
基于AdaBoost 集成加权宽度学习系统的不平衡数据分类
2022-04-18 10:56王萌铎续欣莹阎高伟史丽娟
计算机工程 2022年4期
王萌铎,续欣莹,阎高伟,史丽娟,郭 磊
(太原理工大学电气与动力工程学院,太原 030024)
0 概述
在故障诊断、金融诈骗[1-3]等分类任务中,数据分布通常是不平衡的,类别分布极端时就会形成不平衡数据集。由于少数类别的数据数量相对较少,对准确率的影响也相对较小[4]。在处理不平衡数据集时,目标识别模型受数据自身分布制约学习到的多数类类别特征更多且忽视了少数类别。数据类别分布不平衡现象制约了模型对少数类别目标的识别性能[5-6]。
针对不平衡数据,ZHANG 等[7]提出一种使用新保角函数扩展最优间隔分布机(Optimal-margin Distribution Machine,ODM)核矩阵以提高特征空间可分性的不平衡分类方法(Kernel Modified ODM,KMODM)。ZHU 等[8]提出一种类权重随机森林(Class Weights Random Forest,CWsRF)算法,用于处理医学数据的不平衡分类。SUN 等[9]提出一种加权过采样的深度自编码器(Weighted Minority Oversampling Deep Auto-encoder,WMODA),用于检测实际旋转机械过程中的故障。KHAN 等[10]提出一种代价敏感深度神经网络(Cost-Sensitive Deep Neural Network,CS-DNN),用于自动学习多数和少数类的鲁棒特征表示。
由于类别分布不平衡数据会制约模型分类性能,因此为提升模型的不平衡处理能力,采用组合模型的方式增强算法对少数类别数据的特征提取能力。AdaBoost 作为一种高效集成学习方法,是提升分类模型不平衡数据分类能力的重要手段之一[11-12],通过调整样本权重和弱分类器权值,将弱分类器组集成为一个强分类器。
宽度学习系统(Broad Learning System,BLS)结构简单且分类精度较高[13]。BLS 系统模型结构为数据提取稀疏特征后输入随机向量函数链接神经网络(Random Vector Functional Link Neural Network,RVFLNN)的单层可横向扩展网络[14]。BLS 模型相比深度网络模型[10]训练时间短、易于训练与再训练[15]。大量实验结果表明,标准的BLS 容易受数据集自身分布的影响,改进的BLS 模型相继被提出。XU 等[16]提出一种用于预测多元时间序列的R-BLS(Recurrent BLS)模型。CHU 等[17]采用加权方式提升了BLS 模型对有噪声和异常值工业非线性数据的预测能力。BLS-CCA 与CNN 的级联模型[18]提升了系统对多模态数据的分类能力。徐鹏飞等[19-20]基于加权极限学习机(Weighted Extreme Learning Machine,WELM),提出一种有效的DDbCs-BLS 模型处理不平衡数据,该模型的本质是在训练样本上增加一个额外的权重,以得到更好的分类边界线位置,以改善BLS 性能。
为进一步提升BLS 的不平衡数据处理能力,本文提出一种可实现权重动态更新的集成加权宽度学习系统(Weighted Broad Learning System,WBLS),在KKT 条件下,分析比较BLS 与WBLS 的优化过程,在误差项上添加对角矩阵权重,降低训练误差,提升分类性能。将WBLS 集成到AdaBoost 模型中,通过基分类器WBLS 数据权重的训练实现WBLS 权重的动态更新,获得更符合数据分布特征的权重,并将所有基分类器加权集成为一个具备不平衡数据识别能力的新模型AdaBoost-WBLS。
1 宽度学习系统
本节将简要介绍标准BLS 结构。与深度学习模型不同,BLS 是特征横向排布模型,本质是将数据提取稀疏特征后输入随机向量函数链接神经网络。
当输入数据为X∈Ru×ν的矩阵形式时,可表示为X=[x1,x2,…,xu]T。BLS 通过稀疏特征映射得到映射特征层Zm,可表示如下:

其中:Wk、βk是随机生成的权重和偏差;φ是非线性激活函数;N1是特征层节点数;N2是特征层数。
映射提取到的特征可作为RVFLNN 层的输入,再经特征选择后得到N3维的增强特征层Zel,可表示如下:
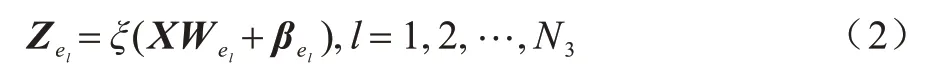
映射特征层与增强特征层横向扩展为平层宽度特征A,如式(3)所示。通过链接权重W分配不同大小的权值进行输出,如式(4)所示。最终模型的目标输出为Y=[y1,y2,…,yu]T。

BLS 的链接权重W是通过岭回归的优化方式快速求得。岭回归是一种快速求解伪逆的方法,本文中其对应的目标函数和计算公式分别如式(5)和式(6)所示:
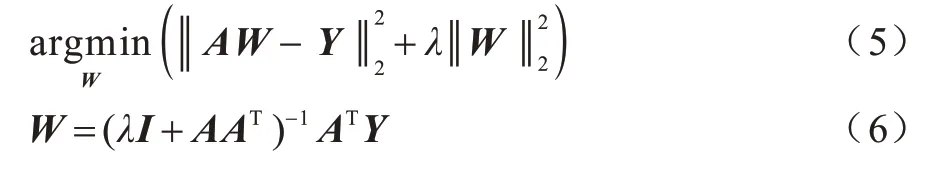
2 AdaBoost 集成的WBLS
2.1 WBLS
在处理实际数据集时,多数据集都存在不同程度的类别不平衡现象。文献[3,14]提供了为浅层网络添加敏感损失权重的方法来处理不平衡数据,以实现类间再平衡。与文献[14]的权重形式不同,权值矩阵可采用对角矩阵形式,将权重添加到数据所对应特征上,采用这种权重形式使模型可以与AdaBoost 结合。
式(5)与极限学习机(Extreme Learning Machine,ELM)[14]等单层网络最小化训练误差、最大化类间距离的过程相似。与LS-SVM 的优化方式相似,本节基于KKT 条件[15],对BLS 与WBLS 约束条件下的凸函数进行优化。通过比较推导结果,分析所添加对角权重Wp在BLS 模型中的作用。
BLS 在输入数据X∈Ru×ν中提取到的宽度特征表示为A,宽度特征对输出的链接权重矩阵表示为W。与WELM[10-11]等模型的优化过程类似,BLS 的优化过程可表示如下:
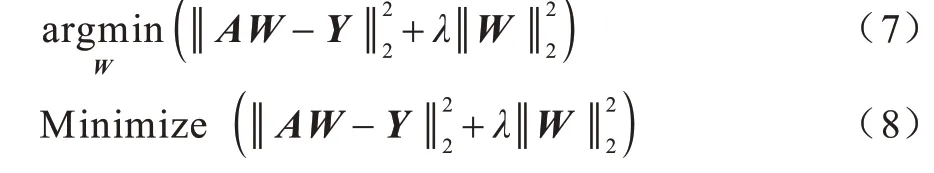
式(8)可简化如下:

其中:Y=[y1,y2,…,yu]T是模型的目标输出;λ是模型的正则化项参数,抑制模型的过拟合,也是影响模型性能的重要参数;ξ=[ξ1,ξ2,…,ξu]T是模型的预测误差。
在KKT 条件下,BLS模型的优化过程可表示如下:
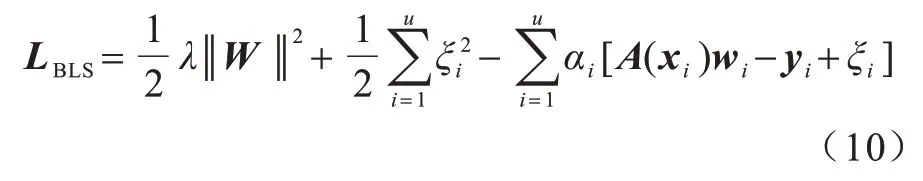
其中:αi是xi的特征映射对应的Lagrange 乘子。
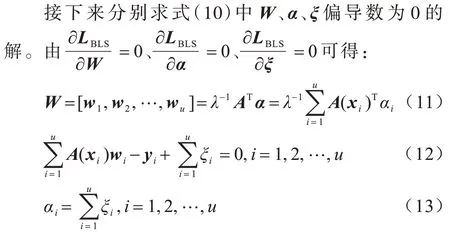
WBLS 的L2 范数凸优化目标可表示如下:
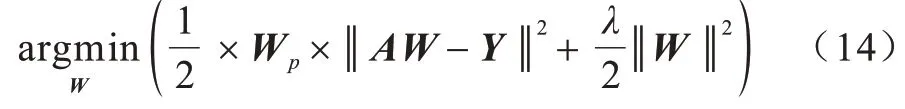
式(14)可简化如下:
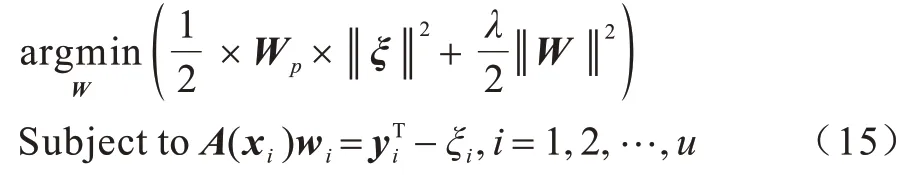
根据KKT 理论,WBLS 优化过程可等价表示如下:

对比BLS 与WBLS 在KKT 条件下的优化结果的式(13)和式(19)可知,输入数据添加的权重Wp是在模型的误差项上,且所加权重与Lagrange 乘子αi成反比。对比式(11)与式(17)可知,在WBLS 中αi又与输入数据所映射的特征层A共同决定了链接权重W。由此可得,权重Wp改变了不同数据特征的比重。
添加的权重有多种形式,文献[5]采用将敏感损失权重添加到所对应的数据层面。本节直接采用对角矩阵权重,Wp计算公式如下:
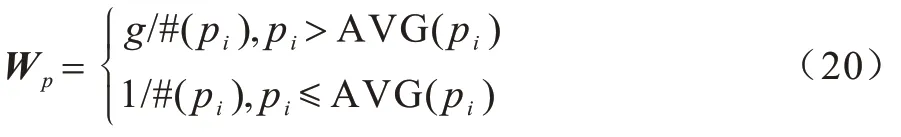
其中,i=1,2,…,u;#(pi)表示第i个数据所属类别的数据量;AVG(pi)表示平均类别的数据量。
2.2 AdaBoost-WBLS 模型
为提升BLS 模型对不平衡数据的识别能力,上文从理论上分析了在BLS 的误差项上添加权重的作用。为进一步提升模型对于少数类的识别能力,将WBLS 集成到AdaBoost.M1 框架中,以获得更符合数据分布特征的权重形式。
AdaBoost 是一种高效集成学习方法[21],主要思想是在训练空间上生成一个分布D,初始分配每个训练样本的权值为1/u,其中u为训练样本个数。利用迭代训练基分类器,动态更新分类器的权重,并根据多数投票规则将基分类器集成为一个强分类器。本文的基分类器是WBLS,其将T个基分类器迭代训练,从而集成为一个分类能力更强的分类器AdaBoost-WBLS。
在AdaBoost 原始框架中,训练样本的分布权值是通过动态迭代实现对基分类器的权重更新。在WBLS 处理不平衡数据时,添加权重Wp可抑制少数类样本的误差,提升分类器对少数类的识别能力。本文将WBLS 集成到AdaBoost,实现了对权重Wp的动态更新,可获得更合理的权重形式。与文献[5]的加权方式不同,本文权重采用对角矩阵形式Wp=diag(),仅在不同数据对应的特征上添加一维常数的权重。
与传统Boosting 类模型集成过程不同,当模型输出数据的类别数为j时,本文对AdaBoost-WBLS的集成过程进行如下改进:
1)在传统的AdaBoost 模型中,第1 个基分类器的起始数据的权重通常选用1/u,而本文采用特殊起始权重1/(j×Wp)。这种将类别数据引入模型初始化过程的方式,可增加模型的类别信息,提升AdaBoost-WBLS 对少数类样本的识别效率与识别能力。权重初始化公式如下:

其中:i=1,2,…,u。
2)在传统Boosting 类模型中,集成学习过程是对所有训练样本之间进行归一化迭代处理,而本文模型采用在类别内部归一化的方法,以达到提升类间平衡度的目的,即分布权值Dt(xi),i=1,2,…,u对不同类别分别累加,依次更新。更新公式如下:

算法1AdaBoost-WBLS 算法
输入训练集P={(x1,y1),(x1,y1),…,(xu,yu)},迭代次数(即BLS 基分类器个数)T

3 实验验证
为验证AdaBoost-WBLS性能,将其分别与Boosting类、BLS 类模型进行消融实验研究,之后与KMODM[7]、CWsRF[8]、WMODA[9]、CS-DNN[10]这4 种不平衡分类模型进行对比研究。实验环境为Windows 10系统,8 GB内存,Intel Core i7 6500 CPU,编程环境为Matlab 2016b。采用输出形式,共输出j个类别,在输出类别的位置上设置为1,其余位置均设置为-1。
映射特征层节点数、特征层数、增强节点层数、正则化参数取值范围分别为N1=10、N2∈{1,3,…,21}、N3∈{1,10,20,…,500}、λ∈{2-40,2-39,…,20,…,220}。
引入不平衡率(Imbalance Ratio,IR),评价不同的不平衡数据集中数据的分布形式。在二分类中IR的计算公式如下:

其中:#(minority)、#(majority)分别表示数据集中多数类与少数类的样本数。
在多分类中IR 的计算公式如下:

3.1 评价指标选取
在对数据进行分类时,准确率是分类任务常用的评价指标,但是在不平衡分类任务中,使用准确率作为评价模型性能的唯一指标,不能准确表征模型对少数类的分类能力。以二分类为例,在一些极端的分布中,少数类与多数类的比例可能达到99∶1,模型即使不具备对少数样本的分类能力,依然可以得到较高的准确率,但此时的全局准确率不能用于评价其对于少数类的识别能力。因此,本文还选用G-mean 评价指标来评价不平衡数据的分类结果。
在二分类中,将少数类作为正样本(+1),多数类作为负样本(-1),则二分类混淆矩阵如表1 所示。

表1 二分类混淆矩阵Table 1 Binary confusion matrix
在表1 中,TTP为正样本被分类为正确类的统计量,FFP为负样本被分类为正样本的统计量,FFN为正样本被分类为负样本的统计量,TTN为负样本被分类为正确类的统计量。
准确率(Accuracy)表示所有样本的准确识别率,计算公式如下:
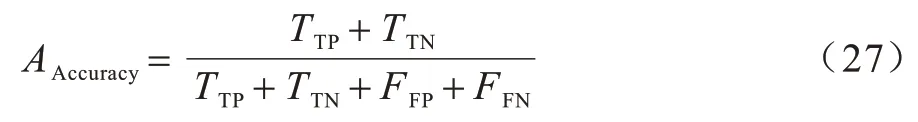
召回率(Recall)表示正样本(少数类)的识别率,计算公式如下:

特异率(Specificity)表示负样本(多数类)的识别率,计算公式如下:

G-mean 值表示各类别识别率的几何平均值。在二分类任务中,G-mean 是召回率与特异率的几何平均值,计算公式如下:

在多分类任务中,分类目标数大于2。此时,G-mean采用一对多(One-Against-All,OAA)的统计方式,分别计算各类别的识别准确率,再求整体G-mean。当有j个类别时,G-mean 计算公式如下:

3.2 数据集选取
选取UCI 数据库中15 个不平衡数据集作为消融实验与对比实验对象。数据集具体情况如表2 所示,其中,12 个数据集是二分类数据集,3 个数据集是多分类数据集,不平衡率分布范围为0.007 6~0.912 8。Abalone 数据集与Yeast 数据集为生物数据集,前者通过物理测量预测鲍鱼的年龄,后者可对核蛋白和非核蛋白的核定位信号进行判别分析。New-thyroid 为甲状腺疾病数据集,Glass、Vehicle 与Satimage 数据集为普通分类数据集。
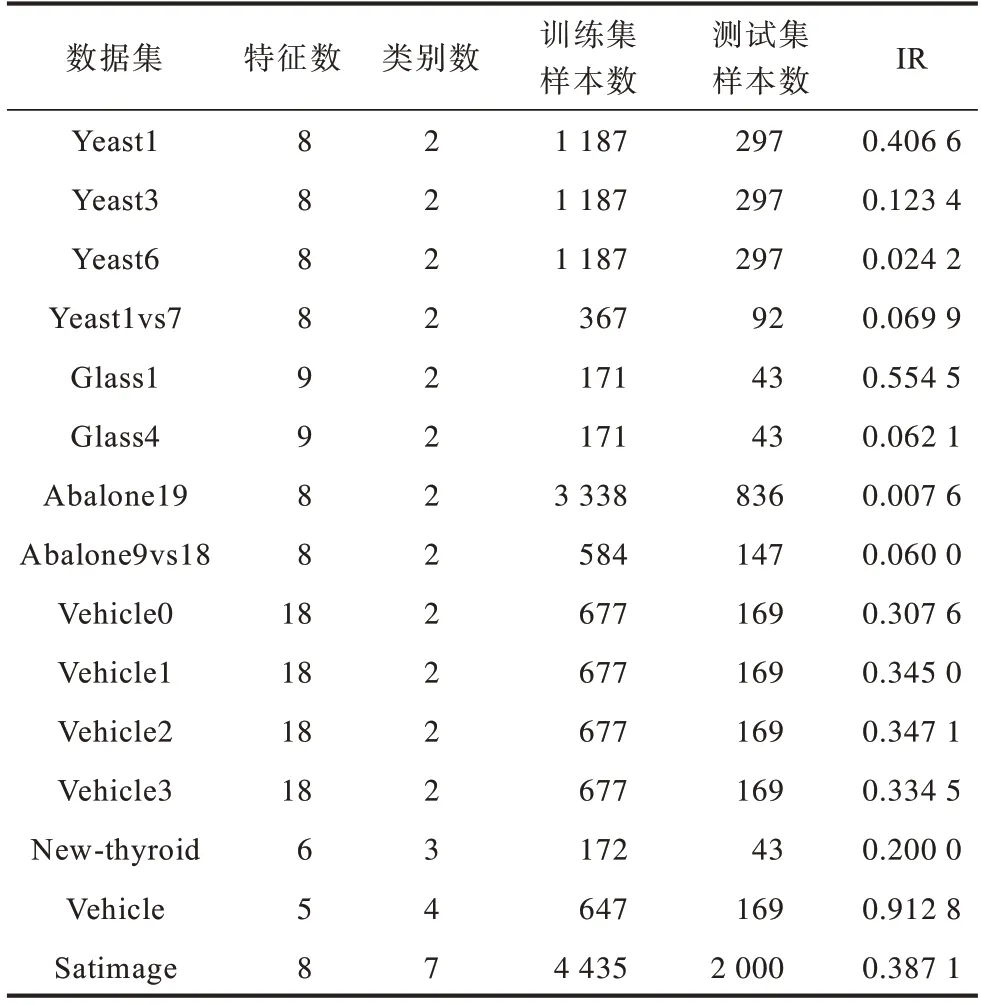
表2 实验数据集设置Table 2 Setting of experimental dataset
3.3 λ 参数的作用
本文对宽度学习模型中的正则化参数λ进行实验讨论。在相关研究中,参数λ通常采用固定值λ=2-30。因此,通过实验分析不平衡数据处理时,参数λ变化对实验结果的影响。
实验对象为不平衡数据集Glass4,N1、N2和N3分别选取10、20 和500,使参数λ成为唯一变量。实验参考了大量研究对λ的取值方式,选取取值范围为λ∈{2-40,2-39,…,20,…,220}。通过实验对比了BLS、g=1时W1-BLS 和g=0.618 时W2-BLS 的G-mean 结果,如图1 所示。
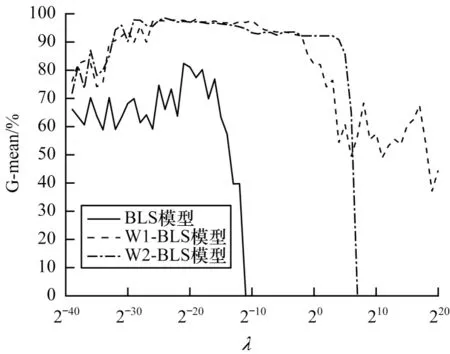
图1 Glass4 数据集上随λ 变化的G-meanFig.1 G-mean when λ varies on the Glass4 dataset
