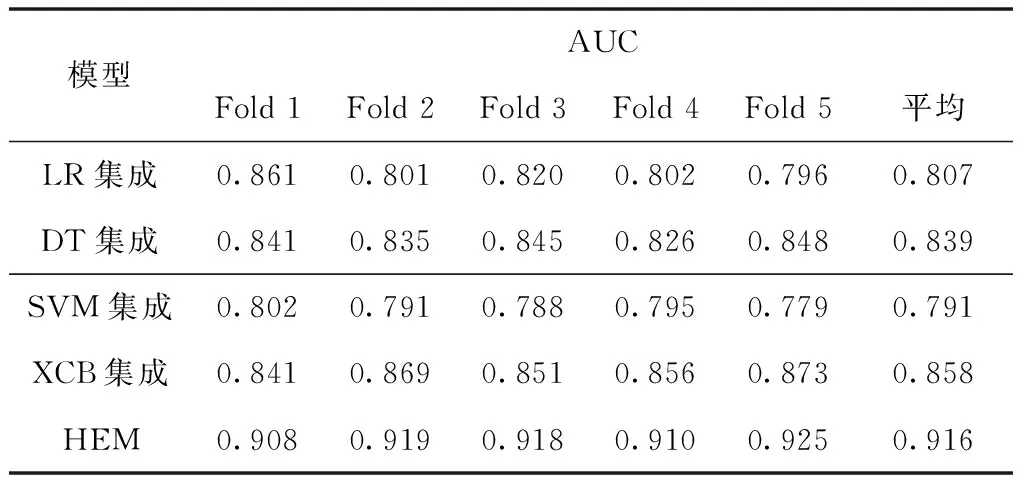
表2 各集成分类算法AUC值
从表2可以看出,在5个评估模型中,本文提出的HEM和其它算法相比准确度均有不同程度的提高。其中,HEM模型的AUC平均值为0.916,分别高出LR、DT、SVM、XGBoost集成模型的10.9%、7.7%、12.5%、5.8%,平均值提高了7.38%。
为说明HEM模型在这次案例研究中的优势,该模型与其它常用算法在个人信用风险评估中的结果进行对比。将本算法与逻辑回归(LR),决策树(DT),支持向量机(SVM),XGBoost(XGB)等进行实验对比,结果如图2所示:
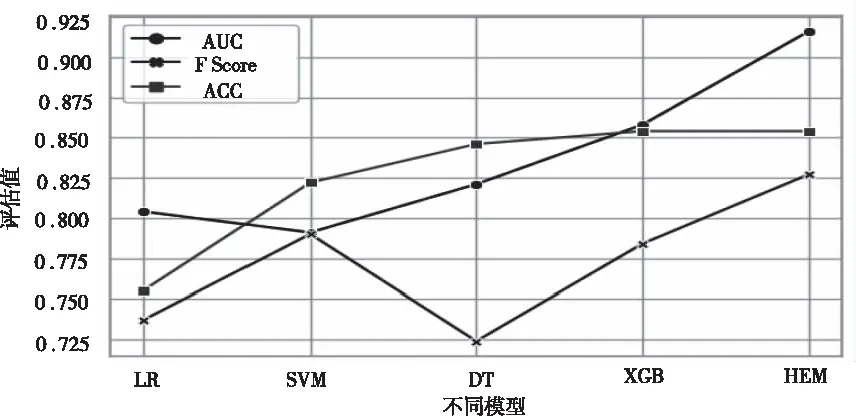
图2 不同模型评估结果对比
从图2的结果可以看出,在同样的数据条件下,本文提出的HEM模型用来个人信用评估的结果好于其它传统方法,同时比原始的XGBoost的效果更好。
4.5 K-S检验
在信用评分领域,经常使用的非参数检验——Kolmogorov-Smirnov检验法,其评价指标是K-S值,它用于检验输入的不同特征对最终个人的信用风险结果的影响。K— S统计量测两个分布之间的最大垂直距离,在评价二元分类模型的预测能力时,通常,K-S统计量越大,模型对正负样本的判别能力就越强。

图3 HEM模型K-S图
对于正负样本,图3、图4对比了两种不同的输入特征,对累计占比进行了模型预测。图3中采用HEM模型评估的K-S最大值为0.687;图4中采用LR模型评估的K-S最大值为0.489,低于HEM模型评估的K-S值0.198。
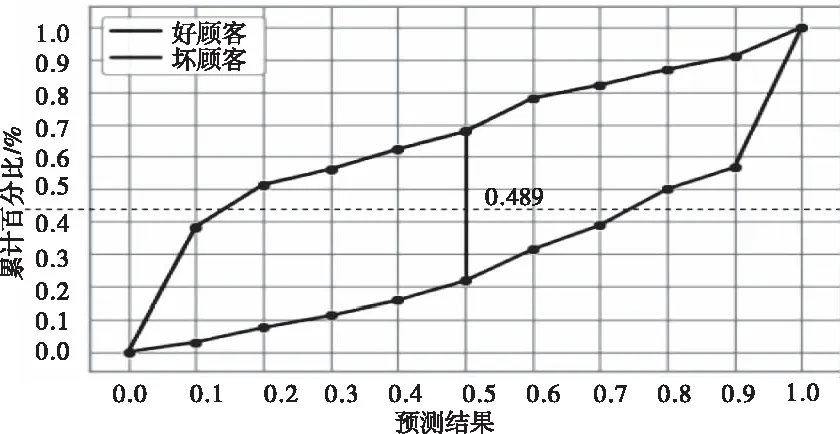
图4 LR模型K-S图
综上可以得出,本文提出的HEM模型可以更好的区分好客户和坏客户,对于个人信用风险评估有明显的提升作用。从另一个角度分析,对于刻画个人信用画像可以起到补充和完善的作用。
5 结束语
针对个人信用风险评估中出现的好坏客户数量严重不均衡的数据特性,基于XGBoost构建新特征和集成学习的思想,提出一种异构集成模型算法。实验通过对UCI德国信用数据集进行验证,并将本文模型与目前常见的机器学习方法进行比较分析,结果证明本文提出的模型在个人信用评估应用上的有效性,这些提升对于银行等金融行业来说将具有重要参考价值。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
成都信息工程大学学报(2020年2期)2020-08-24 08:05:36
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
法大研究生(2020年2期)2020-01-19 01:43:22
电子测试(2018年1期)2018-04-18 11:52:35
汽车与安全(2016年5期)2016-12-01 05:22:05
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
都市丽人(2015年4期)2015-03-20 13:33:22
