
面向视频数据的深度学习目标识别算法综述
2022-04-18 10:56王振华张鑫月郑宗生栾奎峰
计算机工程 2022年4期
王振华,李 静,张鑫月,郑宗生,卢 鹏,栾奎峰
(1.上海海洋大学 信息学院,上海 201306;2.上海海洋大学 海洋科学学院,上海 201306)
0 概述
监测手段的多样化使得数据获取方式从静态的图像拍摄扩展至动态的视频监测,视频数据不再局限于人类娱乐活动,因此,面向动态视频数据的目标识别成为研究热点并被广泛应用于各个领域,如交通领域的车牌识别[1-2]、车辆违章[3-5]、无人驾驶[6-7]等,农业领域的机器采摘[8-9]、农作物成熟度检测[10]、病虫害分析[11-12]等,城市管理领域的智能安防[13-14]、安全监控[15-16]等。
深度学习因其多尺度的特征提取能力和超强的泛化能力,成为视频目标识别的技术支撑。目标识别是计算机视觉的一部分,其目的在于从图像或视频中检测出目标、识别目标类别并计算目标所在位置[17]。视频数据是由连续帧组成的动态数据,相较于静态图像,其包含了目标对象的上下文信息。在深度学习领域,目标识别利用卷积神经网络来完成,即通过卷积神经网络对输入的视频数据进行特征提取,利用提取的特征实现目标的分类与定位[18]。
本文归纳并分析面向动态视频数据的深度学习目标识别算法,通过实验比较各算法的优缺点,并在现有研究基础上对面向动态数据的目标识别研究进行展望。
1 基于深度学习的视频数据目标识别算法
根据是否采用锚点机制,可将基于深度学习的目标识别算法分为Anchor-Based 和Anchor-Free 两类,如图1 所示。Anchor-Based 类算法根据有无区域建议生成可分为基于区域的目标识别算法(Two-stage)和基于回归的目标识别算法(One-stage)[19]。Anchor-Free 类算法根据算法结构可分为基于关键点的目标识别算法和基于特征金字塔的目标识别算法。
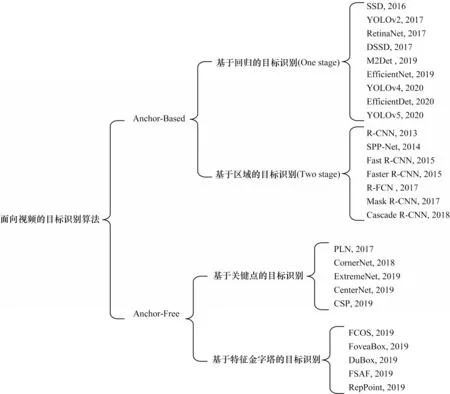
图1 基于深度学习的视频数据目标识别算法分类Fig.1 Classification of video data object recognition algorithms based on deep learning
1.1 Anchor-Based 目标识别算法
Anchor-Based 算法首先预设边界框(Anchor Box)作为目标大小及定位参考。Anchor 是边界框的中心点,也是固定点。Anchor Box 为锚框,是预测目标边界框的重要参考标准。本文对Anchor-Based两类目标识别算法分别进行分析。
1.1.1 基于区域的目标识别算法
基于区域的目标识别算法(Two-stage)包括识别目标候选区选择、卷积神经网络的特征提取、候选区域分类、目标识别结果优化等步骤[20]。2013 年,GIRSHICK 提出Region-CNN(R-CNN)目标识别算法,开启了深度学习用于目标识别的发展之路[21]。2014年,HE 等提出空间金字塔池化算法(Spatial Pyramid Pooling Network,SPPNet),消除了网络对输入图像尺寸的限制,避免了卷积特征的重复计算[22]。2015 年,GIRSHICK 提出Fast R-CNN 目标识别算法,对R-CNN和SPPNet 进行了融合改进[23]。同年,GIRSHICK 等又提出Faster R-CNN 目标识别算法,引入了候选区域生成网络(Region Proposal Network,RPN)用于自动生成目标候选区域[24]。2016 年,DAI 等提出R-FCN目标识别算法,将全连接应用于Faster R-CNN,增加位置敏感得分图和位置敏感池化操作,解决了分类网络的位置不敏感性与检测网络的位置敏感性之间的矛盾[25]。2017 年,HE 等提出Mask R-CNN 目标识别算法,解决了原图与特征图的特征位置不匹配问题[26]。2018 年,CAI 等提出Cascade R-CNN 目标识别算法,通过级联多个检测网络,达到了优化预测结果的目的[27]。
1)R-CNN 目标识别算法
R-CNN 算法流程如图2 所示,主要包括以下步骤:

图2 R-CNN 算法流程Fig.2 Procedure of R-CNN algorithm
(1)创建候选框:利用选择性搜索算法创建候选框。
(2)提取特征并生成特征向量:将创建的候选区域进行固定尺寸的缩放,并将缩放结果输入到AlexNet(去除最后的Softmax 层)中提取特征,生成特征向量。
(3)候选区域分类并生成得分:将特征向量输入到SVM 分类器对候选区域进行分类并生成得分。
(4)结果生成:通过Canny 边缘检测对得分较高的候选框微调得到最终边界框(Bounding boxes)。