根据实验结果可知,在λ从2-40变化到220的过程中,G-mean 值基本呈现先上升后下降的趋势。当λ逐渐增大时,会达到最优的G-mean。当继续增大时,模型将会出现过拟合现象,导致G-mean 值迅速降低。根据对比可知,在BLS 内添加形如Wp=diag()的权重,不仅可以提升模型的G-mean 峰值,而且相对提高了模型的稳定性。
3.4 消融实验
3.4.1 Boosting 类模型实验验证
本文设计一种将WBLS 作为基分类器并在AdaBoost 框架中嵌入WBLS 以提升不平衡数据分类性能的优化方法。设置N1、N2、N3、λ分别为10、20、500、220。AdaBoost-WBLS 与DDbCs-BLS 等加权宽度学习模型的最大不同点在于:基于AdaBoost 模型可以实现自动更新训练样本所添加的权值。在AdaBoost 中,分布权重是训练样本的重要性表征。在训练过程中,被错误分类的样本通过获得相比较被正确分类样本更大的分布权重以提升其重要性。因此,本文采用训练样本所添加的分布权值Wp作为AdaBoost-WBLS 中的训练样本对应的权值。
在Yeast1vs7 数据集上,对AdaBoost-WBLS 与传统Boosting 框架的BLS 迭代过程中G-mean 的变化情况进行比较,结果如图2 所示。由图2 可知,AdaBoost-WBLS 模型的G-mean 曲线上升更快,获取最优基分类的迭代次数更少,稳定性更强,并且峰值更高,表明了学习到的特征更丰富。

图2 Yeast1vs7 数据 集上AdaBoost-WBLS 与Boosting-BLS 模型的G-meanFig.2 G-mean of AdaBoost-WBLS and Boosting-BLS model on Yeast1vs7 dataset
在5个数据集上对Boosting-WELM、AdaBoost-WELM、Boosting-WBLS、AdaBoost-WBLS这4种Boosting模型进行性能对比,G-mean结果如表3所示,Accuracy结果如表4所示,其中Boosting-WELM 和AdaBoost-WELM 模型的结果引自文献[3]。BLS参数通过网格搜索设置为最优参数,其中,λ为正则化参数,L为网络节点数。
比较表3、表4中AdaBoost-WBLS与Boosting-WBLS模型结果可以看出:前者在多数数据集上的G-mean 都相对更高,且具有相对较高的Accuracy;在Yeast3 数据集上G-mean 高0.90 个百分点,Accuracy 基本相等;在Yeast6 数据集上G-mean 高5.17 个百分 点,Accuracy 下降了0.98 个百分点;在Abalone19 数据集上G-mean高1.75 个百分点,Accuracy 却下降了3.25 个百分点,这说明AdaBoost-WBLS 模型更关注少数类,而Boosting-WBLS 模型更关注多数类的总体准确率。比较表3、表4 中AdaBoost-WBLS、Boosting-WELM与AdaBoost-WELM 模型结果可以得出,在经过网格搜索得出最佳参数后,BLS 模型具有更高的Gmean 与Accuracy。
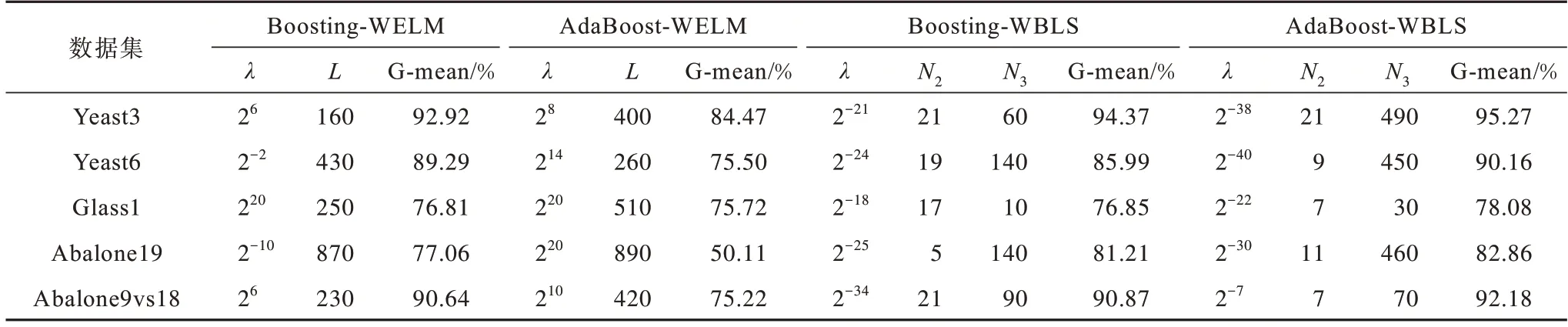
表3 Boosting 类相关模型消融实验的G-meanTable 3 G-mean of Boosting-related model ablation experiments
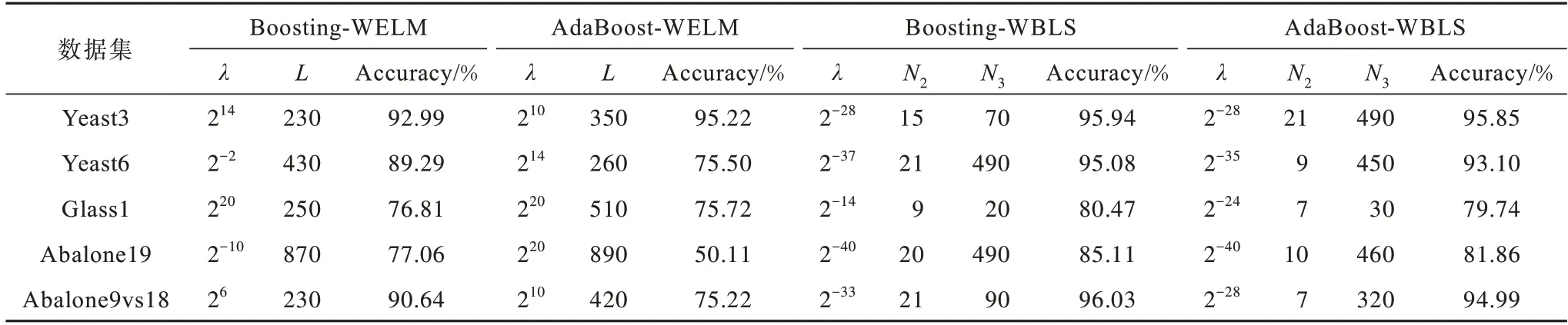
表4 Boosting 类相关模型消融实验的AccuracyTable 4 Accuracy of Boosting-related model ablation experiments
3.4.2 BLS 类模型实验验证
在6 个二分类数据集上比较了AdaBoost-WBLS、BLS、DDbCs-BLS 模型的G-mean 与Accuracy,结果如表5、表6 所示。由表5、表6 可以看出:与BLS 模型相比,AdaBoost-WBLS模型的G-mean结果均得到了改善,在Yeast3数据集上AdaBoost-WBLS 模型提升了9.31个百分点,在Vehicle1 数据集上提升了2.38 个百分点;与DDbCs-BLS[19]模型相比,AdaBoost-WBLS 模型的G-mean 在Yeast1 数据集上高出3.67 个百分点,在Vehicle2 数据集上提高了0.8 个百分点。由此可见,本文提出的不平衡数据分类方法在结合Boosting模型后,提升了集成模型的局部泛化能力。