R-CNN目标识别算法利用神经网络对底层向上的候选区域分类和定位,通过迁移学习解决了数据集规模小的问题。但该算法参数量较多,并且创建候选区域时存在重叠现象,导致计算量大、耗时严重。此外,R-CNN需要单独开辟空间来存取目标特征,存在空间资源消耗问题。
2)SPP-Net 目标识别算法
SSP-Net 是HE 等在神经网络中引入空间金字塔池化的目标识别算法。空间金字塔池化可接受任意尺寸的图像输入,并产生固定输出,其通过不同尺寸的池化对相应目标进行特征提取。SPP-Net 算法的处理流程类似于R-CNN,如图3 所示。该算法相比R-CNN的改进在金字塔池化层,通过金字塔空间池化对特征图中的每个候选区域提取固定长度的特征向量,并输入到全连接层。
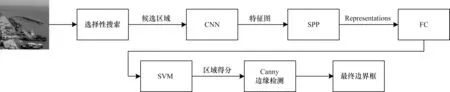
图3 SPP-Net 算法流程Fig.3 Procedure of SPP-Net algorithm
SPP-Net 算法解决了网络对输入图像尺寸的要求,避免了图像剪裁后目标变形、识别区域只包含部分物体等问题,其通过候选区域到全局特征映射,直接获取候选区域中的特征向量,避免了通过网络对特征重复计算,缩短了训练时间。但SPP-Net 算法采用SVM 作为分类处理器,存在空间资源消耗问题,并且该算法采用选择性搜索算法创建候选框,计算量大的不足仍是有待优化的问题。
3)Fast R-CNN 目标识别算法
Fast R-CNN 是一种基于区域的快速目标识别算法,该算法在提高精度的同时,加快了算法的训练时间和测试速度。Fast R-CNN 算法流程如图4 所示,主要包括以下步骤:

图4 Fast R-CNN 算法流程Fig.4 Procedure of Fast R-CNN algorithm
(1)创建候选框并提取特征:与R-CNN 相同,采取选择性搜索算法创建候选框,同时输入图像到VGG-16 中进行特征提取并输出特征图。
(2)ROI 池化:根据候选框和特征图的映射关系在特征图中找到每个候选框对应的特征框,在ROI池化层中将每个特征框池化到特定尺寸并输出等同候选框个数的特征向量。
(3)整合特征:将相同尺寸的向量输入到全连接层进行特征整合,得到固定大小的特征向量。
(4)输出结果:将所得特征向量由SVD 分解输出一个分类得分向量和一个窗口回归向量,对每一类物体进行非极大值抑制,剔除重叠建议框并得到最后目标识别结果。
Fast R-CNN 算法采用感兴趣池化层(ROI Pooling Layer)提高了目标识别精度,并且只在ROI 层进行特征提取,避免了特征的重复计算,缩减了网络的训练与测试时间。此外,其采用多任务损失函数(Multi-task Loss)将分类和定位统一,避免了特征额外的空间消耗。但是Fast R-CNN 算法同样采用选择性搜索算法创建候选框,仍然存在耗时严重的问题。
4)Faster R-CNN 目标识别算法
Faster R-CNN 是对Fast R-CNN 的改进,该算法通过区域候选网络(Region Proposal Network,RPN)代替选择性搜索算法产生候选框,在保证精度的前提下解决耗时问题。Faster R-CNN 的处理流程如图5 所示,主要包括以下步骤:

图5 Faster R-CNN 算法流程Fig.5 Procedure of Faster R-CNN algorithm
(1)特征提取:输入图像到CNN(ZFnet或VGG-16)得到供RPN网络输入的特征图和向前传播的特有特征图。
(2)利用RPN 网络创建候选框:将生成的特征图输入到RPN 网络得到区域建议和区域得分。
(3)ROI 池化:将得分前300 名的区域建议[28]和特有卷积层进行特征提取得到高维特征图输入到ROI 层,输出尺寸相同的特征向量。
Faster R-CNN 算法中的RPN 网络采用锚点机制,以每个锚点为中心生成9 个大小、比例不同的锚点框,其结构如图6 所示。
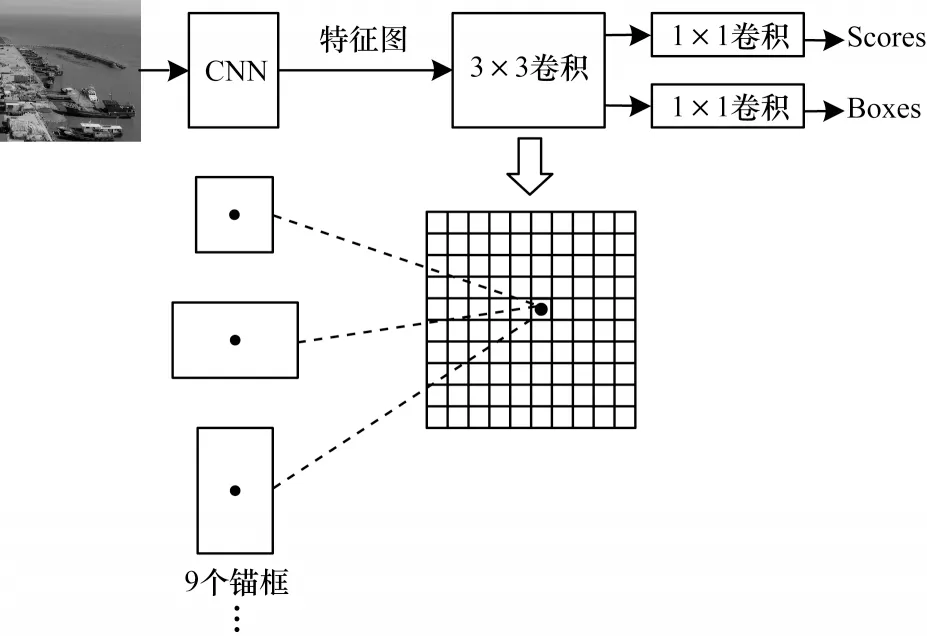
图6 RPN 网络结构Fig.6 RPN network structure
Faster R-CNN 算法将候选框的生成融于网络中,解决了采用选择性搜索算法耗时严重的问题,同时设置不同尺寸的Anchors,解决多尺度问题。但Faster R-CNN 算法需要计算每个候选框的分类,计算量较大,并且该算法存在特征图与原图的配准问题,影响了模型的识别精度[29-31]。
5)R-FCN 目标识别算法
R-FCN(Region-based Fully Convolutional Network)算法的处理流程如图7 所示,主要包括以下步骤:
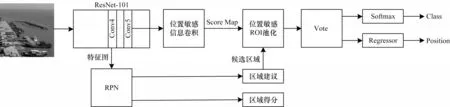
图7 R-FCN 算法流程Fig.7 Procedure of R-FCN algorithm
(1)特征提取:输入图像到Backbone Network(ResNet-101)进行特征提取输出特征图。
(2)生成候选框和位置敏感信息得分图:将ResNet-101 中Conv4 的输出特征图输入到RPN 网络中,得到区域建议和区域得分,将ResNet-101 中Conv5 输出的特征图进行位置敏感信息卷积,得到位置敏感信息得分图。
(3)生成类别得分:将区域建议和位置敏感信息得分图进行位置敏感池化操作,使得每个区域建议都生成对应位置的类别得分。
(4)结果生成:通过Softmax 函数和计算Offset 分别获得对应的类别和位置信息,并生成目标识别结果。
R-FCN 算法的优势是提出了采用位置敏感信息得分图(Position-sensitive score maps),解决了目标识别的位置敏感性问题,同时采用全卷积网络减少了总体计算量,加快了识别速度。但R-FCN 算法只采用一个尺度特征,不适应目标尺度变化的现象,并且该算法的收敛速度仍需改进[32-33]。
6)Mask R-CNN 目标识别算法
Mask R-CNN 是HE等提出 的Faster R-CNN 的扩展,其处理流程如图8 所示,主要包括以下步骤:
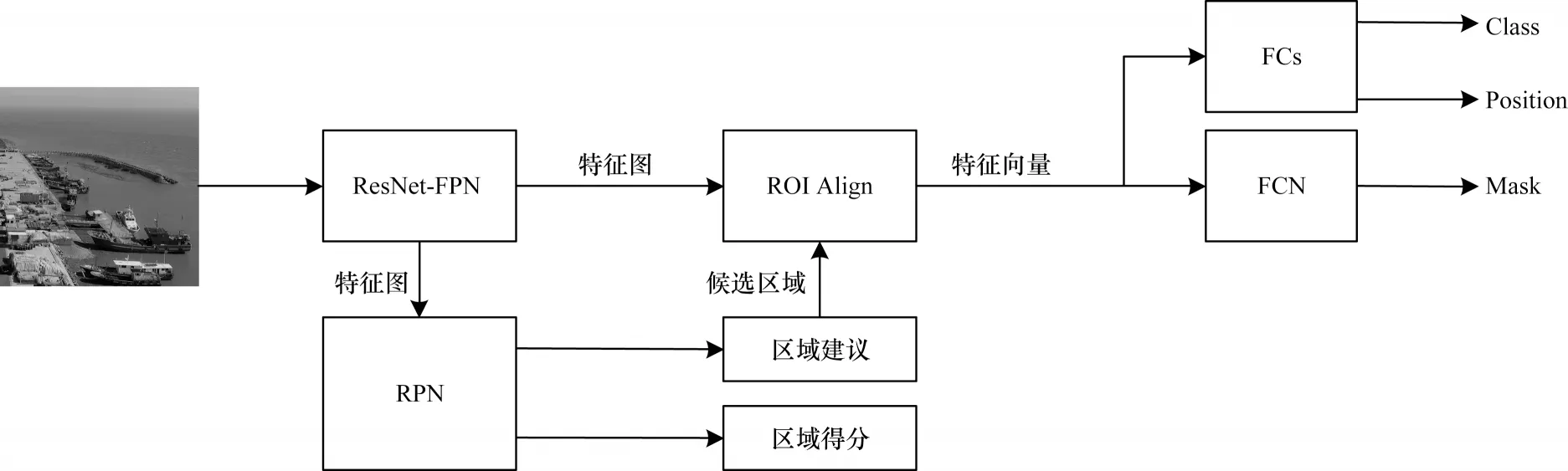
图8 Mask R-CNN 算法流程Fig.8 Procedure of Mask R-CNN algorithm
(1)特征生成:输入图像到ResNet-FPN 网络进行特征提取并输出特征图。
(2)候选框生成:对特征图中的每一点设定预定的感兴趣区域(Region of Interest,ROI),将候选的ROI 输入到RPN 网络,得到区域建议和区域得分并过滤掉部分候选的ROI。
(3)固定尺寸的特征图生成:将生成的候选框和生成的特征图进行双行线插值操作(ROI Align),将特征聚集并输出特定尺寸的向量。
(4)结果生成:将特征向量分别输入到全连接层和FCN网络中进行分类、回归和Mask分割,并生成结果。
Mask R-CNN 目标识别算法利用ROI Align 方法解决了Faster R-CNN 中的Misalignment 的问题,同时通过添加Mask 层融合了浅层与深层特征检测图像特征细节。此外,其定义多任务损失函数,即在Fast R-CNN 的基础上增加了Mask 损失,避免了不同类别之间的相互影响。但Mask R-CNN 算法参数较多,计算量大,这影响了算法的速度[34-35]。
7)Cascade R-CNN 目标识别算法
Cascade R-CNN 是CAI 等提出的一种通过级联多个网络来优化预测结果的多阶段目标识别算法,也是对Faster R-CNN 算法的改进,其处理流程如图9所示,主要包括以下步骤:
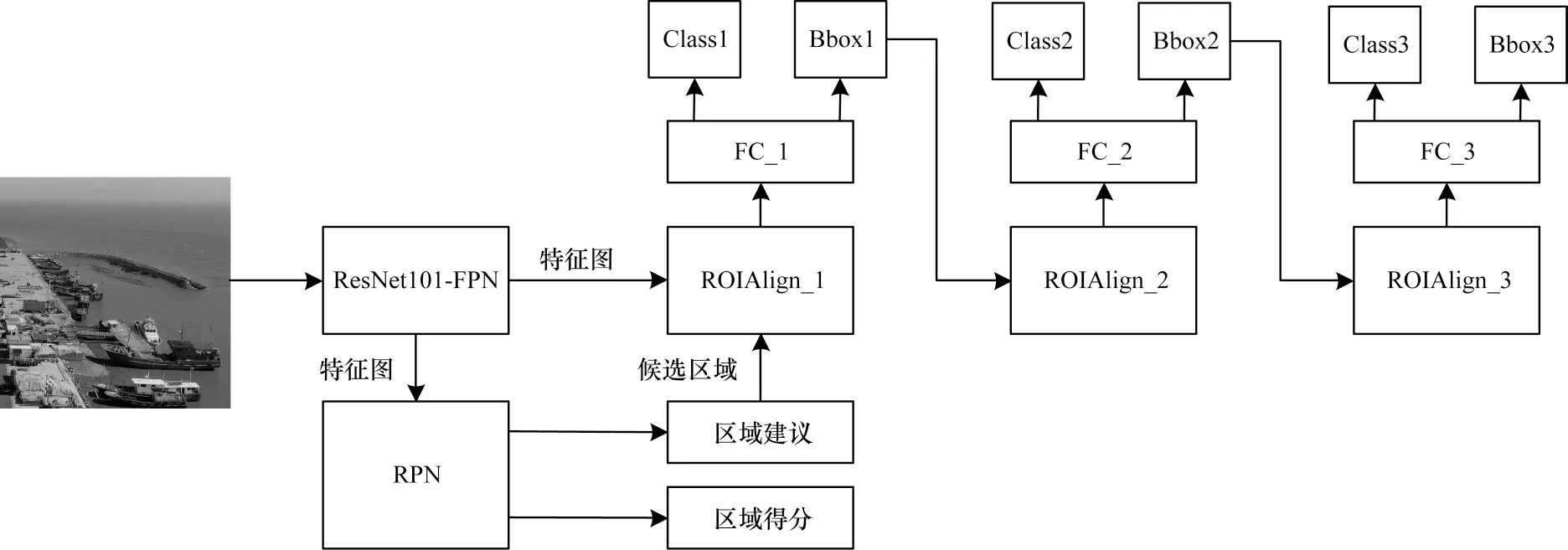
图9 Cascade R-CNN 算法流程Fig.9 Procedure of Cascade R-CNN algorithm
(1)特征生成:输入图像到ResNet101 与FPN 相结合的网络中进行特征提取,得到继续向前传播和输入到RPN 网络中的特征图。
(2)候选框创建:同Faster R-CNN 一样,通过RPN 网络生成候选框。
(3)结果生成:通过级联不同IoU 阈值的检测模型对输入进行逐步分类与定位。
Cascade R-CNN 算法是通过级联不同IoU 阈值的检测器,其各自专注于相应IoU 阈值的目标,避免了因只增加IoU 阈值导致正样本数量减少而产生的数据过拟合问题,提高了目标识别精度。但该算法的级联结构增加了训练成本和计算耗时[36-38]。
1.1.2 基于回归的目标识别算法
基于回归的目标识别算法将目标识别问题转换为回归问题,取消了网络中候选区域(Region Proposal)的产生过程,通过对输入数据集进行训练直接在图像中预测目标的类别概率和位置坐标[39]。2016 年,LIU 等引入多尺度识别技术,提出了SSD 目标识别算法[40]。2017 年,REDMON 等对YOLOv1 进行改进,提出YOLOv2(和YOLO9000),提升了目标识别的定位准确率和召回率[41]。2020 年,LIN 等提出了RetinaNet 算法,解决了正负样本之间不均衡问题[42]。2017 年,FU等在SSD 的基础上改进上采样和预测模块,提出了DSSD 算法[43]。此外,在SSD 算法基础上改进的目标识别 算法还包 括DSOD[44]、FSSD[45]和RSSD[46]等。2018 年,REDMON 等改进基础网络并结合金字塔结构,提出了YOLOv3 算法[47]。2019 年,ZHAO 等提出M2Det 算法解决了目标尺度变化问题[48],TAN 等设计了一种多维度混合的模型放缩方法——EfficientNet算法[49]。2020 年,TAN 等对EfficientNet 扩展改进,提出了EfficientDet 算法[50]。此外,在YOLOv3 的基础上,BOCHKOVSKIY 等提出YOLOv4 算法[51],ULTRALYTICS 等提出了YOLOv5 算法。