表5 BLS 类相关模型消融实验的G-meanTable 5 G-mean of Boosting-related model ablation experiments %

表6 BLS 类相关模型消融实验的AccuracyTable 6 Accuracy of Boosting-related model ablation experiments %
3.5 对比实验
在Vehicle0、Vehicle3、Yeast3 等3 个二分类与New-thyriod、Vehicle、Satimage等3个多分类数据集上对 比AdaBoost-WBLS 与KMODM[7]、CWsRF[8]、WMODA[9]、CS-DNN[10]模型的不平衡数据分类性能。G-mean结果如表7所示。由表7可以看出,AdaBoost-WBLS 的G-mean 明显高于其他4 种模型,在Vehicle0数据集上比KMODM 模型高出3.74 个百分点,在New-thyriod 数据集上比CWsRF 模型高出3.09 个百分点,在Satimage 数据集上比WMODA 模型高出4.36 个百分点,在Vehicle 数据集上比CS-DNN 模型高出1.15 个百分点。实验结果验证了AdaBoost-WBLS 模型通过多个加权BLS 组合成的新分类器可有效处理不平衡数据。
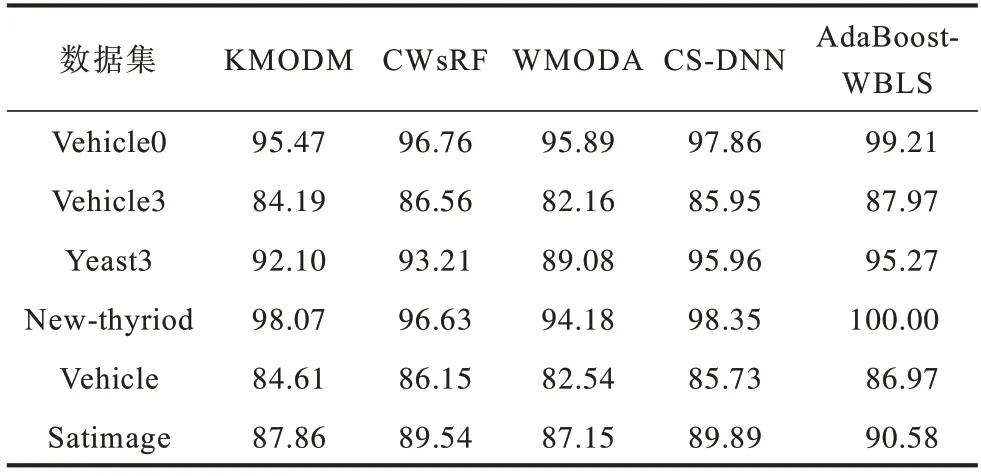
表7 对比实验的G-meanTable 7 G-mean of contrast experiments %
Accuracy 结果如表8 所示,可以看出相比其他4 种模型,AdaBoost-WBLS 模型的Accuracy 相对较高。在New-thyriod 数据集上比WMODA 模型高出4.65 个百分点,达到100%。可见,AdaBoost-WBLS 模型在提升对少数类识别能力的同时,具有较高的识别精度。
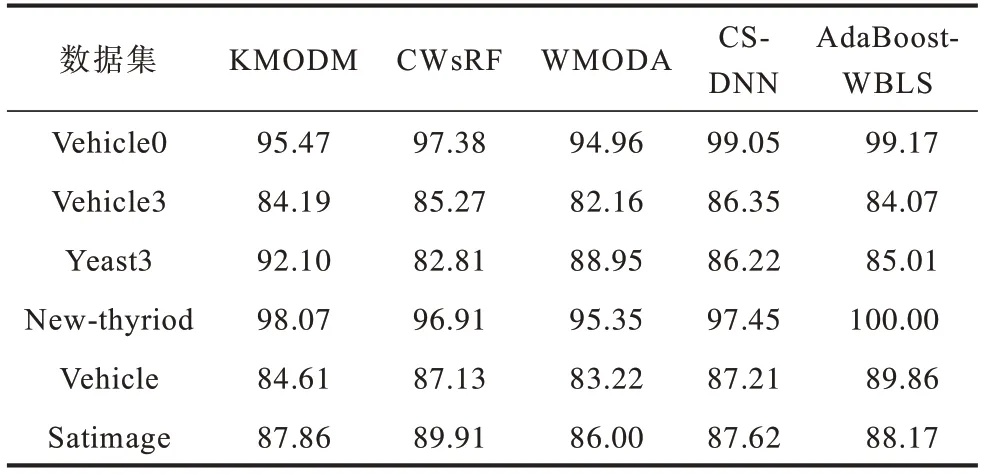
表8 对比实验的AccuracyTable 8 Accuracy of contrast experiments %
4 结束语
本文研究旨在通过集成AdaBoost 与WBLS 提升BLS 的不平衡数据集处理能力。基于KKT 条件推导验证了WBLS 的有效性。将加权宽度学习的数据特征与AdaBoost 中分类器的权重结合,在算法层面进行AdaBoost 与BLS 的融合。在AdaBoost-WBLS 集成初始化时,WBLS 采用基于类别信息的权重,使基分类器具有先验类别信息并且模型更快收敛。在迭代训练过程中,对WBLS 基分类器数据权重的更新方式进行调整。对不同类别数据对应的权重采用不同的正则化准则,使权值具有更高的类间区分度,同时显著提升模型的训练效率。实验结果表明,AdaBoost-WBLS 模型相比同类模型在二分类与多分类数据集上G-mean 均有显著提升,准确率较高,且具有较好的不平衡数据的处理能力。下一步将使用集成BLS 的AdaBoost 模型,解决多模态数据分类等问题。
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
陶瓷学报(2021年4期)2021-10-14
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
少儿画王(3-6岁)(2020年4期)2020-09-13
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
文苑(2015年9期)2015-09-10
航天返回与遥感(2014年5期)2014-07-31
新课程学习·中(2013年3期)2013-06-14