1)SSD 目标识别算法
SSD(Single Shot MultiBox Detector)算法是LIU等于2016 年提出的单一神经网络的目标识别算法,由VGG-16 卷积神经网络和多尺度特征目标识别网络两部分组成。SSD 算法的处理流程如图10 所示,主要包括以下步骤:
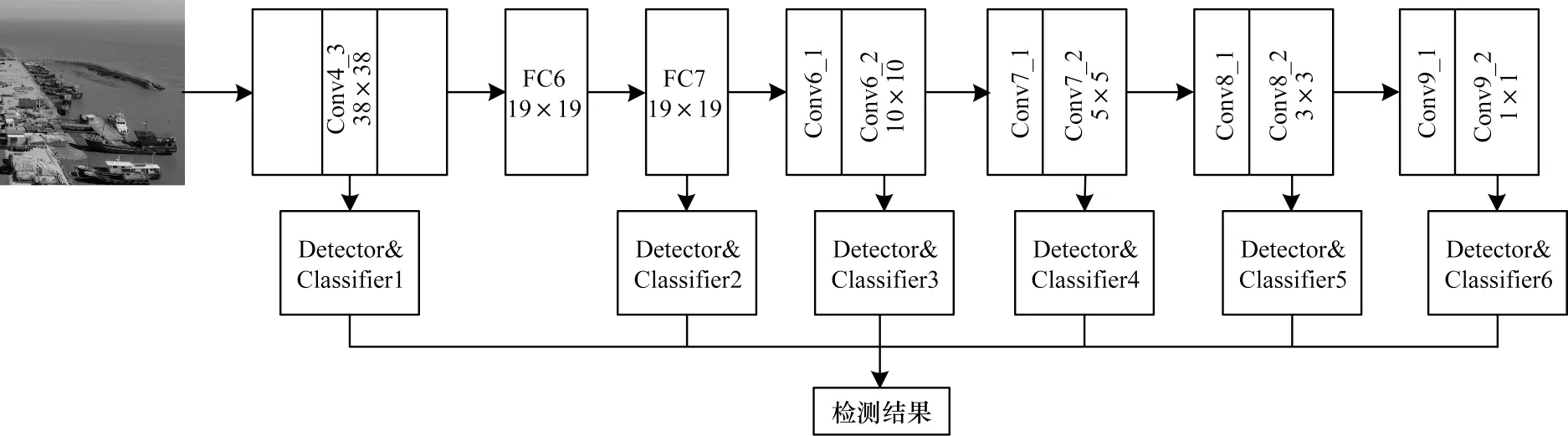
图10 SSD 算法流程Fig.10 Procedure of SSD algorithm
(1)特征获取:输入图像到VGG-16 卷积网络进行特征提取并生成特征图。
(2)先验框获取:选取Cov4_3、FC7、Conv6_2、Conv7_2、Conv8_2、Conv9_2 这6 层特征图并在每个特征层的每个单元格上生成默认框(default box);所有的默认框(default box)经过极大抑制,筛选出先验框(prior boxes)。
(3)结果生成:将先验框(prior boxes)与真实框(ground truth boxes)进行比较,计算最佳Jaccard 重叠(IoU),选择阈值大于0.5 的作为候选框并投入训练,生成最终结果。
SSD 算法在VGG-16的框架下用卷积层替换全连接层,提高了算法的计算效率,同时通过添加空洞卷积,使模型获得更加密集的得分映射,其结构如图11所示。此外,该算法采用不同分辨率的特征图自适应目标大小,实现多尺度目标预测,并采用随机剪裁方式进行数据增强,提高了算法的鲁棒性。但SSD算法需人工设置锚定框的大小,无法有效匹配真实目标尺寸,并且该算法不能有效结合全局特征,存在小目标特征提取不充分现象[52-53]。
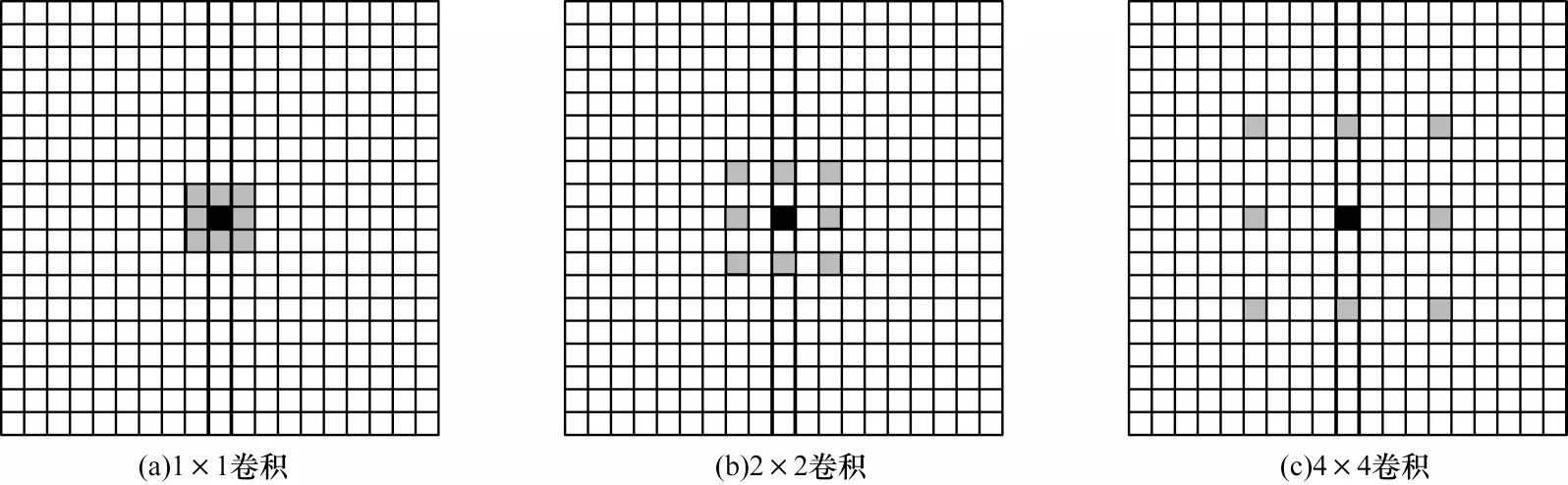
图11 空洞卷积示意图Fig.11 Schematic diagram of dilated convolution
2)YOLOv2 目标识别算法
YOLOv2 算法是REDMON 等针对YOLOv1 中对位不准确等问题进行的一系列改进。
YOLOv2 在提高模型精度方面:
(1)采用了Batch Normalization:在YOLO网络中的卷积层后添加Batch Normalization层,Batch Normalization既可代替Dropout层起到正则作用,又可提高模型的识别精度。
(2)添加了High Resolution Classifier:在进行样本识别之前采用高分辨图像对分类网络进行10 轮次的预训练,使网络更好地适应高分辨率图像的输入。
(3)采用了Convolutional with Anchor Boxes:借鉴Faster R-CNN 的做法,引入先验框思想,去掉全连接层而采用先验框来预测目标的边界框。
(4)采用了Dimension Clusters:通过K-Means 聚类的方法设置先验框的尺寸,通过聚类得到的先验框更加贴合真实框的尺寸,提高模型识别精度。
(5)增加了Direct location prediction:调整预测框的计算公式,将中心点的预测值规定在一个网格范围内,避免了采用先验框而导致在模型训练初期目标中心位置预测不稳定的问题。
(6)添加了Fine-Grained Features:添加Passthrough层保存细节信息,便于小目标的更好识别。
(7)采用了Multi-Scale Training:在训练过程中每10 个batch 就随机更换一种尺寸,使模型可进行多尺度的目标识别。
在提高速度方面:YOLOv2 算法提出了一种新的分类网络Darknet-19,其由19 个卷积层和5 个最大池化层组成。Darknet-19 与VGG-16 相比减少了计算量和参数数量,提高了模型的收敛速度。同时,YOLOv2 使用了WordTree 结构,解决了不同数据集之间的互斥问题。
3)RetinaNet 目标识别算法
RetinaNet 算法是由LIN 等提出用来解决目标识别类别不平衡问题的目标识别算法。该算法的处理流程如图12 所示,主要包括以下步骤:
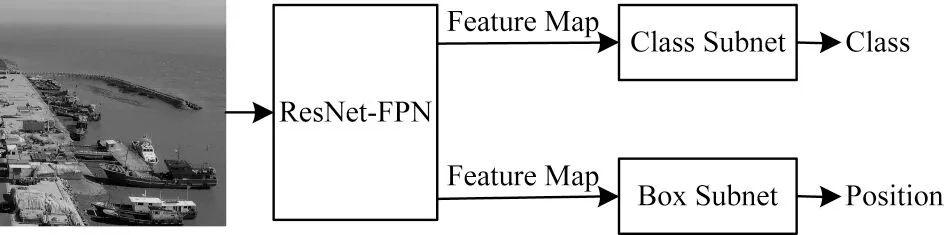
图12 RetinaNet 算法流程Fig.12 Procedure of RetinaNet algorithm
(1)特征提取:输入图像到CNN(ResNet50 或101-FPN)中进行特征提取,输出不同尺度的特征图。
(2)全局特征获取:将不同尺度的特征图融合到图像金字塔中并输出全局特征。
(3)结果生成:将得到的特征图分别输入到分类网络(Class Subnet)和回归网络(Box Subnet)中进行目标分类和预测框调整,并生成最终识别结果。
RetinaNet 算法的主要优势是提出了Focal Loss。通过引入Focal Loss 来平衡类别权重,解决背景类对前景目标识别的影响,提高目标识别的精度。但RetinaNet算法选择ResNet-101 作为特征提取网络,影响了算法的识别速度[54-56]。
4)YOLOv3 目标识别算法
YOLOv3 算法是REDMON 等 对YOLO 系列算法的进一步改进。该算法的处理流程如图13 所示,主要包括以下步骤:
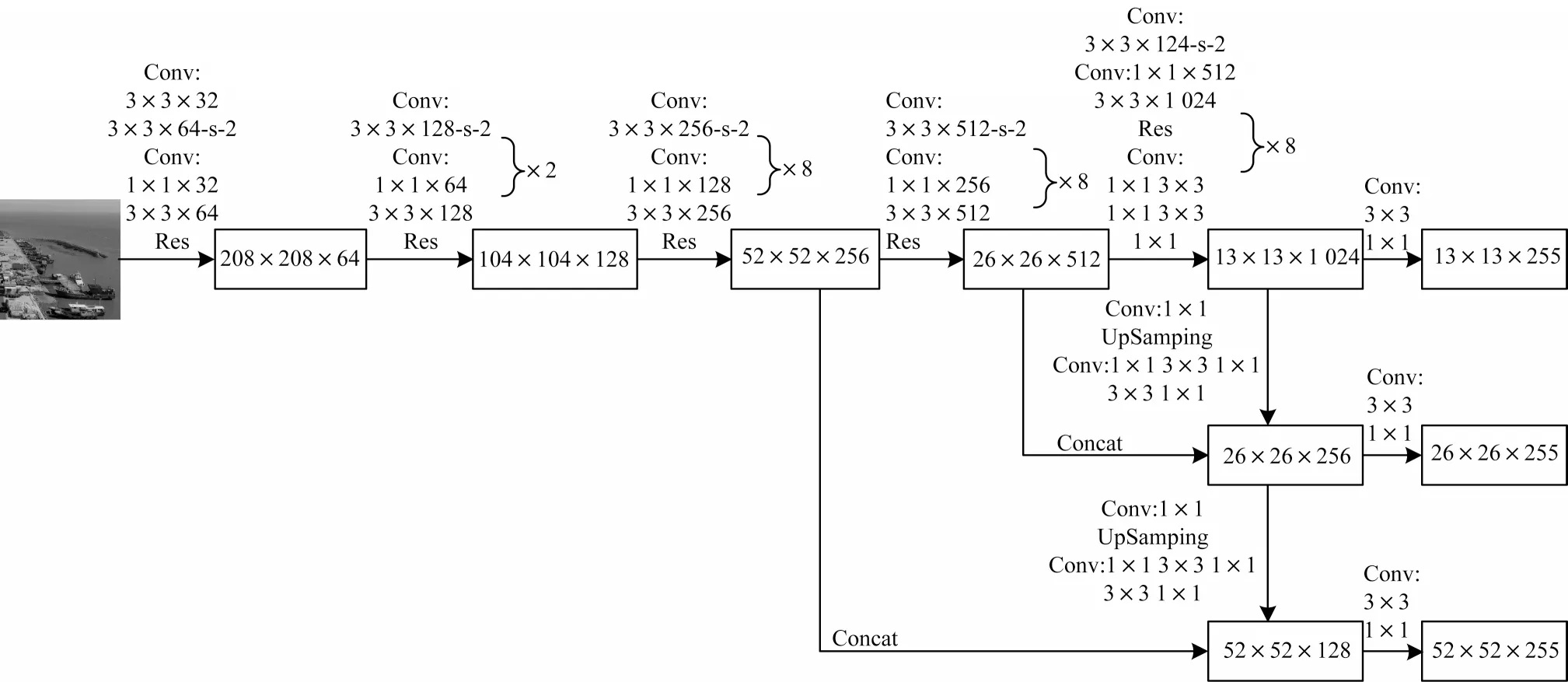
图13 YOLOv3 算法流程Fig.13 Procedure of YOLOv3 algorithm
(1)特征提取:输入图像到Darknet 网络进行特征提取,并通过上采样和张量拼接等操作得到3 个不同尺寸的特征图。
(2)边界框获取:先对图像进行网格划分,并在网格上根据真实框(Ground Truth Boxes)确定目标中心点,再对中心点所在的单元格对应的边界框(Bounding Box)进行筛选并输出边界框信息。
(3)结果生成:采用多尺度融合的方式融合3 个尺寸特征图上的特征信息进行目标预测,并生成结果。
YOLOv3 算法中提出Darknet-53 网络,提高了目标识别效率,同时该算法借鉴FPS 思想,采用多尺度特征进行目标识别,提高了识别精度。此外,其使用Logistic 回归替换Softmax 进行多标签分类,解决了单个边界框中的多目标识别问题。YOLOv3 算法在追求速度的同时亦保证了识别精度,但YOLOv3 算法的特征提取网络不够精细,导致识别物体位置精准性差,召回率低[57-59]。
5)M2Det 目标识别算法
M2Det(Multi-Level Feature Pyramid Network)是由ZHAO 等提出的解决多尺度问题的目标识别算法,该算法的处理流程如图14 所示,主要包括以下步骤:

图14 M2Det 算法流程Fig.14 Procedure of M2Det algorithm
(1)特征提取:输入图像到Backbone Network(VGG-16和ResNet-101)进行特征提取并输出特征图。
(2)多级尺度特征获取:将得到的特征图进行细化U 型模块(TUM)和特征融合模块(FFM)操作,提取出更有代表性的Multi-level 和Multi-scale 的特征,通过尺度特征聚合模块(SFAM)融合获取多级尺度特征。
(3)结果生成:将得到的多级尺度特征用于最终的图像目标预测,并生成目标识别结果。
M2Det 算法提出了多尺度融合方法MLFPN。MLFPN 由特征融合模块(FFM)、细化U 形模块(TUM)和尺度特征聚合模块(SFAM)三部分组成,如图15 所示。MLFPN 是将FPN 框架中不同深度的层替换成一个小的FPN 模块,即FPN 套FPN,同时引入SE block,对不同深度的特征赋予权重。
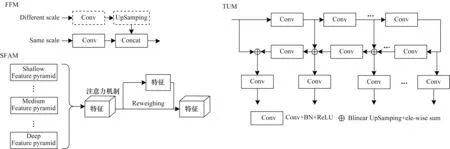
图15 MLFPN 结构Fig.15 Structure of MLFPN
6)YOLOv4 目标识别算法
YOLOv4 是 由BOCHKOVSKIY 等 于2020 年 在YOLOv3的基础上进一步改进与优化而来,并且适用于常规GPU进行训练。YOLOv4 的体系结构是用Mosaic数据增强方法对输入端进行处理,用CSPDarknet53 作为Backbone,SPP附加模块和PANET 路径聚合作为Neck,YOLOv3 的头部作为Head,该算法处理流程如图16所示。此外,YOLOv4 的优化策略主要分为BoF(Bag of Freebies)和BoS(Bag of Specials)两类。BoF 是指在离线状态下,不额外增加算法计算开销的优化策略。BoS 是指仅增加一点推理成本但可极大增加算法精度的优化策略。

图16 YOLOv4 算法流程Fig.16 Procedure of YOLOv4 algorithm
YOLOv4 算法在网络结构改进的基础上,提出了Mosaic数据增强、自对抗训练(Self-Adversarial Training)、跨最小批归一化(Cross mini-batch Normal)、修改SAM、修改PAN这5种创新方法,提高了算法的普适性和高效性。但在面向具体场景的动态识别中,该算法对复杂场景中目标识别具有局限性,存在漏检、误检等问题[60-62]。
7)YOLOv5 目标识别算法
YOLOv5 是ULTRALYTICS 团队于2020 年提出的目标识别算法。该算法的网络结构配置与YOLOv4 算法类似。YOLOv5算法对输入端进行Mosaic数据增强,以Focus 和CSP 结构为Backbone,以FPN+PAN 结构为Neck,同样Head 采用YOLOv3Head。相较于YOLOv4算法,其优势包括:1)自适应锚定框尺寸,通过学习调整锚定框的大小,使其更契合真实目标的尺寸,提高了目标识别精度;2)引入控制因子,灵活控制网络结构以适应不同配置,YOLOv5 算法设计4 个不同版本以适应不同需求;3)优化损失函数,改变匹配规则,加快算法的收敛速度。YOLOv5 在部署和应用中简单灵活,但其性能及稳定性需要做进一步研究[63-64]。
1.1.3 小结
在Anchor-Based 类算法中,基于区域的目标识别算法在面向视频数据的目标识别应用中,识别精度是其优势所在。针对其耗时严重问题,不断有新的算法被提出,但目标识别的时效性仍有待改进。基于回归的目标识别算法有较强的实时性,但其识别的精度有待提高。
1.2 Anchor-Free 目标识别算法
随着目标识别技术的不断发展,Anchor-Free 思想重新引起关注,DenseBox[65]和YOLOv1[66]算法是Anchor Free 的早期探索,在2019 年达到大爆发状态。Anchor-Free 算法无需预先指定Anchor Box 尺寸或生成Anchor Box,其通过生成点来生成目标框,完成目标识别[67]。本文对基于Anchor-Free 的两类目标识别算法进行阐述。
1.2.1 基于关键点的目标识别算法
基于关键点的目标识别将目标识别问题转换为关键点预测问题,先进行关键点的预测,再通过关键点确定目标[68]。2017 年,WANG 等提出了PLN 目标识别算法,其流程是预测中心点和4 个角点并判断点之间是否相连,进而实现目标识别[69]。2018 年,LAW 团队提出了CornerNet 算法,通过预测角点来实现目标识别[70]。2019 年,ZHOU 等提出了ExtremeNet算法,通过预测4 个极值点(最顶部、最左侧、最底部、最右侧)和中心点来实现目标识别[71],同时提出了CenterNet 算法,通过估计目标中心点来实现目标识别。此外,LIU 等提出了CSP 算法,通过中心点和尺度预测实现目标识别[72]。
1)CornerNet 目标识别算法
CornerNet 算法由LAW 团队于2018 年提出,其处理流程如图17 所示,主要包括以下步骤:
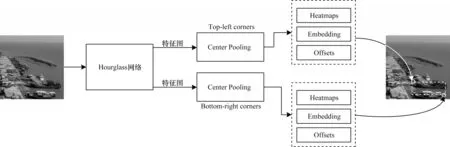
图17 CornerNet 算法流程Fig.17 Procedure of CornerNet algorithm
(1)特征提取:输入图像到Hourglass Network 网络进行特征提取,输出特征图。
(2)角点预测和结果生成:将得到的特征图同时输入到2 个分支进行左上角预测和右下角预测,每个分支输出对应的Heatmaps、Embeddings 和Offsets。Heatmaps 包含角的坐标和目标的类别信息。Embeddings 是利用衡量指标来判断左上角和右下角是否属于同一目标。Offsets 是用于预测框微调的精度丢失信息。
CornerNet算法去除了Anchor,通过左上角和右下角信息生成框提高算法的计算效率,同时通过Corner Pooling 来检测Corner 的位置信息,提高了算法的识别精度。Corner Pooling 结构如图18 所示。
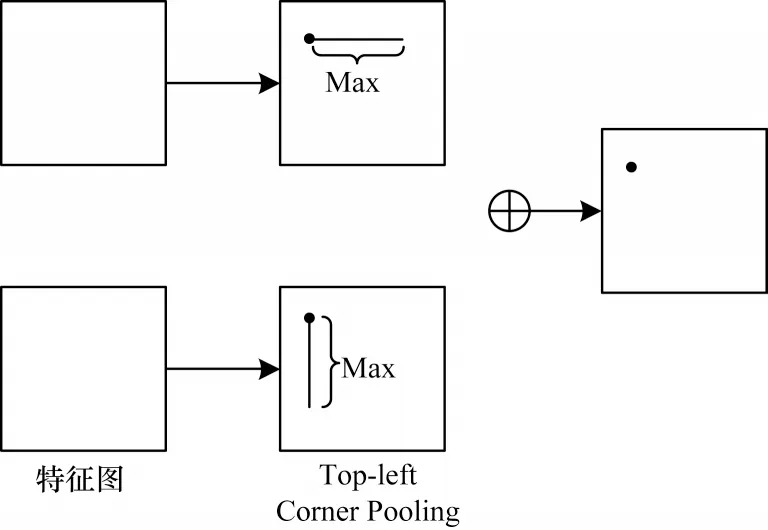
图18 Corner Pooling 结构Fig.18 Structure of Corner Pooling
CornerNet目标识别算法在进行目标识别时,若检测的Corner 信息位于目标之外,其目标识别较困难。同时,该算法参数量较大,计算速度有待进一步提高[73-74]。
2)ExtremeNet 目标识别算法
ExtremeNet 算法由ZHOU 等于2019 年提出,其处理流程与CornerNet 算法类似,但该算法的Offset包含对应极值点的精确定位信息,与目标预测类别无关。此外,该算法用几何方法Center Grouping 替换了CornerNet 中的Embeddings 分组过程,无需进行隐含特征学习,具有更好的组合效果。
ExtremeNet算法中的Ghost Box抑制,抑制在中心点分组时出现的假阳性分组,如图19所示,边缘聚合则对左边和右边的极值点选择垂直方向聚合,而顶部和底部的极值点则选择水平方向聚合,解决了极值点不唯一所导致的弱响应问题。ExtremeNet算法相较于仅估计2个角点的CornerNet算法更加稳定。但ExtremeNet算法的参数量大,影响了处理速度,无法适用于实时性应用。
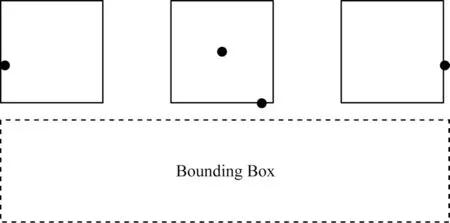
图19 Ghost Box 示意图Fig.19 Schematic diagram of Ghost Box
3)CenterNet 目标识别算法
CenterNet 算法由ZHOU 等于2019 年提出,亦可用于3D 目标检测,其处理流程如图20 所示,主要包括以下步骤:

图20 CenterNet 算法流程Fig.20 Procedure of CenterNet algorithm
(1)获取热力图:输入图像到卷积神经网络得到热力特征图。
(2)中心点估计:通过热力图的峰值估计目标的中心点。
(3)结果生成:通过中心点回归得到目标尺寸即目标预测框,并生成识别结果。
CenterNet 算法预测的中心点、中心点偏置及目标尺寸效果如图21 所示。CenterNet 算法实现了完全的Anchor Free,通过估计目标中心点,根据中心点回归得到目标尺寸来进行目标识别。该算法仅有一个目标中心点,通过正向传播算法回归得到目标尺寸,不存在先验框的得分取舍问题,但该算法存在下采样后相同类型的目标中心点重合问题,影响了预测结果的准确性[75-77]。

图21 CenterNet 算法效果图Fig.21 Effet diagrams of CenterNet algorithm
1.2.2 基于特征金字塔的目标识别算法
基于特征金字塔的目标识别是在算法中融合特征金字塔网络(Feature Pyramid Network,FPN)结构,并针对算法特点改变FPN 层级分配来实现目标识别。TIAN等提出了像素级的目标识别算法FCOS[78]。KONG等提出了FoveaBox 算法,通过学习坐标直接映射转换关系预测目标存在概率,并回归目标所在位置[79]。CHEN等提出了双尺度融合预测的目标识别算法DuBox。YANG 等提出了RepPoints 算法,结合可变型卷积,通过点集的方式更细粒度地实现目标的定位与识别[80]。
FCOS(Fully Convolutional One-Stage Object Detection)算法处理流程如图22 所示,主要包括以下步骤:

图22 FCOS 算法流程Fig.22 Procedure of FCOS algorithm
1)特征提取:输入图像到Backbone 中进行特征提取,并输出不同尺度的特征图。
2)特征融合:将不同尺度的特征图融合到图像金字塔中,并输出相应的特征图。
3)结果生成:将得到的特征进行Classification、Center-ness 和Regression 计算,并生成结果。
FCOS 算法不同于关键点检测,其通过引入金字塔FPN 处理不同层次的目标识别。此外,FCOS 提出了一种新的策略Center-ness,在分类得分的基础上结合中心度,再通过非极大抑制算法过滤结果,以此抑制偏离中心点的预测框的产生。FCOS 算法减少了生成Anchor 的计算量,但该算法通过计算3 个分支来预测目标,增加了算法的计算耗时[81-82]。
1.2.3 小结
在去掉Anchor 的情况下,识别算法结构简单且容易理解,提高了目标识别的精度。基于关键点的目标识别减少了算法的计算量,但特征信息利用不够充分,忽略了正负样本不平衡问题,影响了算法的识别精度。基于特征金字塔的目标识别算法,结合算法自身特点与FPN 融合,提高了算法性能,但一定程度上影响了算法速度。
2 算法性能比较
2.1 数据来源
实验数据是无人机拍摄的上海市金山区、奉贤区和浦东新区的近海海域监测视频数据,并对近海海域监测视频数据进行了截帧提取、小目标复制、旋转等操作,构成实验数据集1 010张图片。识别目标为船(boat)、车(car)和障碍物(rubbish)。训练数据集利用LabelImg和Labelme 对3 类目标进行标注产生。实验环境为Intel core i7-10700k,Geforce RTX 3080,CUDA 11.0。
2.2 目标识别算法评估指标
以平均检测精度(mean Average Precision,mAP)[83]、F1-Score[84]和每秒帧率(Frame Per Second,FPS)[85]为目标识别算法的性能评价指标。
mAP 是所有目标识别的精确度(AP)的平均值,用来评价识别算法的识别精度,其定义如下:

其中:AAP表示每类目标的识别精度;p(r)表示的是由Precision 和Recall 组成的曲线,横轴为Precision,纵轴为Recall。
F1-Score 是对精确率和召回率的综合考量,用来评价识别算法的识别精度,避免精确率和召回率之间的相互影响,其定义如式(3)所示:

精确度也称查准率,其定义如式(4)所示,召回率也称查全率,其定义如式(5)所示:

其中:TP表示真正例,真实类别为真并预测为真;FN表示假反例,真实类别为真但预测为假;FP表示假正例,真实类别为假但预测为真。
FPS 是指每秒处理图片的个数,用来评价算法的运行速度。本文中的FPS 评价指标是指在进行视频处理过程中的FPS。
2.3 实验结果与分析
根据算法的应用及引用数量,分别选取Anchor-Based系列算法中的Faster R-CNN、Mask R-CNN、SSD、YOLOv3、M2Det、YOLOv4和Anchor-Free系列算法中的CenterNet、FCOS 等8种不同类型的识别算法对实验数据中的boat、car、rubbish进行目标识别。图23给出了不同识别算法的识别结果,表1给出了不同识别算法的计算耗时,表2给出了不同识别算法的AP值比较结果,表3给出了不同识别算法的性能指标比较结果。在表中,加粗表示当前范围内最优数据。

图23 不同识别算法的识别结果Fig.23 Recognition results of different algorithms
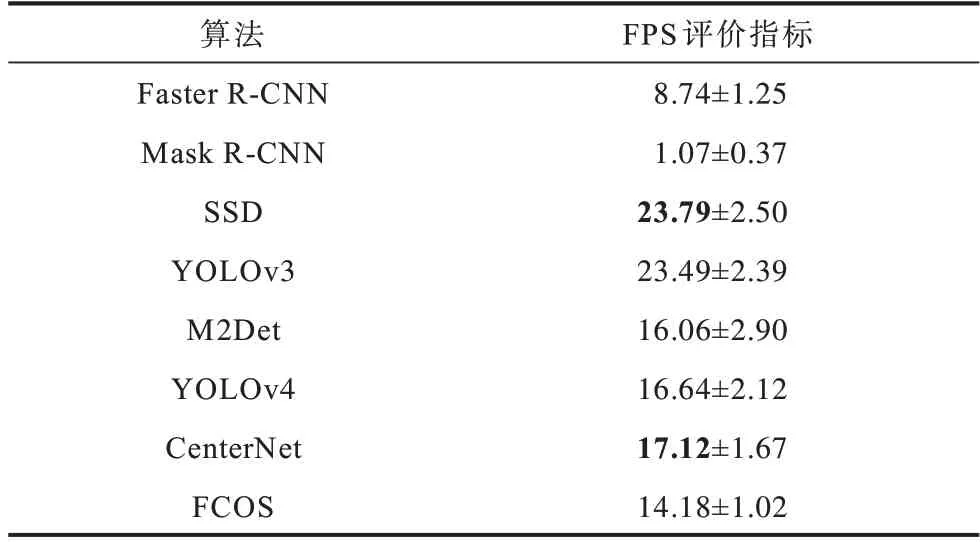
表1 不同识别算法的FPS 比较结果Table 1 FPS comparison results of different recognition algorithms
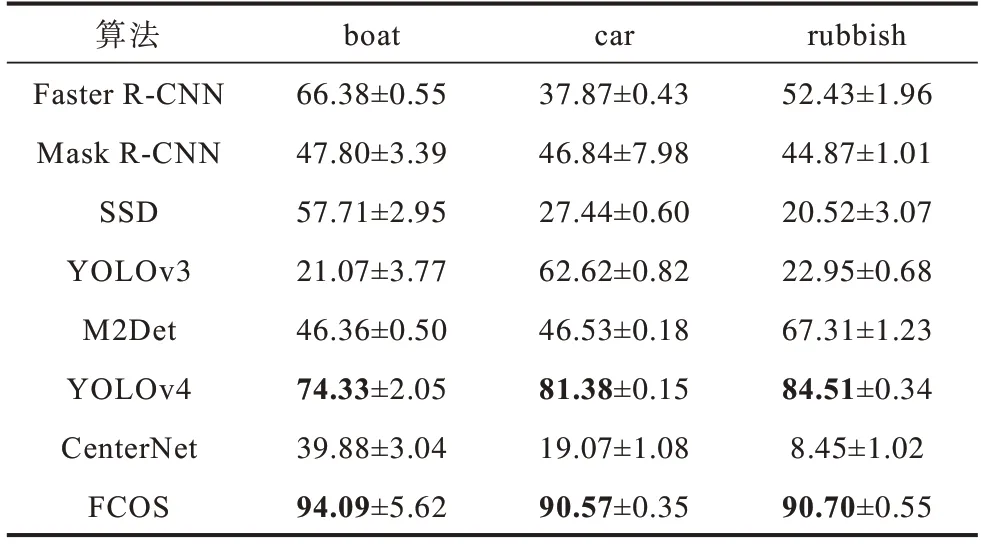
表2 不同识别算法的精确度比较结果Table 2 AP comparison results of different recognition algorithms %
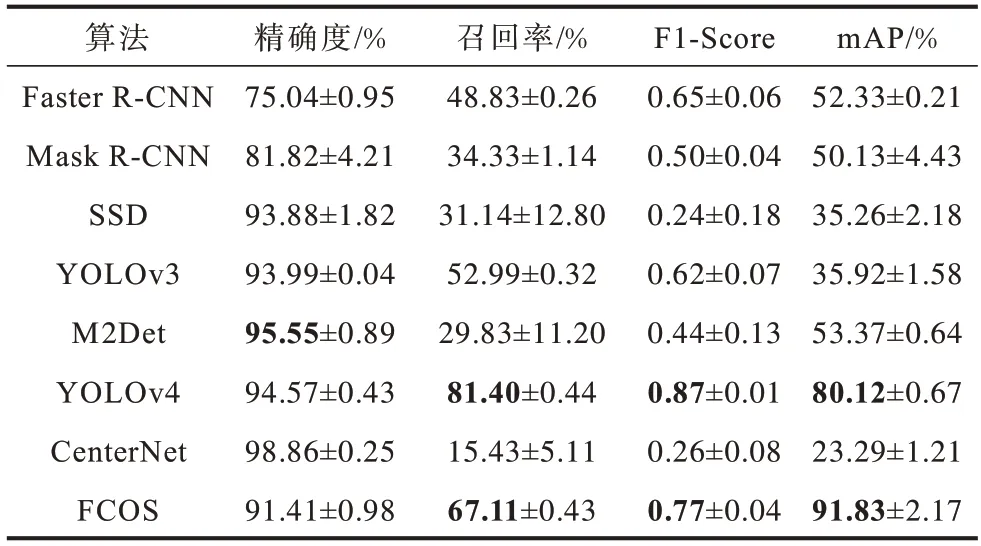
表3 不同识别算法的性能指标比较结果Table 3 Comparison results of performance indicators of different recognition algorithms
由图23、表1~表3 可以看出:
1)Anchor-Based 系列算法
(1)在基于区域的目标识别算法中,Faster R-CNN目标识别算法具有更好的识别效果。Faster R-CNN 与Mask R-CNN 在面向视频的目标识别中,mAP 相差小于3%,F1-score相差小于0.06,但是Faster R-CNN的FPS是Mask R-CNN 的4 倍。
(2)在基于回归的目标识别算法中,YOLOv4 算法较M2Det算法而言,识别效果更为明显,与YOLOv3 和SSD相比,在FPS增加小于8的情况下,mAP增加了45%左右,F1-Score亦有明显的提高。M2Det与YOLOv3和SSD 算法相比较,mAP 提高了大约20%,虽然M2Det的F1-Score 与FPS 不及YOLOv3,但图23 可直观地发现加入多尺度特征融合的M2Det算法在视频目标识别中具有明显优势。
2)Anchor-Free 系列算法
(1)在基于关键点的目标识别算法中,CenterNet算法具有最高的精确度,且FPS 也具有较好的表现。但其他评价指标不理想。
(2)基于特征金字塔的目标识别算法,FCOS 的表现性能较好,除精确度外,每项评价指标均具有最佳值。
3)综 合Anchor-Based 和Anchor-Free 两类算法来看,YOLOv4 是Anchor-Based 算法中性能最佳者,FCOS 是Anchor-Free 算法中性能最佳者。YOLOv4的FPS 高于FCOS,而FCOS 的mAP 高于YOLOv4。
3 未来展望
目前,视频数据已成为各领域研究和应用的重要资源,如何提高从数据到信息的时效性和准确性成为制约数据应用的关键所在,而基于深度学习的目标识别算法为解决该问题提供了理论支撑。综合各类目标识别算法,仍有以下需要改进和发展:
1)直接应用于视频数据的目标识别算法仍是研究重点。现有目标识别算法多数需要对视频数据进行截帧处理,影响了目标识别的效率。针对视频数据进行目标识别和提取的算法,通过多帧处理实现上下文信息关联,计算量大,识别速度有待提高。如T-CNN[86]、Seq-Bbox Matching[87]等。因此,设计直接应用于动态的视频数据,提升视频数据中目标识别的精度和效率,仍是该领域的待研究问题之一。
2)兼顾多尺度特征提取及多目标跟踪仍是目标识别算法需解决的问题之一。视频数据中的目标具有多尺度的特性,尤其是针对小目标的提取及跟踪。如何同步提取小尺度目标,实现多目标跟踪,提高识别算法的鲁棒性和泛化性,仍是待研究的问题。
3)如何兼顾时效性和准确性,设计结构简单的目标识别算法,仍是面向视频数据目标识别算法需要进一步研究的问题。
4 结束语
本文归纳总结面向视频的深度学习目标识别算法,对各类识别算法的网络结构、处理流程及优化策略进行比较和分析。面向深度学习的视频目标识别在特征的自动提取、上下文信息的有效处理、目标运动特性的挖掘等方面具有一定的优势。然而,如何提升深度学习目标识别算法在视频流处理、多尺度目标提取及多目标跟踪等场景中准确性和时效性,促进深度学习目标识别算法在大场景视频监控和长时间序列目标监测等场景中的应用和发展,仍是该领域近期的研究热点和难点。
猜你喜欢
河北省科学院学报(2022年2期)2022-05-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
计算机技术与发展(2020年2期)2020-04-15
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子技术与软件工程(2019年4期)2019-04-26
电子制作(2018年19期)2018-11-14
火力与指挥控制(2018年3期)2018-04-19
太空探索(2016年5期)2016-07-12
